はじめに
Claude Code に指示を飛ばしたときに、その裏側で具体的に何が起きているのか気になったことはないでしょうか。
たとえば、裏側でサブエージェントが何体起動され、何のファイルを読み、どれくらいのトークンを消費したのかや、特定のセッション内で何行のコードを生成・削除したかを可視化し、チームの生産性を確認したい場合などです。
こういう時のために Claude Code は OpenTelemetry(OTel)に対応しており、テレメトリを外部ツールに送信できます。そこで今回、私はClaude Codeのベータ機能(2026/4/20時点)であるトレース送信機能を用い、Langfuseと連携させてその中身を観察してみました。
しかしながら、結論からいうと、サブエージェントとエージェントチームのトレースが期待した形で取得できない、という検証結果になりました。
本記事では、Claude Codeにおけるテレメトリの有効化から、Langfuseとのセットアップ手順、そしてトレースの観察によって得られた発見を共有します。
記事の内容はすべて2026年4月20日時点のものです。Claude Codeはかなりの頻度でアップデートされているため、最新バージョンでは挙動が変化している可能性がある点はご承知おきください。
可観測性の三本柱
Claude Code のセットアップ手順に入る前に、OpenTelemetry(OTel)が定義する三つの要素と Otel Collector について簡単に整理します。
OTelとはアプリケーションの振る舞いを外部ツールに送信するための業界標準仕様です。いわば「可観測性のための共通言語」で、この仕様に沿ってデータを出力しておけば、Grafana・Langfuse・Datadogなど様々なツールで受け取って可視化できます。
OTelが公式に定義するシグナルは三種類あります。
Metrics(メトリクス)
実行時に計測される数値の時系列データです。「何が起きたか」ではなく「どのくらい使ったか」を把握するために使います。カウンター・ゲージ・ヒストグラムなどの形式で集計されます。
Claude Codeで送信されるメトリクスの例:
| メトリクス名 | 意味 |
|---|---|
claude_code.token.usage |
トークン使用量(input / output / cache_read 別) |
claude_code.cost.usage |
API呼び出しのコスト |
claude_code.session.count |
セッション数 |
claude_code.active_time.total |
合計アクティブ時間 (秒単位) |
claude_code.lines_of_code.count |
Claude Codeが編集した行数 |
claude_code.code_edit_tool.decision |
コード編集ツールの権限決定の数 |
claude_code.pull_request.count |
作成されたプルリクエストの数 |
claude_code.pull_request.count |
作成された git コミットの数 |
claude_code.commit.count |
作成されたプルリクエストの数 |
最新の状況についてはClaude Codeの公式ドキュメントを参照してください。
メトリクスはGrafanaのような時系列DBと相性がよく、「今日のトークン消費量の推移」や「生成コード数とセッション時間」などをグラフで可視化できます。
Logs(ログ)
タイムスタンプ付きのイベントの記録です。「その瞬間に具体的に何が起きたか」を記述します。OTelではEventsもログの一種として扱われます。
Claude Codeでは OTEL_LOGS_EXPORTER=console を設定することでターミナルに構造化ログを出力できます。ログにはuser_prompt・tool_result・api_request などのイベントが含まれており、同一の prompt.id で紐づけることで1回のやり取りの流れを追跡できます。
Traces / Spans(トレース / スパン)
