- 生成AIについて人間との比喩を用いて初心者の方にイメージをつかんでもらえればいいな、という記事です
- 間違いはないよう心がけますがかなりデフォルメしている箇所もあります
- イラスト生成、一部文章生成、全体チェックなどにChatGPT 5.4/5.5 Thinking 拡張, Images 2を用いております
最近よく聞く「生成AI」。
でも、
- 何がそんなにすごいの?
- 画像や音楽まで作れるのはなぜ?
- 色々すごいのに、なぜたまにとんでもない変なことを言うの?
このあたり、なんとなく分かったようで分からない、という人も多いと思います。
そこでこの記事では、人間にたとえて、生成AIの「感じ」をつかんでみます。
厳密な技術解説ではなく、まず雰囲気をつかむための話です。
職場に変わった新人がやってきた。名前は「生成AI」。
ものすごく物知りで、頼んだ作業も黙々とこなす。
しかも文句も言わない。
すごく頼りになる相棒ができた感じ。
……と思ったら、急に自信満々で変なことを言い出す。
正直、扱いに困る。
この新人、いったいどういう生い立ちなのだろう?

生成AIは「生まれてから毎日図書館に通って、本ばかり読み続けた人」

まず、生成AIをすごく雑に言うと、
「ものすごい量の文章を読んで、この単語の次はこれが来るなと、それっぽい言葉を出すのがとてもうまくなった存在」
です。
人間でたとえるなら、こんな感じです。
生まれてから遊びなど一切せず、毎日図書館に通い、本だけをずっと読み続けてきた人。
- 小説も読む
- ニュースも読む
- 専門書も読む
- ネットの文章も読む
- 会話文も読む
とにかく、ものすごい量の言葉に触れてきた。
だから、
- 文章の続きを自然につなぐ
- それっぽい説明をする
- 文体をまねる
- 要約する
- 例を出す
といったことが、とても得意です。
これが、生成AIがまずすごい理由です。
なぜ急に賢く見えるようになったのか「生成AI」のご先祖様たち
ITの文脈で「言語」というと、プログラミング言語を指すことも多いです。そこで、人間が日常で使う言語は「自然言語」と呼ばれます。その自然言語をコンピューターでどう扱うかという分野が自然言語処理です。
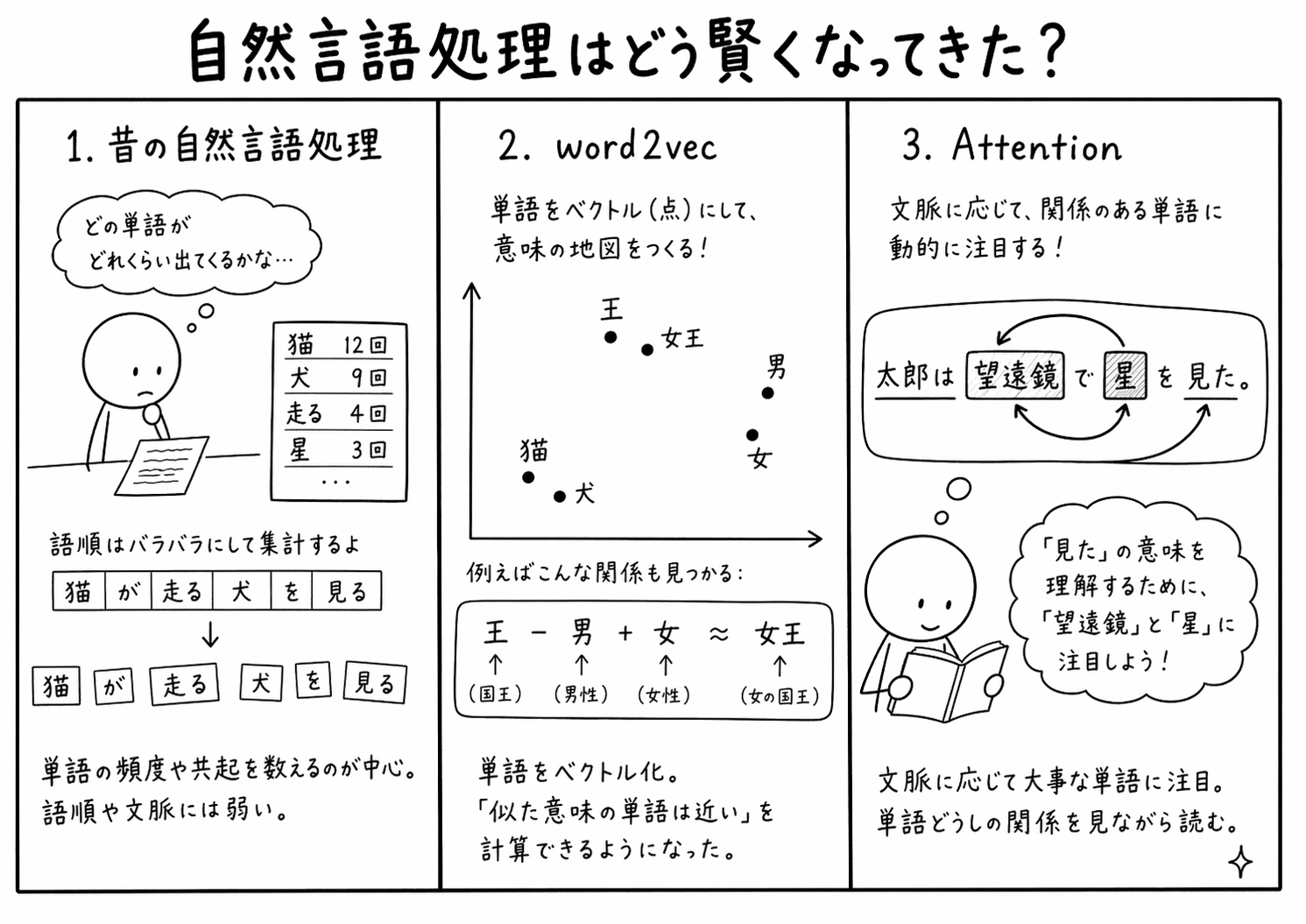
現在の生成AIの曽祖父母「単語の使用頻度」
かつての自然言語処理では、文章に出てくる単語の頻度や、単語同士の共起、TF-IDFのような特徴量を使って文章を扱う方法がよく使われていました。
肯定的な文章であれば「素晴らしい」「いいね」「楽しい」などが多く、否定的な文章であれば「ひどい」「悪い」「つまらない」などが多い、みたいな。
もう少し高度になると、文章の長さ、単語単体ではなく2単語のつながりとか、TF-IDFと言って使用頻度が多くてもどの文章でも使われるありふれたものは無視して、使用頻度が少なめでも特定の文書だけで多く使われるものを重視すると文章の分類に使えるねとか。
ただ、これらだとどうしても限界がありました。
現在の生成AIの祖父母、言葉の「意味」を計算するという革命 Word2Vec
2013年にGoogleの研究者らによって発表されたWord2Vecが革命を起こします。
\begin{align*}
