※以下は全て BigQuery の標準SQLクエリ構文における解説です。
やりたいこと
BigQuery上でFizzBuzzをやってみようと思います。(1−100まで)
ただ単にやるだけでは「1−100のデータをもつテーブルをつくって、case文かいておしまい!」となってしまいます。
FF7Rのハードをやり込んだ身としては、いくつか制限をつけたいということで、
- テーブル使用禁止
- UNION文使用禁止
の2つを縛ってみることにしました。ちなみに、UNION文を禁止したのは、
select 1 union
select 2
...
という裏技を使えなくするためです。
方針
まず考えないといけないのは、1-100をどうやって生成するかです。
残念ながら再帰クエリはBigQueryにはありません
ちなみに PostgreSQL であれば、下記のような再帰クエリを使用することで、1-100までが生成できます。
with recursive seq(i) as (
select 1
union all
select i + 1 from seq where i < 100
)
select i FROM seq;
しかし残念ながら BigQuery には再帰クエリは実装されていません(2020/09/21現在)
https://cloud.google.com/bigquery/docs/reference/standard-sql/query-syntax?hl=ja#with_clause

※強調は筆者
方針は2つです
スタンダードに考えられる方針は2つかなと思います。
- generate_array 関数を使う
- BigQuery Scripting で loop や while を使用する
あとは、無理くりなにかを100個生成してそれらの番号を数えるとかで1-100を表現できますが、今回はそういうセコめのやつは割愛です(笑)
generate_array 実装版
SQL
select
i,
case
when mod(i,3) = 0 and mod(i,5) = 0 then 'FizzBuzz'
when mod(i,3) = 0 then 'Fizz'
when mod(i,5) = 0 then 'Buzz'
else cast(i as string) end as res
from
unnest(generate_array(1, 100)) as i
