はじめに
音声生成の勉強をしていて、深層学習ベースのボコーダー(Wavenet)を実装していきます。とはいっても、論文だけから実装すると行き詰まると思うので、ChainerのWavenetチュートリアルをtensorflowで実装していきます。(というかtensorflow以外使えないので...)
間違っている点があればご指摘下さい。
環境
Python 3.6.7
tensorflow 1.12.0 (google colabで動いているので多分最新verでも動く...はず)
librosa 0.7.0 (音声データ読み込み用)
データの前処理
今回は音声データのサンプルとして、効果音ラボにある音声を使います。
https://soundeffect-lab.info/sound/voice/mp3/line-girl1/line-girl1-ohayougozaimasu1.mp3
今回はlibrosaでデータを読み込みますが、実際にモデルを学習させる際にはtfrecordsなどを使ったほうがいいと思います。
µ-law変換
Wavenetの出力はsoftmax関数で256段階のクラス分類モデルです。一般的なCDなどの音源は16bit整数(=2^16=65536通り)であって、これを65536通りの分類モデルとして学習するのが難しいためµ-law変換を行って256段階(8bit)に変換します。また入力する波形データ x は-1≦x≦1に正規化する必要があります。コードは以下の通り。
class MuLaw:
def __init__(self, mu=256, int_type=tf.int32, float_type=tf.float32):
self.mu = float(mu-1)
