はじめに
技術検証としてRAGを構築するにあたり、YomiToku(ヨミトク)を用いて、以下の3段階のプロセスで進めることにしました。
1)初期検証では、YomiToku(OSS版)をインストールするだけで利用可能なGoogle Colabを採用
2)次に、AWS上のEC2にYomiToku(OSS版)をインストールし、運用面も考慮した構成で構築を実施
3)最後に、本番環境ではAWS Marketplaceの「YomiToku-Pro」をAmazon SageMakerにデプロイして利用する
今回は、その中でも特に構築で苦労した「2)AWS上での構築」に関する備忘録となります。
Google ColabでOSS版YomitoTokuを試す
以下は、YomiTokuを試した手順です。
- Google Colabで新しいノートブックを作成
- YomiTokuをインストール
!pip install yomitoku - OCR対象のPDFファイルをアップロード
- YomiTokuでPDFをMarkdownへ変換
!yomitoku sample.pdf -o output_dir -f md --ignore_line_break
各パラメータの説明
・sample.pdf → 入力ファイル
・-o output_dir → 出力フォルダ
・-f md → Markdown形式で出力
・--ignore_line_break → 不自然な改行を抑制 - ページ毎に生成されたmdファイルを1ファイルにマージ
!ls output_dir/*.md | sort -V | xargs cat > merged.md
変換には数十分を要しましたが、容易にmdファイルを生成することが出来ました。
そこで実運用を想定し、EC2環境にYomiTokuをインストールしようとしたのが、裸足で地雷原に踏み出す行為の始まりだったのです。
YomiTokuをEC2に構築する
ここからが本題です。
実運用を想定し、以下の構成としました。
・OCR対象のPDFファイルをS3にアップロード
・EC2とS3を同期
・YomiTokuで変換したMarkdownファイルを再びS3に同期
利用者はAWSマネジメントコンソールからS3へファイルを配置するだけでよい設計とし、可能な限り運用負荷を下げることを目的としました。
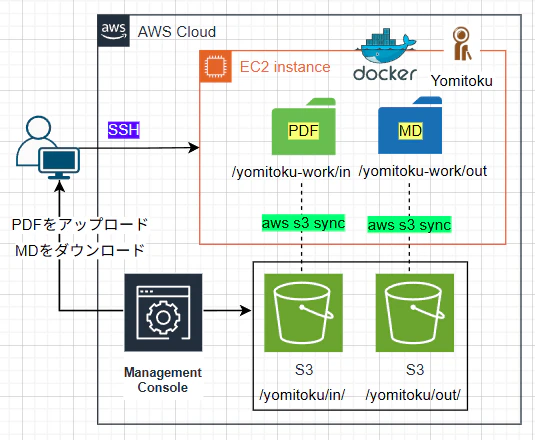
当記事では、S3のプレフィックスと同期するEC2のパスを以下とします。
S3のPDF格納プレフィックス:yomitoku-bucket/yomitoku/in/
S3のMD出力プレフィックス:yomitoku-bucket/yomitoku/out/
EC2のPDF格納パス:yomitoku-work/in
EC2のMD出力パス:yomitoku-work/out
以下に、AWSで環境構築した際、躓いた箇所を備忘録として残しておきます。
1. 事前準備
・EC2:Amazon Linux 2
・インスタンス:t3.medium(4GB)
・EBS:30GB
・IAMロール付与(重要)
IAMロール例
以下ポリシーを付与:
AmazonS3FullAccess(検証用)
※本番ではバケット限定ポリシー推奨
・S3:バケット作成
aws s3api create-bucket --bucket yomitoku-bucket --region ap-northeast-1 --create-bucket-configuration LocationConstraint=ap-northeast-1 `
変換前・変換後用のプレフィックスも作成します。
aws s3api put-object --bucket yomitoku-bucket --key yomitoku/in/
aws s3api put-object --bucket yomitoku-bucket --key yomitoku/out/
2. Docker環境準備
コンテナ実行環境としてDockerをインストールします。
sudo dnf install -y docker
yomitoku取得用にgitをインストールします。
sudo dnf install -y git
Dockerを起動します。
sudo systemctl start docker
EC2再起動後も自動起動するよう設定します。
sudo systemctl enable docker
dockerコマンドをsudoなしで実行できるよう、ユーザーをdockerグループへ追加します。
sudo usermod -aG docker ec2-user
設定を即時反映します。
newgrp docker
newgrp docker を行うことで、再ログインする手間を省きます
3. S3へPDFをアップロード
マネジメントコンソールから以下へアップロードします。
s3://yomitoku-bucket/yomitoku/in/
4. EC2作業ディレクトリ作成
mkdir -p ~/yomitoku-work/in
mkdir -p ~/yomitoku-work/out
5. S3 → EC2 同期
aws s3 sync s3://yomitoku-bucket/yomitoku/in/ ~/yomitoku-work/in/
6. YomiTokuイメージ作成
git clone https://github.com/kotaro-kinoshita/yomitoku.git
cd yomitoku
docker build -t yomitoku:cpu .
