- 生成AIの現状として2025年から直近までの動向を整理
- 動向
- 大規模言語モデルの大競争
- 推論モデルの隆盛
- 人間との比較
- 拡散モデルのLLMへの適用
- DeepSeekの衝撃
- 推論モデルの隆盛
- マルチモーダル
- 世界モデル
- フィジカルAI
- エージェント型AI(AIエージェント)
- 大規模言語モデルの大競争
- 2026年の注目トピック!
基盤モデル
最近ちょっと言われ出しましたが2021年に"On the opportunities and risks of foundation models."1という論文で、いわゆる大規模言語モデルのようなものを「基盤モデル」と呼ぼうとなったようです。
- 言語・テキストを中心の大規模言語モデル(LLM Large Language Model)や
- マルチモーダル性に着目したLMM(Large Multimodal Model)
- 視覚と言語をまたぐモデルVLM(Vision-Language Model)
などがありますね。以下、大規模言語モデル、画像モデルを画像生成として、音声生成を音楽生成として取り上げます。
大規模言語モデルの大競争
大規模言語モデル(LLM)のちょうど良い年表を見つけました。
これを図にしました。
- ほぼ毎月から少なくとも四半期には社運を賭けるような大規模投資を伴う新モデルを発表しなければならない、という凄い世界です
- 2025年12月にはGeminiに遅れをとったOpenAIが"Code Red"を宣言、巻き返しのGPT-5.2を出すなど話題となりました。
あけて2026年も激しさは変わりません。
推論モデルの隆盛
Reasoning Modelとも呼ばれ2024-09-12にOpenAIが発表したo1-previewによって幕を開けました。
従来型のモデルは、プロンプトに対し次の単語を確率的に予測するというもので、計算問題など論理的な問いにはかなり弱いものであった。
従来の非推論モデルと推論モデルの違いをざっくり図にするとこんな感じ。
現在では多くのモデルが推論モデルになっている(回答速度重視で推論を薄め、回答精度重視で時間がかかっても推論を強めの違いなどはある)。
また、それ以前からモデルの性能が上がりそれを検証するデータセットの不足が言われていた。そこに
