1. はじめに
2026年3月、Langfuse Python SDK v4 がリリースされました。v4 の目玉のひとつは Observations API v2 と Metrics API v2 の新設ですが、マイグレーションガイドには気になる一文があります。
If you are self-hosting Langfuse, do not use
api.observationsorapi.metricsyet; useapi.legacy.observations_v1andapi.legacy.metrics_v1until Observations v2 and Metrics v2 are available on self-hosted deployments
「do not use ... yet」とまで書かれているので、実際にセルフホストで v2 API を叩くと何が返ってくるのか、そして Cloud で同じスクリプトを叩くと何が返ってくるのか ―― を実機で確かめてみた、というのが本記事の主旨です。
公式の背景情報(v4 で何が変わったのか、なぜ Cloud 限定なのか)は検証結果の後、5章にまとめています。
主語の整理
Langfuse はサーバー本体のバージョン(v2.x / v3.x)と、各言語 SDK のバージョン(Python SDK v3 / v4 等)が独立して進行しています。本記事で「v4」と書くときは原則として Python SDK v4 を指します。サーバー側は本稿執筆時点でも v3 系のままで、「サーバー v4」というリリースはまだ出ていません1。
今回の検証ゴール
| # | 検証項目 |
|---|---|
| 1 | セルフホストで v2 API を叩くと何が返るのか |
| 2 | Cloud で同じスクリプトを叩くと v2 API は成功するのか |
| 3 | セルフホスト勢が当面とるべき回避策は何か |
検証環境
| 項目 | 内容 |
|---|---|
| マシン | Windows 11 Pro / WSL2 + Ubuntu 24.04.1 LTS |
| Python SDK | langfuse 4.2.0 |
| セルフホスト |
Langfuse OSS(docker-compose.yml を :3 タグで起動。2026-04-18 時点の pull 結果で UI 表示は v3.169.0) |
| Cloud | Langfuse Hobby(EU リージョン、2026-04-18 に新規作成。UI 表示は v3.169.0) |
-
セルフホスト

-
Cloud

Cloud もセルフホストもサーバーバージョン表記は同じ v3.169.0 でした。「v4」という呼称はサーバー本体のメジャーバージョンではなく、Cloud 限定で先行提供されている API v2 / UI 機能群のブランドを指しているようです。こちらは後述するエラーメッセージの読み解きにも影響してきます。
2. 検証スクリプト
両環境で同じ test_api.py を叩きます。.env の3つの値(LANGFUSE_PUBLIC_KEY / LANGFUSE_SECRET_KEY / LANGFUSE_HOST)を切り替えれば、Python スクリプト本体には一切手を入れずに環境を切り替えられる 構成にしました。
test_api.py
from dotenv import load_dotenv
from langfuse import get_client
load_dotenv()
langfuse = get_client()
# ❌ v2 API(セルフホストでは失敗する想定)
print("--- v2 API (expected to fail on self-host) ---")
try:
result = langfuse.api.observations.get_many()
print(f"UNEXPECTED: v2 API succeeded: {result}")
except Exception as e:
print(f"Expected error: {type(e).__name__}: {e}")
# ✅ legacy v1 API(両環境で成功する想定)
print("\n--- legacy v1 API (expected to succeed) ---")
try:
result = langfuse.api.legacy.observations_v1.get_many()
count = len(result.data) if hasattr(result, 'data') else '?'
