
1.はじめに
アポロ株式会社でデータサイエンティストをしている安藤と申します。
生成AIを使ったVOC分析や、メディアにおける記事生成などを行っています。
Databricks Playground入門
Databricks でエージェント開発を始めようとすると、最初のハードルになりがちなのが「どこで試すか」という問題です。
Notebook を作るほどでもないが、モデルの挙動やプロンプト、Tools の設計は実際に動かしながら検証したい。
そんなときに便利なのが Databricks Playground です。
本記事では、Databricks Playground の基本的な役割から、主要な機能、そして実際に簡易エージェントを作成して Notebook に落とし込み、デプロイするまでの流れを一通り紹介します。
2. 導入・概要編
Playgroundとは何か
Databricks Playground は、LLM を使った処理やエージェントの振る舞いを 軽量かつ対話的に検証するための実験場のような位置づけの機能です。Notebook のようにクラスタ設定やコード管理を意識する必要がなく、UI 上でモデルを選択し、プロンプトや Tools を設定してすぐに試せる点が特徴です。特に GenAI 開発では、「まず動かしてみる」ことが非常に重要になります。
プロンプトの書き方ひとつで出力が大きく変わったり、Tools の切り方によってエージェントの使い勝手が変わったりするため、最初から完成形をコードで書くのは非効率です。
Playground を使うことで、こうした試行錯誤を Notebook とは切り離した場所で行い、設計が固まった段階で実装に進むという開発スタイルが取りやすくなります。
3.基本機能編
Playgroundでできること
Playground の画面は非常にシンプルですが、エージェント開発に必要な要素が一通り揃っています。ここでは、Playground で利用できる主な機能を、機能別に整理して紹介します。
モデルの選択
Playground では、利用する LLM を UI 上から簡単に選択できます。
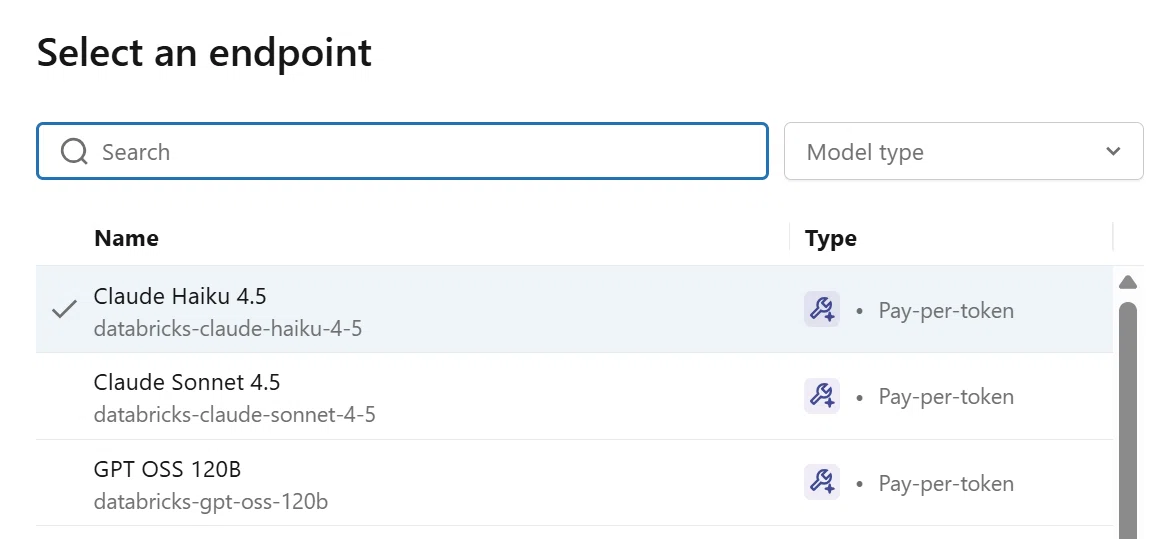
【LLMモデルの選択画面】
-
Databricks 上で利用可能な LLM をプルダウンで切り替え可能
-
同一プロンプトを複数モデルで試し、挙動や出力品質を比較できる
-
ユースケースに対して「どのモデルで十分か」を事前に確認できる
Notebook でモデル切り替え用のコードを書く前に、Playground 上で感触を掴めるため、モデル選定の初期コストを大きく下げられる点がメリットです。
Tools 関数の利用
Playground の中核となる機能の一つが Tools(関数呼び出し)です。
-
SQLやPython で定義した関数を Tools として登録可能
-
LLM が文脈を理解し、必要に応じて関数を呼び出す
-
関数の引数・戻り値を含めた一連の流れをその場で検証できる
エージェントが、「ユーザー入力を解釈 → 必要な処理を判断 → 関数を呼び出す」という振る舞いを、最小限の実装で確認できます。
Tools をどの粒度で切るべきか、どんな引数設計が適切かといったエージェント設計の初期検討に非常に向いている機能です。
システムプロンプト(System Prototype)の設定
Playground では、システムプロンプト(System Prototype)を明示的に設定できます。
-
エージェントの役割や前提条件を定義
-
口調や出力フォーマットの指定
-
Tools を使うべき条件や禁止事項の明示
-
エラー時・曖昧な入力時の振る舞いの指定
システムプロンプトを変更すると、その影響が即座に出力に反映されるため、「どの指示が挙動に効いているのか」を体感的に理解できます。
これにより、プロンプト設計の試行錯誤を高速に回すことができ、学習コストの低い形でエージェントの振る舞いを調整できます。
PlaygroundからNotebookへの引き継ぎ
Playground 自体はあくまで検証用の環境ですが、
ここで検討した内容は後続の実装にそのまま活かせます。
-
選定したモデル
