※ この記事は エキサイト Advent Calendar 2017 24 日目の記事です ※
ごあいさつ
クリスマスイブですね。僕は一人です。

の予定だったんですが心優しい先輩に誘われて夜は飲みに行くことになりました。
今年から新卒一年目で配属しました ウーマンエキサイト エンジニアの本田です!

今年5月末にウーマンチームに配属しまして、 **ウーマンエキサイトアプリ**のAPI担当として
リニューアルバージョンアップを行いました。
アプリAPIと並行してウーマンチームで機械学習プロジェクトを鋭意進行中でありまして、
今日はその中で使っているSVM(サポートベクターマシーン)のパラメータ調節までまとめてみました。
SVM (サポートベクターマシーン)
SVMの話については、今日のために事前にまとめておきました。
SVM(サポートベクターマシーン)についてまとめてみた
こちらの記事で内容をざっくり確認すると以下の内容がすっきりわかるかと思います!
三行でSVMについて言うと
- データ集合を線形分離する識別関数である。
- サポートベクトルの概念を取り入れ、識別平面との距離(マージン)を最大化する。
- データ集合が線形分離不可能な場合はソフトマージンを用いる。
なんでSVM?
最近の深層学習の発展でSVMは一昔前の学習器として言われがちなのですが、
今回使う理由としては、
-
そもそも深層学習するほどデータ数があるわけではない
-
深層学習のラーニングコストを考えて、一から勉強するには時間がかかると思ったから
-
データの次元が大きくなっても識別精度がいい
-
いじるパラメータが少ない(これが一番でかい)
結局どれだけ実装が簡単でもチューニングするパラメータが多くて難しいと、
その分だけラーニングコストがかかってしますからです。
深層学習だとニューラルネットワークのアーキテクチャから考慮しなければならないので、
その点も踏まえてSVMにしました。
あと個人的に院生のときにHawaiiでカーネル法関連の研究を行ったときに、
SVMに対する障壁がなくなったので、使ってみようという好奇心もありました。
Scikit-learnの導入
導入に関しても、今日のために事前に第一回Excite Open Beer Bash で発表した資料でまとめています。
(ばちくそに滑りましたが)
Scikit-learnを使って画像分類を行う

今回はscikit-learnを使うためにanacondaをインストールします。
pyenv install anaconda3-5.0.0
これだけでmacやunixユーザはインストールすることができます。(もちろんpyenvは入れる必要があります)
念のためpyenvの入れ方も
git clone git://github.com/yyuu/pyenv.git ~/.pyenv
brew install pyenv
もちろんhomebrewもry
少し重たいのでインストールに時間がかかると思いますが、しばらく待ちます。
SVMの導入
