Section1 勾配消失問題について

z= t^2 \\
t = x + y \\
\frac{dz}{dx} = \frac{dz}{dt} \frac{dt}{dx}= 2t × 1= 2(x+y)
勾配消失問題
- 誤差逆伝播法が下位層に進んでいくに連れて、勾配がどんどん緩やかになっていく
- そのため、勾配降下法による、更新では下位層のパラメータはほとんど変わらず、訓練は最適値に収束しなくなる
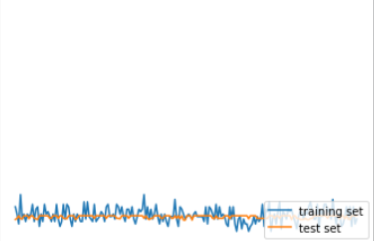
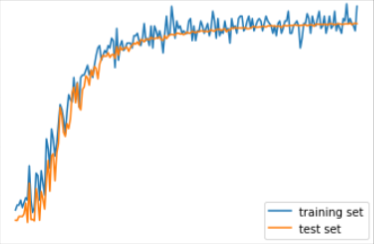
- 上2つの図は横軸が学習回数、縦軸が正解率
- 本来は1つ目の図のように学習を重ねると正解率が上がっていく
- しかし勾配消失問題が起きると2つ目の図のようになる
勾配消失問題の解決策
- 活性化関数の選択
- 重みの初期値設定
- バッチ正規化
活性化関数の選択
- シグモイド関数は微分したときの最大値が025
- 微分の連鎖律は、中間層が多くなればなる程0.25の掛け算が多くなり重みの変化が伝わらなくなり学習率が上がらない
- 改善方法として、RelU関数に切り替える
重みの初期値設定
Xavier
-
Xavierの初期値を設定する際の活性化関数
- ReLU関数
- シグモイド関数
- 双曲線正接関数
-
初期値の設定方法
- 重みの要素を、前の層のノード数の平方根で除算した値
He
-
Heの初期値を設定する際の活性化関数
- ReLU関数
-
初期値の設定方法
- 重みの要素を、前の層のノード数の平方根で除算した値に対し$\sqrt{2}$をかけ合わせた値

- 全ての値が同じ値で出力層まで伝わるため、チューニングが正しく行えなくなる
- 重みの意味がなくなる
バッチ正規化
- ミニバッチ単位で、入力値のデータの偏りを抑制する手法
- バッチ正規化の使い所は?
- 活性化関数に値を渡す前後に、バッチ正規化の処理を孕んだ層を加える
- バッチ正規化層への入力値は$u_l = w_lz_{l-1}+b_l$