print(f"Success: retrieved {count} observations")
except Exception as e:
print(f"UNEXPECTED error: {type(e).__name__}: {e}")
3. 検証手順&実施
①セルフホストで実行
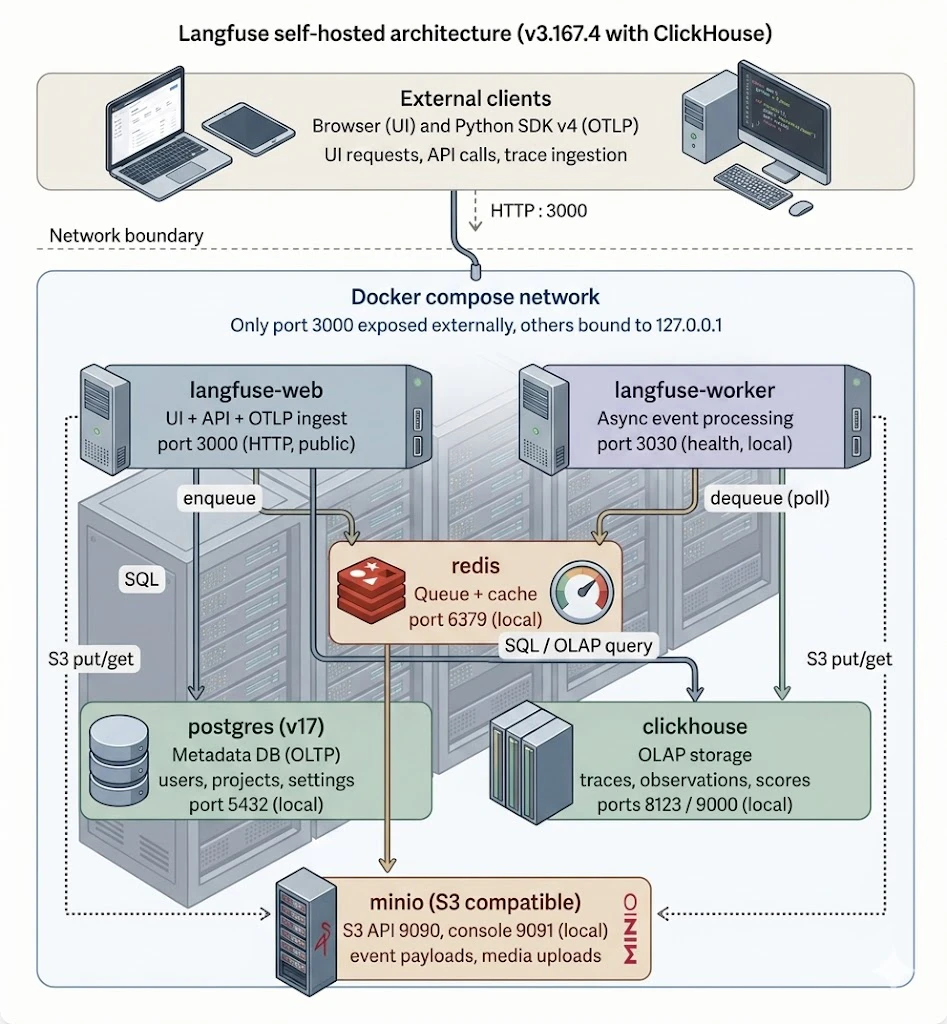
セルフホスト構成のイメージはこちらです。公式のdocker compose構成を実行しているだけです。
.env をセルフホスト用に設定します。
LANGFUSE_PUBLIC_KEY=pk-lf-xxxxxxxx
LANGFUSE_SECRET_KEY=sk-lf-xxxxxxxx
LANGFUSE_HOST=http://localhost:3000
実行結果は次のとおりです。
$ python test_api.py
--- v2 API (expected to fail on self-host) ---
Expected error: NotFoundError: ... status_code: 404,
body: {
'message': 'v2 APIs are currently in beta and only available on Langfuse Cloud',
'error': 'LangfuseNotFoundError'
}
--- legacy v1 API (expected to succeed) ---
Success: retrieved 2 observations
読み取れること
- HTTP ステータスは 404
- レスポンスボディには
'error': 'LangfuseNotFoundError'という Langfuse 固有のエラーコードと、'v2 APIs are currently in beta and only available on Langfuse Cloud'という明示的なメッセージが返ってきます - つまり、単に「API エンドポイントが未実装」ではなく、Langfuse サーバー側が v2 API を受け付けないように意図的に制御されている 状態です。feature flag 的な実装になっていることがうかがえます。セルフホスト側は 本稿執筆時点の最新 v3.169.0 なので、「古いバージョンだったから v2 API が生えていなかった」わけではありません