処理の親子関係と実行順序を構造的に記録するのがトレースです。
- Trace:1回のプロンプト送信から完了までに発生した一連の処理のまとまり
- Span:Trace内の個別の処理単位(ツール呼び出し1回 ≒ 1 Span)
各Spanは trace_id(どのTraceに属するか)と parent_id(どのSpanから呼ばれたか)を持ち、これによって処理の木構造が形成されます。
claude_code.interaction ← Traceのルートスパン
├── claude_code.llm_request ← LLMへのリクエスト
└── claude_code.tool ← ツール呼び出し
└── claude_code.tool.execution ← 実際のツール実行
上記のように、Claude CodeがどのツールをどのLLMリクエストの中で呼び出したかが木構造で可視化されます。
OTel Collector とは
OTel Collector は、テレメトリデータを受け取り・加工し・送り出すためのミドルウェアです。アプリケーション(Claude Code)とバックエンド(Langfuse・Prometheus)の間に置くことで、データの振り分けや変換を担います。
OTel Collector の設定はReceivers / Processors / Exporters / Pipelinesの4要素で構成されます。
| 要素 | 役割 | 今回の例 |
|---|---|---|
| Receivers | データの受け口 | Claude Code から OTLP/gRPC でデータ受信 |
| Processors | データの加工・整形 | 属性名の変換・バッチ処理 |
| Exporters | データを | Langfuse・Prometheus などの外部ツールへ転送 |
| Pipelines | 上記を繋ぐ | Traces と Metrics で別ルートを定義 |
Processors を活用することで属性名の変換・フィルタリングなど柔軟なデータ変換が可能です。今回はこれを活用して Claude Code と Langfuse の属性名の乖離を吸収しました。
実際の手順 -Claude Code でテレメトリを有効化する-
それでは、実際に Claude Code でテレメトリ送信を有効化し、Langfuse などをセットアップしていきましょう。今回の構成は下の図のようになっています。
全体構成
Claude Codeが送信したテレメトリは、まず OTel Collector が一括で受け取ります。Collector はトレースを Langfuse へ、メトリクスを Prometheus 経由で Grafana へ振り分ける構成です。
STEP 1:環境変数の設定
まずは公式ドキュメントの記述通りに環境変数を追加していきます。
今回追加した環境変数は下記のとおりです。
# 1. テレメトリの基本設定
CLAUDE_CODE_ENABLE_TELEMETRY=1 # テレメトリを有効化する
# 2. OTLP エンドポイントとプロトコルの設定
OTEL_EXPORTER_OTLP_ENDPOINT=http://localhost:4317
OTEL_EXPORTER_OTLP_PROTOCOL=grpc
# 3. エクスポーターの選択
OTEL_LOGS_EXPORTER=console
OTEL_METRICS_EXPORTER=otlp
# 4. トレースの設定(ベータ機能)
CLAUDE_CODE_ENHANCED_TELEMETRY_BETA=1 # トレースを有効化するのに必要
OTEL_TRACES_EXPORTER=otlp # トレースのエクスポーターを選択
# 5. コンテンツ記録の設定(※セキュリティに注意)
OTEL_LOG_TOOL_CONTENT=1
OTEL_LOG_TOOL_DETAILS=1
OTEL_LOG_USER_PROMPTS=1
※今回はWindows環境で検証を行っています。
セキュリティについて