-
調整済みのシステムプロンプト
-
Tools の構成や責務分割
これらを整理した上で Notebook に落とし込むことで、
実装フェーズではロジックや運用設計に中心に調整が可能です。「Playground → Notebook → デプロイ」という流れを意識することで、GenAI 開発全体の効率を高めることができます。
4.実践ユースケース編
簡易エージェントの作成からデプロイまで
ここからは、Databricks Playground を使って簡単なエージェントを作成し、最終的に Notebook に落とし込んでデプロイするまでの一連の流れを、ステップ形式で紹介します。
ここではPlayground を「試行錯誤の場」として活用することを目的とします。
Step 1:エージェントの目的を定義する
最初に行うのは、エージェントの目的を脳内でざっくりと定義することです。
この段階では、詳細な仕様や例外ケースまで詰める必要はありません。
-
ユーザーからどのような入力を受け取るのか
-
どのような情報を返したいのか
-
データ取得や計算が必要かどうか
といった点を整理できれば十分です。
例えば、「ユーザーの質問内容に応じてデータ取得用の Tools を呼び出し、その結果を分かりやすく要約して返す」といったレベルの定義で問題ありません。
Step 2:Playgroundで Tools を定義する
次に、Playground 上で必要最低限の Tools を定義します。
ここでは、エージェントが実行すべき処理を関数として切り出します。
例えば、
テーブルからデータを取得する関数
簡単な集計や加工を行う関数
などを用意し、エージェントがそれらを正しく呼び出せるかを確認します。
この段階では、関数の引数や戻り値の形式を実際に動かしながら調整します。
Toolsに関数を取り込むまでの流れは以下の通りです。
-
1.SQL または Python で Tools に取り込むための関数を作成します。
- a.以下は、SQL により指定したテーブルから情報を取得する関数の作成例です。
CREATE OR REPLACE FUNCTION aaa.bbb.get_table()
RETURNS ARRAY<STRUCT<
category STRING,
tag STRING
>>
RETURN
SELECT ARRAY_AGG(
STRUCT(
category,
tag
)
)
FROM (
SELECT
category,
tag
FROM aaa.bbb.tag_master_table
);
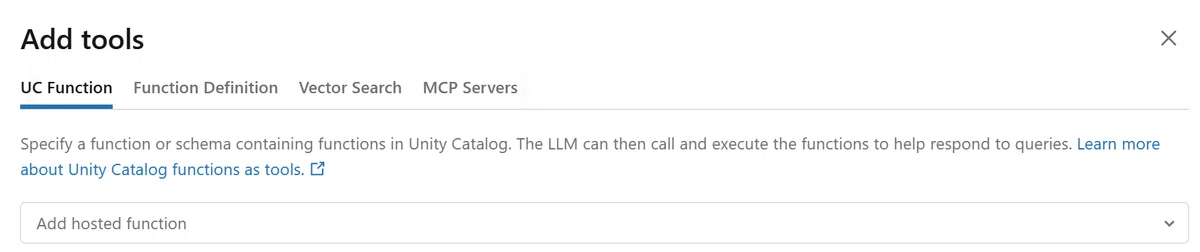
- a.上記の SQL を実行した場合、aaa.bbb.Function の配下に get_table という名前の関数が作成されます。
2.作成した関数は Databricks の Catalog の Functions 配下に登録されます。
3.Catalog の Function 配下に登録された関数を Tools から指定し取り込みます。
【Toolsの関数登録画面】

Step 3:システムプロンプトで振る舞いを調整する
Tools が一通り動くようになったら、システムプロンプト(System Prototype)を調整し、エージェントの振る舞いを整えていきます。
【システムプロンプトの設定画面】

-
どのような役割を持つエージェントか
-
どのタイミングで Tools を使うべきか
-
結果をどのような形式で返すか
といった点をプロンプトに明示し、出力の変化を確認します。
このフェーズは Playground の真価が最も発揮される部分であり、短いサイクルで「試す → 修正する」を繰り返すことができます。
Step 4:モデル設定と全体の挙動を確認する
プロンプトと Tools の調整が進んだら、モデル設定を含めた全体の挙動を確認します。
【モデルの挙動確認画面】(LLMへの質問と、それに対する回答の例)

-
選択しているモデルで十分な回答品質が得られているか
-
Tools が意図しないタイミングで呼ばれていないか
-
想定外の入力に対して破綻しないか
といった点を重点的にチェックします。
