Apple Intelligence × SwiftData × RAG (Retrieval-Augmented Generation)
ローカルPCのドキュメント(PDF/Text)と直接会話でき、プライバシー完全保護のネイティブmacOSアプリ開発の記録です。
※この記事は、一部AIを活用して内容を整理しています。
はじめに
AppleがmacOS 26.0で公開したFoundationModelsフレームワークは、Apple Silicon上でローカルに動作する大規模言語モデル(LLM)への直接アクセスを提供する画期的なAPIです。
このブログでは、RAG(Retrieval-Augmented Generation)機能を搭載したFoundationLLMChatというネイティブmacOSアプリの開発全記録をお届けします。
このアプリの核心機能
「あなたのドキュメントと直接会話する」
- PDFやテキストファイルをアプリにインポート
- ドキュメントの内容に関して質問すると、LLMが文脈を理解して回答
- すべてローカル処理(インターネット不要、プライバシー完全保護)
- Apple Silicon上で高速動作
技術的なアーキテクチャ、RAGシステムの実装、実装上の課題と解決策について詳しく解説します。
プロジェクト概要
FoundationLLMChatは、あなたのドキュメントと「会話」できる次世代チャットアプリケーションです。
主要機能
| 機能 | 説明 |
|---|---|
| RAGドキュメントチャット | PDF/Textファイルをインポートして、その内容について質問・回答 |
| Apple Intelligence | macOS 26.0+のローカルLLM(インターネット不要) |
| SwiftData永続化 | 会話履歴とドキュメントを自動保存 |
| キーワードベースRAG | 独自実装の検索・文脈構築システム |
| PDF対応 | PDFKitによるテキスト抽出 |
| Markdownレンダリング | コードブロック・リスト・テーブル対応 |
技術スタック
| コンポーネント | 技術 |
|---|---|
| UIフレームワーク | SwiftUI |
| データ永続化 | SwiftData |
| LLM推論 | FoundationModels (Apple Intelligence) |
| PDF処理 | PDFKit |
| 並行処理 | async/await + MainActor |
アーキテクチャ設計
MVVMパターンの採用
本アプリでは**MVVM(Model-View-ViewModel)**アーキテクチャを採用しています。これにより、UIロジックとビジネスロジックを明確に分離し、テスト容易性と保守性を高めています。
View (SwiftUI) → ViewModel → Service → Apple Frameworks
アーキテクチャ図
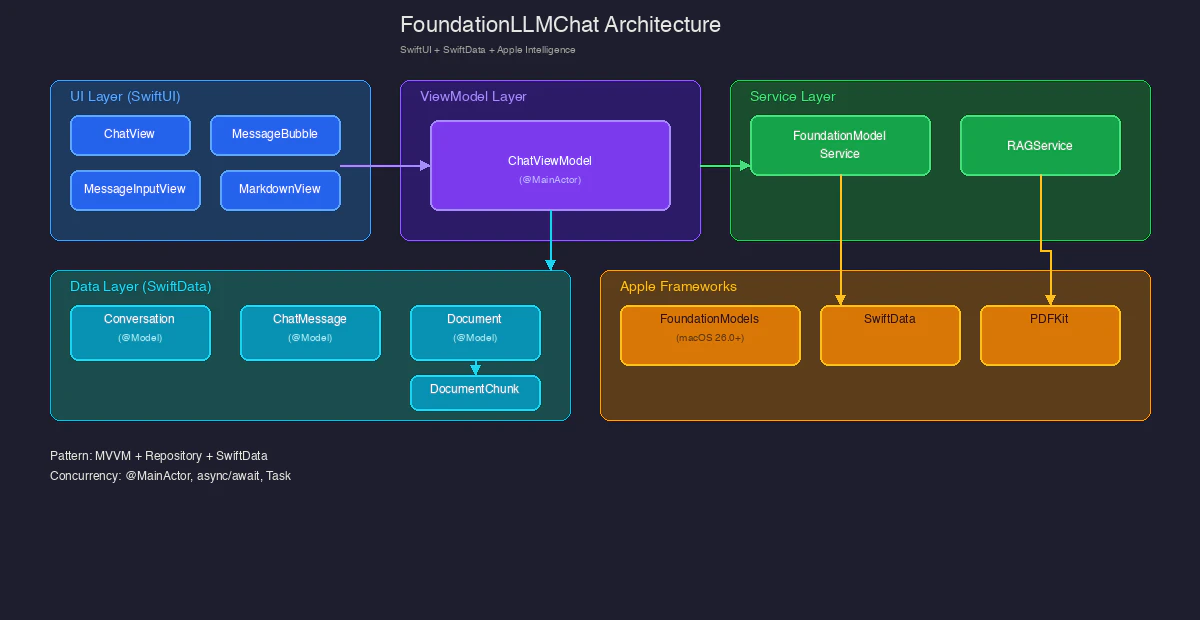
アーキテクチャ図では、以下の5つのレイヤー構成を視覚化しています。
- UI Layer (SwiftUI): ChatView, MessageBubble, MessageInputView, MarkdownView
- ViewModel Layer: ChatViewModel (MainActor) - 状態管理
- Service Layer: FoundationModelService, RAGService
- Data Layer (SwiftData): Conversation, ChatMessage, Document, DocumentChunk
- Apple Frameworks: FoundationModels, SwiftData, PDFKit
レイヤー構成
1. UI Layer (SwiftUI)
-