今回の検証では詳細な挙動の追跡のため、ユーザープロンプトやツールの実行詳細をトレースに含める設定にしています。実際の環境では機密情報や個人情報の流出リスクがあるため、これらはトレースに含めない設定にすることをお勧めします。
具体的には以下のデータがテレメトリとして外部ツールに送信されます:
-
OTEL_LOG_USER_PROMPTS=1:ユーザーが入力したプロンプト全文。機密情報・個人情報が含まれる可能性あり -
OTEL_LOG_TOOL_DETAILS=1:実行した Bash コマンド・MCP サーバー名・ツール引数(ファイルパス、URLなど) -
OTEL_LOG_TOOL_CONTENT=1:Readツールで読み込んだファイルの生のコンテンツ・Bash コマンドの実行結果
クラウドサービスに転送する場合や、ソースコード・設定ファイルを扱うリポジトリでは特に注意が必要です。
ログの出力先について
Logs を otlp で送るには Loki や Elasticsearch などの専用ログストレージが必要ですが、今回の構成には含めていません。console にしておけばターミナルに直接出力されるため、今回はOTEL_LOGS_EXPORTER=consoleに設定しています。
STEP 2:Langfuse を起動する
環境変数の設定が終わったら、トレースの可視化プラットフォームである Langfuse をセルフホストで起動します。
git clone https://github.com/langfuse/langfuse.git langfuse-local
cd langfuse-local
# docker-compose.yml 内の CHANGEME を任意の文字列に置き換える
docker compose up -d
起動後、 http://localhost:3000 にアクセスしてアカウントとプロジェクトを作成し、settings から Public Key・Secret Key を取得します。
次に、OTel Collector が Langfuse に接続するための認証文字列を生成します。Langfuse は Basic 認証を使用しており、公開鍵:秘密鍵 を Base64 エンコードした文字列をヘッダーに付与する必要があります。
# Windowsの場合(PowerShell)
[Convert]::ToBase64String([Text.Encoding]::UTF8.GetBytes("pk-lf-xxx:sk-lf-xxx"))
# macOS / Linux の場合
echo -n "pk-lf-xxx:sk-lf-xxx" | base64 -w 0
生成した認証文字列を後の工程で使用するために .env ファイルなどに控えておきます。
echo "LANGFUSE_AUTH_BASIC=<先ほど生成したBase64文字列>" > .env
STEP 3:OTel Collector・Prometheus・Grafana を起動する
OTel Collector・Prometheus・Grafana を docker compose でまとめて起動します。
# docker-compose.yml
services:
otel-collector:
image: otel/opentelemetry-collector-contrib:latest
volumes:
- ./otel-collector-config.yaml:/etc/otelcol-contrib/config.yaml
ports:
- "4317:4317" # OTLP gRPC
- "4318:4318" # OTLP HTTP
env_file:
- .env # LANGFUSE_AUTH_BASIC を注入
prometheus:
image: prom/prometheus:latest
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- "9092:9090" # 9090 は Langfuse の MinIO と競合するため変更
grafana:
image: grafana/grafana:latest
volumes:
