この記事は AWS Community Builders(※) Advent Calendar 2023 シリーズ2 と PostgreSQL Advent Calendar 2023 3 日目の記事のクロスポストです。
(※)AWS Community Builders については こちら
はじめに
2023年11月に Amazon Aurora PostgreSQL Optimized Reads という機能が発表されました。
- AWS が Amazon Aurora PostgreSQL Optimized Reads を発表
- Amazon Aurora Optimized Reads for Aurora PostgreSQL with up to 8x query latency improvement for I/O-intensive applications
なお、既に2023年4月に RDS for PostgreSQLでもOptimized Reads 機能が実装されています。(後述しますが、若干実装された機能には違いがあります)
基本的にはどちらも高速な ローカルインスタンスに接続される NVMe ベースの SSD ブロックレベルストレージ(インスタンスストア) を利用することで、EBSへの負荷を下げて性能向上を図る機能となります。
Optimized Reads機能とは
通常、Amazon RDS や Aurora においては EBS/Auroraローカルストレージ に一時データを作成します。次の左図はRDS for MySQLですが、Temp Tables が一時データに該当します。一方、Optimized Reads機能を利用すると以下のようにRDS/Auroraインスタンスのインスタンスストア内に一時データが作成されるようになります。
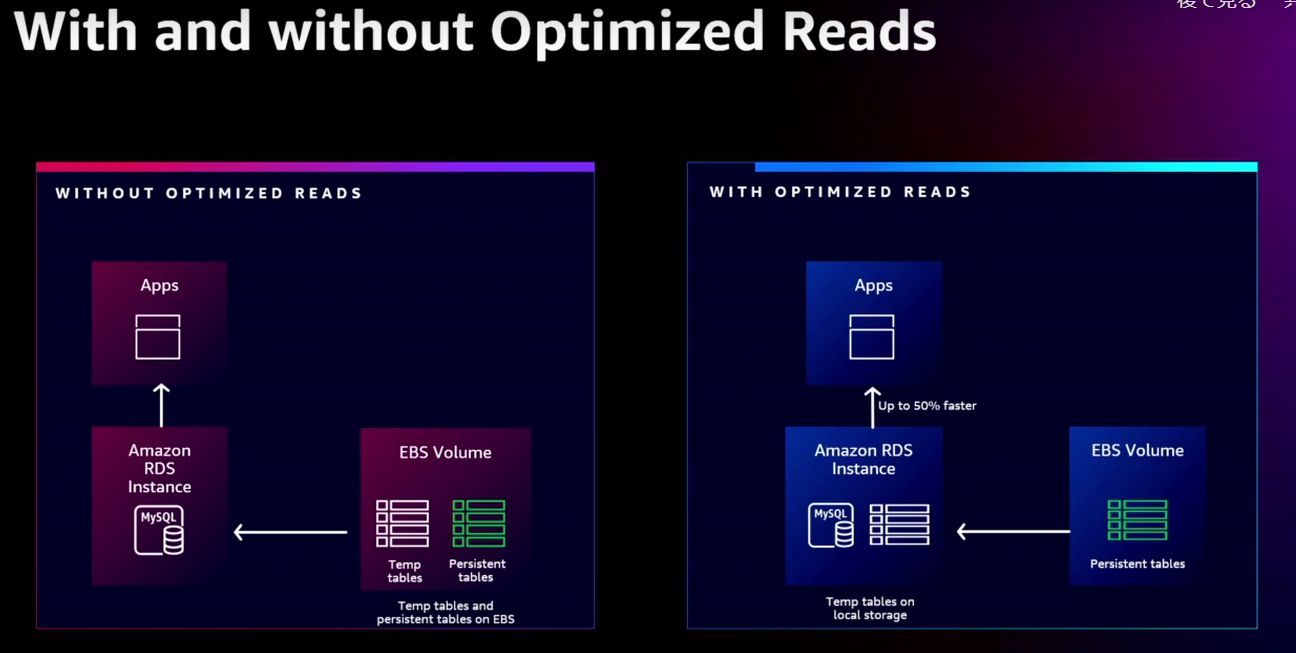
(出典:AWS re:Invent 2022 - Deep dive on MySQL databases in Amazon RDS (DAT222): 動画なのでご注意ください)
データベースが利用するデータには、永続データと一時データがあり、大量データの結合やソートを行うときに一時データが作成されます。基本的には一時データとなるため、永続的なストレージへ保存する必要はありません。このOptimized Reads機能ではそれらの一時データを高速なインスタンスストアに確保する形で性能改善を図ります。
また、NVMe ストレージを利用するため、インスタンスはNVMeが接続されているモデル(rxgd 等、d がつくモデル)である必要があります。
Amazon Aurora Optimized Reads for PostgreSQL とは
Amazon Aurora の Optimized Reads for PostgreSQL機能について、簡単に紹介します。基本的なアーキテクチャは RDS の Optimized Reads と同様ですが、Aurora Optimized Reads では次の二つの機能がサポートされています。
-
階層型キャッシュ
- ローカルの NVMe ストレージを利用して DB インスタンスのキャッシュ容量を拡張
- インメモリデータベースバッファプールから削除されようとしているデータベースページを自動的にキャッシュし、クエリのレイテンシーを最大 8 倍改善
-
一時オブジェクト
- 大量のデータの並べ替え、結合、またはマージするクエリにおいて構成されたメモリ内に収まらない際に、ローカルの NVMe ストレージを利用することで待機時間とスループットが向上
階層型キャッシュ についてはRDSにはなかった機能となります。なお、階層型キャッシュの機能を有効にするためには、NVMeストレージをサポートするインスタンスであるだけでなく、Auroraのクラスタストレージにて I/O Optimized を選択する必要があります。
詳細は機能が紹介されているAWS database blog(New – Amazon Aurora Optimized Reads for Aurora PostgreSQL with up to 8x query latency improvement for I/O-intensive applications)を参照ください。
Amazon Aurora Optimized Reads for PostgreSQL を試してみた
では、実際にAmazon Aurora Optimized Reads for PostgreSQLを試してみます。
Optimized Readsが有効になったAurora PostgreSQLの作成
Optimized Reads が利用できるバージョン(14.9以降、15.4以降)を選択すると、インスタンスクラスの設定で以下のようにNVMe SSDがついているインスタンスを選択することができるようになります。該当のクラスを選択してAuroraを作成すると、自動的にOptimized Reads機能がONになっています。
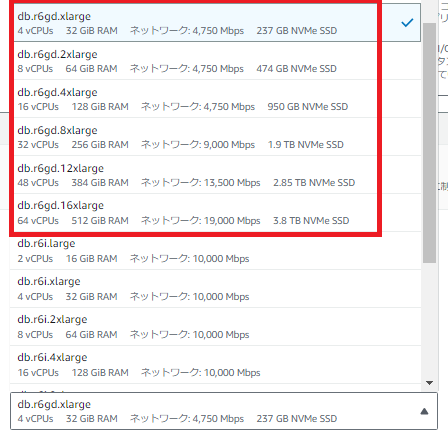
また、作成する際に以下のクラスタストレージ設定において「Aurora I/O 最適化」を選択すると自動的に階層型キャッシュ機能・一時オブジェクト機能がONに、「Auroraスタンダード」を選択すると一時オブジェクト機能のみがONになります。
それぞれの機能のON/OFFは以下のような形でも確認が可能です。