ChatView: メインチャット画面 -
MessageBubble: 吹き出し形式のメッセージ表示 -
MessageInputView: メッセージ入力欄 -
MarkdownView: Markdownレンダリング
2. ViewModel Layer
-
ChatViewModel(MainActor): 状態管理とビジネスロジックの調整- 会話管理
- メッセージ送受信
- RAG制御
- エラーハンドリング
3. Service Layer
-
FoundationModelService: Apple Intelligence APIラッパー -
RAGService: ドキュメント検索・文脈構築
4. Data Layer (SwiftData)
-
Conversation: 会話エンティティ -
ChatMessage: メッセージエンティティ -
Document: ドキュメントエンティティ -
DocumentChunk: チャンク化されたドキュメント断片
5. Apple Frameworks
- FoundationModels: LLM推論
- SwiftData: データ永続化
- PDFKit: PDFテキスト抽出
RAG(Retrieval-Augmented Generation)システム
RAGとは
RAGは、LLMに外部知識を提供する手法です。ユーザーの質問に関連するドキュメントの断片を検索し、プロンプトに追加することで、より正確で文脈に沿った回答を生成できます。
本アプリのRAG実装
ドキュメント処理フロー
PDF/Text → テキスト抽出 → チャンク分割 → キーワード抽出 → SwiftData保存
チャンク化アルゴリズム:
func chunkDocument(chunkSize: Int = 1000, overlap: Int = 200) -> [DocumentChunk] {
var chunks: [DocumentChunk] = []
let text = content
var startIndex = text.startIndex
while startIndex < text.endIndex {
let endIndex = text.index(startIndex, offsetBy: chunkSize, limitedBy: text.endIndex) ?? text.endIndex
let chunkText = String(text[startIndex..<endIndex])
let chunk = DocumentChunk(content: chunkText, index: chunks.count, document: self)
chunks.append(chunk)
// オーバーラップを考慮して次の開始位置を設定
if endIndex == text.endIndex {
break
}
startIndex = text.index(startIndex, offsetBy: chunkSize - overlap, limitedBy: text.endIndex) ?? text.endIndex
}
return chunks
}
検索アルゴリズム
キーワードベースの検索を実装しています。
func retrieveRelevantChunks(query: String, documents: [Document], maxChunks: Int = 3) -> [DocumentChunk] {
let queryWords = query.lowercased()
.components(separatedBy: CharacterSet.alphanumerics.inverted)
.filter { $0.count > 2 }
var scoredChunks: [(chunk: DocumentChunk, score: Int)] = []