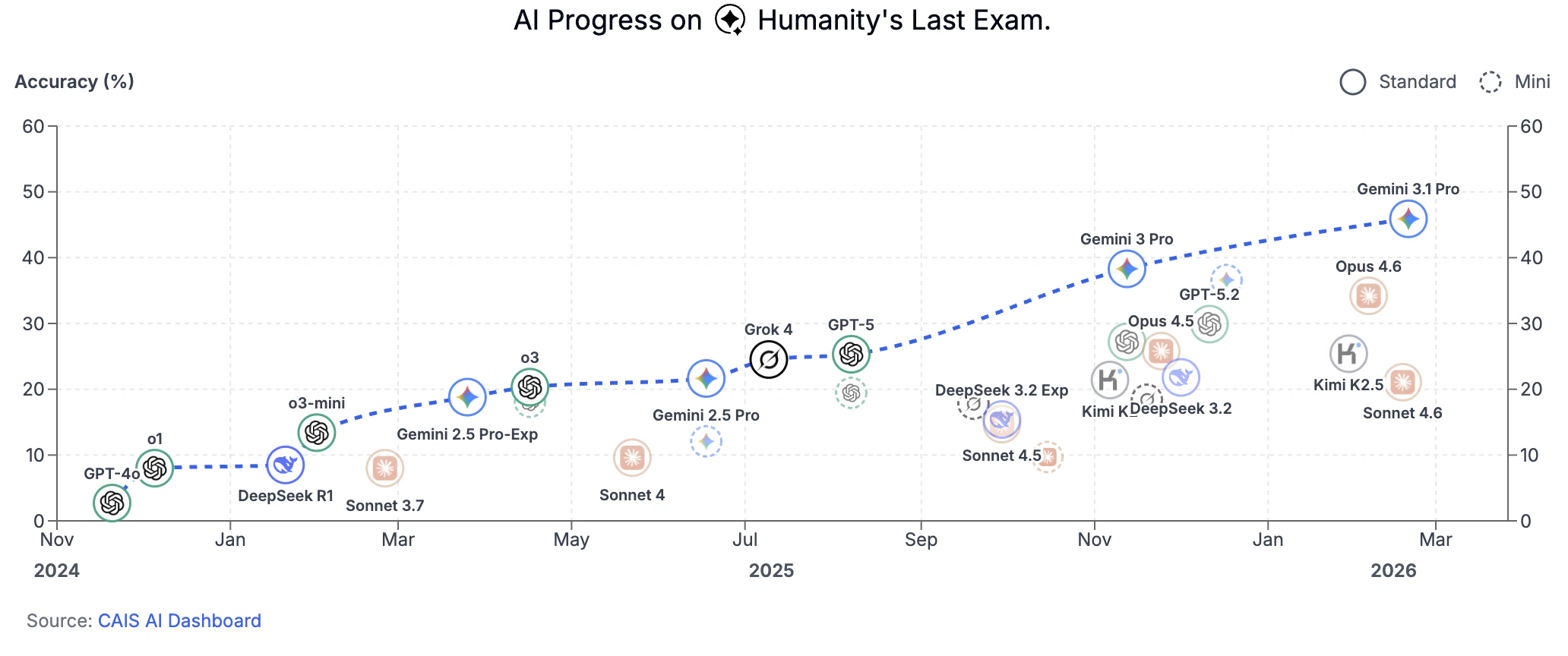
「Humanity's Last Exam」(人類最後の試験) 2
という大層な名前の当分解けないだろうという難問のデータセットができた。2024年に主流モデルだったGPT-4oではわずか数%しか解けないもの。
2024-09にo1-previewが出て以降、2025年は推論モデルの大競走となる。
o1が出てそれを10%程度に上げた。
当初は「当分は高得点が出ないだろう」と思われていたが、2025年以降に推論モデルの進歩とともに急速にスコアが伸びた。現在ではHLE本文の固定集計では Gemini 3 Pro が 38.3%、一方で CAIS AI Dashboard の時系列表示では Gemini 3.1 Pro が約45.9% まで伸びている。
人間との比較
2025-04には、トップ国際会議のワークショップでAI生成論文が査読(論文誌掲載に妥当かを専門家が判断するステップ)を通過したことが話題になりました。
2026-02には大学入試の共通テストでGPT-5.2がほぼ満点を叩き出したと話題になりました。
同月、GPT-5.2が理論物理の新結果に寄与したと話題になりました。
人間のトップレベルの知を超えるようなレベルになったと話題になりました。一方で気をつけなければならないのは、
BabyVision3という研究ではトップレベルモデルでも、人間の3歳児でも解けるようなパズルが解けない、という研究もあります。言葉の意味を正しく理解しているわけではなく、あくまでも頻度を元にした回答をしているだけであり、出された図と言葉のつながりをしっかり結びつけられていない、などと言われています。
このサイトでは
LLMは、与えられた文章の次の一語を正しく予想するようにトレーニングされたニューラルネットであるため、「もっともらしい文章」を作るのは上手です。 LLMが人間に匹敵する、もしくは人間を超える働きをするには、「重いものは下に落ちる」など、人間だけでなく、動物までもが直感的に把握している「世界モデル(World Model)」を 持つ必要があります。
として例えば
扇風機の前に風船を置いたところ、全く動きません。なぜでしょう?