- ./grafana/provisioning:/etc/grafana/provisioning
ports:
- "3001:3000" # 3000 は Langfuse と競合するため変更
Langfuse がポート 3000・9090 を使用するため、Grafana は 3001、Prometheus は 9092 にずらしています。
OTel Collector の設定
OTel Collector の設定ファイルではいくつか Claude Code 用の設定を行っています。
# otel-collector-config.yaml
# ポート4317でgrpcプロトコルを待ち受ける設定
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
processors:
batch:
timeout: 1s
memory_limiter:
check_interval: 1s
limit_mib: 512
transform/langfuse_compat:
trace_statements:
- context: span
statements:
# gen_ai.system 属性を anthropic に設定
- set(attributes["gen_ai.system"], "anthropic")
# attributes["model"] を gen_ai.request.model にコピー
- set(attributes["gen_ai.request.model"], attributes["model"]) where attributes["model"] != nil
# input_tokens, output_tokens をLangfuseが認識できる形式の数値型に変換
- set(attributes["gen_ai.usage.input_tokens"], Int(attributes["input_tokens"])) where attributes["input_tokens"] != nil
- set(attributes["gen_ai.usage.output_tokens"], Int(attributes["output_tokens"])) where attributes["output_tokens"] != nil
exporters:
prometheus:
endpoint: "0.0.0.0:8889"
otlphttp/langfuse:
endpoint: "http://host.docker.internal:3000/api/public/otel"
headers:
Authorization: "Basic ${env:LANGFUSE_AUTH_BASIC}"
service:
pipelines:
metrics:
receivers: [otlp]
processors: [memory_limiter, batch]
exporters: [prometheus]
traces:
receivers: [otlp]
processors: [memory_limiter, batch, transform/langfuse_compat]
exporters: [otlphttp/langfuse]
transform/langfuse_compat が Claude Code 対応のポイントです。
# otel-collector-config.yaml 抜粋
transform/langfuse_compat:
trace_statements:
- context: span
statements:
# gen_ai.system 属性を anthropic に設定
- set(attributes["gen_ai.system"], "anthropic")
# attributes["model"] を gen_ai.request.model にコピー
- set(attributes["gen_ai.request.model"], attributes["model"]) where attributes["model"] != nil
