この記事で扱うこと
- AIエージェントが「技術的に正常」でも「業務的に誤った判断」をする問題
- 従来のアプリケーション監視(レイテンシ、エラーレート)では捉えられないエージェントの意思決定の追跡方法
- ログ設計(トリガ→プロンプト→取得コンテキスト→モデル応答→ツール呼び出し→ポリシー評価→承認→最終アクション)
- 3層のメトリクス設計(技術・品質・ビジネス)
- ドリフト検知とアラート設計の実務ポイント
- 過剰ログによるリスクと、リスク階層に応じた設計のバランス
問題:「動いている」のに間違っている
ある経理チームが、月末決算を支援するAIエージェントを導入した。エージェントはERPからデータを取得し、メール添付のスプレッドシートを読み込み、各勘定科目のコメントを自動生成する。エラーはゼロ。APIタイムアウトもない。ダッシュボードはすべて緑色。
3サイクル後、経理責任者が気づく——複数の勘定科目で、古いデータを使ったコメントが生成されていた。エージェントは正しいツールを呼び出し、技術的には一度も失敗していない。しかし、業務的に誤った判断をしていた。
これが、プロダクションにおけるエージェントシステムの本質的な問題だ。問いは「システムは動いているか」から「エージェントは実際に何をしたか、なぜそれをしたか、結果は良かったか、いつ止めるべきか」に変わる。この問いに答えられなければ、説明責任は成立せず、説明責任のない自律性は管理不能なリスクに転落する。
従来のエンタープライズオブザーバビリティは、レイテンシ、エラーレート、DB速度といった技術的健全性に焦点を当ててきた。エージェントシステムはそれでは不十分だ。エージェントは決定論的なコードを実行するだけではない。推論し、ツールを選択し、コンテキストを取得し、システムを呼び出し、メモリを使い、確率的な出力を生成する。同じ入力でも、実行のたびに異なる判断経路をたどる。オブザーバビリティは、技術的に何が起きたか、エージェントが何を判断したか、その判断がビジネス成果とポリシー準拠にどう影響したかの3層を同時に回答できなければならない。
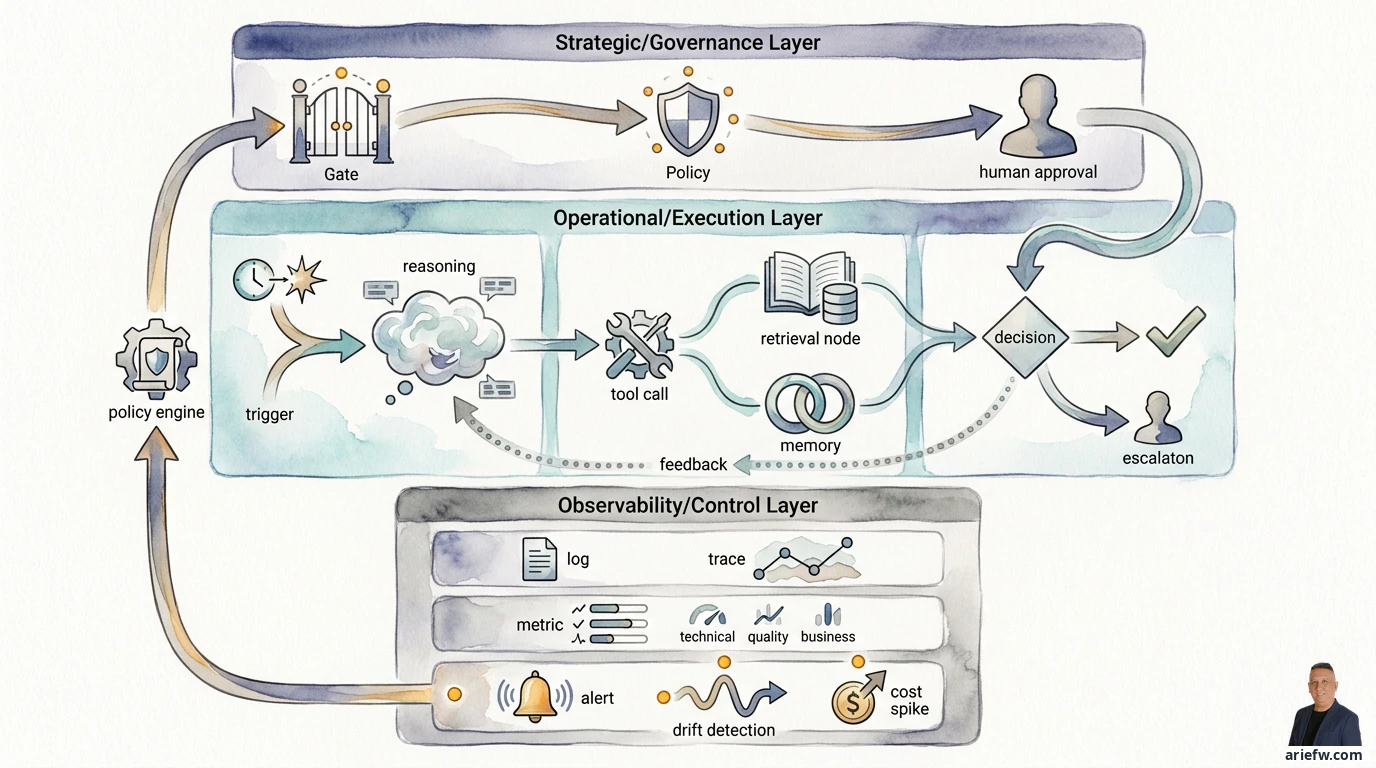
なぜエージェントのオブザーバビリティは難しいのか
難しさの本質は、技術が新しいからではない。観測対象そのものが根本的に複雑だからだ。
標準的なアプリケーションでは、実行フローは線形だ:リクエスト受付→処理→DB読み取り→応答返却。障害が起きれば、ログとメトリクスとスパンを追跡してボトルネックを特定できる。
エージェントシステムは、以下の要素がレイヤー状に積み重なる:
- ユーザー、イベント、ワークフローからのトリガ
- タスクを分解するオーケストレータ
- RAGやメモリからのコンテキスト取得
- モデルが生成する推論や計画
- 逐次的なツール呼び出し
- ポリシーエンジンによる評価
- 人間による承認ゲート
- 最終アクションまたはエスカレーション
厄介なのは、障害が技術的エラーとして現れにくいことだ。エージェントはすべてのAPIを正常に呼び出せるが、間違ったアクションを選択する。クラッシュはしないが、古いコンテキストを使う。技術的にはパスするが、ポリシーに違反する。タスクは完了するが、判断品質が低い。もっともらしいが業務的に誤った出力を生成する。