- 勾配消失が起きづらくなる
- 計算時間が短縮される
実装演習
活性化関数にシグモイド関数を用いたとき
import numpy as np
from common import layers
from collections import OrderedDict
from common import functions
from data.mnist import load_mnist
import matplotlib.pyplot as plt
# mnistをロード
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True, one_hot_label=True)
train_size = len(x_train)
print("データ読み込み完了")
# 重み初期値補正係数
wieght_init = 0.01
# 入力層サイズ
input_layer_size = 784
# 中間層サイズ
hidden_layer_1_size = 40
hidden_layer_2_size = 20
# 出力層サイズ
output_layer_size = 10
# 繰り返し数
iters_num = 2000
# ミニバッチサイズ
batch_size = 100
# 学習率
learning_rate = 0.1
# 描写頻度
plot_interval=10
# 初期設定
def init_network():
network = {}
network['W1'] = wieght_init * np.random.randn(input_layer_size, hidden_layer_1_size)
network['W2'] = wieght_init * np.random.randn(hidden_layer_1_size, hidden_layer_2_size)
network['W3'] = wieght_init * np.random.randn(hidden_layer_2_size, output_layer_size)
network['b1'] = np.zeros(hidden_layer_1_size)
network['b2'] = np.zeros(hidden_layer_2_size)
network['b3'] = np.zeros(output_layer_size)
return network
# 順伝播
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
hidden_f = functions.sigmoid
u1 = np.dot(x, W1) + b1
z1 = hidden_f(u1)
u2 = np.dot(z1, W2) + b2
z2 = hidden_f(u2)
u3 = np.dot(z2, W3) + b3
y = functions.softmax(u3)
return z1, z2, y
# 誤差逆伝播
def backward(x, d, z1, z2, y):
grad = {}
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
hidden_d_f = functions.d_sigmoid
last_d_f = functions.d_softmax_with_loss
# 出力層でのデルタ
delta3 = last_d_f(d, y)
# b3の勾配
grad['b3'] = np.sum(delta3, axis=0)
# W3の勾配
grad['W3'] = np.dot(z2.T, delta3)
# 2層でのデルタ
delta2 = np.dot(delta3, W3.T) * hidden_d_f(z2)
# b2の勾配
grad['b2'] = np.sum(delta2, axis=0)
# W2の勾配
grad['W2'] = np.dot(z1.T, delta2)
# 1層でのデルタ
delta1 = np.dot(delta2, W2.T) * hidden_d_f(z1)
# b1の勾配
grad['b1'] = np.sum(delta1, axis=0)
# W1の勾配
grad['W1'] = np.dot(x.T, delta1)
return grad
# パラメータの初期化
network = init_network()
accuracies_train = []
accuracies_test = []
# 正答率
def accuracy(x, d):
z1, z2, y = forward(network, x)
y = np.argmax(y, axis=1)
if d.ndim != 1 : d = np.argmax(d, axis=1)
accuracy = np.sum(y == d) / float(x.shape[0])
return accuracy
for i in range(iters_num):
# ランダムにバッチを取得
batch_mask = np.random.choice(train_size, batch_size)
# ミニバッチに対応する教師訓練画像データを取得
x_batch = x_train[batch_mask]
# ミニバッチに対応する訓練正解ラベルデータを取得する
d_batch = d_train[batch_mask]
z1, z2, y = forward(network, x_batch)
grad = backward(x_batch, d_batch, z1, z2, y)
if (i+1)%plot_interval==0:
accr_test = accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
# パラメータに勾配適用
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
network[key] -= learning_rate * grad[key]
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()

- 全然正解率が向上していないのが分かる
活性化関数にReLU関数を用いたとき
- 下記の部分だけを変更する
hidden_f = functions.sigmoid
- 変更後
hidden_f = functions.relu
- しっかり、正解率があがってる!
シグモイド関数にXavierを使った場合
- 最初のコードの下記の部分を修正する
network['W1'] = wieght_init * np.random.randn(input_layer_size, hidden_layer_1_size)
network['W2'] = wieght_init * np.random.randn(hidden_layer_1_size, hidden_layer_2_size)
network['W3'] = wieght_init * np.random.randn(hidden_layer_2_size, output_layer_size)
- 修正後
network['W1'] = np.random.randn(input_layer_size, hidden_layer_1_size) / (np.sqrt(input_layer_size))
network['W2'] = np.random.randn(hidden_layer_1_size, hidden_layer_2_size) / (np.sqrt(hidden_layer_1_size))
network['W3'] = np.random.randn(hidden_layer_2_size, output_layer_size) / (np.sqrt(hidden_layer_2_size))