のような問いを用意しています。扇風機が止まっているからですね。これらを博士課程の問題のようなもので高得点を出すモデルでも軒並み間違えます。「扇風機の正面中央は『無風帯(デッドゾーン)』」とか理屈をこねくり回します。
ただ、GPT 5.4 Thinking 思考の拡張 で試したところ解けるようになっています。こういう「世界認識」みたいなところも少しずつは進化している模様。
拡散モデルのLLMへの適用
拡散モデルとは、元のデータにノイズを少しずつ加えていって最後には完全なノイズにするということを実施。そして、その逆に完全なノイズから少しずつノイズを除去して最後には元データに戻す、という学習を行う。元々は画像生成で一般的となった手法だが、大規模言語モデルへの適用もいくつかみられた。ここでは2025年にMercuryで話題となった、拡散モデルの言語モデルへの適用を書いてみます。
大規模言語モデルで一般的なTransformerと比較すると拡散モデルであるDiffusionのイメージは下記である。
言語モデルでの拡散モデルは画像と違い離散的にノイズ(トークンをマスクして復元)していきます(下記図では簡単のために、トークンではなく単語単位で表示)。
- Transformer vs Diffusionと完全に対比されるわけではなく、Diffusion実装の代表であるMercuryでは、ノイズ除去の提案役としてTransformerを用いている
- そのため、Transformerアーキテクチャの自己回帰デコードと拡散デコード手法の対比、というのがここのイメージに近い
- テキストでは“ノイズ”はマスク/置換などの離散的な方法で実装されることが多い
本手法の実装としてはMercuryなどが有名である。Transformerがトークンを1つずつ生成するのに比べ並行で生成できるため、比較的高速な生成が利点である。
- 2025-02-26 Mercury発表
- 2026-02-24 Mercury 2発表
DeepSeekの衝撃
2025年の事件としてDeepSeekは外せませんね。2025-01-22にDeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning4という発表で一般ニュースでも話題となりました。
公開されているLLMに強化学習と蒸留という手法を用い、当時のGPTやGeminiに近い性能をはるかに低コストで叩き出したというもの。
強化学習は、学習済みのLLMの性能を引き出すために、追加の学習を行うもの。また、蒸留という手法自体はモデルの必要部分だけを抽出して小さくするということで知られていましたが、大幅なコストダウンで最高性能モデルに近いものが出せてしまうということが驚きでした。
マルチモーダル
マルチモーダルの「モーダル(modal)」とは、AIや機械学習において、テキスト、画像、音声、動画、センサーデータなど、情報やデータの「形態」「様式」「入力モード」を指す。
言語を中心に伸びてきた生成AIも画像、動画、音声等に広がっている。
画像生成
元々DALL-Eなどの画像生成はありましたが、GPT4oイメージ(後のAPI名は gpt-image-1)という画像生成モードにより、手軽にそれなりの絵が描けるということで大流行OpenAIのアルトマンさんが「GPUが溶けている」と投稿するなど大きな話題となりました。
その後GeminiのNano Bananaがよりリアルな画像や、詳細な図解のスライド資料が作れると話題になりました。
どれくらいの違いがあるかをLLM比較サイトの https://arena.ai/ で比較してみました。
プロンプトはシンプルに、
日本の春
-
dall-e-3

-
gpt-image-1

-
gpt-image-1.5-high-fidelity

-
gemini-3-pro-image-preview-2k (nano-banana-pro)

-
gemini-3.1-flash-image-preview (nano-banana-2) [web-search]

この1年で普通の写真とほとんど違いがわからない画像生成ができるようになっています。
性能差はDesignArenaのImage Arenaが詳しいです。
動画生成
NHKニュースにも取り上げられたSoraの衝撃的な動画生成能力から1年以上経ちこの分野もかなり性能が上がりました。
