1.本記事の目的、学習内容
2.今回学習したBERTについて
3.実施手順一覧
4.学習内容の考察
###1.本記事の目的、学習内容
自身の学んでいる、また仕事としている分野において調査を進めていく際に関連論文のアブストラクトを検索し抽出し、より類似性の高い記事をピックアップを行うことで調査を効率化することを目標として自然言語処理を学習しています。
###2.今回学習したBERTについて
BERTとは、2018年にGoogleから発表された自然言語処理モデルのことです。
最大の特徴は「文脈を読むことが可能になった」ことで、多様なタスクにおいて当時の最高スコアを叩き出し、スマートスピーカーなどの性能を革新的に飛躍させた技術であり、自然言語処理という分野の中では私たちの暮らしの一番身近にある検索エンジンに利用されている身近な技術の一つです。
日本では、日立ソリューションズは「活文 知的情報マイニング」などに導入されています。
###3.実施手順
※実行環境はGoogle Colaboratoryを使用しました。
また、こちらのブログを参考に作成させていただきました。
https://colors.m-field.co.jp/search-by-bert/?utm_source=techblog
今回は、形態素解析を行うにあたり、日本語の形態素解析器として代表的なMeCabを使用していきます。
形態素解析とは、文章として構成されている単語を最小単位に分解し、文章を分割する作業のことです。
MeCabとは、京都大学情報学研究科と日本電信電話株式会社コミュニケーション科学基礎研究所の共同研究のなかで、現Googleソフトウェアエンジニア 工藤拓氏によって開発されたオープンソース型の形態素解析ツールです。
辞書やコーパスの種類に依存せずに利用可能で、汎用的な設計となっており、条件付き確率場とよばれる学習モデルにより高い解析精度を誇っています。
mecab-python3 はそのままインストールするとBERTのトークナイズ時にエラーになってしまったので、バージョン指定してインストールしています。
%%bash
# ライブラリのインストール
apt install aptitude swig
aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
pip install mecab-python3==0.996.5
#pip install mecab-python3
pip install unidic-lite nlplot japanize-matplotlib transformers fugashi ipadi
osモジュールとは、OS(オペレーティングシステム)に依存する機能をPythonで扱えるように提供されたモジュールです。ファイル操作を行ったり、コマンドラインでシステムの操作を行うときによく使われます。
モジュール re とは、 Python で正規表現を行うモジュールです。 Python の標準ライブラリに含まれています。正規表現とは、文字列の集合を「意味合いをもたせた記号を組み合わせて」表現する手法です。正規表現は以下のような用途で利用されます。
import os
import re
import numpy as np
import pandas as pd
from tqdm.notebook import tqdm
tqdm.pandas()
import nlplot
import warnings
warnings.simplefilter('ignore')
import torch
import transformers
from transformers import BertJapaneseTokenizer
import logging
logging.getLogger("transformers.tokenization_utils_base").setLevel(logging.ERROR) # tokenize時の警告を抑制
Colaboratoryと自分のGoogldriveとを繋げていく。
Googledriveに今回使用するcsvファイルが保存されているため。
from google.colab import drive
drive.mount('/content/drive')
今回はここでtest3というcsvファイルを読み込んでいる。
理想としては、ここで各論文タイトルにアブストラクトをテキストに指定して抽出したファイルで読み込めたらと思いましたが、今回は初めてということもありエラーを恐れて短めの文章にしています。
import pandas as pd
df = pd.read_csv('/content/drive/MyDrive/test3.csv')

###文書の特徴ベクトル化
BertExtractor classで日本語学習済みモデルのトークナイザーと学習済みモデルを読み込み、記事の本文を特徴ベクトル化します。
学習済みモデルの使用の流れとしては、使用するトークナイザーとモデルをfrom_pretrained 関数を使用して呼び出し、トークナイザーで文書の分かち書きを行いベクトル化したものをモデルに入力し、文書の特徴ベクトルを取り出すという形になります。呼び出している学習済みモデルは東北大学の乾研究室が作成したものになります。
classとはいわば使いまわせる型のようなもので、オブジェクトはその中身。
個人的には、たい焼きの型をつける鉄板で、たい焼きを焼いていくようなものと覚えました。
