この記事はコードレビューに関するTipsを投稿しよう! by CodeRabbit Advent Calendar 2025の5日目の記事です
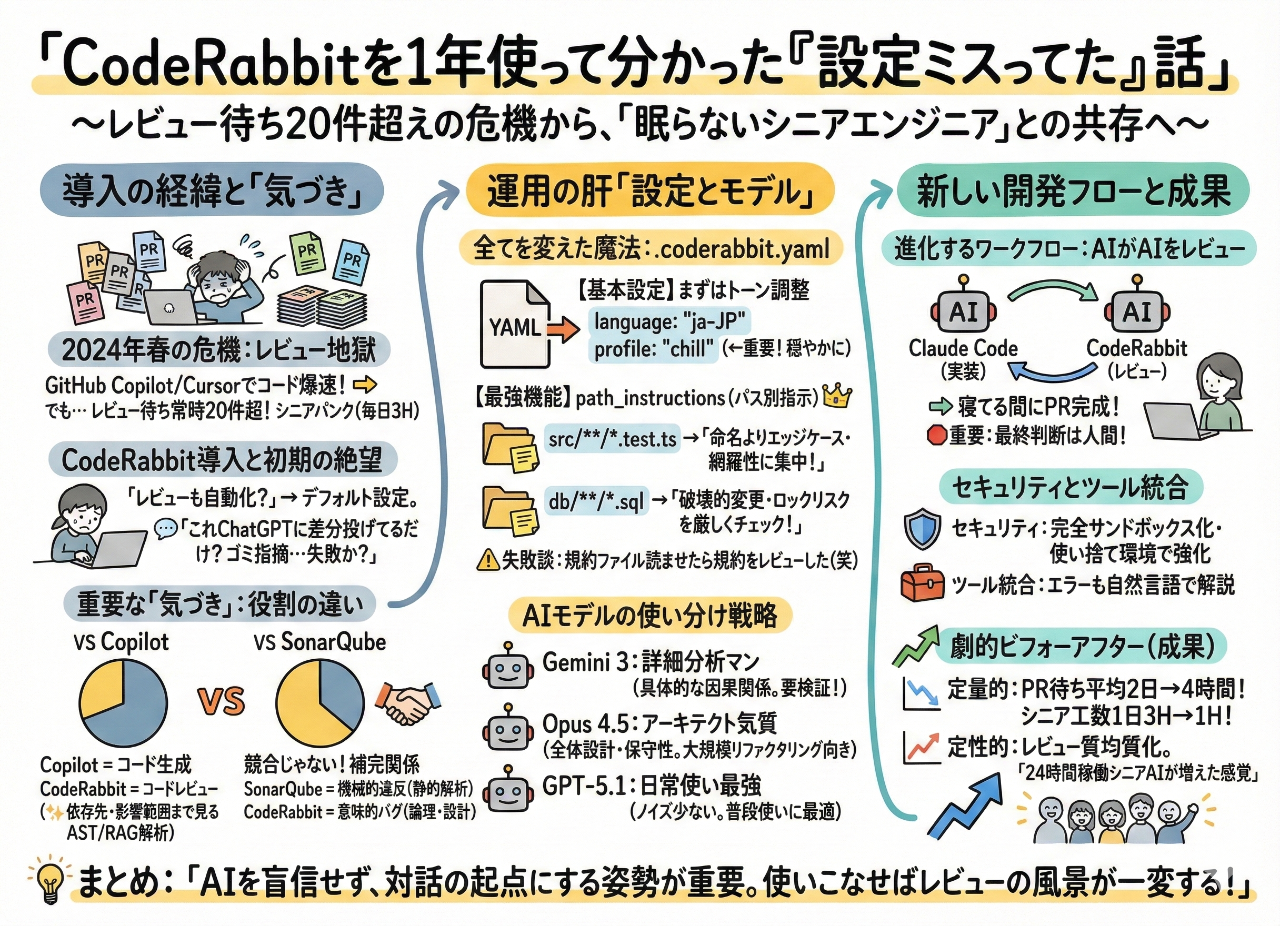
GitHub CopilotとCursorのおかげでコードは爆速で書けるようになったのはいい。でも、PRのレビュー待ちが常時20件オーバー。シニアエンジニアが毎日3時間レビューに費やしても全然追いつかない。
「AIでコード書く時代なんだから、レビューも自動化できるんじゃね?」
そんな安易な発想でCodeRabbitを入れてみた。
最初の感想?「これ、ChatGPTに差分投げてるだけじゃん」
デフォルト設定で出てくるコメントは正直ゴミみたいな指摘ばかり。「あー、これ導入失敗したわ」と思った。
ところが.coderabbit.yamlでカスタマイズを始めた瞬間、全てが変わった。