画像生成と同じ拡散モデルが用いられていましたが、長時間の動画は難しいという課題があったようです。そこにさまざまな技術を投入して、たとえば言語モデルのTransformerを用いて、シーンごとの因果関係をあたかも文章を処理するかのように対応することにより、長時間のスムーズなシーン展開も可能になってきているようです。
また、主にPhysical AIの方で注目されている世界モデルですが、動画生成のSoraやVeoにも取り入れられています。
OpenAIのSoraとGoogle/DeepMindのVeoがトップランナーでしたが、最近xAIのGrok Imagine 1.0や、Niobotics ByteDance社のSeedance 2.0はよりリアルな映画レベルのような動画生成が可能となっており、話題となっています。
性能差はDesignArenaのVideo Arenaが詳しいです。
音楽生成
作曲などができることは知っていましたが、正直あまりフォローしていませんでした。GoogleがLyria 3をGeminiに標準搭載したことで盛り上がってくるのかと思います。
2026-02-24に音楽生成のProducer.aiがGoogle Labsに参加とのことでLyriaが伸びるでしょうか。
Geminiの音楽生成(Lyria 3)を試しました。
音楽生成AI Lyria 3の特徴をシューゲイザー風の曲で紹介して
世界モデル
最近やっと話題に上がってきました。まだ日本語の記事も少ないですね。
Qiitaの別記事に書いております。
世界モデルの最近の話題としては2026-01にGoogleが出したGenie 3は、単なる動画生成ではなく、ユーザーがその中を移動するとそれに対応して次の世界が生成されるというインタラクティブ性が可能になりました。
単なるゲームと思われるかもしれませんが、ビジネスにおいても教育とか、人材育成とかに広がるのかなと思っております。
フィジカルAI
ということで今年の「バズワード」は「フィジカルAI」らしい。
ロボットと混同されやすいが、
AIが言語能力や画像・動画認識能力をかなり持ち、では、身体を持って実環境で動作するにはどうしたらいい?というところからフィジカルAIが注目されていると思われる。
2025-01-07にNVIDIAさんがCosmosという世界基盤モデル5を発表して一気に加速した感がある。
世界基盤モデルとは、環境の認識と未来予測を担う世界モデルと、動画などでロボットの動作を大量に学習した基盤モデルを組み合わせ、ロボットに必要な基本的な動作はすでに知っているから、ユーザが必要な動作をちょっと教えるだけで動かせますよ、的なプラットフォーム。
中身のイメージはこんな感じ。
従来の動画生成だと見た目綺麗には描けるが物理法則などを無視したようなものも生成されてしまう。
それに対し漫画のコマのようにとびとびだけれど、物理法則の原因と結果のような整合性を持った動画生成を行う。
それを合体させて、因果的にも正しくスムーズな将来動画が描けるDigital Twin的なDBを作成しておく。
これにより、雨の高速道路でトラックに追い抜かれるシーン、などと指示するとリアルな動画を生成して自動運転でそれにどう対処するか、のような仮想実験を低コストで行える、というもの。
その他Physical AIについて詳しくは同じくCRDSの俯瞰報告書
S2 ロボティクス S2.01 ロボットの知能化参照。
エージェント型AI(AIエージェント)
去年のバズワード「エージェント」ですね。今年から本格化していくと思います。
単にプロンプトに対して返答するだけではなく、ユーザの指定した指示に対して、自律的に行動(Web検索やPC上の処理の実行など)を行う機能が「エージェント」と呼ばれている。
ただ注意が必要なのは、各社がそれぞれ独自の用語を用いていたり、同等機能と比較できるものでなかったりするなど用語の混乱が見られます。
この辺りは、ガートナーさんの「Gartner、AIエージェントとエージェント型AIに関する見解を発表」が一番整理されていると思います。
それらを元に私なりの整理としては以下と考えています。
| 「生成AI」 | 「エージェント」 | ||
|---|---|---|---|
| ワークフロー | AI Agent | Agentic AI | |
| プロンプトの指示に回答 | ユーザーが手順を指定 | 限定的な範囲でユーザーの指示にある程度自律的に行動・回答 | ユーザーの指示に自律して行動・回答 |