# input_tokens, output_tokens をLangfuseが認識できる形式の数値型に変換
- set(attributes["gen_ai.usage.input_tokens"], Int(attributes["input_tokens"])) where attributes["input_tokens"] != nil
- set(attributes["gen_ai.usage.output_tokens"], Int(attributes["output_tokens"])) where attributes["output_tokens"] != nil
Langfuse は GenAI Semantic Conventions に準拠した属性名(gen_ai.usage.input_tokens 等)でトークン数・コストを読み取ります。一方、Claude Code の公式仕様では input_tokens・output_tokens という属性名が定義されており、スパンもこの名前で送信されます。この名前の乖離により、そのままでは Langfuse でのコスト集計などが機能しません。
そこで、transform プロセッサーを挟むことで、アプリケーション(Claude Code)側を一切変更せずに、インフラレベルで属性名を変換できます。
Claude Code のスパンはトークン数を文字列("3")で送信します。Langfuse は整数を期待するため、Int() で明示的に変換する必要があります。
Langfuse セルフホスト版の注意点
また、セルフホスト版の Langfuse はモデルの価格情報が登録されていない状態で起動します。transform プロセッサーでトークン数の属性名変換が完了していても、モデル定義がなければコストは $0.00 のままです。
Settings → Models → Add model から使用するモデルを手動で登録します。

| フィールド | 値の例 |
|---|---|
| Model name | claude-sonnet-4-6 |
| Match pattern |
claude-sonnet-4-6(スパンの model 属性値と完全一致) |
| input |
0.000003($3 / MTok) |
| output |
0.000015($15 / MTok) |
| cache_read_input_tokens |
0.0000003($0.30 / MTok) |
Match pattern がスパンの model 属性値と一文字でも違うとコストは計上されません。Langfuse の Trace 詳細でスパンの model 属性値を確認してから登録するのが確実です。
属性名の変換・モデルの価格情報の登録まで行うと、Langfuse の Home からコストなどが可視化されるようになります。
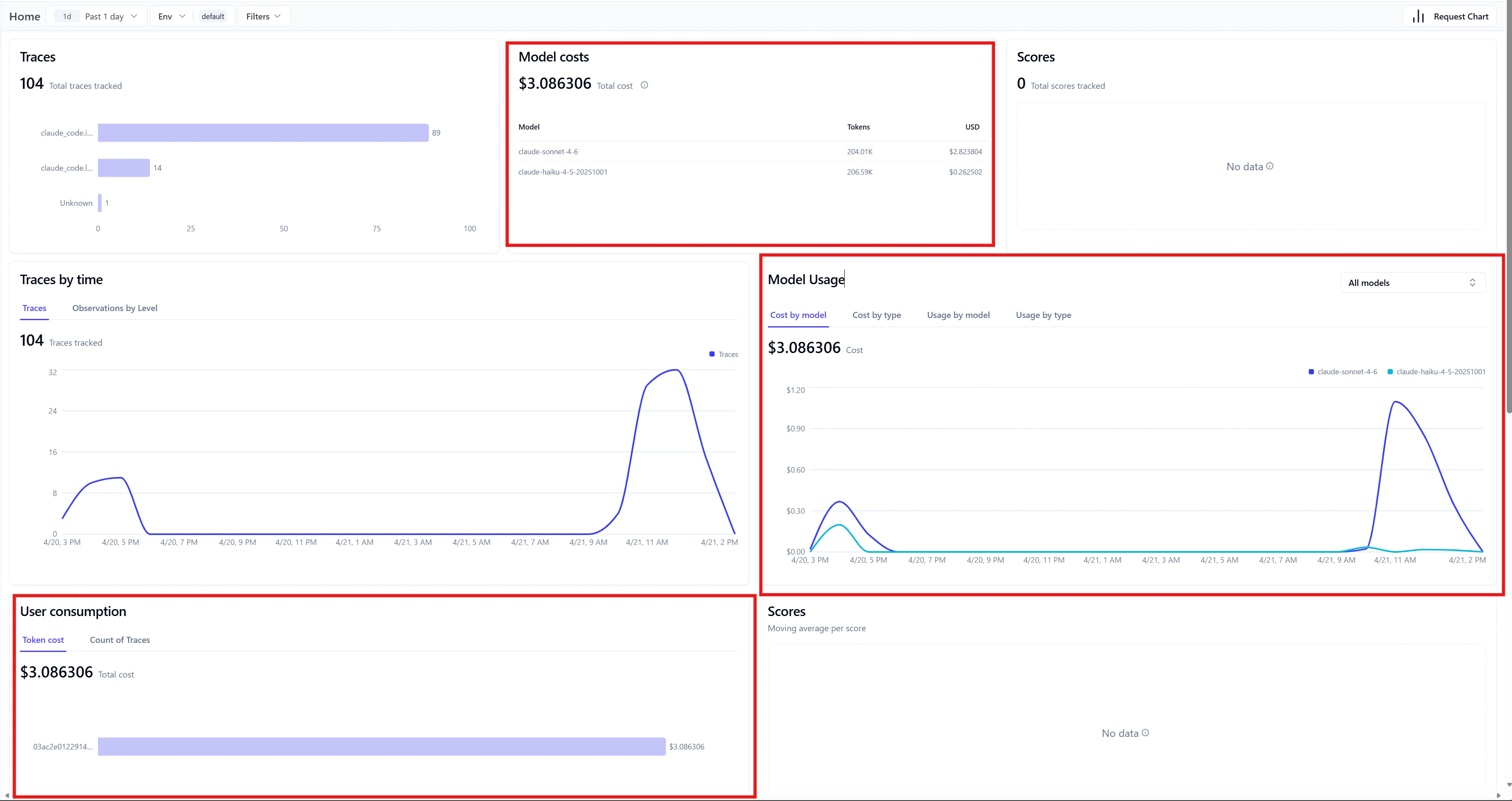
今回は Grafana もセットアップしているため、そちらでメトリクスを確認する分には不要なひと手間ですが、langfuse 単体でもコストが可視化されるようになるメリットがあります。
三本柱の使い分け
改めてそれぞれのシグナルの確認場所をまとめると、今回は下記のようになっています。
| シグナル | 何を知るか | 確認場所 |
|---|---|---|
| Metrics | トークン消費量、コスト推移、アクティブ時間などの統計データ | Grafana |
| Logs | 特定の瞬間におけるイベント、エラーメッセージ、詳細な入出力内容 | ターミナル |
| Traces | LLM実行フローの追跡、処理の親子関係、依存構造 | Langfuse |
トレース観測 -シンプルなプロンプトの場合-
今回の構成でテレメトリが正常に発信されているかを確認するため、まずはシンプルなプロンプトで単純なタスクを Claude Code に実行させ、そのテレメトリを Langfuse で確認しました。
使用したプロンプト:
「storage.py の中身を読んで、何をしているファイルか日本語で説明して。」
実際に Langfuse に出力されたトレースが下記です(一部マスクしています)。

このトレースでは1つの trace_id(34caf48eed2e51bbed9689bfdc98a84b) のもとに全スパンが収まっています。内部には claude_code.llm_request が3つ、claude_code.tool が2つ(Glob と Read)含まれています。
Claude が「まず Glob でファイルを探し、次に Read で内容を読み、最後に回答を生成する」という流れを複数の LLM 呼び出しで進めた痕跡です。ツール実行も含めてすべてが1つのトレースとして追跡されており、シンプルなウォーターフォール型のトレース構造になっていることが確認できました。
プロンプトキャッシングが効いていた
このトレースで目立ったのは最後の llm_request スパンの属性値です。
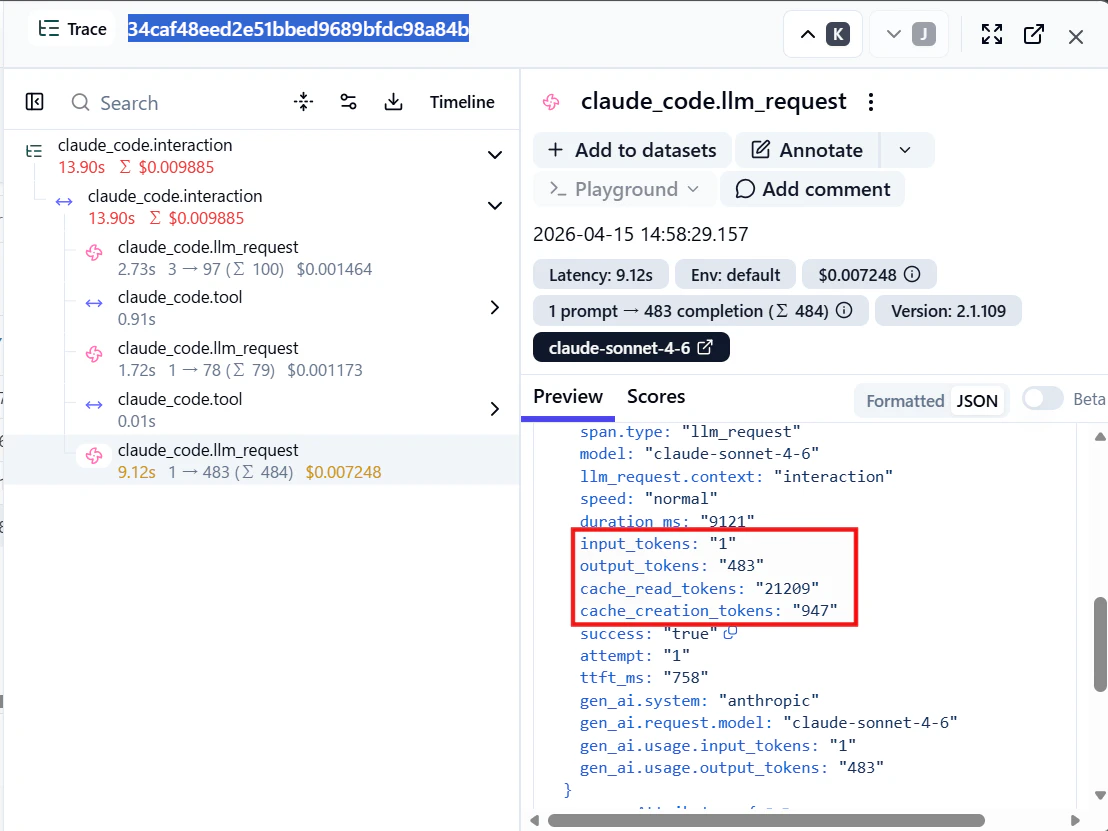
input_tokens = 1
output_tokens = 483
cache_read_tokens = 21,209
cache_creation_tokens = 947
input_tokens がわずか1に対して cache_read_tokens が21,209でした。新たにLLMへ渡したトークンはほぼゼロで、コンテキストのほぼ全てがプロンプトキャッシュから供給されてることがわかります。
コスト内訳でみると output(483トークン, 約$0.007)に対してキャッシュ読み取り(21,209トークン、約$0.006)が肉薄しており、キャッシュヒットがなければコストが膨らんでいたであろうことが見て取れます。
プロンプトキャッシングとは
Anthropic のモデルには、会話の中で繰り返し登場する大きなコンテキスト(システムプロンプト・ツール定義・長い会話履歴など)をキャッシュする仕組みがあります。一度キャッシュされた内容は次のリクエストでは再処理されず、キャッシュから読み出されます。通常の input トークンに比べてキャッシュ読み取りは約1/10のコストで済むため、長いコンテキストを持つセッションではコスト削減効果が大きくなります。
公式:プロンプトキャッシング
今回これほどキャッシュが多かった理由
このプロンプトは同じセッション内の7回目のやり取りでした(スパンの interaction.sequence: "7" で確認できます)。Claude Code はツール定義・CLAUDE.md の内容・それまでの会話履歴などをコンテキストとして蓄積しており、これらがすでにキャッシュに乗っていました。新たに送信したのはユーザーのプロンプト本文だけだったため、input_tokens=1 という極端に小さい値になっていたと考えられます。逆に言えば、2万トークン以上の文脈をキャッシュから引き出して回答を生成していたことになります。
サブエージェントを並列で起動した場合
次に、複数のサブエージェントを並列で動かすケースを試しました。
使用したプロンプト:
「Agent ツールを使って、3つの独立したサブエージェントを並列で起動してください。それぞれ以下の観点で trace-test/ 配下を調査し、最後に結果を統合してレポートにまとめてください。(コード品質 / テスト網羅性 / ドキュメントの過不足)」
期待していた構造
OTel の分散トレーシングでは、親プロセスが子プロセスを生成するときに traceparent ヘッダー を引き渡すことで、すべての処理を1つのトレースとして統合できます。
この仕組みが機能すれば、次のような入れ子構造がひとつのトレースとして Langfuse に届くはずでした。
claude_code.interaction(親)
├── claude_code.llm_request ← 計画立案
├── claude_code.tool (Agent) × 3 ← サブエージェント呼び出し(並列)
│ └── claude_code.interaction ← 子エージェントの対話