王-男+女&=女王 \\
パリ-フランス+日本&=東京
\end{align*}
たとえば、よくある説明では次のような関係が紹介されます。
$$王-男$$
で国王的な意味から性別の男性を取り除き、
$$+女$$
それに性別の女性を加える。国王的な意味の女性版つまり女王となる。
同様にパリからフランスを除くと首都的な意味。それに日本を加えるということは首都的な意味の日本版つまり東京となる。
コンピューターが単語の意味を理解しているわけではないですが、単語同士の関係をベクトルという数学表現で表して、コンピューターが得意の計算で処理できる!となりました。
ただ、これはあくまでも単語ベースのことであり、文脈が重要な長文などとなると手に負えませんでした。
現在の生成AIの父母。TransformerとAttention
ただWord2Vecだと単語の意味的なものは扱えるのですが、文脈によって異なる意味合いのようなものは分かりません。
やはり自然言語をコンピューターで扱うのは難しいかーとなっていたところへ、
2017年にGoogleが出した論文"Attention is All You Need"。「注意が全てさ」くらいの意味でしょうか。
我々も意味のとりにくい文章を読むときにマーカーやアンダーラインを引いて「ここに要注目だな」ってやりますよね。それ的なことをするのがAttentionです。
Attentionは、人間が文章を読むときに「ここが大事そう」とマーカーを引く感覚に少し似ています。厳密には、単語同士がどれくらい関係しているかを計算し、文脈に応じて注目する場所を変える仕組みです。
このAttentionを中心に組み立てた代表的な仕組みがTransformerです。
現在の大規模言語モデルの多くは、このTransformerを土台にしています。
現在の生成AIの産声は「スケーリング則」と共に
AttentionとTransformerが有望そうだとなりましたが、自然言語処理の能力を測るベンチマークの結果は良好なものの、人間と対話できるようなのはちょっと難しいかもね、くらいな感じでした。
2020年にOpenAIが"Scaling Laws for Neural Language Models"という論文で「スケーリング則」を発表します。
大規模言語モデルの性能と「学習に使われるデータの量」「学習に使われる計算量」「モデルのパラメータ数」の関係を示したものです。
難しそうに聞こえますが、かなり乱暴にざっくり言うと、
モデルを大きくし、学習データを増やし、計算量を増やすと、一定の範囲では性能がかなり規則的に伸びる
という話です。当初は懐疑的な意見も多かったのですが、この方向に大きく賭けた代表的な企業の一つがOpenAIで、GPT-1、 GPT-2、GPT-3、と「自然な文章が出せるじゃん!」と世界を驚かせ、誰でも使いやすいChatGPTの登場以降、一般ユーザーにも一気に広まりました。
ここでやっと冒頭の新人「生成AIさん」の話に戻りますが、人間にたとえると分かりやすいです。
たとえば、普通の人が本を月に1冊読むのに対して、ある人が生まれてから毎日図書館に通って、何年も何年も本を読み続けたらどうなるか。
最初は「ちょっと物知り」くらいかもしれません。でも、量が増えていくと、だんだん