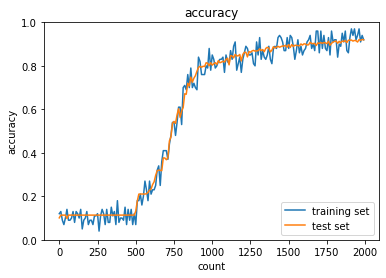
- これもしっかり正解率があがってるのがわかる!
ReLu関数にHeを使った場合
- 関数を先ほど同様ReLUに変更したあと、下記の部分を修正する
network['W1'] = wieght_init * np.random.randn(input_layer_size, hidden_layer_1_size)
network['W2'] = wieght_init * np.random.randn(hidden_layer_1_size, hidden_layer_2_size)
network['W3'] = wieght_init * np.random.randn(hidden_layer_2_size, output_layer_size)
- 修正後
network['W1'] = np.random.randn(input_layer_size, hidden_layer_1_size) / np.sqrt(input_layer_size) * np.sqrt(2)
network['W2'] = np.random.randn(hidden_layer_1_size, hidden_layer_2_size) / np.sqrt(hidden_layer_1_size) * np.sqrt(2)
network['W3'] = np.random.randn(hidden_layer_2_size, output_layer_size) / np.sqrt(hidden_layer_2_size) * np.sqrt(2)
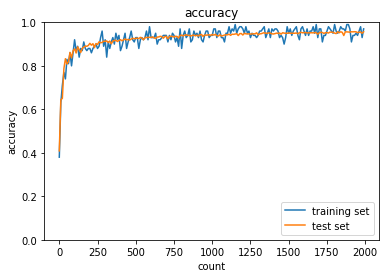
- これも同じく正解率があがっていってる!
Section2 学習率最適化手法について
- 勾配降下法の学習率とは?
- 大きすぎる場合、最適地にたどり着かず発散してしまう可能性がある
- 小さすぎる場合、最適地にはたどりつくが、たどり着くまで時間がかかる
学習率の決め方
- 初期の学習率設定方法の指針
- 初期の学習率を大きく設定し、徐々に学習率を小さくしていく
- パラメータ毎に学習率を可変させる
- 学習率最適化手法を利用して学習率を最適化
- 学習率最適化手法には下記がある
- モメンタム
- AdaGrad
- RMSProp
- Adam

-
モメンタム
- 局所的最適解にはならず、大域的最適解となる
-
AdaGrad
- 勾配の緩やかな斜面に対して、最適値に近づける
-
RMSProp
- ハイパーパラメータの調整が必要な場合が少ない
-
それぞれの詳細は下記にまとめる
モメンタム