self.int_type = int_type
self.float_type = float_type
def transform(self, x, name='MuLaw_Encode'):
with tf.name_scope(name):
signal = tf.sign(x)*(tf.log1p(self.mu*tf.abs(x)) / tf.log1p(self.mu))
signal = (signal + 1)/2*self.mu + 0.5
signal = tf.cast(signal, self.int_type)
return signal
def reverse(self, y, name='MuLaw_Decode'):
with tf.name_scope(name):
if y.dtype != self.float_type:
y = tf.cast(y, self.float_type)
y = 2 * (y / self.mu) - 1
y = tf.sign(y) * (1.0 / self.mu) * (tf.pow((1.0 + self.mu), tf.abs(y)) - 1.0)
return y
transformがµ-law変換でreverseが逆変換用の関数です。変換後の出力はOne-Hotベクトルにする都合でint型にしています。
元の波形
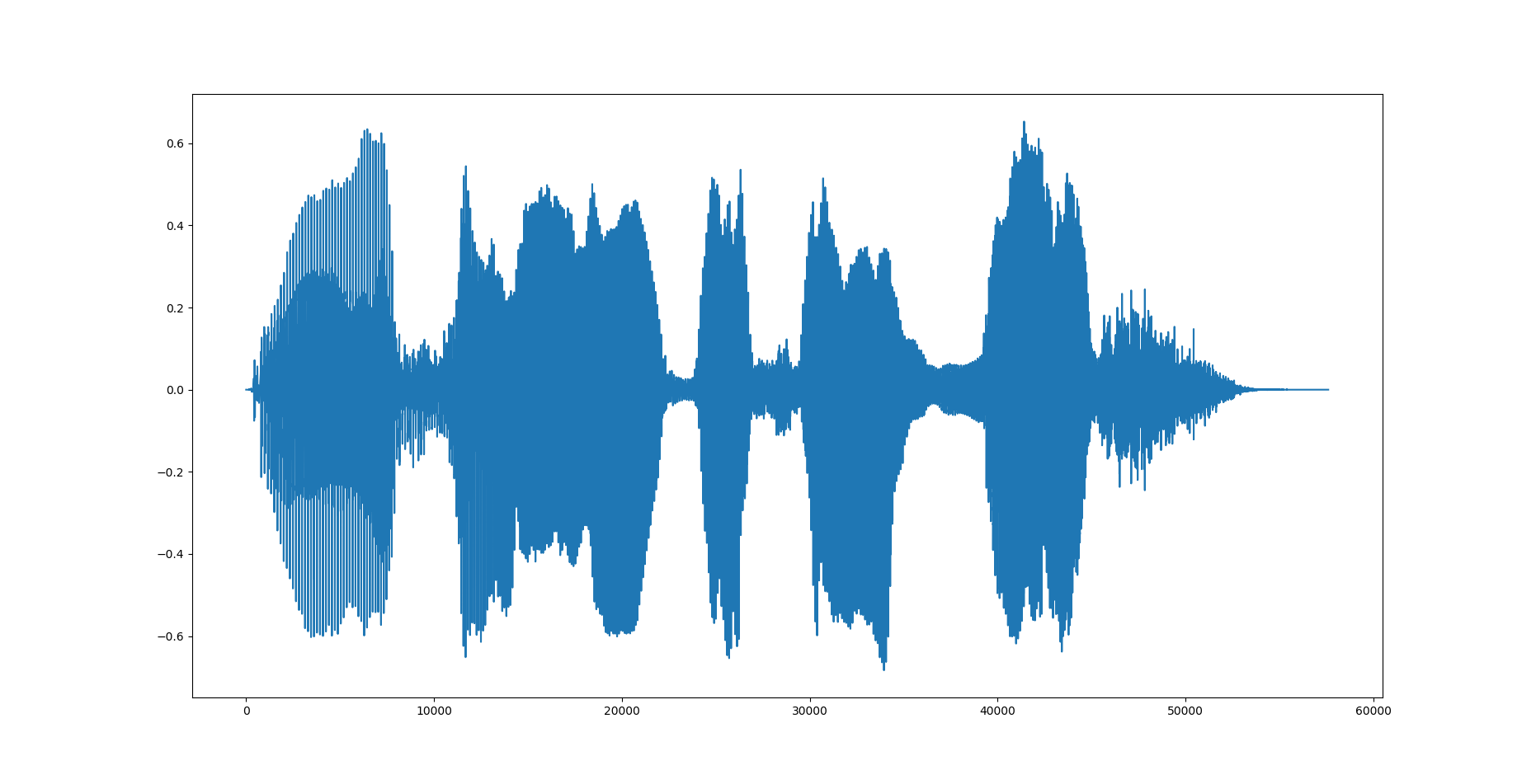
変換後
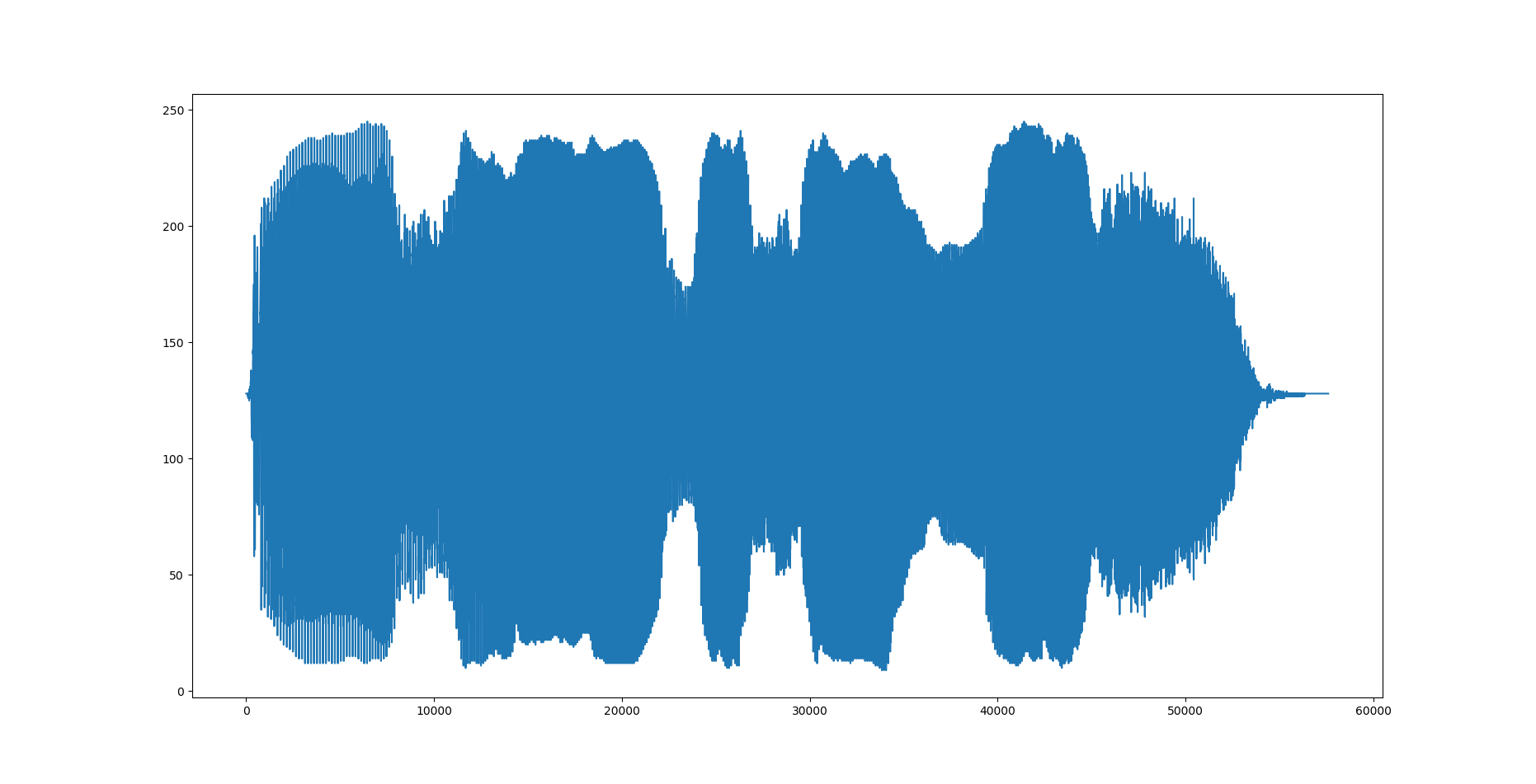
逆変換
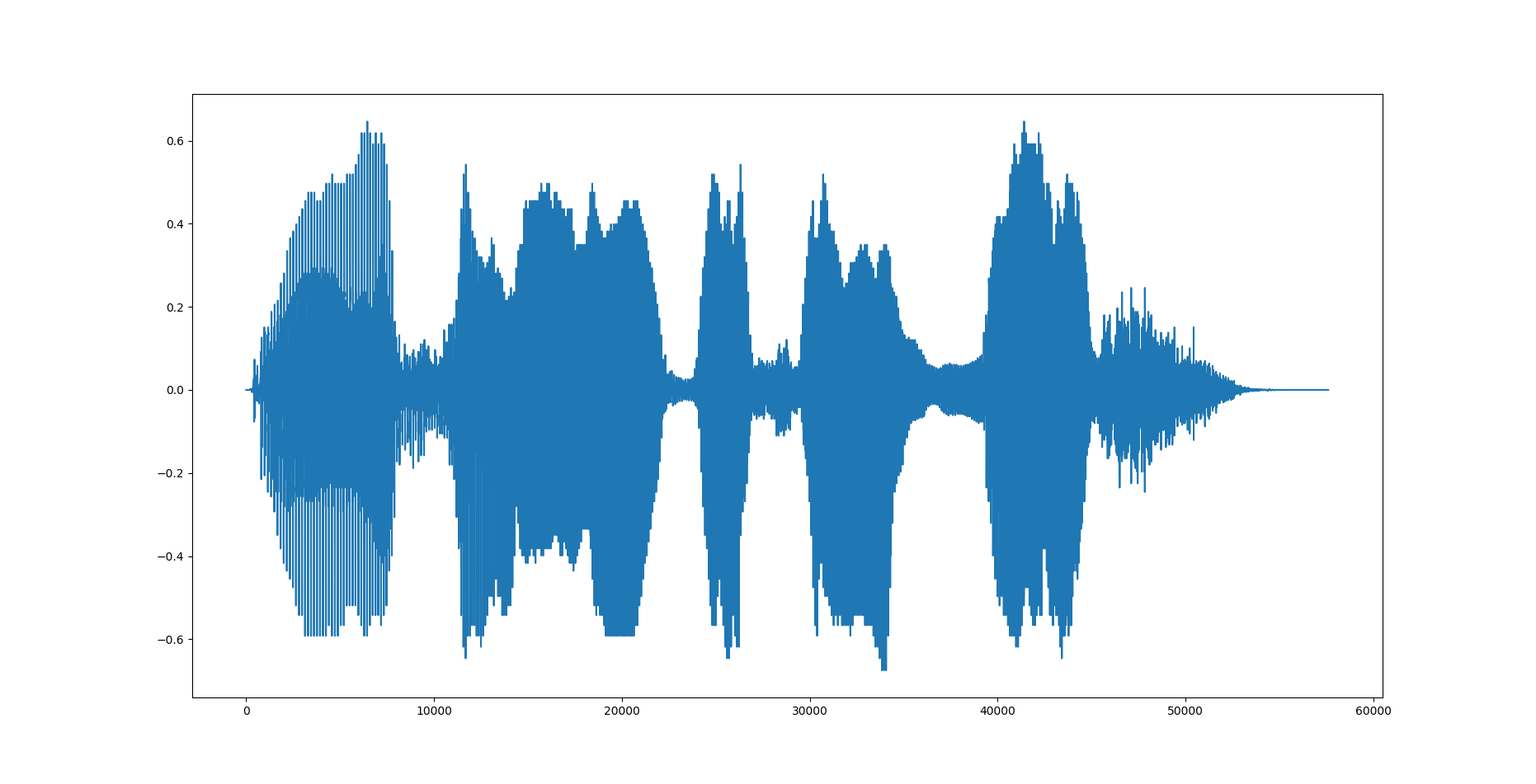