この段階で問題が見つかれば、Playground 上で即座に修正できるため、後工程での手戻りを大きく減らすことができます。
Step 5:Notebookに落とし込み、デプロイする
挙動が安定したら、Notebook への落とし込みです。
Playground で検証した以下の要素を整理し、Playground の UI 上からデプロイのため雛形コードをNotebook としてダウンロードが可能です。
-
利用するモデル設定
-
調整済みのシステムプロンプト
-
Tools のロジックと役割分担
Notebook の雛形コードを実行し、Databricks の Serving にデプロイすることで、エージェントを実際の業務フローに組み込むことができます。
デプロイしたモデルは Playground 上のモデル一覧から選択することも可能なため、ここでエージェントの動作チェックができます。
5.ハマりどころ・注意点
Playground は非常に便利な検証環境ですが、いくつか注意すべき点があります。
特に Tools を使ってテーブルやデータを扱う場合、Playground と Notebook では許容される仕様が異なるため、「Playground では動いたのに、Notebook にするとエラーになる」というケースが発生しがちです。
ここでは、公式ドキュメントで定義されている仕様を踏まえつつ、実際にハマりやすいポイントを整理します。
以下、Playgroundや使用するモデルに関する公式ドキュメントです。
Playground は成果物を保存・共有する場所ではない
まず大前提として、Playground は 検証用の環境 です。
-
プロンプトの試行錯誤
-
モデルの挙動確認
-
Tools 設計の初期検討
といった用途には最適ですが、最終的なロジックや設定を残す場所ではありません。
そのため、「Playground で動いたから完成」と考えるのではなく、
必ず Notebook に実装として落とすことを前提に利用する必要があります。
Playground は設計フェーズ、Notebook は実装・運用フェーズ、という役割分担を意識することが重要です。
Tools の Function では JSON 型の入出力しか認められない
公式ドキュメント上、Tools の Function はJSON としてシリアライズ可能な型のみを入出力として扱う仕様になっています。
具体的には、以下の型が前提です。
-
文字列(string)
-
数値(number)
-
配列(array)
-
オブジェクト(object)
Databricks のテーブルや DataFrame は、Tools の入出力として直接扱うことはできません。
Tools の中でテーブルを参照すること自体は可能ですが、LLM に渡す値は、必ず JSON に変換された結果である必要があります。そのため、Toolsのアウトプット形式は必ず上記4種類のいずれかの型とし、JSON形式に変換できる型を指定しましょう。
返却値がテーブルだと Notebook 実行時にエラーになる
この点は、Playground 利用時に最も誤解されやすいポイントです。
Playground の UI 上では、Tools の返却値がテーブル形式で表示されることがあります。
そのため、一見すると問題なく動作しているように見えます。
しかし、同じ Function を Notebook から実行すると、返却値がテーブルの場合はエラーになります。
Notebook 実行時には、返却値が 文字列・数値・配列・オブジェクト形式 でなければなりません。
NG 例:テーブルをそのまま返す Function
CREATEOR REPLACEFUNCTION sample.get_users_ng()
RETURNSTABLE (idINT, name STRING)
RETURN
SELECT id, name
FROM sample.users;
このようにテーブルを返す Function は、Playground の UI 上では表示できる場合がありますが、Tools として Notebook から呼び出すとエラーになります。
OK 例:JSON 形式に変換して返す Function
