Overview
bash で webスクレイピングをするシェル芸です。
実質 css selector 頼りなのでシェル芸と言ってもいいか微妙なところですが…
あと、スクレイピング周りの知見もつらつら書いてきます。
なお、よくあるページネーション型のサイトが対象です。
SPA みたいなサイトはたぶん Selenium + Headless Chrome とか使わないと駄目かも。
requirements
この辺使うので無かったら落としてきてください。
あと、その他のちょい役で出てくるコマンド類は全部 GNU 版です。
Disclaimer
内容が内容だけに悪用禁止です。
何かあっても知りませんのでご注意ください。
お約束
というかマナーですね。
不必要なアクセスはしない
htmlの解析などは、いったん手元に素の状態でダウンロードしてきてから、手元で当たりをつけましょう。
wait を入れる
wget は 複数URLを指定すると全力で落としにかかる ので、 -w 1 とかでウェイトを入れましょう。
wget じゃなくても 1アクセスにつき1秒くらいは sleep 入れたほうが良いです。
それぞれ別サイトごとに並列化なら、してもいいかもしれません。
サンプルサイト
とはいっても、大々的にスクレイピングしてもOKなサイトとか、
まぁ普通に考えてあるわけがない(笑)ので、サンプルを用意したいところです。
さて、ちょうどいいところに wordpress の docker-compose.yml と
http://docs.docker.jp/compose/wordpress.html
サンプルデータを用意してくれている人がいるので、
https://github.com/jawordpressorg/theme-test-data-ja
これらを使って手元にスクレイピング用の wordpress を立ててみます。
やり方は この辺 みてください。
ここまで準備。
スクレイピングの手順
なんかの記事サイトであれ、ECサイトであれ、スクレイピング対象のほとんどのwebサイトは、
- 一覧ページ:http://localhost:8000/?paged=2
- 個別ページ:http://localhost:8000/?p=993
- 個別ページ:http://localhost:8000/?p=1446
- 個別ページ:...
という構成になってると思います。
なので、
- まず一覧ページを全て入手して
- 個別ページのURLを解析して
- 個別ページを全て入手する
という方針で行くとスムーズです。
そのためには、まず全部で何ページあるかを調べます。
総ページ数がわからない場合の方法は、おまけで別途書きます。
全部で何ページあるか調べる
まず、ページネーションのある場所を探します。
だいたいは最後のページヘのリンクか、最後のページ数があるはずなので、これを調べます。
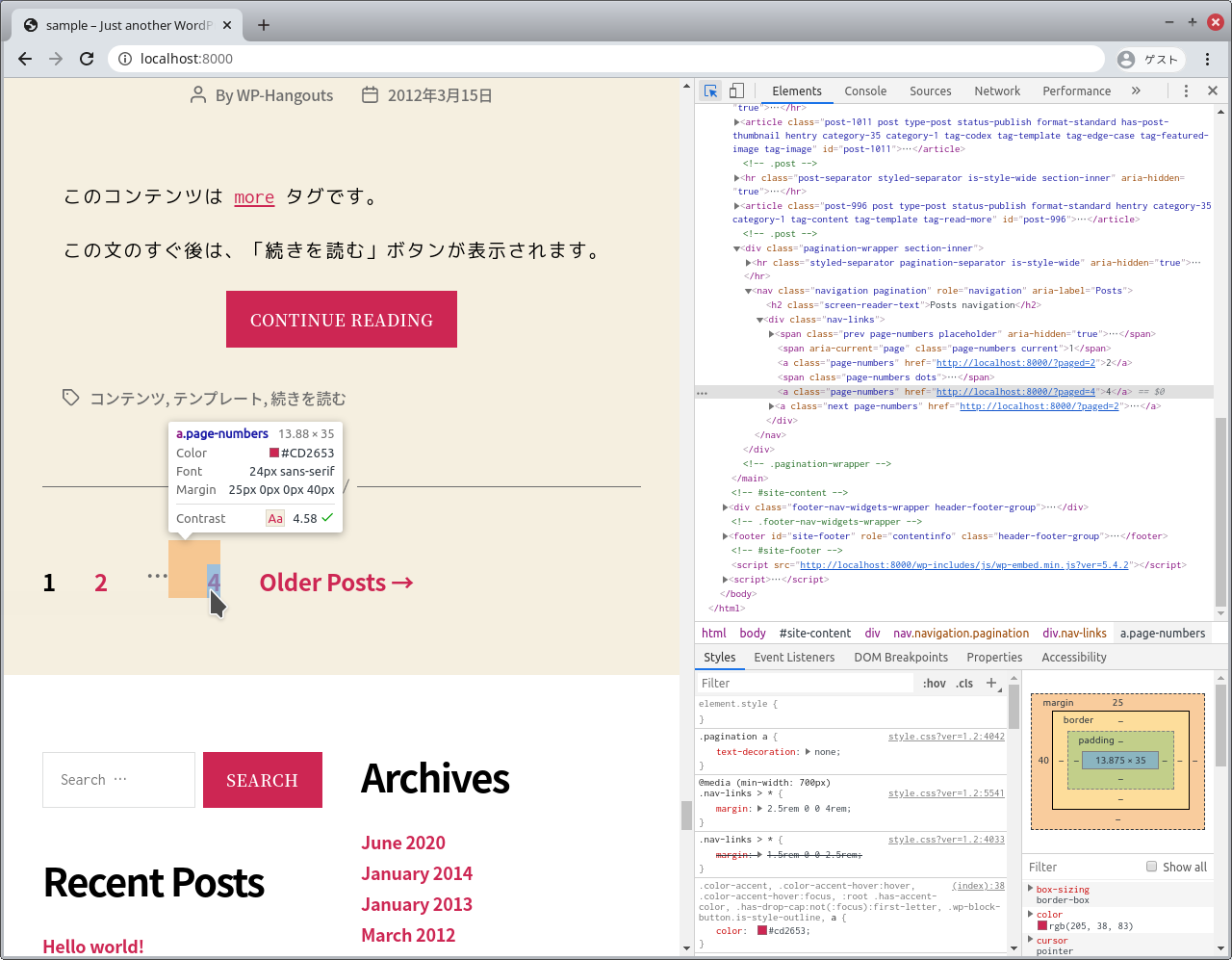
今回は4ページみたいですね。
一覧ページを全て取得する
ページURLのフォーマットを調べて、全ページ数分のURLを生成します。
$ seq -f 'http://localhost:8000/?paged=%g' 1 4
http://localhost:8000/?paged=1
http://localhost:8000/?paged=2
http://localhost:8000/?paged=3
http://localhost:8000/?paged=4
ちなみに、1ページ目も http://localhost:8000/?paged=1 とかで取得できる場合がほとんどなので、
その場合1ページ目を特別扱いする手間が省けるので、調べてみると良いです。
これを wget に食わせます。