- 受け答えが自然になる
- 言い回しが豊かになる
- 知らない話題でも、それっぽく話せる
- 文章を書くのがうまくなる
というふうに、急に賢く見えてきます。つまり、魔法のような新機能が突然1つ加わったというより、
とにかく大量に学ばせたら、思った以上にできることが増えた
という面が大きいです。
ここまでをまとめると、生成AIさんは「大量の文章を読んだことで、自然な文章を作るのがとても上手くなった新人」です。
ただし、この時点ではまだ、計算や論理パズルは苦手でした。
生成AIさんは、たまに急にバージョンアップする
そういえば生成AIさんは、知識量は半端ないのに、簡単な計算や論理的な問題は苦手だな、と思っていた。
ところが、ある日から急にできるようになった。
そして、とんでもないことを言い出す。
「私はバージョンアップします」
最近の生成AIは「日◯研にも通い始めた」

以上のようにたくさん読書をして豊富な知識であたかも知的な会話をする生成AIさんですが計算やパズルが苦手でした。
コンピューターは計算が得意だろうと言いたくなりますが、生成AIさんは内部では膨大な数値計算をしていますが、人間が筆算するように、計算ルールをそのまま実行して答えているわけではありません。
そのため、昔の生成AIは簡単な計算でも間違えることがありました。
またパズルなど論理的思考が必要そうなものも苦手でした。
ただ、最近の生成AIをもう少し見ると、昔より「考えている感じ」が強くなっています。
これをざっくりたとえるなら、
ずっと図書館で本を読んでいた子が、最近は日◯研にも通い始めた
という感じです。
つまり、ただ知識を増やしただけではなく、
- すぐ答えを出すのでなく
- いったん問題を分けて
- 順番に考えて
- 手順を踏んで答える
ような練習もしてきた、ということです。
これが、最近よく言われる推論モデルのイメージです。
もちろん、人間みたいに本当に頭の中で完全に理解している、ということではありません。
でも少なくとも、
「それっぽく続けるだけ」から、「少し段取りを踏んで考える」方向に進んでいる
とは言えます。
だから最近の生成AIは、以前より
- 数学や論理問題
- 長い手順が必要な作業
- 条件を整理して考える仕事
が強くなってきました。
さらに最近は、ヤ◯ハのエレクトーン教室や絵画教室にも通い始めた

昔の生成AIは、基本的に「文字の人」でした。
でも最近は違います。
図書館で本を読み、日◯研で考える練習もして、
さらにヤ◯ハのエレクトーンや絵画教室にも通い始めた
そんな感じです。
つまり、
- 文章だけでなく
- 音も扱って
- 画像も見て
- 動画も扱って
- ときには音声で会話もする
ようになってきています。
これがマルチモーダルです。
要するに
「文字だけでなく、いろいろな種類の情報をまとめて扱える」
ということです。
たとえば、
- 写真を見て説明する
- 手書きメモを読んで整理する
- 音声を聞いて文字起こしする
- 画像を作る
- 音楽を作る
といったことができるようになってきました。
昔は「文章が得意なAI」だったのが、今は「文章も、画像も、音も扱うAI」になりつつあります。
じゃあ、生成AIは人間みたいなものなのか?