- メリット
- 局所的最適解にはならず、大域的最適解となる
- 谷間についてから最も低い位置(最適値)にいくまでの時間が早い
AdaGrad


- メリット
- 勾配の緩やかな斜面に対して、最適値に近づける
- 課題として学習率が徐々に小さくなるので、鞍点問題を引き起こす事があった
RMSProp


- メリット
- 局所的最適解にはならず、大域的最適解となる
- ハイパーパラメータの調整が必要な場合が少ない
Adam
-
メンタムの過去の勾配の指数関数的減衰平均とRMSPropの過去の勾配の2乗の指数関数的減衰平均をそれぞれ孕んだ最適化アルゴリズム
-
メリット
- モメンタムおよびRMSPropのメリットを孕んだアルゴリズムであること
実装演習
SGDで学習
# データの読み込み
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True, one_hot_label=True)
print("データ読み込み完了")
use_batchnorm = False
network = MultiLayerNet(input_size=784, hidden_size_list=[40, 20], output_size=10, activation='sigmoid', weight_init_std=0.01,
use_batchnorm=use_batchnorm)
iters_num = 1000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.01
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
# 勾配
grad = network.gradient(x_batch, d_batch)
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
if (i + 1) % plot_interval == 0:
accr_test = network.accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = network.accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()
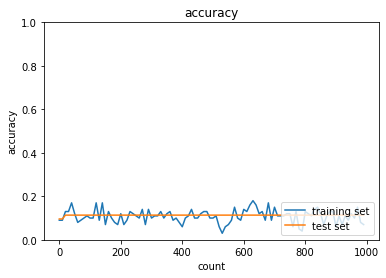
- うまく学習できていなさそう。。
モメンタムで学習
# データの読み込み
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True, one_hot_label=True)
print("データ読み込み完了")
use_batchnorm = False
network = MultiLayerNet(input_size=784, hidden_size_list=[40, 20], output_size=10, activation='sigmoid', weight_init_std=0.01,
use_batchnorm=use_batchnorm)
iters_num = 1000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.3
# 慣性
momentum = 0.9
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
# 勾配
grad = network.gradient(x_batch, d_batch)
if i == 0:
v = {}
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
if i == 0:
v[key] = np.zeros_like(network.params[key])
v[key] = momentum * v[key] - learning_rate * grad[key]
network.params[key] += v[key]
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
if (i + 1) % plot_interval == 0:
accr_test = network.accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = network.accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()
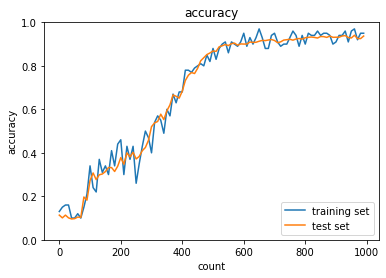
- これはしっかり学習できてそう
AdaGradで学習
# データの読み込み
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True, one_hot_label=True)
print("データ読み込み完了")
use_batchnorm = False
network = MultiLayerNet(input_size=784, hidden_size_list=[40, 20], output_size=10, activation='sigmoid', weight_init_std=0.01,
use_batchnorm=use_batchnorm)
iters_num = 1000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
# 勾配
grad = network.gradient(x_batch, d_batch)
if i == 0:
h = {}
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
if i == 0:
h[key] = np.full_like(network.params[key], 1e-4)
else:
h[key] += np.square(grad[key])
network.params[key] -= learning_rate * grad[key] / (np.sqrt(h[key]))
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
if (i + 1) % plot_interval == 0:
accr_test = network.accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = network.accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()
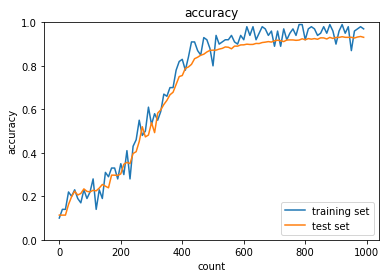
- これもしっかり学習できてそう
RMSpropで学習
# データの読み込み
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True, one_hot_label=True)
print("データ読み込み完了")
use_batchnorm = False
network = MultiLayerNet(input_size=784, hidden_size_list=[40, 20], output_size=10, activation='sigmoid', weight_init_std=0.01,
use_batchnorm=use_batchnorm)
iters_num = 1000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.01
decay_rate = 0.99
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
# 勾配
grad = network.gradient(x_batch, d_batch)
if i == 0:
h = {}
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
if i == 0:
h[key] = np.zeros_like(network.params[key])
h[key] *= decay_rate
h[key] += (1 - decay_rate) * np.square(grad[key])
network.params[key] -= learning_rate * grad[key] / (np.sqrt(h[key]) + 1e-7)
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
if (i + 1) % plot_interval == 0:
accr_test = network.accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = network.accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()
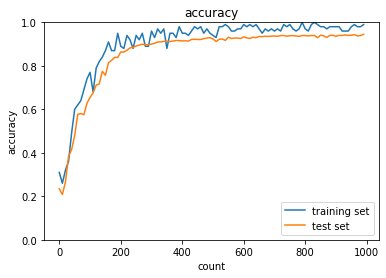
- これもしっかり学習できてそう
Adamで学習
# データの読み込み
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True, one_hot_label=True)
use_batchnorm = False
network = MultiLayerNet(input_size=784, hidden_size_list=[40, 20], output_size=10, activation='sigmoid', weight_init_std=0.01,
use_batchnorm=use_batchnorm)
iters_num = 1000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.01
beta1 = 0.9
beta2 = 0.999
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
# 勾配
grad = network.gradient(x_batch, d_batch)
if i == 0:
m = {}
v = {}
learning_rate_t = learning_rate * np.sqrt(1.0 - beta2 ** (i + 1)) / (1.0 - beta1 ** (i + 1))
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
if i == 0:
m[key] = np.zeros_like(network.params[key])
v[key] = np.zeros_like(network.params[key])
m[key] += (1 - beta1) * (grad[key] - m[key])
v[key] += (1 - beta2) * (grad[key] ** 2 - v[key])
network.params[key] -= learning_rate_t * m[key] / (np.sqrt(v[key]) + 1e-7)
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
if (i + 1) % plot_interval == 0:
accr_test = network.accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = network.accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()