スペクトログラム
Wavenetでは生成の際に特徴量を付与できます(Global conditioningとLocal conditioning)。今回はその特徴量としてメルスペクトログラムを使用するためその処理も作成します。コードは以下の通り。
class Spectorogram:
def __init__(self, sampling_rate, nfft, hop_length):
self.sr = sampling_rate
self.nfft = nfft
self.hop_length = hop_length
def make_power_spectorogram(self, waveform, name='make_spectorogram'):
with tf.name_scope(name):
frames = signal.stft(waveform, frame_length=self.nfft, frame_step=self.hop_length, fft_length=self.nfft, pad_end=True)
power_spectorogram = tf.pow(tf.abs(frames), 2.0)
return power_spectorogram
def make_mel_spectorogram(self, waveform, mel_bins=128, name='make_mel_spectorogram'):
with tf.name_scope(name):
power_spec = self.make_power_spectorogram(waveform)
mel_matrix = signal.linear_to_mel_weight_matrix(num_mel_bins=mel_bins, num_spectrogram_bins=int(self.nfft/2+1), sample_rate=self.sr, lower_edge_hertz=0.0, upper_edge_hertz=int(self.sr/2))
mel_spec = tf.einsum('ijk,kl->ijl', power_spec, mel_matrix)
return mel_spec
def power2db(self, spec, top_db=80.0, normalize=True, name='power_to_db'):
with tf.name_scope(name):
eps = 1e-10
ref = tf.reduce_max(spec)
log_spec = 10.0 * self.log_base(tf.clip_by_value(spec, clip_value_min=eps, clip_value_max=ref), base=10.0)
log_spec -= 10.0 * self.log_base(tf.maximum(eps, ref), base=10.0)
log_spec = tf.maximum(log_spec, tf.reduce_max(log_spec)-top_db)
if normalize:
log_spec = (log_spec + (top_db / 2.0)) / (top_db / 2.0)
return log_spec
def log_base(self, x, base=10.0):