generate_array(1, 100) で1-100の配列を生成し、それを unnest することで列に変換しています。
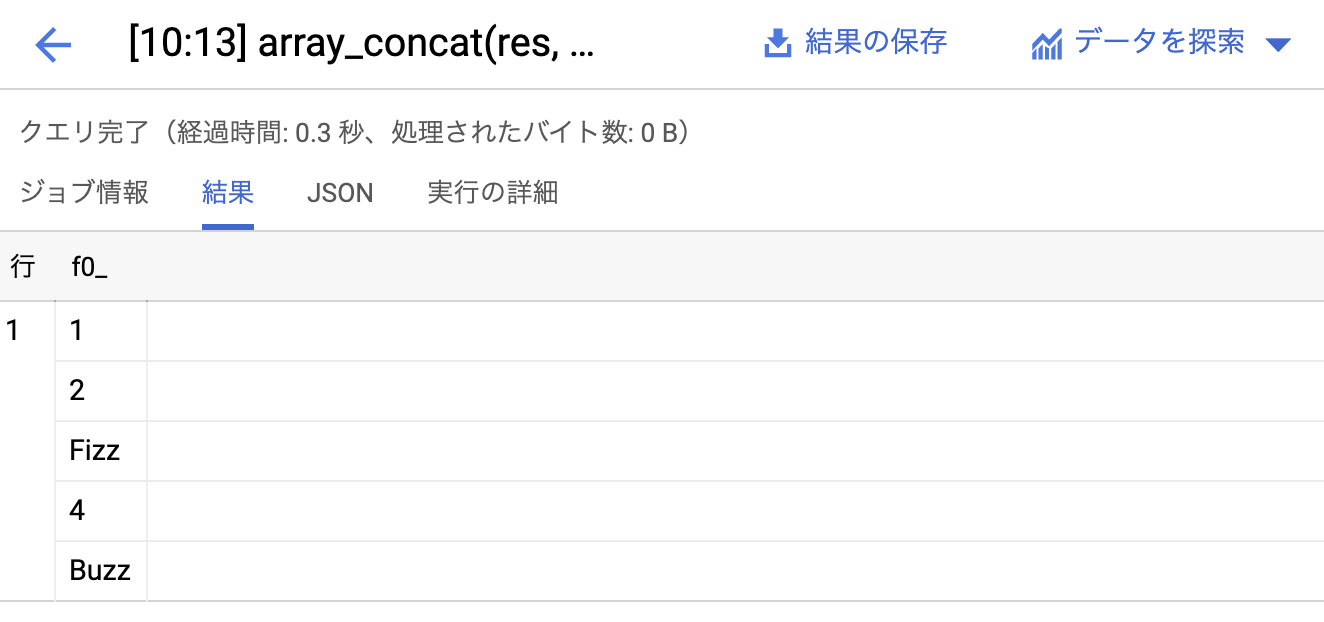
そしてその変換した列の値を用いて、case文による処理をして FizzBuzz を表示しています。正しく動いているということでスクショ貼っておきます。
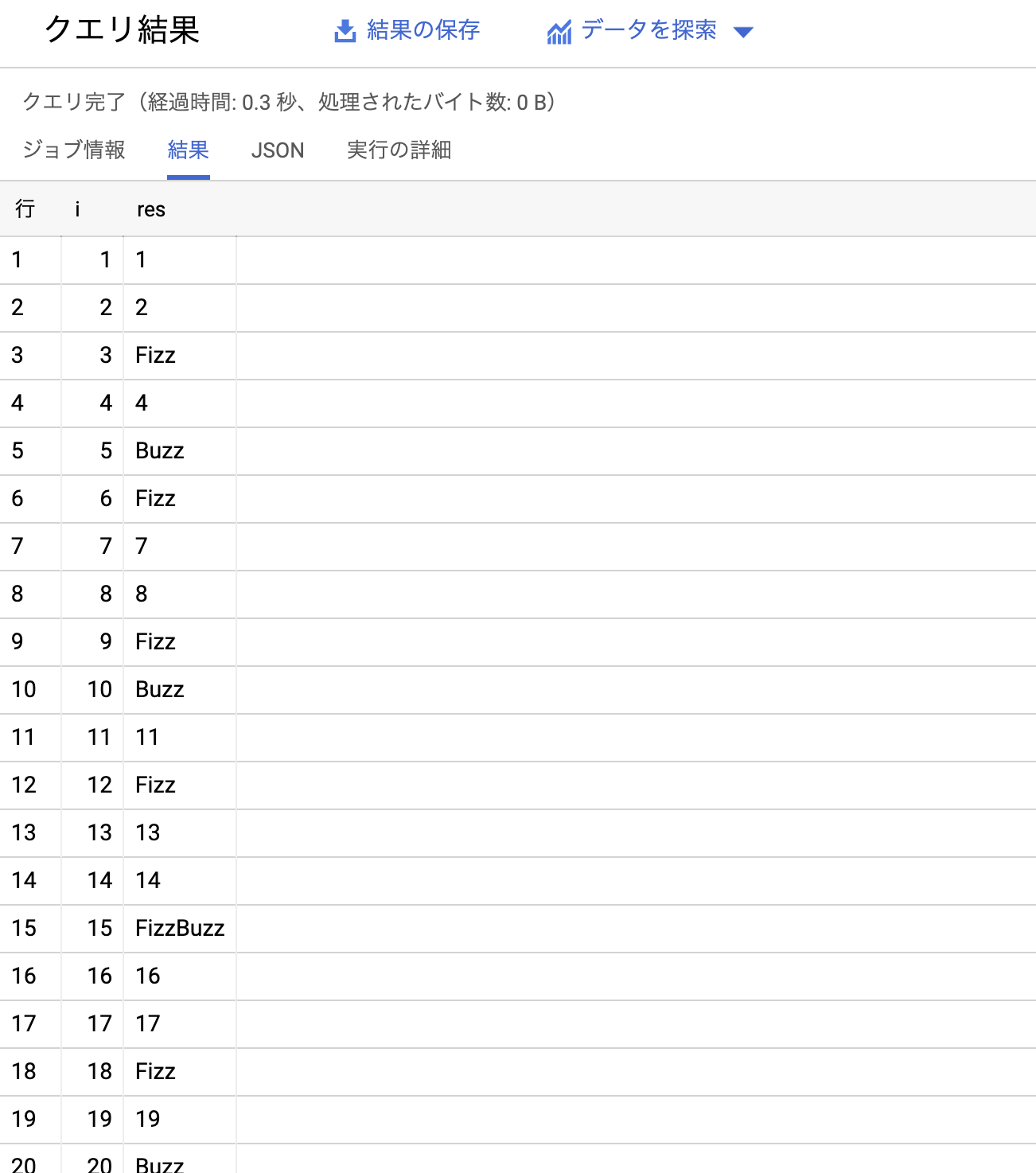
実行結果詳細
注目してほしいのが実行結果詳細です。InputとOutputの2つのみのステージで、全体は0.3秒でクエリが終了しています。
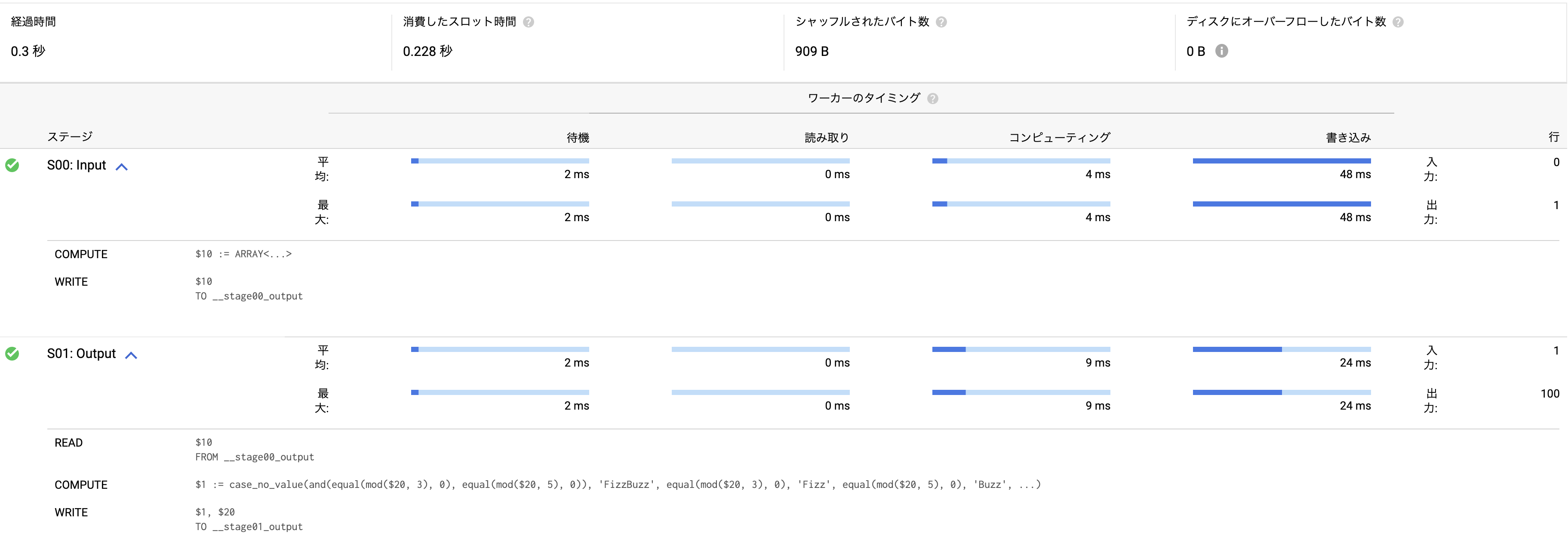
BigQuery の生い立ち上他の言語と比べると可愛そうですが、全体処理が0.3秒で返ってきているので、 generate_array 関数は積極的に使っていこうという気になります。
BigQuery Scripting 実装版
BigQuery には BigQuery Scripting という独自拡張が施されております。具体的には下記を読んでくださいw