- 一方、
api.legacy.observations_v1.get_many()は正常に 2 件の observation を取得しています(事前に@observe()で送信したトレース内のmy_agentとsearch_web)
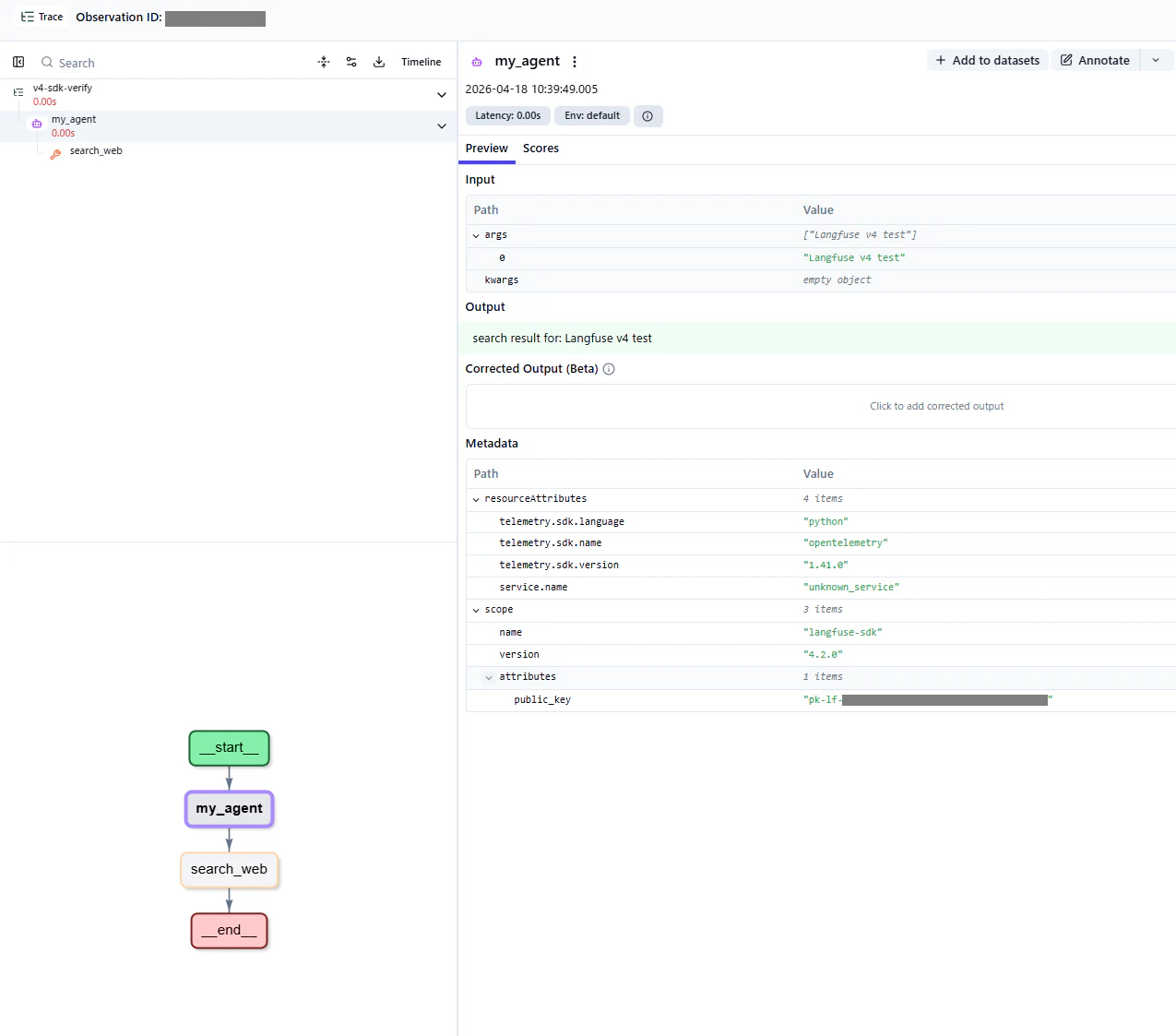
セルフホスト版のUI
②Cloud で実行
.env の3つの値(Public Key / Secret Key / HOST)を Cloud 用に差し替えます。Python スクリプト本体は 1 行も変更しません。
LANGFUSE_PUBLIC_KEY=pk-lf-xxxxxxxx-cloud
LANGFUSE_SECRET_KEY=sk-lf-xxxxxxxx-cloud
LANGFUSE_HOST=https://cloud.langfuse.com
実行結果は次のとおりです。
#UNEXPECTEDが出ているのは元のスクリプトをそのまま流用したのでご愛敬、という事で・・
$ python test_api.py
--- v2 API (expected to fail on self-host) ---
UNEXPECTED: v2 API succeeded: data=[ObservationV2(id='xxxxxx',
trace_id='xxxxxxxxxxxxxxxxxxxx',
start_time=datetime.datetime(2026, 4, 18, 5, 32, 38, 701000, ...),
project_id='xxxxxxxxxxxxxxxxxxxxxxxxxx',
parent_observation_id='xxxxxxxxxxxxxxxxxx',
type='TOOL', name=None, input=None, output=None, metadata=None,
...