anaconda3がインストールできた状態で、atomでもpyCharmでも開いて早速svmを使いましょう。
from sklearn import svm
clf = svm.LinearSVC()
importしてsvmインスタンスの変数を入れるだけです。
ここで、LinearSVCを使っています。
saketさんの記事が非常にわかりやすかった参考にさせていただきます。
scikit.learnでは分類に関するSVMは
- SVC
- LinearSVC
- NuSVC
の3つである. SVCは標準的なソフトマージン(エラーを許容する)SVMである. 一方, NuSVCはエラーを許容する表現が異なるSVMである. LinearSVCはカーネルが線形カーネルの場合に特化したSVMであり, 計算が高速だったり, 他のSVMにはないオプションが指定できたりする
LinearSVCの主要パラメータの簡単な解説
| パラメータ | 説明 |
|---|---|
| penalty | 罰則項。L1正則化・L2正則化(デフォルト)を選択可 |
| loss | 評価関数。ヒンジ損失か二乗ヒンジ(デフォルト) |
| dual | 双対問題を解くか否か(デフォルトはtrue) |
| tol | アルゴリズムの終了条件(default=1e-4) |
| C | ソフトマージンの厳しさを表すパラメータ |
L1正則化・L2正則化が選択できるのがいい点ですね。上記のほかのSVMにないオプションです。
正則化の解説
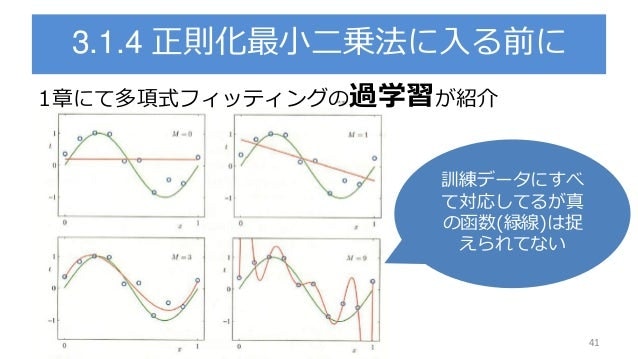
penaltyとlossの組み合わせは三通りで
- Standard : loss=L1, penalty=L2 (通常のSVM)
- LossL2 : loss=L2, penalty=L2
- PenaltyL1 : loss=L2, penalty=L1
このようになっています。
余談:L1にするとパラメータwの解がスパース(疎)になる利点があります。
この三種類の条件で、もっとも良い精度を出してくれるのはなにかをチューニングする必要があります。
Gridsearch-CVでのパラメータチューニング
scikit-learnでGridsearch-CVとは何?ということで
一言で言えば、
**パラメータをある範囲で全部試して一番精度の良いパラメータ条件を引っ張ってくるライブラリ**です。
パラメータをある範囲で全部試すところがGridsearchにあたり、
CVは交差検定方法(Cross-Validation)です。
CV法は簡単に説明すると、
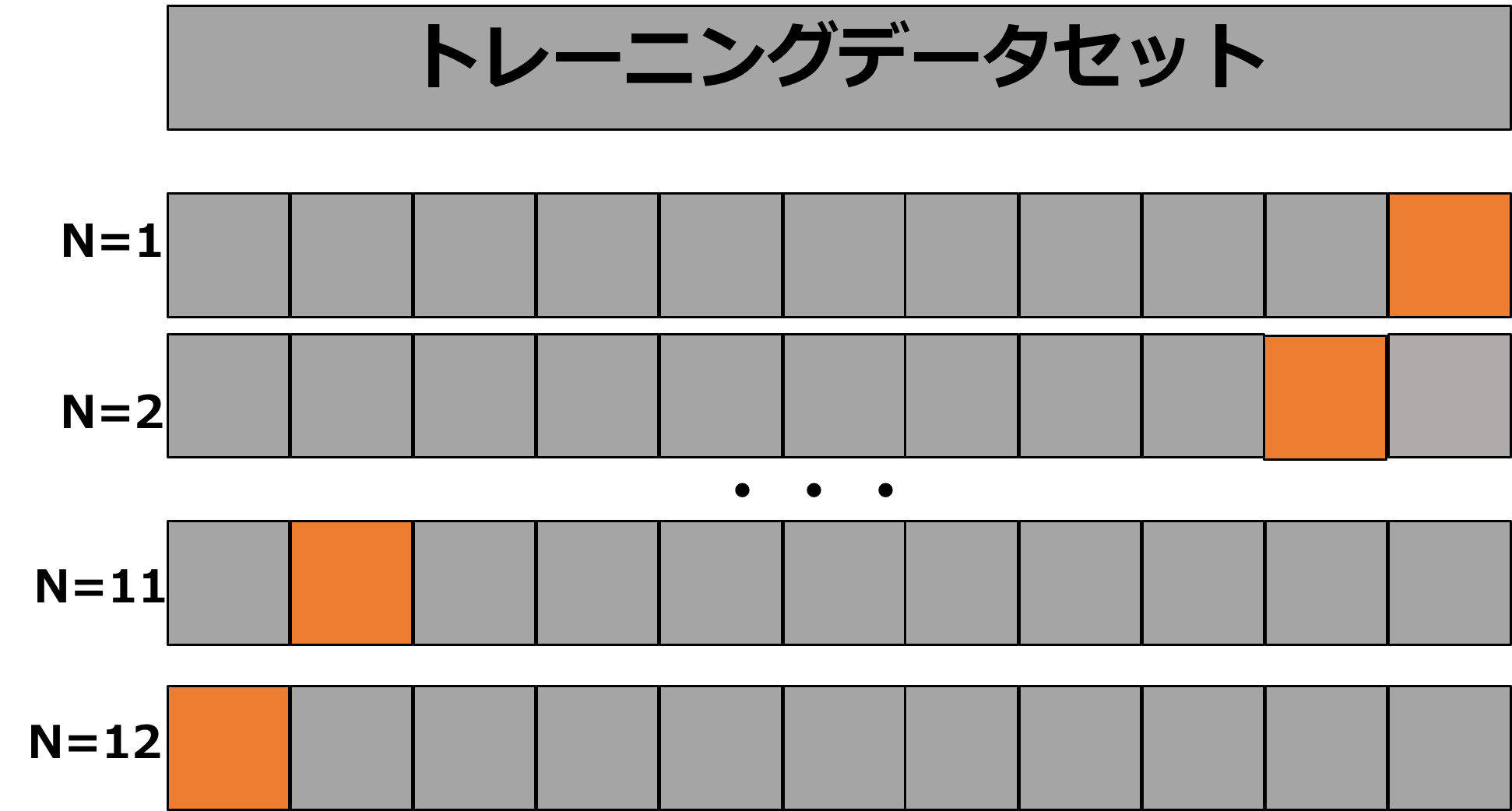
学習用のデータを整数k個で分割して、それぞれの試行で出た精度を平均化してスコアを出してくれます。
結局何を調節するの?
ソフトマージンの制約パラメータであるCです
導入
実際に導入していきます。