CREATEOR REPLACEFUNCTION sample.get_users_ok()
RETURNSARRAY<STRUCT<idINT, name STRING>>
RETURN
SELECT collect_list(
struct(id, name)
)
FROM sample.users;
このように、返却値を配列やオブジェクトなどの JSON 形式に変換することで、Notebook からも安全に利用できます。
テーブル全体を扱うとトークン数の上限に抵触しやすい
Tools の Function でテーブルを扱う際、テーブル全体をそのまま返す設計は避けるべきです。
Playground では、
-
Tools の入出力
-
LLM に渡されるコンテキスト
に対して トークン数の上限 が存在します。
行数やカラム数の多いテーブルをそのまま返すと、
-
トークン上限超過
-
レスポンスの途中切れ
-
モデルの不安定な挙動
といった問題が起こりやすくなります。
NG 例:テーブル全体を JSON 化して返す
CREATEOR REPLACEFUNCTION sample.get_all_logs_ng()
RETURNSARRAY<STRUCT<idINT, message STRING>>
RETURN
SELECT collect_list(struct(id, message))
FROM sample.logs;
データ量が増えると、簡単にトークン数の上限に達してしまいます。
OK 例:必要最小限に絞る/集計済みの結果を返す
# 必要最小限に絞る
CREATEOR REPLACEFUNCTION sample.get_recent_logs_ok(limit_numINT)
RETURNSARRAY<STRUCT<idINT, message STRING>>
RETURN
SELECT collect_list(struct(id, message))
FROM (
SELECT id, message
FROM sample.logs
ORDERBY created_atDESC
LIMIT limit_num
);
# 集計済みの結果
CREATE OR REPLACE FUNCTION sample.count_logs_ok()
RETURNS INT
RETURN (
SELECT COUNT(*)
FROM sample.logs
);
このように、
-
フィルタ
-
集計
-
件数制限
を Tools 側で行い、LLM には判断に必要な最小限の情報だけを渡す設計が推奨されます。
Playground には過去の質問応答をチェーンする機能はない
Playground は対話形式の UI を提供していますが、Notebook のように過去の質問応答や実行結果を明示的にチェーンして管理する機能はありません。そのため、
-
長い文脈を前提とした対話
-
状態を持つエージェントの検証
には向いていません。
Playground は、
-
単発または短い文脈での挙動確認
-
プロンプトや Tools 設計の初期検証
に使い、状態管理や継続的な文脈保持は Notebook 側で実装する、という使い分けが現実的です。
6.おわりに
Databricks Playground は、GenAI やエージェント開発における「最初の一歩」を大きく楽にしてくれる機能です。
Notebook を作る前に Playground で設計を固めることで、開発スピードと品質の両方を向上させることができます。
アポロでは生成AI活用の悩み事やエンタープライズでの実装に関して、設計・開発のご支援、社内AI人材育成の研修なども実施しています。興味がある方はお気軽に下記連絡先までお問い合わせください。
また、生成AI活用の知見を所属会社問わず共有していくことも、生成AIエンジニアリング力を上げるためには重要だと思いますので、質問や議論もお気軽に安藤までお声掛けください。
最後までお読みいただき、ありがとうございました。
これからも役立つ技術情報をお届けしますので、ぜひフォローお願いします!
アポロでは仲間を積極募集中です!
ご興味のある方は是非求人をチェックしてみてください!