ただし、型は決まっているものの初期値を入れなければいけないため、init_(selt)で指定していきます。
init(一番最初)、self(自分)という意味で、
自分が一番最初に初期化する際にself.deviceに書いている'cuda'などの値を入るということです。
例えばself.device = 'cuda'というのは、'cuda'が使えるならば'cuda'を使用し、文字列をself.deviceに入れる。GPU外部プロセスがなければ、cpuを入れるという意味になります。
その下のself.model.nameも同様で、どういう学習済みモデルを使用するかということです。
self.tokeneizerは、 BertJapaneseTokenizerというオブジェクトの中の.from_pretrainedというメンバーを自分のself.tokeneizerに入れています。
オブジェクトの中の「.」ドットは〇〇の中の〇〇という意味になります。
ここで調べたものがいわえる「オブジェクト指向」と呼ばれるコンピュータプログラムの設計や実装についての考え方の一つです。互いに密接に関連するデータと手続きをオブジェクトと呼ばれるまとまりとして定義し、様々なオブジェクトを組み合わせて関連性や相互作用を記述していくことでシステム全体を構築するといったところでしょうか。
「オブジェクト指向」に関しては、明快な答えに行きつけていないため今後も調査し続けていこうと考えています。
class BertExtractor:
"""文書特徴抽出用クラス"""
def __init__(self):
self.device = 'cuda' if torch.cuda.is_available() else 'cpu' #GPUが使用可能ならGPUを使用
self.model_name = 'cl-tohoku/bert-base-japanese-whole-word-masking' #使用する学習済みモデル名
self.tokenizer = BertJapaneseTokenizer.from_pretrained(self.model_name) #使用するBERTトークナイザー
self.bert_model = transformers.BertModel.from_pretrained(self.model_name) #学習済みモデル呼び出し
self.bert_model = self.bert_model.to(self.device)
self.max_len = 128 #使用する入力文書の長さ。最大512まで
def extract(self, sentence):
"""文書特徴ベクトルを抽出する"""
# 文書のトークナイズ
inp = self.tokenizer.encode(sentence)
len_inp = len(inp)
# 入力トークン数の調整
if len_inp >= self.max_len:
inputs = inp[:self.max_len]
else:
inputs = inp + [0] * (self.max_len - len_inp)
# モデルへ文書を入力し特徴ベクトルを取り出す
inputs_tensor = torch.tensor([inputs], dtype=torch.long).to(self.device)
seq_out = self.bert_model(inputs_tensor)[0]
if torch.cuda.is_available():
return seq_out[0][0].cpu().detach().numpy() # 0番目は [CLS] token, 768 dim の文章特徴量
else:
return seq_out[0][0].detach().numpy()
extract 関数で各文章の特徴ベクトルを取り出し、text_feature カラムに格納します。
その後 cos_sim_matrix 関数で各記事の特徴ベクトル間のコサイン類似度行列を計算し、返却しています。
簡単に言ってしまえば、問いに値を与え、計算したその値と値を使って、その類似度を表すcos sim matrixという計算をしています。
return d / norm / norm.Tで上記で説明したものの戻り値を表している。
1行目のdef cos sim matrix(matrix): からreturn d / norm / norm.Tまでは、関数の記述であり何か実行するわけではないため、bex = BertExtractor()という行で文章の特徴を算出することができ、それ以降で文章の特徴ベクトル、類似度を算出しているということになります。
def cos_sim_matrix(matrix):
"""文書間のコサイン類似度を計算し、類似度行列を返す"""
d = matrix @ matrix.T
norm = (matrix * matrix).sum(axis=1, keepdims=True) ** .5
return d / norm / norm.T
bex = BertExtractor()
df['text_feature'] = df['text'].progress_apply(lambda x: bex.extract(str(x))) # 文書の特徴ベクトル化
sim = cos_sim_matrix(np.stack(df.text_feature)) # 類似度行列
sim

類似文書の検索