BigQuery スクリプトを使用すると、1 回のリクエストで複数のステートメントを BigQuery に送信して、変数を使用したり、IF、WHILE などの制御フロー ステートメントを使用できます。たとえば、変数を宣言し、値を代入し、第 3 の場所にあるステートメントからその変数を参照できます。
https://cloud.google.com/bigquery/docs/reference/standard-sql/scripting?hl=ja#bigquery_scripting
今回は、 loop を使ってみようと思います。
SQL
declare i int64 default 1;
declare res array<string> default ['1'];
loop
set i = i + 1;
if i > 100 then
leave;
end if;
set res = array_concat(res,
[(
select
case
when mod(i,3) = 0 and mod(i,5) = 0 then 'FizzBuzz'
when mod(i,3) = 0 then 'Fizz'
when mod(i,5) = 0 then 'Buzz'
else cast(i as string) end
)]
);
end loop;
select
row_number() over () as i,
res
from
unnest(res) as res;
SQL とは。。というコードになってきました。 select 文が使われているので、 SQL っぽくみえなくはないですが、これをそのまま BigQuery に投げて動くとは思いませんよねぇ。(まぁ動くんですが
処理の流れをいうと、 loop 変数と使用している i から Fizz/Buzz の判定を行い、その判定結果を res という配列に array_concat で突っ込んでいるというものです。
念の為結果を貼っておきます。
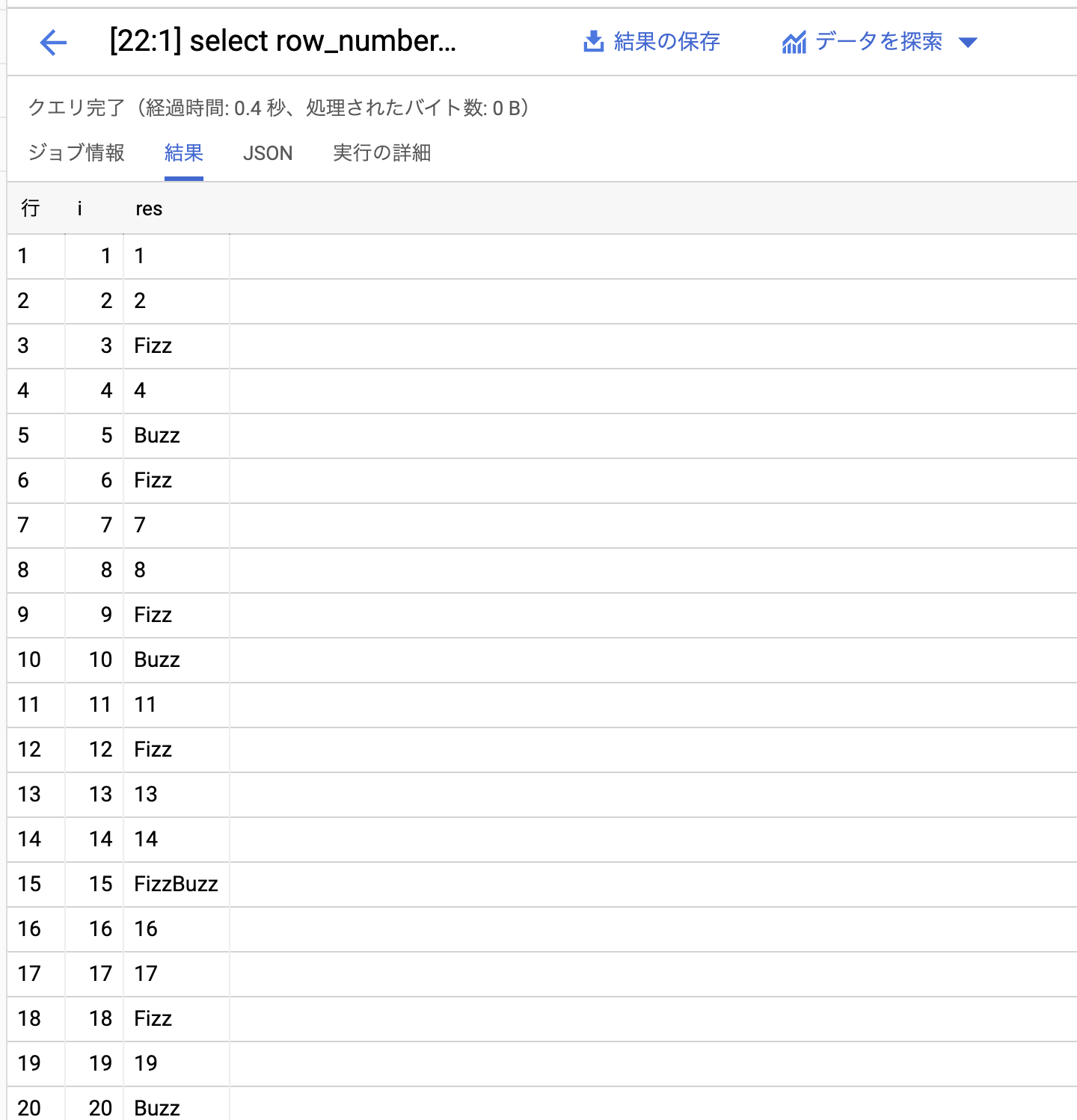
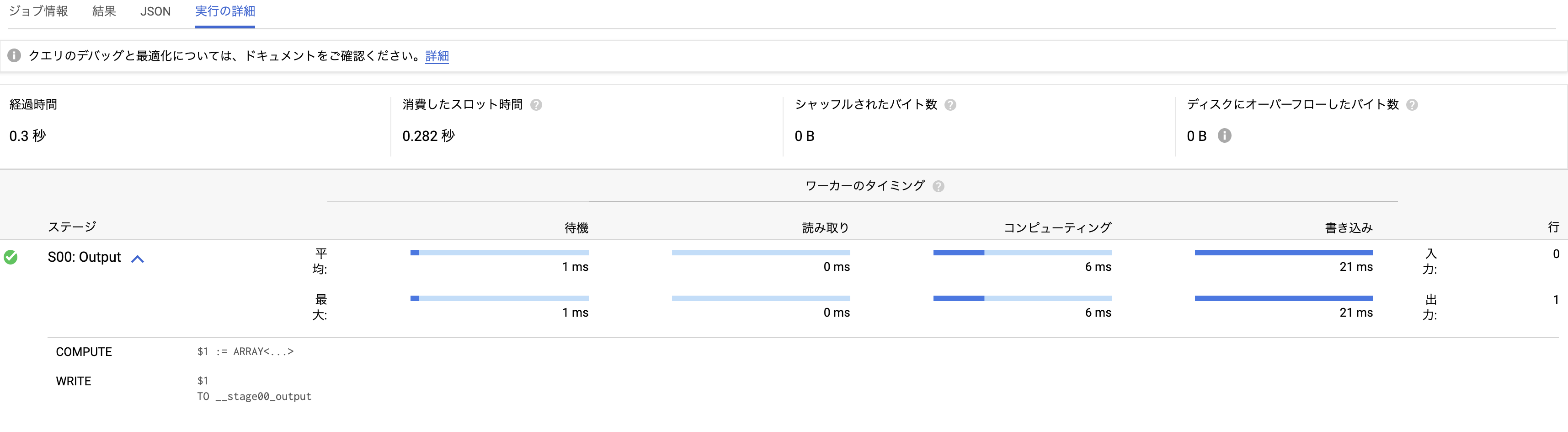
実行結果詳細
注目してほしいのが実行結果詳細です。全体で1分12秒かかっています。どんだけ〜。
まぁ、どんだけ〜とおちゃらけてみましたが、この処理内部的には100このステートメント(ジョブ)が実行されているのです。
結果画面では、ループ文の1回毎の処理結果が出力されています。
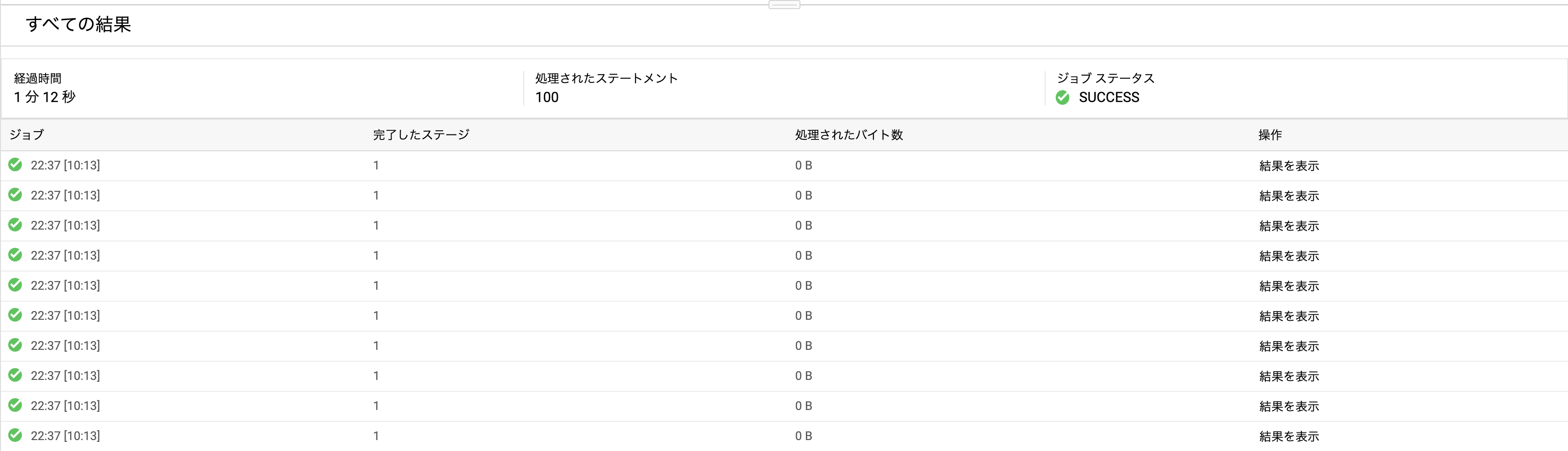