latency=0.0, ...),
ObservationV2(id='xxxxxxxxxxxxxxxxx',
trace_id='xxxxxxxxxxxxxxxx',
parent_observation_id=None, type='AGENT', ...)
] meta=ObservationsV2Meta(cursor=None)
--- legacy v1 API (expected to succeed) ---
Success: retrieved 2 observations
読み取れること
-
v2 API が成功。同じスクリプトを、
.envの接続情報3点(Public Key / Secret Key / HOST)だけ差し替えて叩いているので、差分はサーバー側にあることが確定 しています - レスポンスは
data=[ObservationV2(...), ...]とmeta=ObservationsV2Meta(cursor=None)の構造。v2 新機能の cursor ベースのページネーション がここに現れています -
type='TOOL'type='AGENT'と大文字で返っています(Python SDK でas_type="tool"as_type="agent"と書いたものが、DB レベルでは大文字で保存される仕様) -
parent_observation_id経由で parent-child 関係が保持されている(search_webの親はmy_agent) - Cloud 版の出力をよく見ると、
name=None、input=None、output=None、metadata=Noneのように多くのフィールドがNoneになっています。これは v2 API の selective field retrieval 機能がデフォルトで効いているためで、デフォルトではcore + basicの最小フィールドグループのみが返却され、input/output/metadataなどを取得するにはfieldsパラメータでの明示指定が必要です2
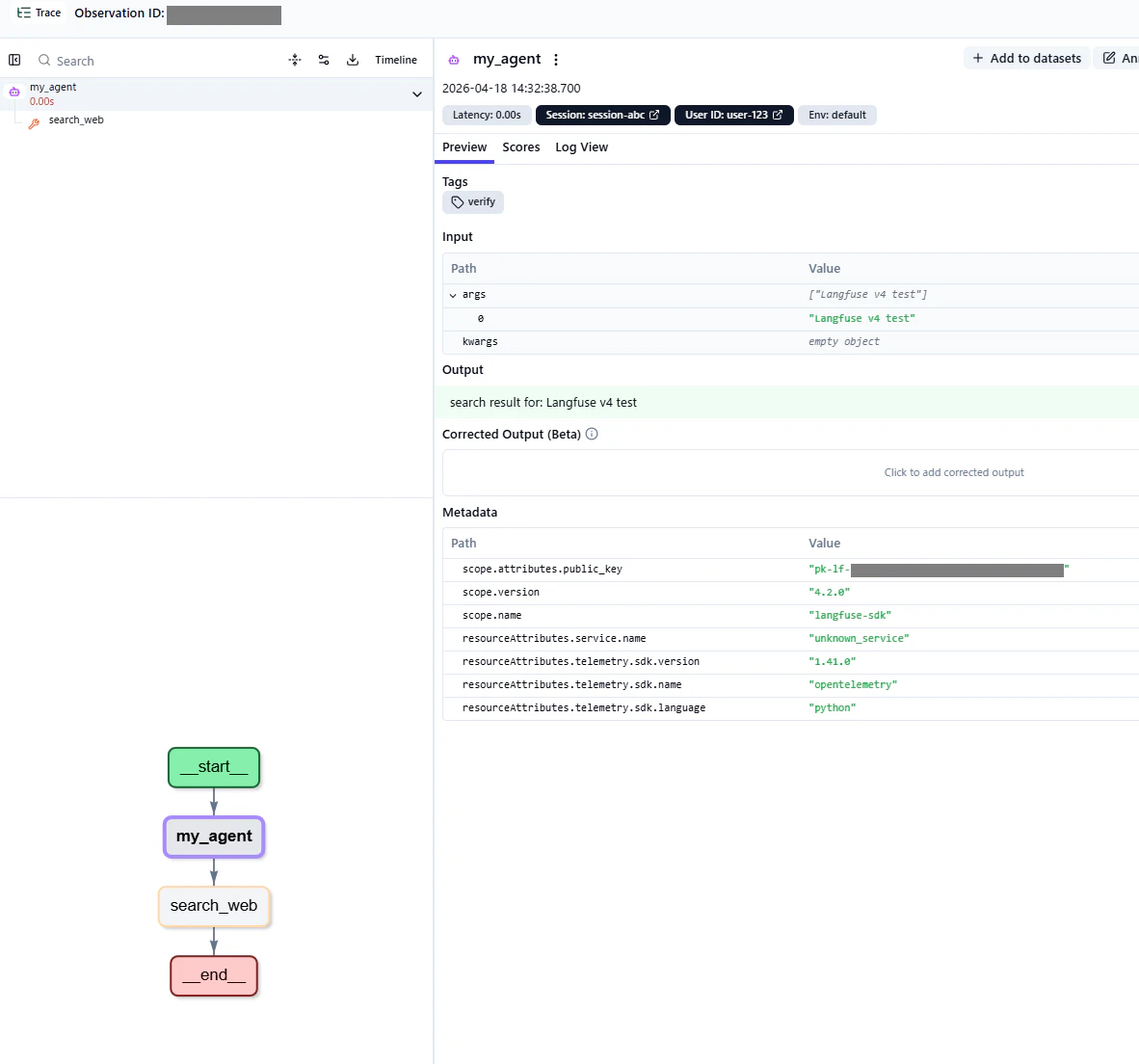
Cloud版のUI
4. 対比サマリ
| 呼び出し | セルフホスト v3.169.0 OSS | Cloud v3.169.0 Hobby |
|---|---|---|
api.observations.get_many()(v2) |
❌ 404 LangfuseNotFoundError「Cloud only」と明示 | ✅ data=[ObservationV2, ...] meta=ObservationsV2Meta(cursor=...)
|
api.legacy.observations_v1.get_many()(v1) |
✅ 2 observations | ✅ 2 observations |
Python スクリプト本体は 1 行も変更せず、.env の接続先3点(Public Key / Secret Key / HOST)だけを差し替えた結果 です。SDK v4 のクライアントは同じコードで両環境を扱えるよう設計されており、v2 / v1 の両クラスが同梱されているのは、この「Cloud/OSS でエンドポイントの提供状況が異なる」状況にピンポイントで対応するためだと理解できます。
5. 背景: v2 API で何が変わったのか・なぜ Cloud 限定なのか
ここまでが実機検証の本編ですが、「なぜ v2 API が Cloud 限定になっているのか」「そもそも v2 API で何が変わったのか」という背景を知っておくと、今回の検証結果が腑に落ちやすいので、公式ソースと合わせてまとめておきます。
v2 API で何が変わったのか
Langfuse の v1 API は、observation や metric の取得時にすべてのフィールドを返す「全部入り」方式で、かつ join と dedup を伴う read クエリが内部で実行されていました。小規模な確認用途では問題ないのですが、外部分析基盤から大量データを fetch するようなユースケースでは、不要なフィールドのスキャンコスト と ページネーションの重さ が課題になっていました。