for document in documents {
for chunk in document.chunks ?? [] {
var score = 0
let chunkContent = chunk.content.lowercased()
// 完全一致に高いスコア
if chunkContent.contains(query.lowercased()) {
score += 10
}
// 単語ごとの一致
for word in queryWords {
if chunkContent.contains(word) {
score += 1
}
}
// キーワードリストとの一致
for word in queryWords {
if chunk.keywords?.contains(word) == true {
score += 2
}
}
if score > 0 {
scoredChunks.append((chunk, score))
}
}
}
// スコア順にソートして上位を返す
let sortedChunks = scoredChunks.sorted { $0.score > $1.score }
return Array(sortedChunks.prefix(maxChunks).map { $0.chunk })
}
スコアリング体系:
- 完全一致: +10点
- 単語一致(コンテンツ内): +1点
- キーワードリスト一致: +2点
処理フロー図
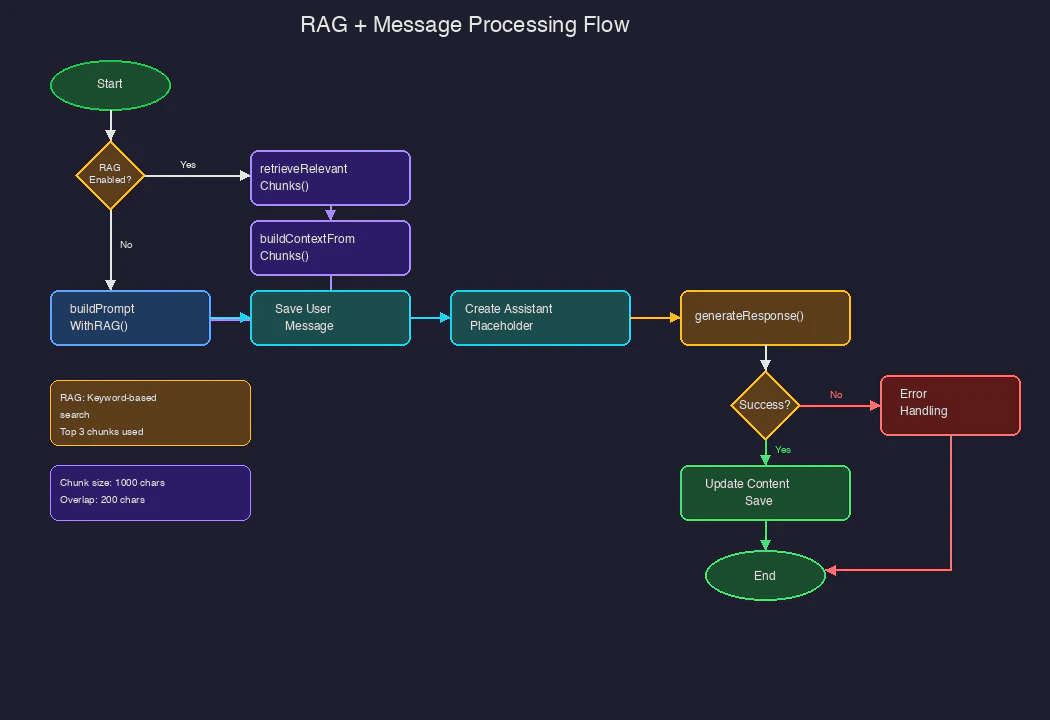
RAG + メッセージ処理のフローは以下の通りです。
- ユーザー入力を受信
- RAGが有効かチェック
- Yesの場合:retrieveRelevantChunks() → buildContextFromChunks()
- buildPromptWithRAG()でプロンプト構築
- ユーザーメッセージを保存
- アシスタントプレースホルダーを作成
- generateResponse()でLLM推論
- 成功時:コンテンツを更新・保存
- 失敗時:エラーハンドリング
ユーザーシーケンス
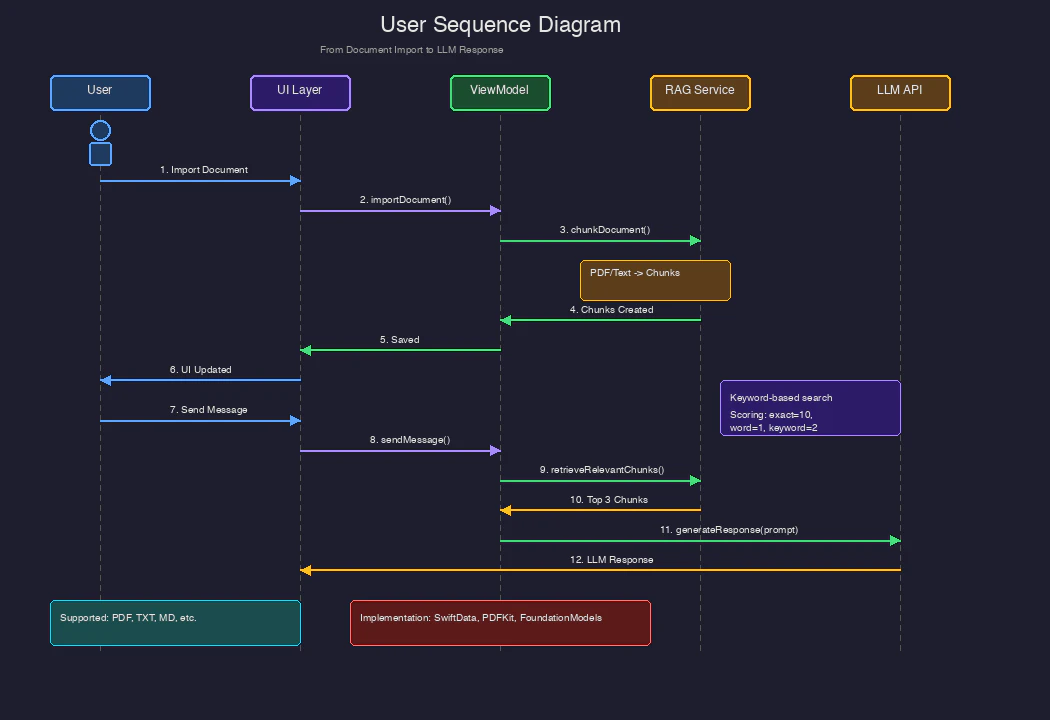
以下に、ドキュメントインポートからLLM応答取得までのシーケンスを示します。
Phase 1: ドキュメントインポート (1-6)
- ユーザーがPDF/Textファイルを選択
- UI LayerがViewModelに通知
- ViewModelがドキュメントをチャンク化
- チャンクがSwiftDataに保存
- UIが更新されドキュメント一覧を表示
Phase 2: メッセージ送信とRAG (7-12)
- ユーザーがメッセージを送信
- ViewModelがメッセージを保存
- RAG Serviceが関連チャンクを検索
- トップ3チャンクが返却
- プロンプト(RAGコンテキスト含む)をLLMに送信
- LLM応答が返却されUIに表示
実装上の課題と解決策
課題1: FoundationModelsの可用性チェック
FoundationModelsフレームワークはmacOS 26.0+とApple Siliconが必要です。
解決策: 条件付きコンパイル
#if canImport(FoundationModels)
import FoundationModels
// 実際の実装
#else
// フォールバック実装
class FoundationModelService {
@Published var availabilityStatus: ModelAvailabilityStatus = .unavailable(
reason: "FoundationModels framework not available. Requires macOS 26.0+ and Apple Silicon."