ここは大事なので、はっきり書きます。
似ているところはあるけれど、人間そのものではありません。
人間っぽく見えるのは、
- 言葉が自然
- 会話がそれらしい
- 文章が上手
- ときどき考えているように見える
からです。
でも実態としては、まず強いのは
「言葉・画像・音などのパターンを大量に学んだこと」
です。
なので、生成AIを人間そのものと思うと誤解します。
逆に、ただのオウム返しだと思っても実態を見誤ります。
ちょうど中間くらいで、
ものすごく多くを学習したことで、
驚くほど人間っぽい出力ができるようになった存在
と考えるのが、初心者にはいちばんしっくり来ると思います。
新人の「生成AIさん」の決定的弱点、「生きていない」
ここが大事です。
たしかに本はものすごく読んでいます。
でも、
- 友達と喧嘩したことはない
- 外で泥だらけになって遊んだこともない
- 部活で失敗して落ち込んだこともない
- 満員電車に乗って疲れたこともない
- 熱いコーヒーをこぼして「あつっ」となったこともない
つまり、現実世界を身体で生きた経験がない。
ここが、生成AIの特徴を考えるうえでとても大事です。
生成AIは、言葉の世界ではものすごく強い。
でも、人間のように身体を持って世界を生きてきたわけではありません。
だから、文章はうまいのに、ときどき変なことも言います。
そこまで「賢い」のになぜとんでもない嘘を言うのか?
生成AIには、ハルシネーションという問題があります。
簡単に言うと、もっともらしい嘘をつくことがあるということです。
「本当に知っているから話している」のではなく、
「言葉として自然そうだから出している」
もちろん、全部が嘘というわけではありません。
むしろかなり役に立ちます。
でも、自信満々に間違えることがある。
ここは、人間が使うときに注意しないといけない点です。
これも先ほどの比喩で考えると、少し分かりやすくなります。
本を読みまくっていて、言葉のつながりにはすごく強い。ですが、
- 分からないときでも、沈黙するより、それっぽく続きを話してしまう
- 人間のような生活経験に基づく常識が弱いので、言葉として自然な内容をそのまま答えてしまう
- 実体験がないので、言葉とリアルを結びつけられていない
| 人間での比喩 | 生成AIとしての原因 |
|---|---|
| 分からないときでも、沈黙するより、それっぽく続きを話してしまう | LLMは次に自然に続く言葉を生成する仕組みなので、不確かな場面でも文章を続けやすい。さらに会話用に調整される過程で、「何か役に立つ回答を返す」方向に寄りやすい |
| 人間のような生活経験に基づく常識が弱いので、言葉として自然な内容をそのまま答えてしまう | 学習データには誤情報・古い情報・矛盾も含まれる。さらに、人間のような生活経験に基づく常識でチェックしているわけではない |
| 実体験がないので、言葉とリアルを結びつけられていない | テキストや画像から世界を学んでいるが、身体を持って現実世界で試行錯誤しているわけではない。そのため、言葉として自然でも現実には不自然な回答をすることがある |

「生成AI」さんは大喰らい
ここからは少し視点を変えて、生成AIさんの燃費を見てみます。
人間は育つまでに時間がかかります。
食費も教育費もかかります。
ただ、エネルギーという観点だけで見ると、人間はかなり省エネです。
人の脳が使う電力は、ざっくり 20ワット前後 とよく言われます。もちろん身体全体のエネルギーや生活費とは別の話ですが、脳だけを見ると、かなり低い電力で高度な知的活動をしています。(PMC)
一方で、生成AIはかなりの大喰らいです。
生成AIは、まず学習段階で莫大な計算を回します。