| ChatGPT, Gemini, etc | GPTs, Gems, etc | ChatGPTやGeminiなどの「エージェントモード」 | 研究中だったが、2026年にはここが熱い? |
そして2025年に各社Chat生成AIサービスでもエージェントモードが実装されました。
エージェントは各社によって機能などがまちまちなため同列に比較しにくいです。ざっくり広義のエージェント機能の流れということで。
各社で「エージェント」「Agent Mode」「agentic capabilities」の粒度が異なるため、ここでは厳密な同一機能比較ではなく、agentic機能の公開・発表の流れとして並べています。
ここは私も追いつけていないので今後Updateしたいですが、Qiitaのエンジニアの観点では、エージェントに関しては別の観点で整理した方が良いかなと思い、以下試みます。
(ここ殴られそうだな、違和感や間違いがあったら殴らずにコメントなどで教えてくださいな)
元々はプロンプトの工夫で生成AIに指示していたが、不可能を可能に、性能向上などから様々な技術が出てきている(プロンプトエンジニアリング自体も引き続き使われています)。
これはユーザーがこのモードを指定するとAI側が自動的に実行してくれるものですね。
これはユーザーが各エージェントを目的に応じつなぎ合わせる時の規約ですね。
上記両方に関わりますが、単なる指示のプロンプトだけじゃなくそれを問うている「コンテキスト」も適切に渡したほうが良い回答を得られるよということですね。
コーディングであれば、Chatの画面よりもIDEがいいでしょうという当然ですが、コーディングだけではなく、例えばMicrosoftですとOffice製品にM365 Copilotを統合していっているのも同じ流れなのかなと思います。
ブラウザ作業のプラットフォームとするなら専用のブラウザにしちゃえ、のようなことですね。
「エージェントモード」「AI IDE・開発プラットフォーム」「AIブラウザ」でも一部ローカルPC上の操作ができますが、もっと進んでPCを操作してしまおうというもの。可能性と危険性がないまぜで今年の話題となりそう。
それに対し、代表的な各社サービスも対応しています。
| OpenAI | Anthropic | etc | ||
|---|---|---|---|---|
| エージェントモード | ChatGPT agent | Gemini Agent Mode | Cowork / Claude Code | |
| エージェントプロトコル | - | A2A | MCP | 事実上MCP & A2Aがデファクト MCP:AIアプリを外部システムにつなぐオープン標準 A2A:別のエージェントに仕事を委譲・連携する規格 |
| コンテキストエンジニアリング | AGENTS.md | - | CLAUDE.md | AGENTS.md |
| AI IDE・開発プラットフォーム | Codex app | Antigravity | - | Cursor, 各社サービスのVS Code拡張 |
| AIブラウザ | ChatGPT Atlas | Gemini in Chrome agentic browsing is coming |
Claude in Chrome | Perplexity/Comet, Dia |
| computer-use agent | Operator, ChatGPT agent | Project Mariner, Gemini agent | Cowork | OpenClaw |
その他エージェント型AIについて詳しくは同じくCRDSの俯瞰報告書
S1.03 人・AI共生モデル参照。
2026年のトピック!
独断と偏見によるものです。
AIと戦争
不幸なことですが避けて通れないですね。
「ついにAIが戦争に使われる」と仰る方もいますが、残念ながら昔から使われています。そもそもコンピューター自体が戦争と切り離せない。
こちらはAIと戦争について人工知能学会会長の栗原氏へのインタビューです。
また、単に画像解析やドキュメント分析にもAIは使われるでしょうがより踏み込んで戦争の意思決定に!というようなものもすでに取り組まれているようです。
-
AI海戦 人工知能は海戦の意思決定をどう変えるのか?