コマンド説明
・git clone:ソース取得
・docker build:依存関係含むコンテナ作成
・-t:イメージ名指定(GPUでなくCPU動作を前提としたので、yomitoku:cpuとした)
実はここに問題の原因が潜んでいました(詳細は後述)。
7. yomitokuでOCRを実行
docker run --rm -v ~/yomitoku-work/in:/work/in -v ~/yomitoku-work/out:/work/out --entrypoint yomitoku yomitoku:cpu /work/in -o /work/out -f md --ignore_line_break
コマンドパラメータの説明
・docker run : Dockerコンテナを新しく起動する
・--rm : 処理が終わったらコンテナを自動削除する
・-v : ホスト(EC2)とコンテナをマウントする(ホスト側パス:コンテナ側パス)
-v ~/yomitoku-work/in:/work/in
-v ~/yomitoku-work/out:/work/out
・--entrypoint yomitoku : コンテナ起動時に[yomitoku]コマンドを実行する
・yomitoku:cpu : 使用するdockerイメージ名
・/work/in : 入力ディレクトリ指定
・-o /work/out : 出力ディレクトリ指定
・-f md : 出力フォーマットをマークダウンに指定
・--ignore_line_break : 改行を無視して整形する
そして、ここから長い闘いが始まったのです。
上記コマンドを実行しても途中で処理が止まってしまうのです。
標準出力にも明確なエラーは表示されません。
WARNING - CUDA is not available. Use CPU instead. →CUDAでなくCPUで動く
INFO - Initialize TextDetector/Recognizer/LayoutParser/TableStructureRecognizer →初期化のログ
INFO - Processing file: /work/in/<InputFile.pdf> →PDFファイルをOCR処理
-> Cannot close object; pdfium library is destroyed. This may cause a memory leak. →後始末時のログ
ログ取得方法の改善
ChatGPT先生に散々聞きまくった結果、肝心のエラー部分が出力されていないことが分かりました。
そこで、ログをファイルにも保存することと、tee でパイプ経由にすることでエラーログのバッファリングができるように変更しました。
docker run --rm \
-v ~/yomitoku-work/in:/work/in \
-v ~/yomitoku-work/out:/work/out \
--entrypoint yomitoku yomitoku:cpu /work/in -o /work/out -f md \
2>&1 | tee ~/yomitoku-work/yomitoku_result.log
そして、ようやくエラーの真因に辿り着くことが出来ました。
AttributeError: 'PdfDocument' object has no attribute 'render'
yomitoku が「PdfDocument.render() がある前提」でPDFを画像化しようとしているのに、コンテナ内の pypdfium2(PDFiumのPythonバインディング)が新しい版で PdfDocument.render() を削除していて、API不一致となっていました。
実際、pypdfium2 v5系では **PdfDocument.render() が削除された(ページ単位レンダリングへ移行)**という breaking change(破壊的変更) になっています。
その結果、yomitoku側がPDFを開けずにエラーとなっていました。
ValueError: Failed to open the PDF file
簡潔に言うと、Docker内のライブラリの依存関係が壊れていた。(こんなの分かるか!)
✅ 対処方法:
pypdfium2 を “古い互換版” に固定した新イメージを作成します。
いま使っている yomitoku:cpu をベースにして、pypdfium2 を v4系にダウングレードします。
7-1. EC2で作業ディレクトリ作成
mkdir -p ~/yomitoku-dockerfix && cd ~/yomitoku-dockerfix
7-2. Dockerfile作成
cat > Dockerfile <<'EOF'
FROM yomitoku:cpu
# pypdfium2 v5でPdfDocument.render()が削除され、yomitoku側が落ちるため
# v4系に固定する(まずは広めに <5 でOK)
RUN pip install --no-cache-dir "pypdfium2<5"
# 念のためyomitokuも更新(任意:現状維持したいなら削除してOK)
RUN pip install --no-cache-dir --upgrade yomitoku
EOF
7-3. 新イメージをビルド(yomitoku:cpu-fixで新イメージを作成)
docker build -t yomitoku:cpu-fix .
7-4. 新イメージでOCR変換を再実行
docker run --rm \
-v ~/yomitoku-work/in:/work/in \
-v ~/yomitoku-work/out:/work/out \
--entrypoint yomitoku yomitoku:cpu-fix \
/work/in/ -o /work/out -f md --ignore_line_break
Dockerファイルで依存関係を再構築することでOCR変換が無事に成功しました。
Google Colabで動作していたのは、依存ライブラリの組み合わせが互換状態だったためと考えられます。
しかし、まだこれで終わりではありません。
変換したマークダウンファイルは、ページ毎に複数ファイルで生成されています。
最後にこれらをページ順にソートして1ファイルにマージする必要があります。
8. mdファイルを1つに結合
out配下のmdをページ順に結合:
cd ~/yomitoku-work/out
ls *.md | sort | xargs cat > merged_output.md
9. EC2 → S3 同期
aws s3 sync ~/yomitoku-work/out/ s3://yomitoku-bucket/yomitoku/out/
差分のみ同期されます。
最後に
これでRAG向けのMarkdownファイルを準備できました。
yomitokuのように長時間処理や大量ログを出力するワークロードでは、
ログ管理と出力制御が非常に重要であることを実感しました。
今後は以下も検討していきたいです。
・ワンショット実行スクリプトの作成
・EventBridgeによる「S3アップロード → 自動変換」のイベント駆動化