ランダムに文章を一つ選び、その文章との類似度が高い順に文章を100件取り出す search 関数を作成し、検索結果を DataFrame 化してみます。
def search(n=100):
doc = df.sample(1)
doc_idx = doc.index[0]
sim_index = sim[doc_idx].argsort()[::-1]
rec_df = df.iloc[sim_index][:n]
rec_df['similarity'] = np.sort(sim[doc_idx])[::-1][:n]
return rec_df[['title', 'text', 'similarity']]
df2 = search()
df2

search 関数を実行すると以下のような DataFrame が作成されます。1番上に表示されている記事がランダムに取り出した記事で、2番目以降に1番目の記事と類似した記事が類似度順に並んでいます。similarity カラムはその記事の特徴ベクトルと先頭記事の特徴ベクトルとの類似度を表しており、先頭文書の similarity は自分自身との類似度を表すため1になっています。
検索結果の可視化
検索結果の100件の記事の内容を bi-gramとwordcloudを使って可視化してみます。
可視化には nlplot をいうライブラリを使用します。自然言語処理の可視化を簡単に行うことができ便利です。
nlplot を使用するためには記事の本文をトークナイズする必要があるため、tokenize 関数を使用して本文をトークナイズします。
def tokenize(text,):
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
wakati_ids = tokenizer.encode(str(text), return_tensors='pt')
tokens = tokenizer.convert_ids_to_tokens(wakati_ids[0].tolist())
return tokens[1:-1] #[CLS], [SEP]トークンを除く
df2['tokenized_text'] = df2['text'].progress_apply(tokenize)
npt = nlplot.NLPlot(df2, target_col='tokenized_text')
# top_nで頻出上位単語, min_freqで頻出下位単語を指定できる
stopwords = npt.get_stopword(top_n=20, min_freq=0)
# bi-gram表示
npt.bar_ngram(
title='bi-gram',
xaxis_label='word_count',
yaxis_label='word',
ngram=2,
top_n=50,
stopwords=stopwords,
)
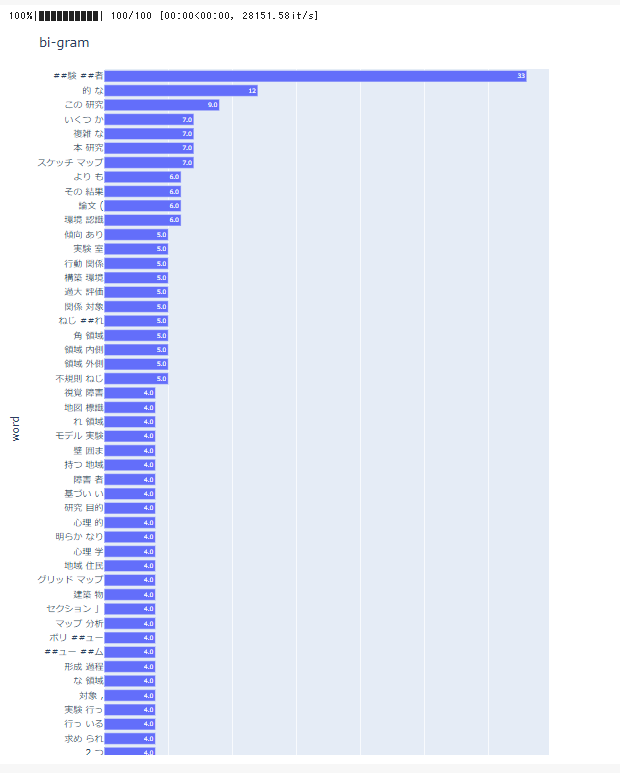
この出力結果を見ると、よく使われているワードが上位から並んでいます。
自分の調査したい分野に近い文献を探すのが本来の目的であるため、「研究、いくつか、本、スケッチ」とうのワードが上位に入ってしまうことはいい結果とは言えません。
データ抽出の方法や、より文脈や関連性の高いキーワードから出力できるように改善していく手必要があるため、今後も調査を続けていこうと考えています。
今回は探しきれなかったのですが、ここはキーポイントになってくるため時間をかけてブラッシュアップしていく必要があります。
トークナイズ後、nlplot を使用し bi-gram の出現頻度を棒グラフで表示してみます。ノイズ単語除去のため stopwords で出現頻度の多い単語の上位20個を表示結果から除くように指定しています。
npt = nlplot.NLPlot(df2, target_col='tokenized_text')
# top_nで頻出上位単語, min_freqで頻出下位単語を指定できる
stopwords = npt.get_stopword(top_n=20, min_freq=0)
# bi-gram表示
npt.bar_ngram(
title='bi-gram',
xaxis_label='word_count',
yaxis_label='word',
ngram=2,
top_n=50,
stopwords=stopwords,
)
続いてwordcloudも表示してみます。研究、分析、関係、領域という単語の大きく表示されている結果からも、論文のアブストラクトの分析という本来の目的は果たせませんでした。
こちらもグラフと同様、データ抽出の方法や、関連しないワードの削除などを検討していく必要があります。
npt.wordcloud(
max_words=100,
max_font_size=100,
colormap='tab20_r',
stopwords=stopwords,
)
###4.学習内容の考察
学習内容を振り返ると、データの抽出の仕方、データの加工の仕方次第でより目的に近い結果が出せたのではないかというのが結論となります。
また、論文のアブストラクトの検索、データ抽出においてもBeautifulSoupなどを用いて手作業でない抽出方法を探していくことで自分の日常の業務や参考文献の検索をより効率化できるのではないかと考えています。
今回は、初めての自然言語処理ということもあり控えめな内容になっていますが、今後も自分に必要な文献や資料をより効率的に分析する方法を模索していきたいと思います。