- これもしっかり学習できてそう
Section3 過学習について
- 特定の訓練データに対して、特化して学習すること
- つまり、テスト誤差と訓練誤差とで学習曲線が乖離すること
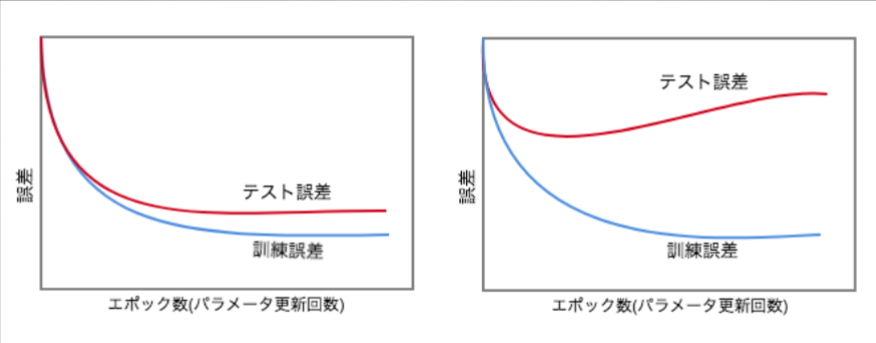
- 過学習の原因として考えられるものに下記がある
- パラメータ数が多い
- パラメータの値が適切でない
- ノードが多い
- まとめてネットワーク(層数、パラメータ数、ノード数...)の自由度が高いと言える
正則化
-
ネットワークの自由度(層数、パラメータ数、ノード数...)を制約すること
-
正則化手法を利用して過学習を抑制する

解答:a
過学習の原因
- 重みが大きい値をとることで、過学習が発生することがある
- 学習させていくと、重みにばらつきが発生する
- 重みが大きい値は、学習において重要な値であり、重みが大きいと過学習が起こる
過学習の解決策
- 誤差に対して、正則化項を加算することで、重みを抑制する
- 過学習がおこりそうな重みの大きさ以下で重みをコントロールし、重みの大きさにばらつきを出す必要がある
L1正則化、L2正則化
- 誤差関数に、pノルムを加える
E_n(w)+ \frac{1}{p} \lambda ||x||_p
- pノルムは下記
||x||_p=(|x_1|^p+...+|x_n|^p)^\frac{1}{p}
- p=1の場合、L1正則化
- p=2の場合、L2正則化
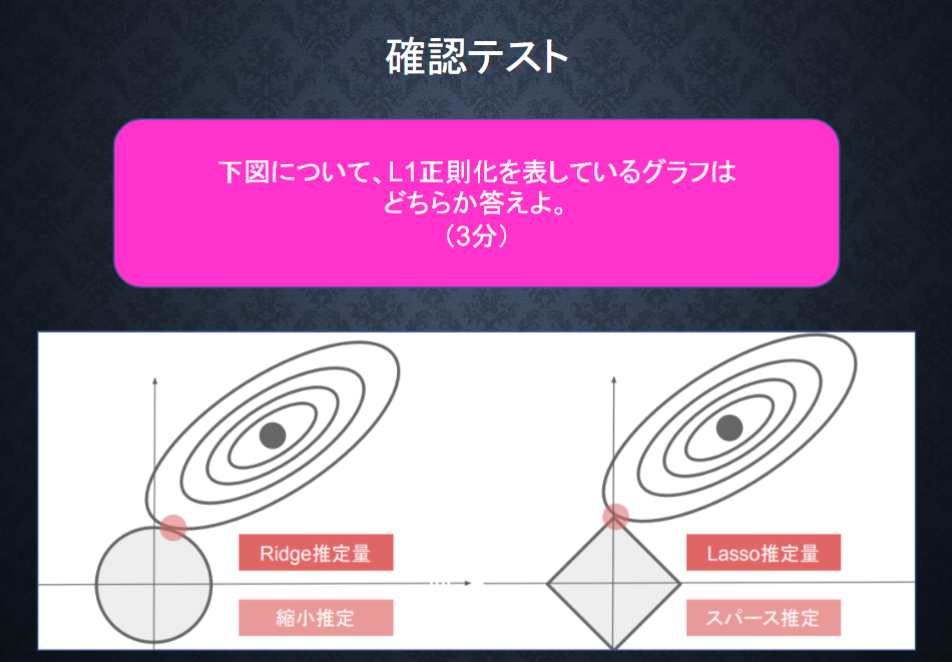
- 右がL2正則化で左がL1正則化
ドロップアウト
- 過学習の課題としてノードが多いということがあげられる
- ドロップアウトとはランダムにノードを削除して学習させられることである
- データ量を変化させずに、異なるモデルを学習させていると解釈できる
実装演習
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True)
print("データ読み込み完了")
# 過学習を再現するために、学習データを削減
x_train = x_train[:300]
d_train = d_train[:300]
network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100], output_size=10)
optimizer = optimizer.SGD(learning_rate=0.01)
iters_num = 1000
train_size = x_train.shape[0]
batch_size = 100
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
grad = network.gradient(x_batch, d_batch)
optimizer.update(network.params, grad)
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
if (i+1) % plot_interval == 0:
accr_train = network.accuracy(x_train, d_train)
accr_test = network.accuracy(x_test, d_test)
accuracies_train.append(accr_train)
accuracies_test.append(accr_test)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()