=> show temp_tablespaces ;
temp_tablespaces
------------------
=> show shared_preload_libraries;
shared_preload_libraries
------------------------------------------
rdsutils,pg_stat_statements,writeforward
=> show temp_tablespaces ;
temp_tablespaces
------------------------
aurora_temp_tablespace
=> show shared_preload_libraries;
shared_preload_libraries
------------------------------------------
rdsutils,pg_stat_statements,writeforward
=> show temp_tablespaces ;
temp_tablespaces
------------------------
aurora_temp_tablespace
=> show shared_preload_libraries;
shared_preload_libraries
-----------------------------------------------------------------------
rdsutils,pg_stat_statements,aurora_optimized_reads_cache,writeforward
Optimized Reads機能の利点確認
Optimized Reads 機能の利点は以下の二つになります。
- 階層型キャッシュ
- 一時オブジェクト
階層型キャッシュについては、紹介されている AWS Database blog で性能検証が行われ、レイテンシが9倍に、ピークスループットが 2.6倍に、と報告されています。
という事で、ここでは 主に一時オブジェクト について検証してみます。
一時オブジェクトの書き込み性能
Optimized Reads なのに書き込み性能?と思われるかもしれませんが、NVMe のローカルストレージを利用するため、その部分への書き込み性能ももちろん向上します。
以下の約20GBのオブジェクトをCTAS(create table as select) で一時データとして作成します。
=> select relname, (relpages::int8 * 8192)/1024/1024 as MB from pg_class where relname='sbtest1' and relpages > '1000' order by 2 desc;
relname | mb
---------+-------
sbtest1 | 21116
$ time psql -h xxxxxx.cluster-xxxxxxxxxxxx.ap-northeast-1.rds.amazonaws.com -p 5432 -U postgres -d xxxxxx -c "create temp table tmp_sbtest as select * from sbtest1;"
SELECT 100000000
real xx m xx s
実行時間等は以下のようになり、一時オブジェクト機能がONになっていると性能向上していることが確認できます。階層型キャッシュの有無は影響ないことも確認できます。
| インスタンスクラス | ストレージ設定 | 有効機能 | 実行時間(秒) | スループット(MB/秒) |
|---|---|---|---|---|
| r6g.4xlarge Optimized Reads 無効 |
スタンダード | 83.2 | 253.8 | |
| r6gd.4xlarge Optimized Reads 有効 |
スタンダード | 一時オブジェクト | 59.8 | 353.1 |
| r6gd.4xlarge Optimized Reads 有効 |
I/O 最適化 | 階層型キャッシュ 一時オブジェクト |
58.6 | 360.3 |
ベンチマーク性能
1億行のデータを持つ sbtest1 テーブルに対して、以下のクエリをsysbenchから複数のThreadで実行して、平均実行時間を確認します。一時オブジェクト機能を有効化することで、性能が向上していることが確認できます。
- EXPLAIN(analyze, buffers) SELECT DISTINCT pad FROM sbtest1 limit 65000000;
- EXPLAIN(analyze, buffers) SELECT k , length(pad) FROM sbtest1 ORDER BY pad LIMIT 50000000;
| インスタンスクラス | ストレージ設定 | 有効機能 | 並列度 4 平均実行時間(秒) |
並列度 8 平均実行時間(秒) |
並列度 12 平均実行時間(秒) |
並列度16 平均実行時間(秒) |
並列度20 平均実行時間(秒) |
|---|---|---|---|---|---|---|---|
| r6g.4xlarge Optimized Reads 有効 |
スタンダード | - | 1,121.3 | 560.5 | 373.6 | 280.3 | 224.2 |
| r6gd.4xlarge Optimized Reads 無効 |