assert base > 0 and (type(base) in [type(tf.Tensor), float]), 'base must be floating number and larger than 0'
with tf.name_scope('log_base_%d'%base):
y = tf.log(x)
d = tf.log(base)
return y/d
スペクトログラムを作成する際の短時間フーリエ変換はtf.contrib.signalの関数を利用しています。tensorflowのver1.14ではtf.contribの使用が非推奨となっていたため、tf.signalモジュールを使用する必要があると思われます。
スペクトログラムをメル尺度に変換するための行列(メルフィルタバンク)はlinear_to_mel_weight_matrixで生成できます。tensorflowでは行列計算をする関数としてtensordotやmatmulなどがありますが、ここでeinsumを使用しているのは私の環境では他では返り値のshapeがNoneになったためeinsumを使いました。
power2dbでは周波数からデシベルへの変換?(librosaの実装を丸写ししただけなのでよく理解していない)を行っています。この変換式は、
y_{db}=10\log_{10}{y}
でtensorflowでは対数関数が自然対数しかなかったためその変換を行うためlog_baseを使っています。以下の画像が生成したメルスペクトログラムです。nfft=1024, hop_length=256で生成しました。
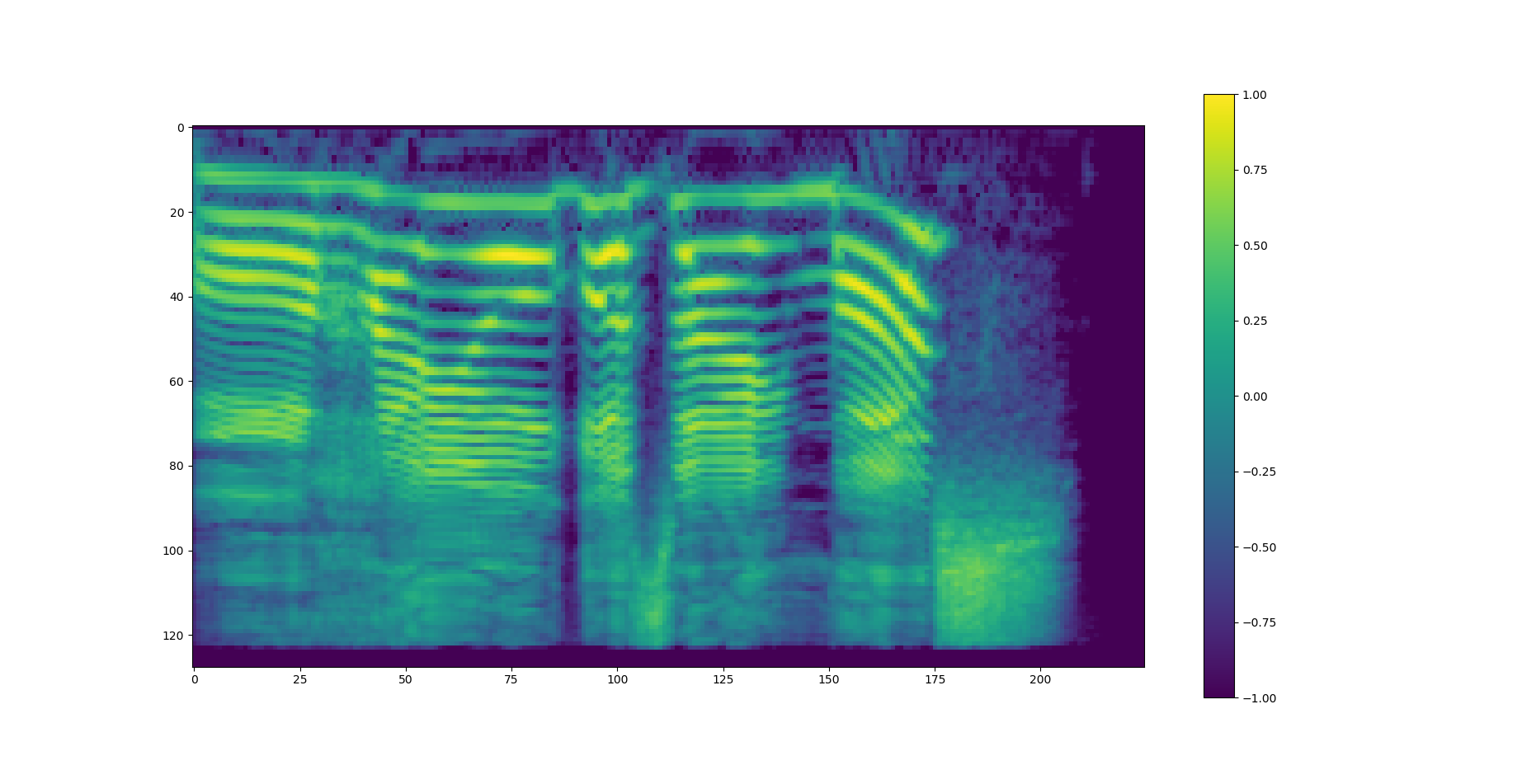
というわけで今回はここまでです。