この確率的性質が監視の方法を変える。同一のプロンプト、ツール、データでも出力は変動する。エラーコードだけに頼れない。行動パターンを監視する必要がある。返金エージェントが技術的に一度も失敗しなくても、以前は自動処理していたケースをエスカレーションし始める——これは生産性を静かに低下させる行動ドリフトだ。調達エージェントはリクエストを作成し続けるが、取得ポリシーの変更により、より保守的な承認経路を選び始める。技術的インシデントはないが、サイクルタイムは悪化する。
エンタープライズにおいて、オブザーバビリティは単なる運用ツールではない。ガバナンスの仕組みだ。リスク管理、監査、コンプライアンス、プロセスオーナーは次の問いに答えなければならない:エージェントはどのコンテキストを使ったか、どのツールを呼び出したか、どのポリシーが適用されたか、いつ停止して承認を求めたか、誰が出力を修正したか、その判断はビジネストランザクションにどう影響したか。このチェーンを再構築できなければ、インシデント調査、監査、品質評価、モデル改善、自律性拡大の基盤は存在しない。
何をログするか:プロンプトから成果まで
最もよくある誤りは、プロンプトと応答だけをログすることだ。エンタープライズ用途では、それは危険なほど浅い。エージェントシステムの適切なログは、エンドツーエンドの判断トレイルを捕捉しなければならない。以下の6つの構成要素が重要だ。
1. トリガと初期コンテキスト
ワークフローはどのように開始されたか——ユーザー、システムイベント、スケジュール、別エージェントからのハンドオフか。発行元プリンシパル、時刻、チャネル、関連ビジネスオブジェクト(請求書番号、チケットID、注文ID)を記録する。
2. プロンプトと実行時指示
すべての詳細は不要だが、どのシステム指示がアクティブだったか、どのパラメータが使われたか、どのプロンプトまたはワークフローバージョンが実行されたか、どのモデル設定が適用されたかを理解できる程度の情報が必要。これはエージェントバージョンの比較や挙動変化の調査で必須になる。
3. 取得コンテキスト
RAG、ナレッジグラフ、メモリを使用する場合、どのドキュメントまたはコンテキストチャンクが取得されたか、そのソース、バージョンまたはタイムスタンプ、アクセスが権限チェックを通過したかをログする。これなしでは、エージェントが特定の判断をした理由を説明できない。
4. モデル応答と推論アーティファクト
生の思考連鎖(chain-of-thought)は不要だが、監査とデバッグに十分な情報は必要だ:アクション計画の要約、意図分類、信頼度シグナル、後続ステップで使われる構造化された判断出力。説明責任のために十分な量を保存するが、機密データや知的財産の漏洩は避ける。
5. ツール呼び出しと結果
すべてのツール呼び出しについて記録すべき項目:どのツールか、主要パラメータ、成功/失敗、レイテンシ、リトライ回数、対象システムの状態変化。財務クローズ、IT運用、調達ワークフローでは、ここでエージェントが業務現実に影響を与え始める。
6. ポリシー判断、人間承認、最終アクション