│ ├── claude_code.llm_request
│ └── claude_code.tool (Read, Grep 等)
└── claude_code.llm_request ← 統合レポート生成
大量の独立したトレース
しかし、実際には多数の独立したトレースが生成されました。
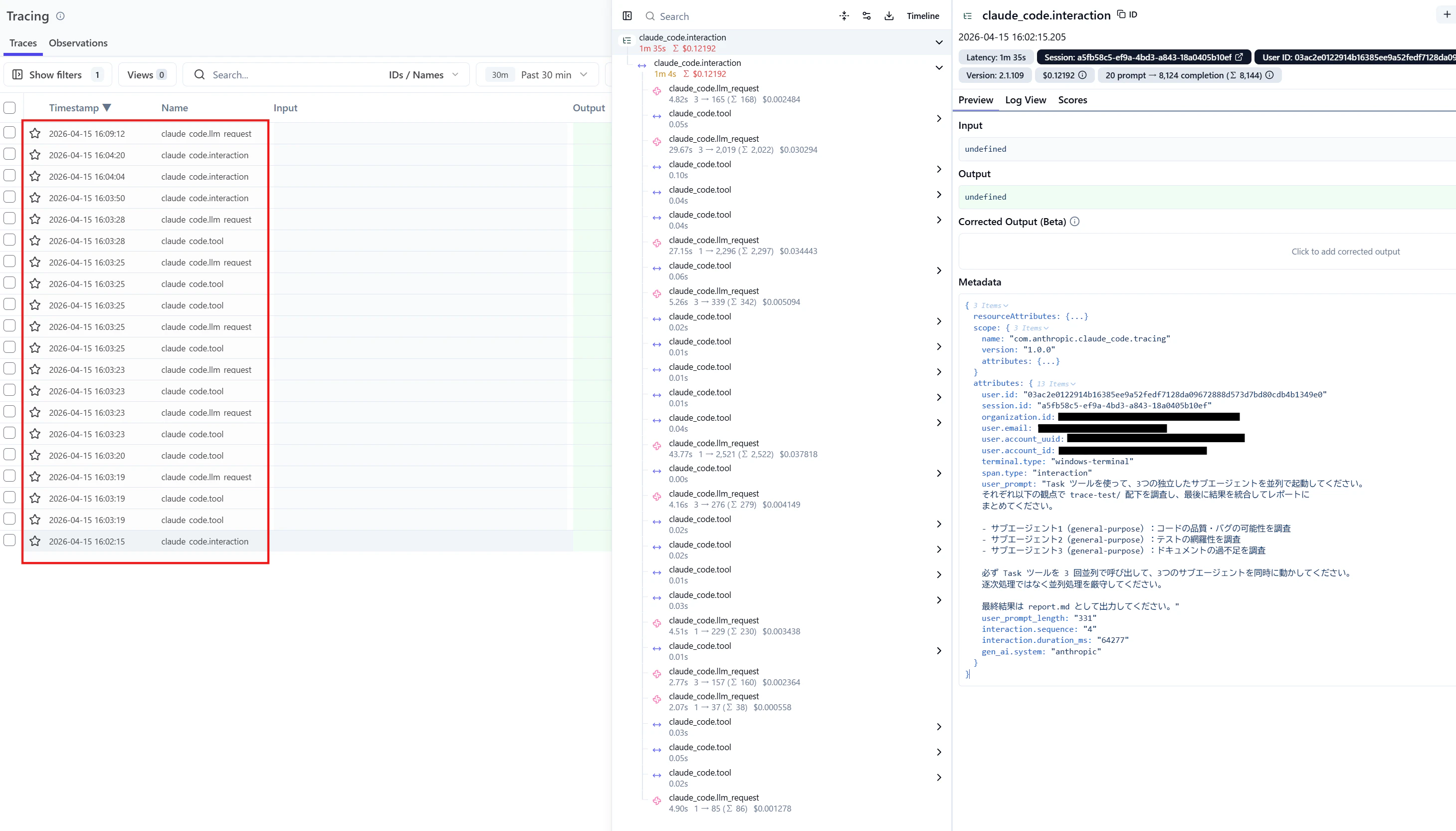
画像左の赤枠の部分が、サブエージェントを並列で動かすプロンプトで生成されたトレース群です。それぞれが親子関係をもって一つのトレースに収まるのではなく、独立したトレースとして表示されていました。

親トレース側を確認すると、確かに tool_name: "Agent" のスパンが3つ存在しており(画像赤枠)、サブエージェントを正しく呼び出しています。しかし、各サブエージェントはそれぞれ別の trace_id を持つ独立したルートスパンになっており、親子の繋がりはトレース上に現れません。
さらにサブエージェントが複数ターンにわたって動作する場合、ターンごとに新しいルートスパンが作られるため、実際のトレース一覧はサブエージェント数の数倍に膨れ上がっていました。
| 項目 | シンプルなタスク | サブエージェント利用時 |
|---|---|---|
| トレース数 | 1 | 断片化 |
| スパンの木構造 | 一つのトレースに繋がっている | 親子が繋がっていない |
| Langfuse での全体把握 | 1トレース | タイムスタンプで手動照合が必要 |
なぜ入れ子にならないのか
OTel の分散トレーシングで親子のスパンを繋ぐには、子プロセスを起動するときに TRACEPARENT(W3C TraceContext)を環境変数などの形で渡す必要があります。親の trace_id を子が知らなければ、子は自身を「起点(ルート)」と認識し、新しいルートトレースを独立して作ってしまいます。今回の検証で見られた挙動は、まさにこのコンテキスト伝播が途切れている状態でした。
親エージェント → trace-id: AAA(独立)
子エージェント1 → trace-id: BBB(独立)
子エージェント2 → trace-id: CCC(独立)
子エージェント3 → trace-id: DDD(独立)
Claude Code は v2.1.97/98(2026年4月)以降、Bash ツールが実行するシェルコマンドについては TRACEPARENT を自動注入するようになっています(公式ドキュメント / Release v2.1.110)。一方、Agent ツールで起動するサブエージェントへの伝播については、現時点(2026年4月20日)で公式の記述は見当たりません。実際に試した結果、サブエージェントはそれぞれ独立したトレースを生成しており、親子関係が繋がっていませんでした。
Traces 機能自体がベータ扱いであり、この挙動は今後変わる可能性があります。
エージェントチーム(Experimental)での挙動
なお、エージェントチーム(CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1)においても同様の検証を行いましたが、結果は同じでした。メンバーごとに独立したトレースが断片化して生成され、チーム間のメッセージ送受信(SendMessage)はスパンとして現れませんでした。
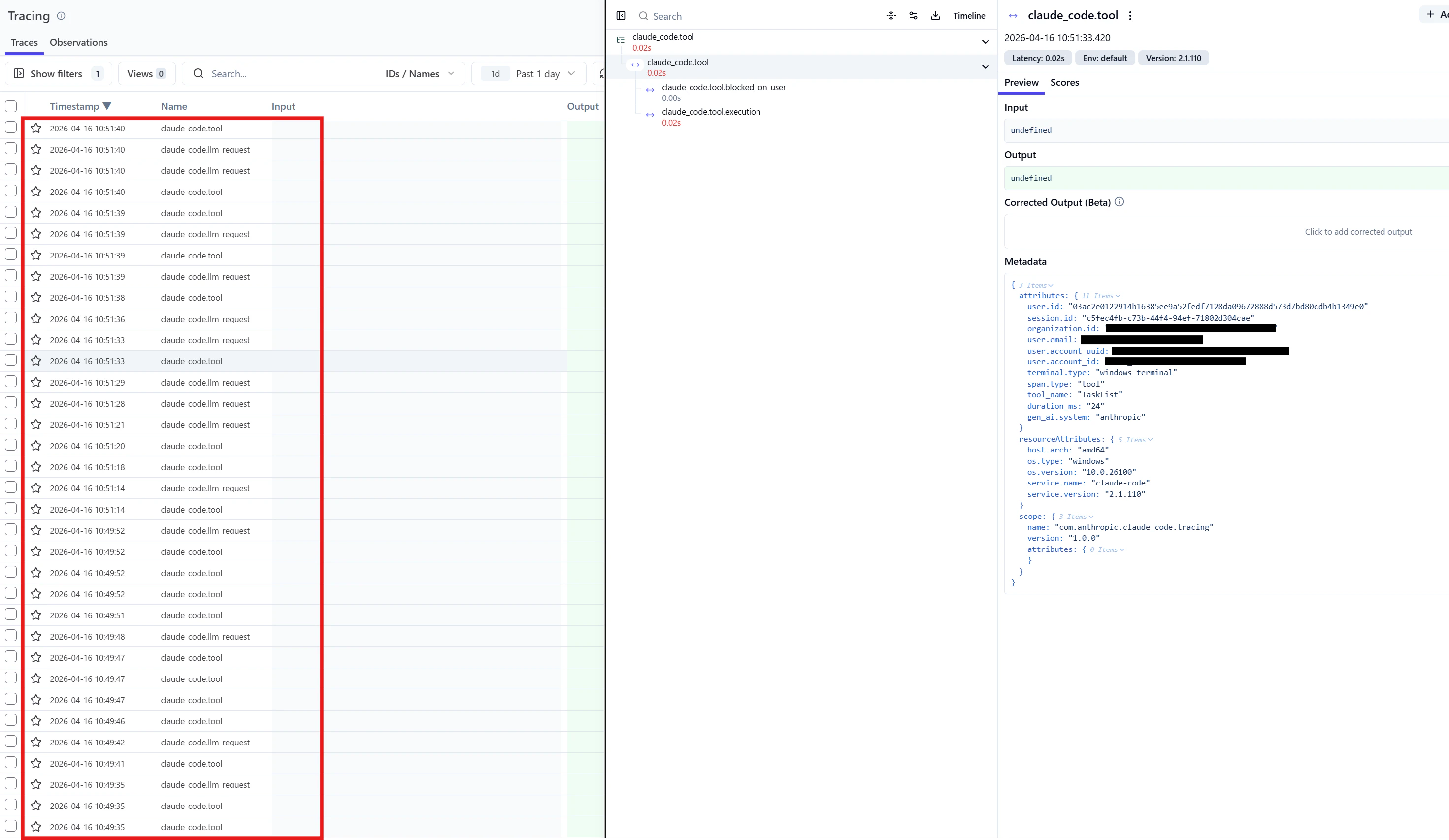
エージェント間のトレースを繋げるには
v2.1.110 以降、SDK やヘッドレスセッション(-p)で起動した Claude Code は環境変数から TRACEPARENT を読み取れるようになっています(Release v2.1.110)。つまり Agent SDK などを使って自前のオーケストレーターからエージェントを呼び出す構成であれば、呼び出し元が TRACEPARENT を渡すことで、呼び出し元のトレースにClaude Codeの実行を1つのスパンとして接続することが可能です。