-i | --input file オプションで取得するURLを渡せるので、これを stdin から流し込んでます。
$ seq -f 'http://localhost:8000/?paged=%g' 1 4 | wget -w 1 -P pages -i -
(..snip..)
$ tree pages/
pages/
├── index.html?paged=1
├── index.html?paged=2
├── index.html?paged=3
└── index.html?paged=4
なお、ページ数が連番じゃなくてもこのアプローチはいろいろ応用が利くので、覚えておくと良いと思います。
個別ページのURLを解析する
css selector で抜き出すので、 dev tools で眺めてみます。
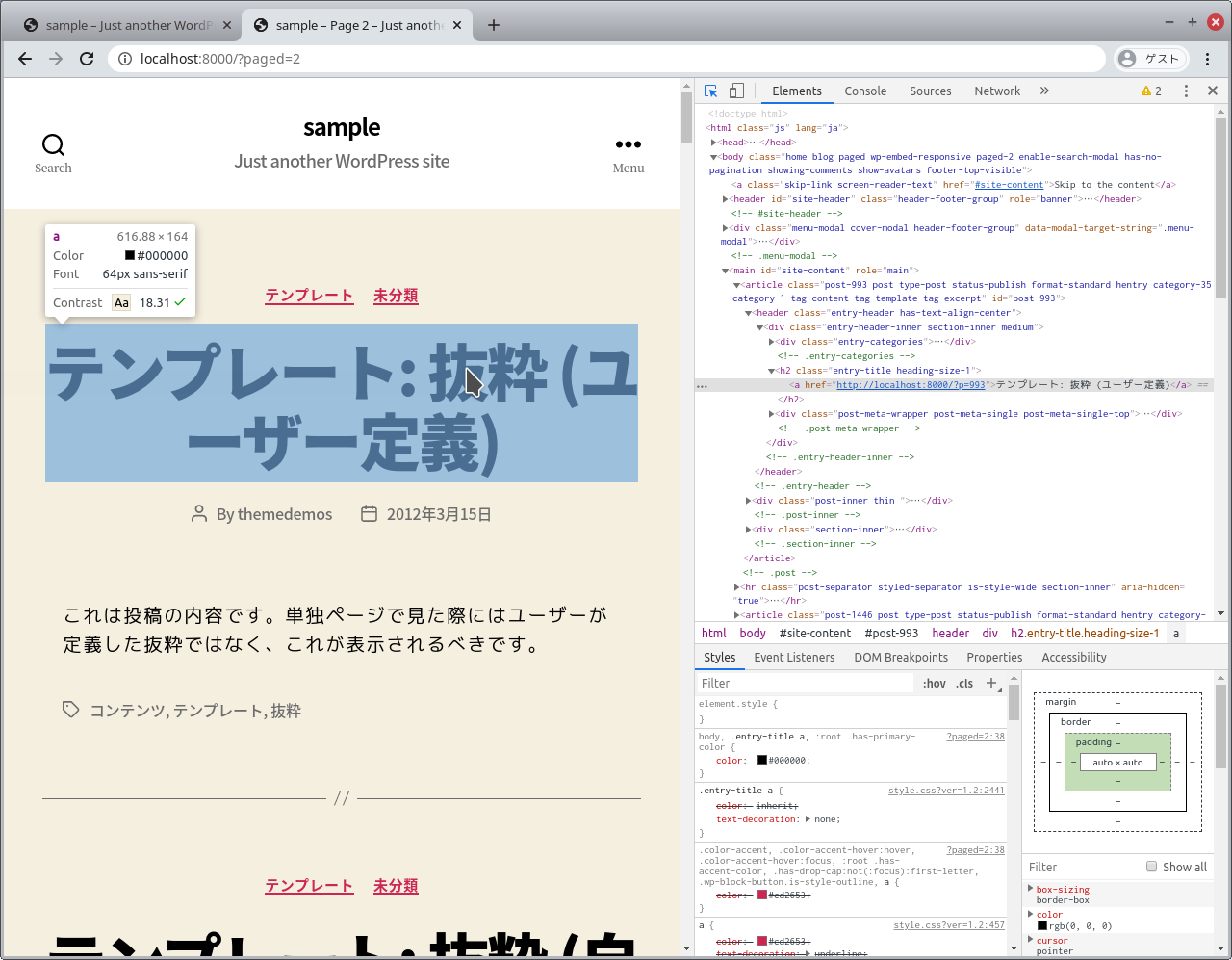
article.post h2.entry-title > a とかで行けそうですね。
pup は attr{href} で属性を抜き出せるので、
$ cat pages/index.html\?paged\=1 | pup 'article.post h2.entry-title > a attr{href}'
http://localhost:8000/?p=1241
http://localhost:8000/?p=1
http://localhost:8000/?p=2069
http://localhost:8000/?p=1178
http://localhost:8000/?p=1177
http://localhost:8000/?p=1176
http://localhost:8000/?p=1174
http://localhost:8000/?p=1173
http://localhost:8000/?p=1016
http://localhost:8000/?p=1011
http://localhost:8000/?p=996
できました。
個別ページを全て入手する
あとは、一覧ページを一括でダウンロードしたのと同じ要領でいけます。
$ cat pages/* | pup 'article.post h2.entry-title > a attr{href}' | wget -w 1 -P articles -i -
(..snip..)
$ tree articles/
articles/
├── index.html?p=1
├── index.html?p=1000
├── index.html?p=1005
├── index.html?p=1011
├── index.html?p=1016
├── index.html?p=1031
├── index.html?p=1148
├── index.html?p=1149
├── index.html?p=1150
├── index.html?p=1151
├── index.html?p=1152
├── index.html?p=1158
├── index.html?p=1161
├── index.html?p=1163
├── index.html?p=1168
├── index.html?p=1170
├── index.html?p=1171
├── index.html?p=1173
├── index.html?p=1174
├── index.html?p=1175
├── index.html?p=1176
├── index.html?p=1177
├── index.html?p=1178
├── index.html?p=1179
├── index.html?p=1241
├── index.html?p=1241.1
├── index.html?p=1446