スタンダード | 一時オブジェクト | 649.5 | 352.7 | 234.4 | 175.9 | 141.1 |
| r6gd.4xlarge Optimized Reads 有効 |
I/O 最適化 | 階層型キャッシュ 一時オブジェクト |
709.1 | 352.0 | 234.6 | 176.1 | 140.7 |
※本ベンチマークは AWSのワークショップ(Optimized Reads) を参考にデータ準備等を行っています、試行回数は二回平均です
まとめ
もともとのAWS Database blogの紹介記事にもありますが、大きめのデータを扱う場合にインスタンスクラスを変更することなく対応ができる可能性がありますので、それぞれのシステムのワークロードで検証して利用していくのが良いと思います。
最近はDatabaseの前段にElastiCacheを入れてDatabaseの負荷の軽減、等も積極的にAWSから紹介されており、いろいろな形に応じて負荷軽減、ひいてはコスト軽減が行えるようになっていますが、その分それぞれの環境に応じた設計が必要になってきています。
是非、Optimized Read機能に限らず様々な機能を試して負荷/コスト軽減につなげてもらえたらと思います。
また、いままでは大体Auroraの機能追加はMySQLが先行していましたが、本Optimized Reads機能や先日のRe:inventで発表された Limitless DatabaseはPostgreSQLが先行しています。いずれにせよ両方とも大容量を扱う、Redshiftと連携する、といった機能を中心にアップデートされてきているように見えており、うまくOLTPをAuroraで捌きながらリアルタイムでDWHであるRedshiftでもデータを利用できるようにしていく、というような思想を感じます。
注意点
紹介blogにある通り、Optimized Reads 階層型キャッシュ機能が無効の場合には NVMe ストレージの 90% が一時オブジェクトに割り当てられますが、階層型キャッシュが有効になる(I/O最適化ストレージを利用する)と、一時オブジェクトはインスタンスメモリの2倍に設定され、それ以外の部分が階層型キャッシュに割り当てられます。
つまり、階層型キャッシュが有効になると一時オブジェクトのサイズは小さくなります。また、一時オブジェクトが上限まで使われた場合、トランザクションはエラーになってしまうため、NVMeの空き容量(FreeEphemeralStorage)はきちんとモニタする必要があります。

FATAL: PQexec() failed: 7 could not write to file "pg_tblspc/16399/PG_14_202107181/pgsql_tmp/pgsql_tmp3254.2": No space left on device
FATAL: failed query was: EXPLAIN(analyze, buffers) SELECT k , length(pad) FROM sbtest1 ORDER BY pad LIMIT 100000000;
FATAL: `thread_run' function failed: load_test2.lua:11: db_query() failed
FATAL: PQexec() failed: 7 could not write to file "pg_tblspc/16399/PG_14_202107181/pgsql_tmp/pgsql_tmp3253.2": No space left on device
FATAL: failed query was: EXPLAIN(analyze, buffers) SELECT k , length(pad) FROM sbtest1 ORDER BY pad LIMIT 100000000;
FATAL: `thread_run' function failed: load_test2.lua:11: db_query() failed
FATAL: PQexec() failed: 7 could not write to file "pg_tblspc/16399/PG_14_202107181/pgsql_tmp/pgsql_tmp3256.1": No space left on device
FATAL: failed query was: EXPLAIN(analyze, buffers) SELECT k , length(pad) FROM sbtest1 ORDER BY pad LIMIT 100000000;
FATAL: `thread_run' function failed: load_test2.lua:11: db_query() failed
※ベンチマーク時と少しSQLを変えてます
おまけ
実は本機能(Amazon Aurora Optimized Reads機能)は現時点(2023/12/2)ではまだ Aurora MySQL には実装されていません。一方で、RDS の Optimized Reads機能はMySQLに実装済みで、さらにMySQLには Optimized Writesも実装されています。
また、RDS for Oracleでも2022年9月のアップデートで名前は違いますが同様の機能を利用できるようになっています。(一時テーブルスペース用インスタンスストア が 一時オブジェクト、データベーススマートフラッシュキャッシュ が階層型キャッシュ に該当します)