↑この5つめの結果を表示すると、下記のような結果が表示されます。つまり、ループ1回分に約0.3秒かかっているわけです。
ループの毎回に COMPUTE, WRITE の双方の時間がかかっていることが見て取れます。
ここから言えることは、やはりパフォーマンスが良くないということです。
もともと、 BigQuery は大きなデータを取り扱うことに長けたデータベースであり、複雑な条件分岐はまだまだ緊急回避的な用途にとどめておくほうが懸命かなと思います。(特に繰り返し文は)
おまけ
array_concat(a, b) の順番が担保されていないと上記のクエリはうまく動かないんじゃないの?という疑問が湧くと思います。
そうなんです。BigQuery のドキュメントでは、必ず a,b の順番を保って結合するとは 書かれていません。

https://cloud.google.com/bigquery/docs/reference/standard-sql/arrays?hl=ja#combining_arrays
なので仕様変更により上記のクエリが異なる結果を返す可能性はありますが、 concat 関数である以上、おそらく順番は担保されているんじゃないかなと考えております。
ちなみに、順番が担保されない関数には注釈がでている(下記の例はarray_concat_agg関数)ことからも、おそらく array_concat は順番を担保してくれているんだと信じています(笑
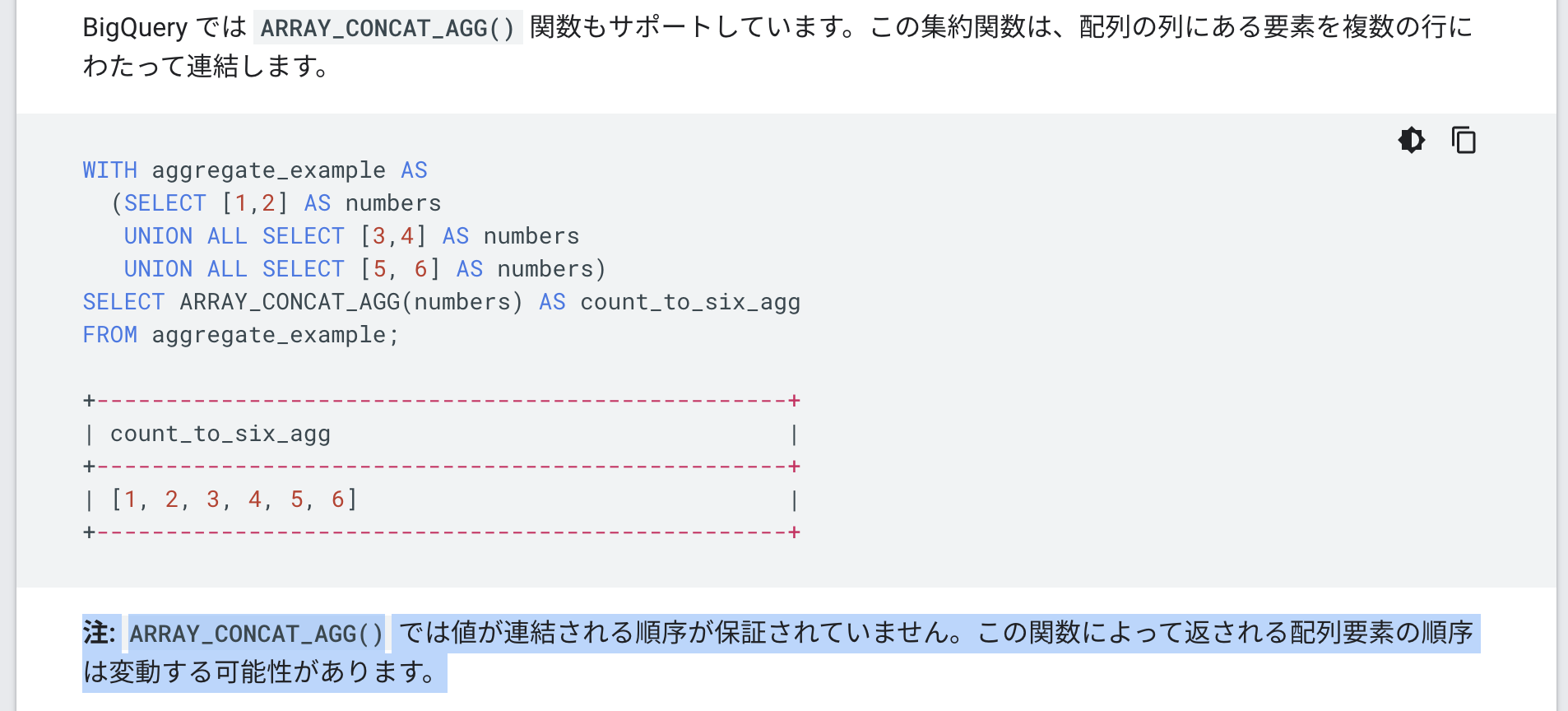
https://cloud.google.com/bigquery/docs/reference/standard-sql/arrays?hl=ja#arrays_and_aggregation
まとめ
- BigQuery で Fizz, Buzzをやった
- 普通じゃ面白くないので、テーブルなし・UNIONなしの条件下において、2通りの方法でやった
-
generate_arrayを使う方法はシンプルで読みやすくて実行もはやい - BigQuery Scripting の loop を使うことでも実現できるが、パフォーマンスは著しく劣る
- BigQuery Scripting は現段階ではゴリゴリと複雑な処理を書くのではなく、どうしてものときの緊急避難的な使い方がよさそう
※ASSERTでエラー検知したり、IF文一発で条件分岐したりはいいのだけど、LOOPやWHILEは避けたほうが良さそうかなーという所感