# 学習データと評価データへ分割するライブラリの導入
from sklearn.model_selection import train_test_split
# グリッドサーチCVの導入
from sklearn.model_selection import GridSearchCV
# svmのインポート
from sklearn import svm
# todo: 学習用データを用意する
# 特徴量と正解ラベルを学習データと評価データへ分割(3割をテストデータに)
data_train, data_test, label_train, label_test = train_test_split(
inputVec, outputVec, test_size=0.3)
# LinearSVCの取りうるモデルパラメータを設定
Standard = svm.LinearSVC(penalty='l2', loss='hinge', dual=True, tol=1e-3)
LossL2 = svm.LinearSVC(
penalty='l1', loss='squared_hinge', dual=False, tol=1e-3)
PenaltyL1 = svm.LinearSVC(
penalty='l2', loss='squared_hinge', dual=True, tol=1e-3)
model_set = [Standard, LossL2, PenaltyL1]
# グリッドサーチしたいパラメータCの値域をnp.logspaceで設定
tuned_parameters = [
{'C': np.logspace(-1, 2, 30)}
]
# 各モデルを一つずつCに関してグリッドサーチを行う
for model in model_set:
# 5-fold Cross-Validationで評価指標はprecision(適合率)を選択
clf = GridSearchCV(model, tuned_parameters, cv=5, scoring='precision')
# 設定したパラメータで学習しつつ検証を行う
clf.fit(data_train, label_train)
グリッドサーチには、一番良いスコアを返すbest_score_や、
一番いいスコアのモデル設定条件を返す、best_estimator_などがあります。
三種類のモデルパラメータで且つ一番いいパラメータCを保持して、
最終的なテストのスコアで最高のモデルを保存すればいいでしょう。
感想
-
実装に関しては簡単ではあるものの、GridSearchはあくまで特定範囲内での探索方法なので、
実際はベイズ推定などのパラメータ推定法を用いるべきであると思いました。 -
学生の時は理論ばかりやっていたのでここまでpythonのコードを書けるまで随分成長したとしみじみ
参考
最後に
**エキサイト Advent Calendar 2017**も明日でとうとう最終日です。
最後のトリは【3人できるユーザビリティテスト】、気になります!
メリークリスマス!