v4 はこの課題に対して、データモデル自体を traces + observations の2テーブル構成から observations 一本 に再設計し、副産物として API v2 を提供しています(Langfuse v4: Faster and Observations-First)。具体的には次の3点で改善が図られています。
① cursor ベースのページネーション
v1 の offset ベースから cursor ベースに変更されました。大量データを分割取得する際の一貫性とパフォーマンスが向上しています3。
② selective field retrieval
デフォルトでは core + basic の最小フィールドグループのみを返し、input、output、metadata などは明示的に fields パラメータで指定しないと取得されません4。本文中の Cloud 実行結果で多くのフィールドが None になっていたのは、この仕様によるものです。
# 必要なフィールドだけを明示して取得(v2 ならではの書き方)
result = langfuse.api.observations.get_many(
fields="core,basic,input,output,usage"
)
③ ClickHouse の単一テーブルクエリ化
v2 API の裏にある ClickHouse のデータモデルが、wide で(ほぼ)immutable な observations テーブルに一本化されている、と説明されています5。この設計により、read 時の JOIN と dedup が不要になり、大量データのテーブルロード時間が「秒からミリ秒に」短縮されたとされています6。
これらの改善は、特に外部の BI ツールや分析基盤から Langfuse のデータを引き抜いているユーザーにとっては運用面で大きな違いになります。
なぜセルフホストではロックアウトされているのか
GitHub Discussion #12518 と #12926 に公式の整理があります。要点は次の3つです。
- v2 API は 2025年12月17日から Cloud 限定のベータ として先行提供されてきた7。v4 リリース(2026年3月)はこの路線を標準化したもの
- v2 API の裏にある ClickHouse のデータモデルが新しい。wide で(ほぼ)immutable な observations テーブルに一本化されており、read 時の join と dedup を撲滅する設計
- セルフホスト向けマイグレーションパスは "coming weeks"。自動マイグレーションツールと OSS 向けの dual-write セットアップを整備中
つまり API v2 の Cloud 限定化は「技術的な制限」ではなく「段階的ロールアウトの途中」という位置付けです。セルフホスト勢は legacy v1 を使って待っていれば、いずれ v2 に移行できるはずです。
6. まとめ
Langfuse Python SDK v4 の公開 REST API v2 は、cursor ベースのページネーションと selective field retrieval により、大量データの分析系ユースケースで明確なメリットがあります。ただし現時点では Cloud 限定での先行提供 となっており、セルフホスト環境では意図的にロックアウトされています。
セルフホスト利用者が事前に実行・もしくはウォッチしておくと良いこと
- Python SDK を v4 系にアップグレード。トレース送信機能はセルフホストでもそのまま動作します
-
Python SDK を使う場合、API 呼び出しは
api.legacy.observations_v1.get_many()/api.legacy.metrics_v1.get_many()に書き換え-
メソッド名は
get_many()。.list()ではないので注意 -