MIT News が紹介している研究では、GPT-3クラスの学習だけでも 1,287MWh の電力を使ったと推計されています。さらに、最先端モデルでは学習コストも急拡大しており、Epoch AI は、最大級の学習実行が将来的に 10億ドル超 になりうると推計しています。(MITニュース)
しかも、生成AIは「育てるとき」だけでなく、「答えるとき」にも電力を使います。
MIT News は、研究者の推計として ChatGPT への1回の問い合わせは、単純なウェブ検索の約5倍の電力を使う と紹介しています。つまり、生成AIさんは、勉強するときだけでなく、質問に答えるたびにもエネルギーを食べているわけです。(MITニュース)
人間なら、1日の食費は数百円から数千円くらいでイメージできます。
しかし生成AIは、1日じゅう何百万・何千万・何億回も呼ばれるので、「今日の昼代いくら?」という感覚では捉えにくい。
むしろ、巨大な厨房を24時間動かしているようなものです。
モデルが大きいほど、回答が長いほど、画像や音声まで扱うほど、必要な計算資源と電力は増えていきます。
実際、IEA によれば、データセンター全体の電力消費は 2024年に415TWh、2030年には945TWh に達する見通しで、AI がその増加の大きな要因になっています。(IEA)
大量の計算をするために、世界でGPUの争奪戦や、AIデータセンター向けの電力確保が話題になっているのもこのためです。
つまり生成AIは、
「超優秀だけれど、燃費はかなり悪い」
存在です。
文句は言わない。
ルーチンもこなす。
知識量も圧倒的。
でもその裏では、巨大な計算資源と電力 を食べている。
ここも、人間との大きな違いのひとつです。
大量の計算をするために世界でGPUの争奪戦や発電所の建設ラッシュがあるのもこのせいですね。

えっ、生成AIさんライ◯ップとキッ◯ニアとUd◯myも始めたの?ス◯ッチャも?
生成AIさんは賢いのでその欠点にも気づいています。
もちろん、生成AIさん自身が欠点に気づいているわけではありません。
それを作っている研究者や企業が、欠点を減らそうとしています。

ライ◯ップで一生懸命減量しています。
生成AIの言葉ですと、量子化(計算を軽くするために数値表現を粗くする)、蒸留(大きなモデルの振る舞いを小さなモデルに学ばせる)などと呼ばれるものですね。
- 量子化は「持ち物を軽くする」イメージ
- 蒸留は「大きな先生モデルのコツを、小さな生徒モデルに教える」イメージ
ここからは、ChatGPTのような文章中心の生成AIから少し広がって、Physical AI の話です。
Physical AIとは、ざっくり言うと、ロボットや自動運転のように、物理世界で動くAIのことです。
たとえばNVIDIAのCosmosは、そうしたAIをいきなり現実世界で試すのではなく、動画やシミュレーション、合成データを使って事前に学習・検証しやすくする仕組みです。
さしずめ、事前にUd◯myで動画学習をして、キッ◯ニアで職業体験をしているかのようです。
ス◯ッチャのようにスポーツも始めました。
といっても、ChatGPTのような生成AIがそのまま走ったり卓球をしたりするわけではありません。
AIを組み込んだロボットが、物理世界で動く能力を高めている、という話です。
最近では、ヒューマノイドロボットがハーフマラソンで非常に速いタイムを出し、人間の世界記録を上回る水準だったと報じられた事例や、
Sony AIの卓球ロボットAceがエリート・プロ級選手と競えるレベルに達した事例も報じられています。
減量したり、言葉や芸術だけではなく足りなかった「体験」や「身体性」を得ようとトライしているようです。
結局、生成AIってなんなの?