Section4 畳み込みニューラルネットワークの概念
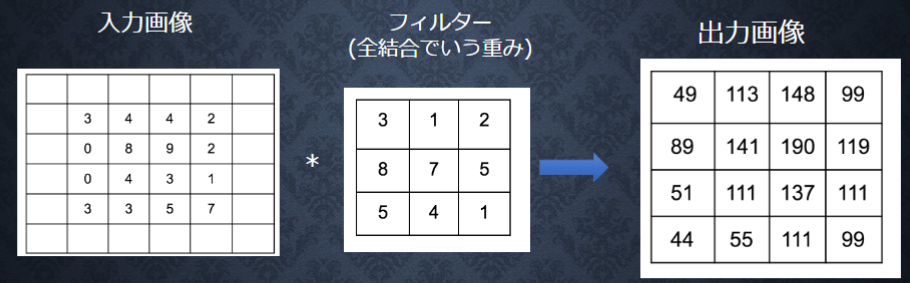
畳み込み層
- 3次元の空間情報も学習できるような層
- 画像の場合、縦、横、チャンネルの3次元のデータをそのまま学習し、次に伝えることができる

-
出力画像は左上が$3×3+4×1+4×2+0×8+8×7+9×5+0×5+4×4+3×1 = 141$となる
-
他も同じように計算すると右上が190、左下が101、右下が137となる
-
上記のような計算を畳み込み演算という(画像処理でいうフィルター演算に相当)
-
畳み込み演算は入力データに対して、フィルターのウィンドウを一定の間隔でスライドさせながら適用する
- 赤枠を移動させていくイメージ
バイアス
- フィルター適用後のデータに加算される
- バイアスの値は1つだけ
- 先ほどの式にバイアスも入ると考えると各値に$+b$を行う
- バイアスが4だとすると
- 左上が145、右上が194、左下が105、右下が141となる
パディング
- 畳み込み層の処理を行う前に入力データの周りに固定のデータを埋めること
※空白は0とする
ストライド
- フィルターを適用する位置の間隔のこと
- 最初の図がストライドが1のとき
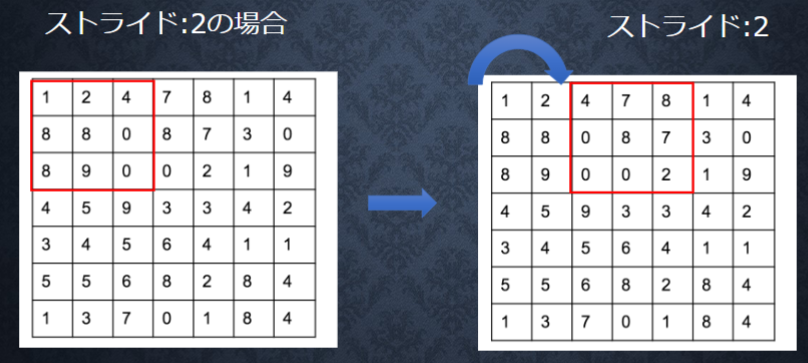
チャンネル
- 奥行方向
- 入力データの数