ただし、Claude Code内部のサブエージェント実行まで含めてトレースを自動的に階層構造として可視化する機能は、現時点では提供されていません。また、これはターミナルで claude を対話的に使う使用法とは大きく異なります。
現時点で Claude Code の全体像をトレースで追いたい要件がある場合は、Agent SDKなどをベースに、独自にspan管理を行う設計が必要になるでしょう。
まとめ
今回、Langfuse を使って Claude Code のテレメトリを実際に観察して、気づいたことを整理します。
見えたもの
- 1回のプロンプトに対して Glob・Read などのツールがどの順番で呼ばれたか
-
llm_requestごとのトークン数・コスト・レイテンシ - プロンプトキャッシュがどれだけ効いているか(
cache_read_tokensの実数)
これらは Langfuse のトレース画面を開くだけで確認でき、普段の開発では気づけないコスト構造が見えてくるという点で、可観測性を導入する価値を実感できました。
見えなかったもの
- サブエージェントや Agent チームの全体像(入れ子のトレース)
- エージェントチームメンバー間のメッセージ送受信
これらはトレースとして現れません。サブエージェントを使うほど断片化が進み、Langfuse 上では大量の独立したトレースが並ぶだけになります。現状の仕様では、サブエージェント等を活用するほどトレースの断片化が進んでしまいます。
現状の位置づけ
Claude Code の Traces 機能は現時点でベータ扱いであり、属性名も GenAI Semantic Conventions とは異なる独自仕様を使っています(OTel Collector の transform プロセッサーで吸収できますが、一手間必要です)。OTel 対応も今後、継続発展していくことが期待されます。
まずは「最小構成」から始めてみる
とはいえ、Claude Code のテレメトリはかなり簡単に有効化できます。最小構成であれば環境変数2行を追加するだけで始められます:
export CLAUDE_CODE_ENABLE_TELEMETRY=1
export OTEL_METRICS_EXPORTER=console
これだけでメトリクスが流れ始め、トークン消費量やコストがリアルタイムに見えるようになります。まずはテレメトリを有効化し、どんな値が流れるのか意識的に観察することで発見できることもあるのではないでしょうか。
おまけ:Grafana で見るメトリクス
Langfuse はトレース(処理の構造)を可視化するツールですが、「どれくらい使ったか」という量的な把握には Grafana が適しています。Prometheus がメトリクスを蓄積し、Grafana で可視化できます。

今回の構成で Grafana に表示したメトリクスの例です。
生成/削除コード行数(claude_code.lines_of_code.count)
-
type=addedとtype=removed別に集計することで、Claude Code がどれだけコードを生成・削除したかを把握できます。
推定コスト(claude_code.cost.usage)
-
model属性で使用したmodelごとのコストを集計できます。
アクティブ時間(claude_code.active_time.total)
-
type=user(入力・閲覧)とtype=cli(ツール実行・AI応答)に分かれており、実際に Claude Code が処理していた時間を確認できます。
総トークン数(入出力)(claude_code.token.usage)
-
type属性でinput/output/cacheRead/cacheCreationに分解すると、キャッシュ効率が一目でわかります。
トークン使用量(時系列)(claude_code.token.usage)
- 時系列で、トークンを多く消費した時間帯が把握可能です。
Grafana のダッシュボードは JSON で定義・共有できるため、一度作成すれば組織内で再利用できます。Claude Code Monitoring Guide にはすぐ使えるダッシュボード定義も公開されていますので、ぜひ参考にしてみてください。