ポリシーエンジン、承認ワークフロー、ガードレールが関与した場合、それをログする:どのポリシーが評価されたか、結果(許可、拒否、エスカレーション、承認要求)、人間の承認者は誰か、最終判断、実際に実行されたアクション。この層がなければ、技術ログであってガバナンスログではない。
ログ設計におけるセキュリティとプライバシー
ログが増えればデータ露出リスクも増える。エージェントシステムは顧客データ、給与情報、ベンダー詳細、契約書、財務データ、内部インシデント記録に触れる。以下の設計が必要だ:
- 機密データのリダクション
- 識別子のトークン化またはマスキング
- アクセス制御付きの安全なストレージ
- 明確な保持ポリシー
- 職務分離(ログの作成者と閲覧者を分ける)
監査可能性を高めることは、ブラスト半径を拡大することと同義ではない。
メトリクス:技術的健全性を超えて
ログとトレーシングの次はメトリクスだ。多くの実装はレイテンシとエラーレートで止まり、「観測可能」と宣言する。エージェントシステムには3つの明確に分離されたメトリクスグループが必要だ。
技術メトリクス(ランタイム健全性)
- ステップごとおよびエンドツーエンドのレイテンシ
- トークンまたはトランザクションあたりのコスト
- ツールエラーレート、リトライ率、タイムアウト率
- フォールバック使用率、障害モード分布
- モデルゲートウェイ、ベクトルストア、ポリシーエンジン、ツールレジストリの可用性
これらはプラットフォームチームが安定性を維持するのに役立つが、エージェントが信頼できるかは教えてくれない。
品質メトリクス(判断の良し悪し)
これこそがエージェントオブザーバビリティをアプリケーションオブザーバビリティから区別するものだ:
- 期待される成果に対する正確性
- ハルシネーションまたは根拠のない回答率
- エスカレーション率
- ポリシー違反率
- 人間による修正率
- エージェントアクション後の手戻り率
- ツール選択の正確性
- 取得コンテキストに対するグラウンディング品質
一部の品質メトリクスは完全自動化できない。自動評価、手動サンプリング、ユーザーフィードバック、ドメイン専門家レビューの組み合わせが必要になる。
ビジネスメトリクス(業務改善の実現)
エージェントが実際に業務を改善しているかを測定する:
- サイクルタイム
- トランザクションあたりのコスト
- 解決率
- タッチレス率(人間介在なしで完了した割合)
- バックログ削減
- 収益または運転資本への影響
- 顧客または従業員満足度
エージェントが技術的に健全で品質スコアが高くても、ケースあたりのコストが下がらずバックログが改善しなければ、設計の見直しが必要だ。
これら3グループは分離して管理する。混在させると根本原因の診断が困難になる。レイテンシスパイクは技術的問題。人間修正率の上昇は品質問題。サイクルタイムの停滞はビジネスまたはプロセス設計の問題。関連はしているが、同じではない。
ドリフトをインシデントになる前に監視する
メトリクスが定義できたら、何を継続的に監視し、いつアラートを出すかを決める。エージェントシステムでは、問題は多くの場合、完全な障害ではなくパターンの変化として現れるため、これはより難しい。
監視すべきドリフト
行動ドリフト:
- エスカレーション率の変化
- 出力長の異常なシフト