├── index.html?p=2069
├── index.html?p=358
├── index.html?p=555
├── index.html?p=559
├── index.html?p=562
├── index.html?p=565
├── index.html?p=568
├── index.html?p=575
├── index.html?p=579
├── index.html?p=582
├── index.html?p=587
├── index.html?p=993
└── index.html?p=996
ちょろいもんだぜ。
あとは手元に落としてきた html を解析して、煮るなり焼くなりしてください。
ちなみに、何故か p=1241 が2件ありますけど、page1 と page2 の両方に 1241 が出現するのが原因なので、たぶんサンプルデータの不備だと思います(ちゃんと中身見てないけど
気になるなら wget に流す前に sort -u を挟むとよいです。
個別ページの title をざっと抜き出してみると
$ cat articles/* | pup 'title text{}'
Hello world! – sample
極端な例: ネスト化された混合リスト – sample
投稿フォーマット: 動画 (VideoPress) – sample
テンプレート: アイキャッチ画像 (横) – sample
テンプレート: アイキャッチ画像 (縦) – sample
投稿フォーマット: ギャラリー(タイル) – sample
テンプレート: コメント – sample
テンプレート: ピンバックとトラックバック – sample
テンプレート: コメント不可 – sample
極端な例: たくさんのタグ – sample
極端な例: たくさんのカテゴリー – sample
投稿フォーマット: 画像 – sample
投稿フォーマット: 動画 (YouTube) – sample
投稿フォーマット: 画像(キャプション) – sample
テンプレート: パスワードで保護されたページ – sample
極端な例: コンテンツのない投稿 – sample
テンプレート: ページ分け – sample
マークアップ: マークアップ付きのタイトル – sample
マークアップ: 特殊記号を含むタイトル ~`!@#$%^&*()-_=+{}[]/;:’”?,.> – sample
Pneumonoultramicroscopicsilicovolcanoconiosis – sample
マークアップ: テキスト配置 – sample
マークアップ: 画像の配置 – sample
マークアップ: HTML タグとフォーマット – sample
メディア: Twitterの埋め込み – sample
テンプレート: 先頭固定表示 – sample
テンプレート: 先頭固定表示 – sample
テンプレート: 抜粋 (自動生成) – sample
1行分しか想定されていない見出しのデザインだと文字がはみ出してしまってあら大変。ものすごく長い日本語のタイトルが付いた記事の表示テストです。複数行になっても問題ないデザインだといいですね。あと前後の記事への リンクを出力している場合や、パンくずリストを実装している場合なども表示にズレがないか確認しておきましょ う。 – sample
投稿フォーマット: 標準 – sample
投稿フォーマット: ギャラリー – sample
投稿フォーマット: アサイド – sample
投稿フォーマット: チャット – sample
投稿フォーマット: リンク – sample
投稿フォーマット: 画像(リンク) – sample
投稿フォーマット: 引用 – sample