- 上記は3チャンネルの場合
プーリング層
- 縦・横方向の空間を小さくする演算
- 例えば、3×3の領域を一つの要素に集約するような処理を行い、空間サイズを小さくする

-
上記をMAX値をとるとすると
- 左上:9
- 左下:9
- 右上:9
- 右下:9
-
この画像だとどこをとっても最大値は9になってしまった。。。


- グレー部分はパディングで追加したもの
- 出力は7×7となる
実装演習
'''
input_data: 入力値
filter_h: フィルターの高さ
filter_w: フィルターの横幅
stride: ストライド
pad: パディング
'''
def im2col(input_data, filter_h, filter_w, stride=1, pad=0):
# N: number, C: channel, H: height, W: width
N, C, H, W = input_data.shape
# 切り捨て除算
out_h = (H + 2 * pad - filter_h)//stride + 1
out_w = (W + 2 * pad - filter_w)//stride + 1
img = np.pad(input_data, [(0,0), (0,0), (pad, pad), (pad, pad)], 'constant')
col = np.zeros((N, C, filter_h, filter_w, out_h, out_w))
for y in range(filter_h):
y_max = y + stride * out_h
for x in range(filter_w):
x_max = x + stride * out_w
col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride]
col = col.transpose(0, 4, 5, 1, 2, 3) # (N, C, filter_h, filter_w, out_h, out_w) -> (N, filter_w, out_h, out_w, C, filter_h)
col = col.reshape(N * out_h * out_w, -1)
return col
# im2colの処理確認
input_data = np.random.rand(2, 1, 4, 4)*100//1 # number, channel, height, widthを表す
print('========== input_data ===========\n', input_data)
print('==============================')
filter_h = 3
filter_w = 3
stride = 1
pad = 0
col = im2col(input_data, filter_h=filter_h, filter_w=filter_w, stride=stride, pad=pad)
print('============= col ==============\n', col)
print('==============================')

Section5 最新のCNN
AlexNet
- 畳み込み層とプーリング層を重ねて最後に全結合層を経由して結果を出力する
- 基本的な構造はLeNetと構造は大きく変わらない
- LeNetと異なる点は下記
- 活性化関数にReLUを用いる
- LRNという局所的正規化を行う層を用いる
- ドロップアウトを使用する
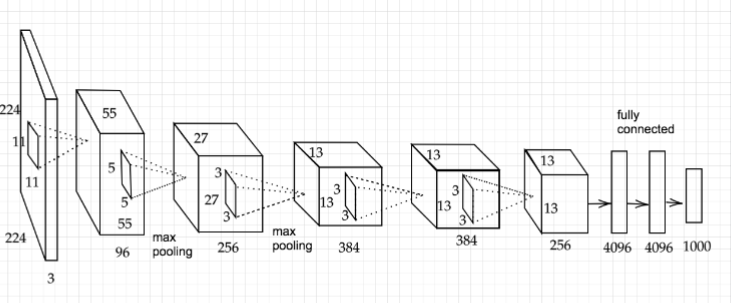
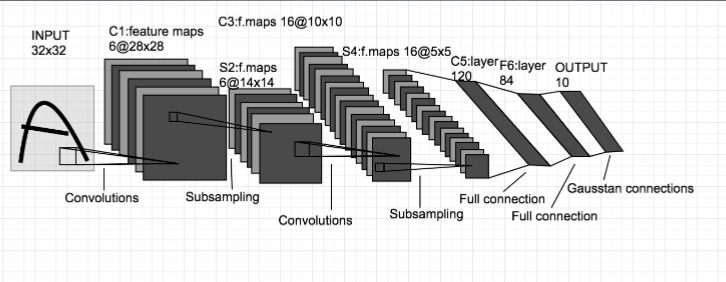
LeNetってなに?
- AlexNetの説明でLeNetと構造は変わらないと記載したが、そもそもLeNetとは何か?
- 畳み込み層とプーリング層を連続して行い、最後に全結合層を経て結果が出力される
- AlexNetと異なる点は下記
- 活性化関数にシグモイド関数を用いる
- 中間データのサイズ縮小を行っている
実装演習
- Section2の実装演習に包含
参考文献
ゼロから作るDeep Learning