curlや他言語から直接 REST API を叩く場合は、従来どおり/api/public/observations等のパスに GET すれば v1 として動作(URL 側に/legacy/は入らない)
-
メソッド名は
- Langfuse サーバーは v3.125.0 以上を推奨(Python SDK v3 の動作要件。v4 でも同バージョン以上で OK)
- v4 OSS 対応の進捗は GitHub Discussion #12518 と #12926 でウォッチ
参考
- Langfuse v4: Faster and Observations-First
- Python SDK v3 → v4 マイグレーションガイド
- Query via SDKs(API メソッド一覧)
- Simplifying Langfuse for Scale(公式技術ブログ、v4 データモデル解説)
- Dashboard Changes in Langfuse v4
- Self hosted v4(GitHub Discussion #12926)
- Upcoming architecture changes: Simplify Langfuse for Scale (v4)(GitHub Discussion #12518)
-
Langfuse の OSS リポジトリでは
v3.x系が継続してタグ付けされており、「v4」という名前のサーバーリリースは本稿執筆時点では確認できませんでした。 ↩ -
selective field retrieval の詳細は 5 章を参照。デフォルトでは
core + basicの最小フィールドグループのみが返却されます。 ↩ -
Observations API 公式ドキュメント 参照。「The v1 API uses offset-based pagination (page numbers) which becomes increasingly slow for large datasets. The v2 API uses cursor-based pagination for better and more consistent performance.」 ↩
-
Observations API 公式ドキュメント 参照。「The v2 API lets you specify which field groups you need as a comma-separated string:
?fields=core,basic,usage. Iffieldsis not specified,coreandbasicfield groups are returned by default.」 ↩ -
GitHub Discussion #12518 で公式に「We are moving to an observation-centric data model based on a new, wide, (mostly) immutable ClickHouse table.」と表明されています。同じ思想は Langfuse v4 ドキュメント の「single unified observations table」という説明や、v4 ダッシュボード変更ドキュメント の「all data lives in a single denormalized ClickHouse table — the wide observations table」という記述でも確認できます。 ↩
-
Langfuse 公式ブログ Simplifying Langfuse for Scale 参照。「This eliminates joins and deduplication at read-time ... Initial table loads for large amounts of data go from seconds to milliseconds.」 ↩
-
v2 Metrics and Observations API (Beta) changelog(2025-12-17) 参照。 ↩