- この本は翻訳時点で3年前のため生成AIについては言及がありませんが、こういった情報は一般人では得られないので貴重かと思います
- (私は社会のシミュレーションに関心がありその特異な例として読みましたが、まさかリアルな戦争に、、、)
- 今ならKindle Unlimited無料のようなのでご関心がある方は
- この本は翻訳時点で3年前のため生成AIについては言及がありませんが、こういった情報は一般人では得られないので貴重かと思います
AIが職を奪うのか職を生むのか
いよいよ、リアルになってきました。
2026-03-05のAnthropicさんの記事

図2:職業カテゴリ別に見た、理論上の対応可能範囲と実際に観測された利用範囲
LLM が理論上実行できる職務タスクの割合(青)と、利用データに基づいて算出した当社独自の職務カバレッジ指標(赤)を示す。
ホワイトカラー職では LLM の理論上の適用可能範囲が大きいことが示された一方、実際の利用範囲はまだそこまで達していない。つまり「すぐ全面代替」というより、「代替可能性の上限が可視化され始めた」と話題になっています。これはただ理論上の可能性を示しただけで本当にそうかどうかはわかりませんが、今年話題となることは間違いないですね。
Affective AI
たまたま、「科学技術への顕著な貢献 2025(ナイスステップな研究者)を選定しました」こんな記事を見つけまして、その中に、奈良先端大の日永田氏の「心に寄り添うAIロボットに向けた感情モデルの開発」という研究を見つけまして。氏のサイトは https://www.hieida.com/ 。AIの感情についての研究ですね。
調べましたら、人工知能学会の「私のブックマーク『Affective Computing(感情計算論)』」が情報が詰まっております。
感情ですとEmotionがすぐ浮かびますが、
- 感情(Affect)
- 情動(Emotion)
と分けられ、それらをコンピュータ上で扱うのにはAffective Computingという分野があると。
Affective Computingで良いのですが、OO AIとすぐ呼ばれがちなのでAffective AIと呼ばれ出すのかなと(ググると総称しているものもいくつか)。
単純に今年のバズワードがPhysical AIでロボット的な話題で溢れると、これらと人とのコミュニケーションはどうなるんだ、言語のやり取りはできても感情は?となり、流行るはずだと。
AIと人間の脳
スケーリング則に則った大規模言語モデルはそろそろ行き詰まるとか、言葉の相関のみでは人間の脳に至らないとか、そもそも計算しすぎで電気コストがかかりすぎとか。
MetaをやめたLeCunもずっと提唱しています。LLMとは違う道が必要だと。
また脳の研究の立場からも、脳神経科学の第一人者のFristonは脳の認識について自由エネルギー原理に基づく能動的推論を提唱しています。そして新たなAXIOMというモデルを提案しています。
元々人間の脳のニューロンからできたニューラルネットですが似ても似つかない化け物になっていますので、今一度人工知能の先輩の「脳」から学ぶという流れがうねっていくのではないかなと。
その他、人間の脳、知能について詳しくは同じくCRDSの俯瞰報告書
S1.01 人間知能の理解参照。
私も記事を書いております。
補足
CRDSの研究開発の俯瞰報告書 システム・情報科学技術分野~領域別動向編~(2026年)| 人工知能(AI) S1 人工知能(AI) S1.02 AIモデルのレポートを元に参考情報を付与しています。
このレポートのキーワードと、あと私が気になる点を現状の動向としてまとめました。
キーワード:
- 生成AIの要素技術・適用先として重要ではあるがQiitaに多数記事あり、略
- 機械学習、深層学習、強化学習、模倣学習、生成AI、パターン認識、自然言語処理
AIと機械学習と深層学習と生成AIについての整理は過去に別記事を書いております。
- 動作生成
- ロボットが実世界を操作するための行動計画・動作生成ステップに関わる研究。本記事の範囲外と一旦整理(単に私が詳しくない)
- フィジカルAI文脈で、同じくCRDSの俯瞰報告書S2 ロボティクス S2.01 ロボットの知能化参照
関連記事
-
BOMMASANI, Rishi, et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021. ↩
-
PHAN, Long, et al. Humanity's last exam. arXiv preprint arXiv:2501.14249, 2025. ↩
-
CHEN, Liang, et al. BabyVision: Visual Reasoning Beyond Language. arXiv preprint arXiv:2601.06521, 2026. ↩
-
GUO, Daya, et al. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature, 2025, 645.8081: 633-638. ↩
-
AGARWAL, Niket, et al. Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575, 2025. https://arxiv.org/abs/2501.03575 ↩