最後に一言でまとめるなら、私はこう思います。
生成AIは、
生まれてから毎日図書館に通って本を読み尽くし、
最近は日◯研にも通い、
さらにヤ◯ハのエレクトーンや絵画教室にも通い始めた。
大喰らいに気づき、ライ◯ップで減量に取り組み、
読書や習い事だけでなく、もっと外で色々な体験をしようとUd◯myで学んでキッ◯ニアで職業体験をしたり、ス◯ッチャでスポーツもする
好奇心旺盛な頑張り屋さん、に近い。
だから、ものすごく物知りに見える。
会話もうまい。
文章も書ける。
絵も描ける。
音も扱える。
だから使う側も、人間に仕事を頼むときと同じように、プロンプトという指示をなるべく具体的にした方がよいです。
さらに最近では、単発の指示だけでなく、「どういう文脈でその仕事を頼んでいるのか」というコンテキストも与えた方が、望む答えに近づきやすくなっています。
でもその一方で、
人間のように身体を持って世界を生きてきたわけではない。
だから、ときどき妙な間違いもする。
もっともらしい嘘もつく。
本当に分かっているのか、少し怪しい場面もある。
この
「めちゃくちゃ賢く見える」
でも
「人間そのものではない」
という不思議さが、人によっては生成AIってすごい!人によっては生成AIって気持ち悪い・よく分からない!の正体なのだと思います。
おわりに
生成AIを難しい用語で説明しようとすると、
- 大規模言語モデル(LLM)
- Attention/Transformer
- 基盤モデル
- トークン
- マルチモーダル
- 蒸留
- 量子化
- Physical AI
など、いきなり専門用語だらけになります。
でも初心者にとって大事なのは、まず
「どういう感じのものなのか」
をつかむことかなと思って誤解を恐れず書いてみました。

- イメージを使うために生成AIを人間に模して説明しましたが、生成AIは、人間と同じ意味で言葉を理解したり、意識を持ったりしているわけではありません
- そもそも「知能」「認識」「意識」とは何か自体がAIにおいても生命においても答えの出ていない研究テーマであり、すぐAGIだ、ASIだと騒ぐ人とはちょっと距離を置いた方が良いかなと思います
- AGI:汎用人工知能。人間と同等の知能のこと
- ASI:人工超知能。人間を超えた知能のこと
- そもそも「知能」「認識」「意識」とは何か自体がAIにおいても生命においても答えの出ていない研究テーマであり、すぐAGIだ、ASIだと騒ぐ人とはちょっと距離を置いた方が良いかなと思います
- ニューラルネットは脳のニューロンから着想を得ていますが、現在のAIモデルは脳そのものを再現したものではありません
- 一方で、脳科学の知見をAI研究に活かそうとする研究も進んでいます
- ❌ 生成AI=大規模言語モデル(LLM)
- Transformer系の大規模言語モデルは、大きく見るとエンコーダー型、エンコーダー・デコーダー型、デコーダー型に分けて説明できます
- エンコーダー型
- 文章の意味を抽象化するようなことが得意 文章の分類など
- エンコーダー・デコーダー型
- エンコーダーで入力文を内部表現に変換し、デコーダーで別の文章として出力する方式です。翻訳や要約などで使われてきました
- デコーダー型
- 前の単語列をもとに、次の単語を順番に生成していく方式です
- これがスケーリング則と相まって大発展しているのが「生成AI」と呼ばれるもの
- エンコーダー型
- Transformer系の大規模言語モデルは、大きく見るとエンコーダー型、エンコーダー・デコーダー型、デコーダー型に分けて説明できます
- ⭕️ 現在の生成AIブームの中心には、ChatGPTのようなデコーダー型TransformerのLLMがあります
- また、生成AI全体には画像生成・音声生成・動画生成なども含まれます
- ❌ 生成AIは最近できた?
- 「機械学習→深層学習→生成AI」というように進化した、かのように解説している記事を見かけますが異なります
- 「何かを生成する」研究自体は昔からありました。たとえば、文章生成、画像生成、音声合成、シミュレーションなどは長く研究されてきました
- ⭕️ 生成するAIという考え方に深層学習が結びついて大きく発展した、くらいの方が正確と思います
参考
アカデミックまではいかないですが、もう少し専門的な解説
少し専門的な表現での202603時点の生成AIの状況
少し専門的な内容から、かなり専門的な内容まで学ぶための書籍紹介