- ツール使用パターンの変化
- 分類分布の急激な変化
原因として考えられるもの:モデル更新、プロンプト変更、取得コーパスのシフト、データ分布の変化、ツール応答の変更。
ツール使用異常:
- 通常は契約APIとベンダーAPIを呼ぶ調達エージェントが、手動例外パスを頻繁に呼び始める
- IT運用エージェントが特定のRunbookをベースラインを大きく超えて実行する
これらはドリフト、バグ、環境変化のシグナルだ。
出力分布の変化:
- 「わかりません」という応答の増加
- より保守的な推奨
- 人間がキャンセルするアクションの増加
- 未解決で終了するケースの増加
これらは、可視的なインシデントになる前にエージェント品質の低下を示すことが多い。
アラートのカテゴリ設計
すべてのアラートが技術的インシデントではない。以下の4カテゴリに分類し、それぞれに異なる対応オーナーとエスカレーションパスを設定する:
| カテゴリ | 例 | 対応オーナー |
|---|---|---|
| 技術的インシデント | モデルゲートウェイダウン、ツールAPIタイムアウト | SRE / プラットフォームチーム |
| ポリシー違反 | エージェントが許可されていないアクションを試行、アクセス違反 | セキュリティ / コンプライアンス |
| 品質劣化 | 人間修正率の急上昇、根拠のない回答の増加 | AIエンジニアリング / プロダクト |
| コストスパイク | トランザクションあたりのトークンコスト上昇、過剰なツール呼び出し、高価なモデルへのフォールバック | ファイナンス / プラットフォーム |
トレードオフ:監視の怪物を作らない
ここに罠がある。組織は優先順位なしにすべてをログしようとする。ストレージコストが膨らむ。ダッシュボードがノイズになる。チームは重要なシグナルを特定できなくなる。プライバシーリスクが増大する。
リスク階層とユースケースの重要度に応じて設計する。内部ナレッジアシスタントは軽いログでよい。返金自動化システム、財務例外ハンドラ、IT修復ワークフローははるかに深いトレーシングと監査が必要だ。
健全な原則:説明責任のために十分なログ、意思決定のために十分な測定、チームが実際に行動するための十分なアラート。優れたオブザーバビリティとは最も多くのデータを持つことではなく、エージェントの行動を見て、説明し、制御するために最も有用なデータを持つことだ。
スケールに耐えられないオブザーバビリティの警告サイン
- 単一のエージェント実行をトリガからビジネス成果までトレースできない
- 技術メトリクス、品質メトリクス、ビジネスメトリクスが分離されていない
- どの機密データをリダクションし、誰がログにアクセスできるかが定義されていない
- すべてのアラートを同じインシデントタイプとして扱っている
- プロダクションでエージェント品質をレビューする体系的なプロセスがない
エージェントシステムのオブザーバビリティはダッシュボードプロジェクトではない。コントロールプレーンの決定だ。正しく設計すれば、信頼、説明責任、責任ある自律性の基盤ができる。間違えれば、エージェントが何をしているかを知るのは手遅れになる——その頃には、エージェントはすでにあなたの代わりに行動している。