この記事で扱うこと
「うちはもうAIエージェントを導入している」という言葉を聞いたとき、それが単なるチャットボットなのか、メール下書き支援なのか、それとも実際にAPIを叩いて業務システムに書き込みを行う自律実行なのか、組織内で定義が一致していない経験はないだろうか。
本記事では、Agentic AI Maturity Model(エージェンティックAI成熟度モデル) を、エンジニアリングの観点から解説する。特に以下の点にフォーカスする。
- 各レベルにおけるアーキテクチャの違いとAPI連携の要件
- エージェントが「動く」ために必要な権限設計・監査・運用基盤
- 現実的な12ヶ月のターゲット設定と、やってはいけない実装パターン
経営論だけでは終わらせず、システム設計に落とし込める内容を目指す。
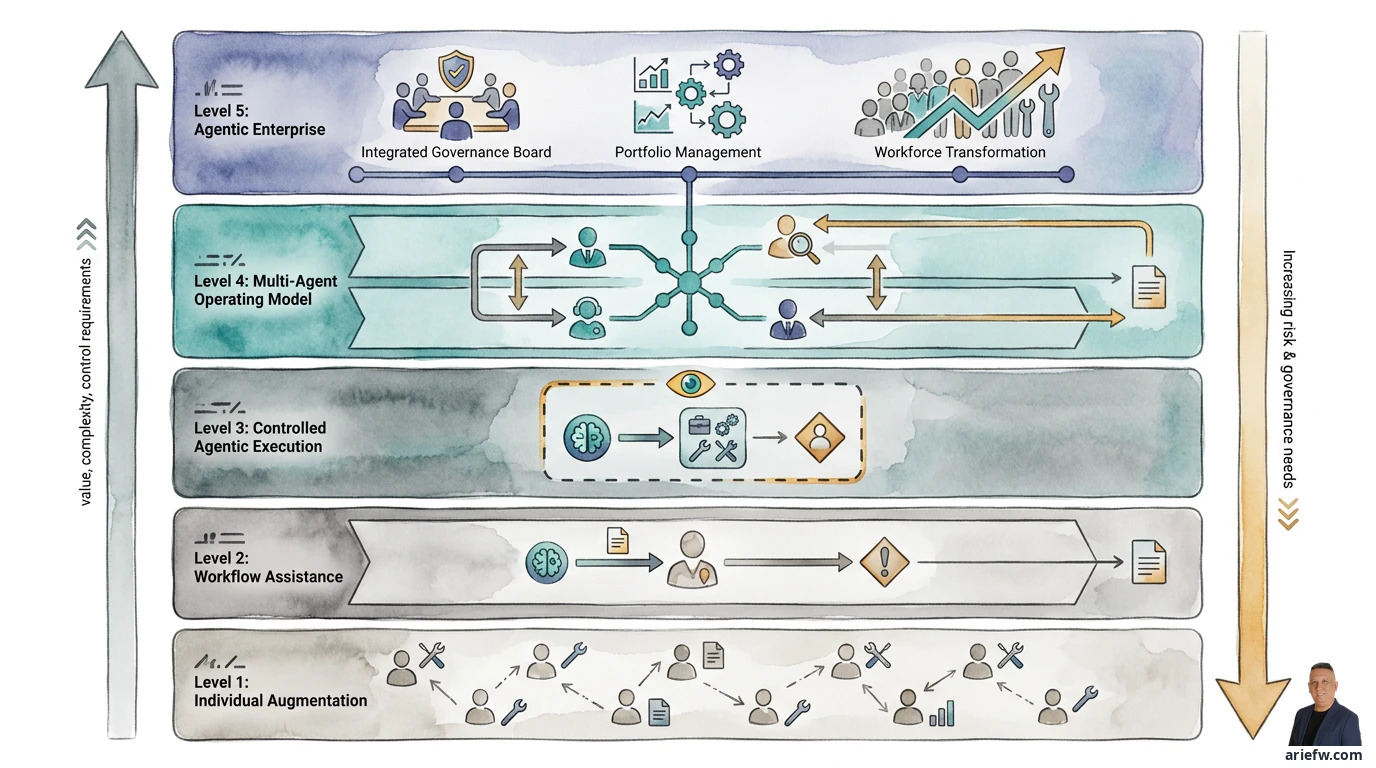
Level 1: 個人生産性向上 — 最も多いが最も危険なスタート地点
状態: 各エンジニアやビジネスユーザーが、ChatGPTや社内LLMを個人のアシスタントとして利用。コードレビューの下書き、ドキュメント要約、メール作成支援など。
アーキテクチャの実態:
- システム連携はなし。ブラウザ上のWeb UIが主戦場。
- API呼び出しは発生するが、それは個人のクライアントからLLMプロバイダへの直接呼び出し。
- 企業としてのトレーサビリティやガバナンスは存在しない。
エンジニアリング上の問題点:
- データ流出リスク: 顧客情報やソースコードが、許可されていない外部LLMに送信される可能性。
- 再利用性ゼロ: プロンプトや設定は個人のローカル環境に閉じ、組織の資産にならない。
- 計測不能: 「生産性が上がった」という主観的な報告しか得られない。サイクルタイムの短縮やエラー率の改善といったビジネス指標に紐付かない。
判断基準:
- 「AI使ってるよ」と言いながら、その成果が個人の満足度アンケートでしか測れていない。
- プロセスオーナーが不在で、誰もAIのアウトプット品質に責任を持っていない。
Level 2: ワークフロー支援 — エンタープライズ価値の入り口
状態: AIが公式なワークフローに組み込まれる。人間が最終実行はするが、AIが下書き・分析・検索を支援する。
アーキテクチャの特徴:
- RAG(検索拡張生成) の導入が一般的。社内ナレッジベースや過去のチケットをベクトルDBに格納し、LLMが参照。
- API連携は参照系が中心。CRMやチケットシステムからデータを取得し、AIが要約・提案を生成。書き込みは人間が行う。
- ガードレールはプロンプトレベル。システムプロンプトで「機密情報を出力しない」「特定のフォーマットに従う」などを指定。
実装例(カスタマーサポート向け):
# 疑似設定: ワークフロー支援のためのAIエージェント設定
workflow_assistant:
name: "case_summarizer"
data_sources:
- type: "vector_db"
endpoint: "https://internal-vector-db.company.com"
index: "support_cases"
- type: "api"
endpoint: "https://api.company.com/v1/cases/{case_id}"
method: "GET"
actions:
- type: "generate_summary"
prompt_template: "以下のケース履歴を要約し、未解決のアクションアイテムを箇条書きで出力してください。\n{case_history}"
output:
destination: "human_review" # 人間が確認後、システムに貼り付け
