pythonをサポートしている並列分散ライブラリの1つであるDaskを使ってみたので処理速度の比較などメモ。
この記事はdask 0.16.0 documentationを参考にしています。
実行環境
Python version : 3.6.1
compiler : GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.57)
system : Darwin
release : 16.7.0
machine : x86_64
processor : i386
CPU count : 4
interpreter: 64bit
そもそもDaskって何ですか ??
Daskは、pythonを用いた分析のための柔軟な並列計算ライブラリです。numpyやpandasのAPIをバックエンドとして利用しており、並列計算/分散処理を行うことが可能です。また、Daskではマッピングされたタスクスケジューラのノードごとに処理を行うため、常にメモリ上に全データが乗っている必要性がなく、メモリに収まりきらないデータに対しても処理できる構造になっています。
(http://sinhrks.hatenablog.com/entry/2015/09/24/222735 を参照)
共通のインタフェース
Daskではpandasやnumpyのような有名ライブラリと同じような書き方で処理を行うことが出来ます。
Pandas
import pandas as pd
df = pd.read_csv('2015-01-01.csv')
df.groupby(df.user_id).value.mean()
import dask.dataframe as dd
df = dd.read_csv('2015-*-*.csv')
df.groupby(df.user_id).value.mean().compute()
csvファイルを読み取りidごとに平均値を計算する処理。
ほぼpandasと同じような書き方が出来ています。
numpy
import numpy as np
f = h5py.File('myfile.hdf5')
x = np.array(f['/small-data'])
x - x.mean(axis=1)
import dask.array as da
f = h5py.File('myfile.hdf5')
x = da.from_array(f['/big-data'],chunks=(1000, 1000))
x - x.mean(axis=1).compute()
こちらも取得データに対して平均値を計算する処理を行なっています。
daskの場合は処理を行うのにcompute()メソッドが使用されています。
いつ使えばいいの ?
Daskはデータがメモリ内に収まりきらない場合を想定されて開発されたライブラリです。そのため、メモリ内に処理が収まりきる場合は通常のようにpandasやnumpyを使用した方がいいです。これはDaskがタスクスケジューラのマッピングを行う際に微小時間ではありますがオーバーヘッドを発生させるため処理時間が遅くなってしまうためです。また、あまりにも大規模なデータセットの場合はsparkやhadoopなどの並列計算ライブラリを使用する方が良いです。
Daskを使った簡単な並列処理を書いてみる。
加算、インクリメント、合計をそれぞれ関数をして用意する。
sleep関数を入れている理由は処理時間をわかりやすくするためです。
from time import sleep
def slowadd(x,y):
""" addをスローで行う """
sleep(1)
return x+y
def slowinc(x):
""" incrementをスローで行う """
sleep(1)
return x+1
def slowsum(L):
""" sumをスローで行う """
sleep(1)
return sum(L)
Daskを使用しない場合
上記の関数を利用してリストから合計値を求める計算を書いてみます。
%%time
data = [1,2,3]
A = [slowinc(i) for i in data]
B = [slowadd(a,10) for a in A]
C = [slowadd(b,100) for b in B]
score = slowsum(A) + slowsum(B) + slowsum(C)
print(score)
387
CPU times: user 1.52 ms, sys: 1.41 ms, total: 2.93 ms
Wall time: 12 s
Daskを使用しない場合で12sの計算時間がかかる。
Daskを用いて先ほどの関数を並列処理させる
Daskのdelayedメソッドを利用して並列計算をさせてみます。
Daskではdelayedメソッドの名前の通り遅延評価を行います。
delayedメソッドでは与えられた計算式に対してタスクスケジューラを作成します。しかし、ここでは計算自体は行わずマッピングのみを行います。計算はユーザーが意図したタイミングで行うことが可能です。
from dask import delayed
%%time
data = [1,2,3]
A = [delayed(slowinc)(i) for i in data]
B = [delayed(slowadd)(b,10) for b in A]
C = [delayed(slowadd)(c,100) for c in B]
score = delayed(slowsum)(A) + delayed(slowsum)(B) + delayed(slowsum)(C)
print(score)
Delayed('add-c46a2efa72a0682c848925b6e4d9b100')
CPU times: user 2.16 ms, sys: 1.08 ms, total: 3.24 ms
Wall time: 2.82 ms
計算時間は2.82msと極端に小さい値になったが、ここでは計算処理を行なっておらず、タスクスケジューラのマッピングを行なっている。
マッピングされた結果はvisualizeメソッドで表示することが出来る。
score.visualize()
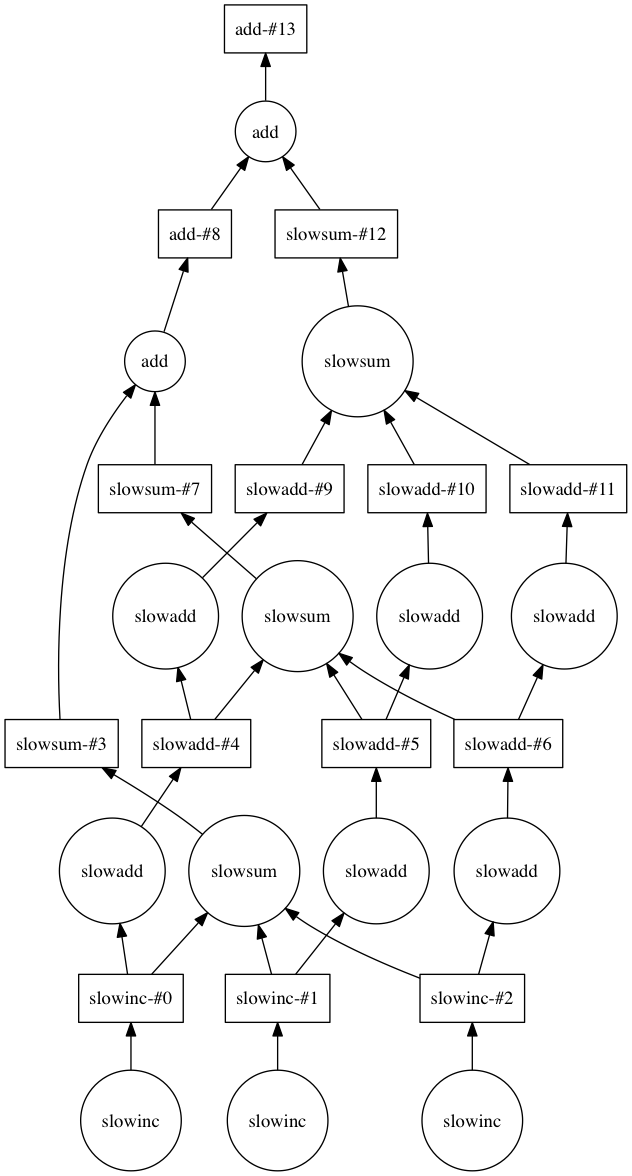
このようにDaskではユーザーが意識せずに並列処理マッピングを行なってくれる。
計算処理はcomputeメソッドを使用して行う。
%%time
score.compute()
CPU times: user 9.87 ms, sys: 3.82 ms, total: 13.7 ms
Wall time: 4.02 s
処理時間は4.02sとなった。
Daskを使用しない例では12sかかっていたため3倍ほど高速になっている。