投稿フォーマット: ステータス – sample
投稿フォーマット: 動画 (WordPress.tv) – sample
投稿フォーマット: オーディオ – sample
テンプレート: 抜粋 (ユーザー定義) – sample
テンプレート: More タグ – sample
こんな感じで、「ページ内の特定の位置の画像が欲しい」とかなら、個別ページをさらに解析して、同じことの繰り返しでいけます。
おまけ
最後のページがわからないケース
infinite scroll みたいな最後のページが取得できない場合は、
ページ数をインクリメントしながら、欲しい情報がもう出てこなくなるまで繰り返します。
sleep 入れるのを忘れずに。
# !/bin/bash
mkdir -p pages
yes | awk '{print NR}' | while read x; do
PAGE_FILE=pages/${x}.html
wget "http://localhost:8000/?paged=$x" -O ${PAGE_FILE}
sleep 1
done
さて、無限に連番生成するのでどこかで break しないと止まらないんですが、ここでパターンが別れます。
404 Not Found が返ってくるケース
404 が返ってくると wget が異常終了するので、 $? を見て break してやればOKです。
# !/bin/bash
mkdir -p pages
yes | awk '{print NR}' | while read x; do
PAGE_FILE=pages/${x}.html
wget "http://localhost:8000/?paged=$x" -O ${PAGE_FILE}
[ $? != 0 ] && break # <--- これ
sleep 1
done
200 OK だが要素が空で返ってくるケース
今回の場合 article.post のセレクタが1件単位だったのを上で確認しましたが、
200 で返ってくるのにこれが0件のケースです。
pup に要素が0件のセレクタを当てても何も返ってこないので、json に変換して、0件の場合に break するように細工してやります。
# !/bin/bash
mkdir -p pages
yes | awk '{print NR}' | while read x; do
PAGE_FILE=pages/${x}.html
wget "http://localhost:8000/?paged=$x" -O ${PAGE_FILE}
cat ${PAGE_FILE} | pup 'article.post json{}' | jq -e 'length == 0' && break # <--- これ
sleep 1
done
これでOK。
落としてきた直後のファイルを cat するので、 -O でファイル名指定してやる必要があります。
そういえば jq ここでしか使ってないな…
wget の保存ファイル名
url の末尾がスラッシュで終わる場合、 wget は index.html でファイルを保存するので、普通にやると
-
/page/1/->index.html -
/page/2/->index.html.1 -
/page/3/->index.html.2
みたいに厄介なことになるので、
その場合も -O オプションで連番ファイル名を指定してやると良いと思います。
あとは curl -o とかでもOKです。
っていう話なんですけど、あんまりシェル芸要素なかったですね。まぁいいや。
ちなみに xpath でも同様にできますが、xpath が扱えるいい感じの cli ツールが xmllint くらいしか無くて、これがまたけっこう茨の道なため、シェル芸でやるならオススメしません。