エンジニアリング上のポイント:
- 計測可能になる: 「AI支援後の平均処理時間」「初回解決率の変化」を追跡できる。
- リスクは低い: 人間がすべてのアクションを実行するため、誤った書き込みは発生しない。
- 限界: 高頻度プロセスの根本的な経済性は変わらない。人間がボトルネックであり続ける。
Level 3: 制御されたエージェント実行 — ここからが本番
状態: AIがツールを呼び出し、限定的なアクションを実行する。ここで初めて「エージェント」と呼べる動作が始まる。
アーキテクチャの必須要素:
- Function Calling / Tool Use: LLMが定義されたAPIを選択・呼び出し。例: 返金API、チケット作成API、在庫確認API。
- IDとアクセス制御: エージェントにサービスアカウントを付与。人間と同じIAMポリシーで管理。
- ポリシーエンジン: 「この条件下でのみアクションを許可する」というルールを実行時に評価。例: 「返金額が5,000円未満かつポリシー違反がない場合のみ実行可能」。
- 監査ログ: すべてのツール呼び出し、LLMの応答、人間の承認/却下を記録。
- 人間インザループ: 特定の条件(高額取引、初回の顧客など)では、エージェントは提案まで行い、人間の承認を待つ。
実装例(返金エージェント):
# 疑似コード: ポリシーエンジンによるアクション制御
def can_execute_refund(agent_id: str, refund_amount: float, customer_tier: str) -> bool:
# エージェントの権限確認
agent_permissions = get_agent_permissions(agent_id)
if "execute_refund" not in agent_permissions:
return False, "Agent does not have refund execution permission"
# ポリシールール評価
if refund_amount > 5000:
return False, "Amount exceeds automatic threshold, requires human approval"
if customer_tier == "vip":
return False, "VIP customers require manual handling"
# 監査ログに記録
log_decision(agent_id, "refund", refund_amount, "approved_by_policy")
return True, "Policy check passed"
エンジニアリング上の落とし穴:
- APIの非同期性: エージェントが同期的なAPI呼び出しを前提とすると、長時間処理やタイムアウトでエラーが多発する。イベント駆動型のアーキテクチャ(キュー、Webhook)が必要。
- エラーハンドリングの複雑さ: APIが503を返したら? 部分成功したら? ロールバックは可能か? これらをエージェントのプロンプトだけで解決するのは不可能。オーケストレーションレイヤーでトランザクション管理が必要。
- プロンプトインジェクション: 悪意のあるユーザー入力が、エージェントに意図しないAPI呼び出しをさせる可能性。入力サニタイズとツール呼び出しのホワイトリストが必須。
判断基準:
- エージェントに専用のIAMロールが割り当てられているか?
- 「読み取り専用API」と「書き込みAPI」が明確に分離されているか?
- エージェントのアクションをリアルタイムで可視化するダッシュボードがあるか?