)
}
#endif
課題2: SwiftDataのモデル関係
ConversationとChatMessageの1対多関係を正しく設定する必要がありました。
解決策: RelationshipとInverseの設定
@Model
class Conversation {
@Relationship(deleteRule: .cascade, inverse: \ChatMessage.conversation)
var messages: [ChatMessage]?
}
@Model
class ChatMessage {
@Relationship
var conversation: Conversation?
}
deleteRule: .cascadeを設定することで、会話削除時に関連メッセージも自動削除されます。
課題3: メインスレッドでのUI更新
SwiftUIの@Publishedプロパティはメインスレッドでのみ更新する必要があります。
解決策: @MainActorの適用
@MainActor
class ChatViewModel: ObservableObject {
@Published var isGenerating: Bool = false
@Published var errorMessage: String?
// ...
}
課題4: 非同期ストリーミング応答の処理
FoundationModelsは現時点でストリーミング応答を直接サポートしていないため、逐次更新の実装が課題でした。
解決策: プレースホルダー方式
// まず空のプレースホルダーを作成
let assistantMessage = ChatMessage(role: .assistant, content: "", conversation: conversation)
assistantMessage.isStreaming = true
context.insert(assistantMessage)
try await context.save()
// 非同期で応答を生成
Task {
let response = try await modelService.generateResponse(for: prompt)
// 応答を更新
assistantMessage.content = response
assistantMessage.isStreaming = false
try context.save()
}
パフォーマンス最適化
RAGの最適化
チャンクサイズのチューニングについては、1000文字のチャンクサイズと200文字のオーバーラップを採用しています。これにより文脈の連続性を保ちつつ、検索精度を向上させています。
検索結果の制限については、トップ3チャンクのみを使用することで、プロンプトサイズを抑えレイテンシを削減しています。
データベース最適化
// 会話履歴は最新10件のみをプロンプトに含める
let recentMessages = conversation.sortedMessages.suffix(10)
デモ動画
FoundationLLMChatの主要機能を紹介するデモ動画です。

今後の展望
Github上で公開
現在リポジトリを準備中のため、近い将来に公開する予定です。
計画中の機能
セマンティック検索では、現在のキーワードベースから埋め込みベースの検索への移行を予定しています。CoreMLを活用したローカル埋め込み生成により、より精度の高い検索を実現する予定です。
ストリーミング対応については、FoundationModelsのストリーミングAPIが公開された際に速やかに対応していきます。
マルチモーダル対応では、画像入力への対応を検討しています。
エクスポート機能として、会話履歴のMarkdown/PDF出力も実装予定です。
まとめ
FoundationLLMChatは、Appleの最新技術(FoundationModels、SwiftData、SwiftUI)を組み合わせることで、プライバシーを完全に保ちながら強力なLLM機能を提供するアプリケーションです。
RAG機能により、ユーザーのドキュメントを文脈として活用できるため、単なるチャットアプリを超えた個人の知識ベースと対話できるツールとなっています。
学んだこと
- SwiftDataのパワー: 宣言的なデータモデリングと自動永続化により、複雑なデータ管理をシンプルに記述できます
- FoundationModelsの可能性: ローカル推論によるプライバシー保護と高速応答を両立できます
- MVVMの重要性: 状態管理を明確に分離することで、保守性が大きく向上します
- RAGの実装: キーワードベース検索でも、チューニング次第で十分実用的な精度を実現できます
参考リンク
本ブログは2026年3月に作成されました。FoundationModels APIはベータ版のため、今後変更される可能性があります。