Level 4: マルチエージェント運用モデル — 組織横断のオーケストレーション
状態: 複数のエージェントがオーケストレーターの下で連携し、エンドツーエンドのバリューストリーム(例: 見積から請求まで、インシデント発生から解決まで)を処理する。
アーキテクチャの特徴:
- オーケストレーターエージェント: タスクを分解し、適切なエージェントに割り振る。状態管理を行い、全体の進行状況を追跡。
- エージェントカタログ: 各エージェントの責務、利用可能なツール、連絡先オーナーを管理するレジストリ。
- クロスファンクショナルなデータ同期: 部門間でデータの不整合があると、エージェント同士が矛盾した判断をする。マスターデータ管理(MDM) の重要性が増す。
実装例(購買発注の例外処理):
- 購買エージェント: 発注依頼を受け取り、ポリシーチェック。在庫不足を検出。
- 在庫エージェント: 代替倉庫の在庫状況を確認。納期を計算。
- ポリシーエージェント: 「顧客優先度が高い場合は、緊急調達を許可」というルールを評価。
- オーケストレーター: 上記の結果を統合し、購買担当者に「代替案A: 別倉庫から配送(+2日)、代替案B: 緊急調達(+5万円)」を提示。人間が選択。
エンジニアリング上の課題:
- エージェントスプロール: 管理されていないエージェントが増殖し、誰が何をしているかわからなくなる。エージェントのライフサイクル管理(登録、バージョン管理、廃止)が必要。
- コンフリクト解決: エージェントAが「承認」、エージェントBが「却下」を推奨した場合、どうするか? 優先順位ルールとエスカレーションパスを設計する必要がある。
- 説明責任の所在: マルチエージェントの判断が誤った場合、どのエージェントのどの判断が原因かトレースできるか? 分散トレーシング(OpenTelemetryなど)の導入がほぼ必須。
Level 5: エージェンティックエンタープライズ — プラットフォームとしてのAI
状態: エージェントはもはや実験プロジェクトではない。企業の実行レイヤーの公式な一部として、統合プラットフォーム、ガバナンス、運用モデルが確立されている。
アーキテクチャの特徴:
- 統合エージェントプラットフォーム: エージェントの開発、デプロイ、監視、管理を一元化する内部プラットフォーム。
- ポリシー・アズ・コード: すべてのガバナンスルールがコード化され、CI/CDパイプラインで管理される。
- 人間-AIチームのパフォーマンス指標: エージェント単体の精度だけでなく、「人間+エージェント」のチームとしての生産性、品質、コストを測定。
重要な誤解: Level 5=完全自動化ではない。むしろ、「いつエージェントに任せ、いつ人間が介入すべきか」の境界が明確に定義されている状態。一部のドメインでは高度な自律性を持ち、別のドメインでは人間インザループが支配的。重要なのは一貫性のある運用規律であって、自律性の高さではない。
12ヶ月の現実的なターゲット設定
ほとんどの組織では、以下の3パターンのいずれかが現実的。
- Level 1 → Level 2: 優先度の高い2〜3のワークフローを選び、AIを公式プロセスに組み込む。サイクルタイムと品質を計測し、基本的なガードレールを構築する。
- Level 2 → Level 3: リスクの低いアクション(例: 定型のチケット作成、ポリシーチェック)から始める。ID管理、ポリシーエンジン、承認ワークフロー、監査ログを整備する。APIとデータ基盤の成熟度を確認する。
- Level 3 → Level 4: エージェントのスプロールを防ぐ。オーケストレーターとエージェントカタログを構築する。クロスファンクショナルなオーナーシップを確立する。孤立したユースケースではなく、バリューストリーム単位で管理を始める。
Level 5へのフルジャンプを12ヶ月で目指せる組織は、すでにデジタルコア、ガバナンス、運用規律が成熟している場合に限られる。
まとめ: エンジニアが今すべきこと
- 「エージェント」の定義を組織内で統一する: コパイロット、ワークフロー支援、アクション実行エージェントを明確に区別する。
- APIとデータ基盤の成熟度を棚卸しする: Level 3を目指すなら、書き込みAPIの安定性、エラーハンドリング、非同期処理の対応は必須。
- ガバナンスを後回しにしない: エージェントが動き始めてからでは遅い。IAM、ポリシーエンジン、監査ログは先行投資として考える。
- 計測できないものは改善できない: 個人の満足度ではなく、プロセスのサイクルタイム、エラー率、コスト削減額でAIの価値を測る。
成熟度モデルは、組織全体が一律に同じレベルを目指す必要はない。HRはLevel 1、財務はLevel 2、カスタマーオペレーションはLevel 3という状態もあり得る。重要なのは、自分たちが今どこにいて、次に何の基盤を整えるべきかを正確に把握することだ。