GitHub Copilotとは何が違うのか
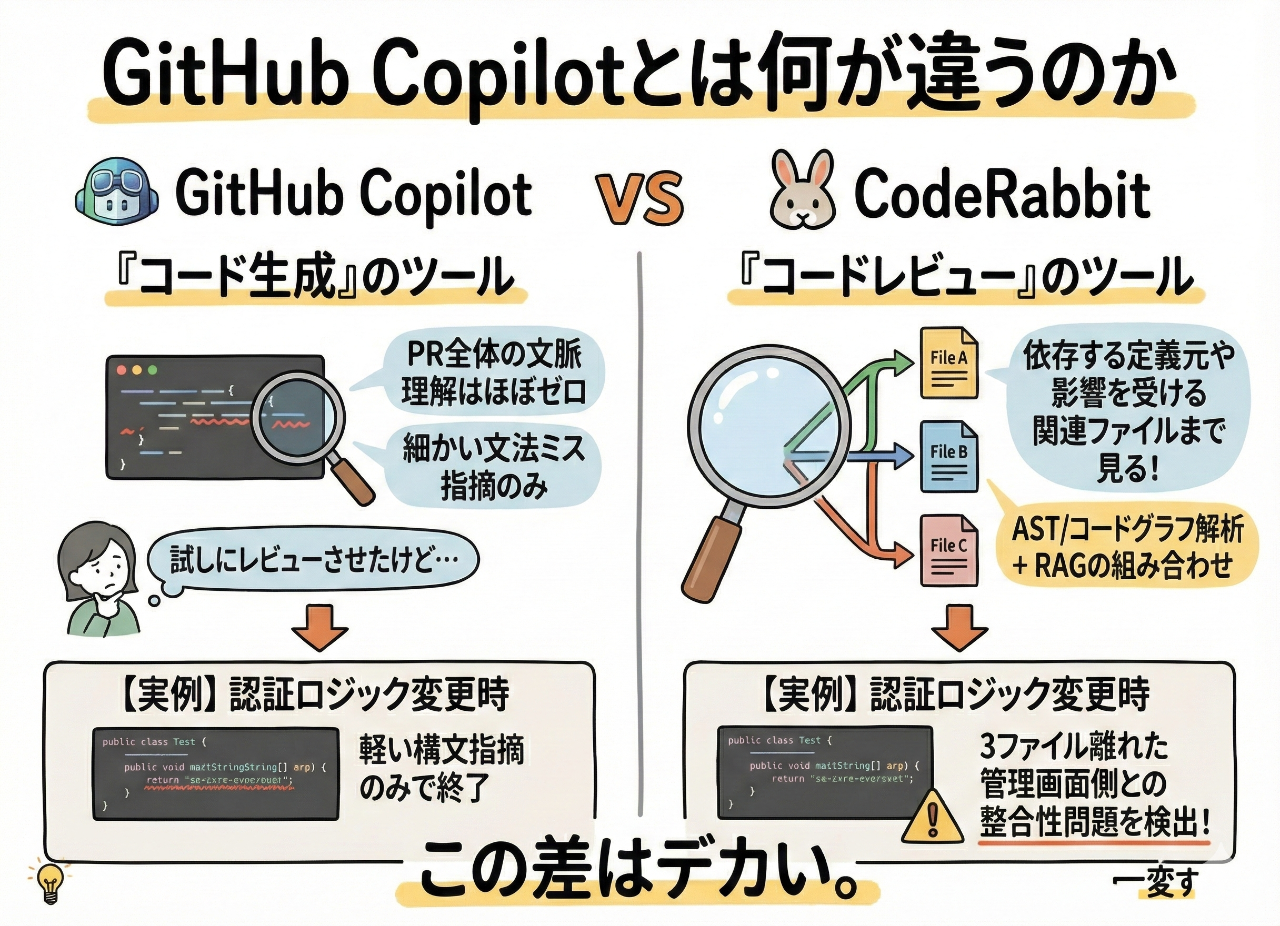
GitHub Copilotは「コード生成」のツール。CodeRabbitは「コードレビュー」のツール。この違いは明確だった。
試しにCopilotのプレビュー機能でレビューさせてみたけど、PR全体の文脈を理解した指摘なんてほぼゼロ。細かい文法ミスを指摘してくるだけ。
CodeRabbitは違った。変更された行だけじゃなくて、依存する定義元や影響を受ける関連ファイルまで見てくれる。AST解析とコードグラフ解析、それにRAGを組み合わせてるからできる芸当らしい。
実例を挙げる。認証ロジックを変更したとき、Copilotは軽い構文の指摘で終わった。でもCodeRabbitは、3ファイル離れた管理画面側の認証チェックとの整合性問題まで検出した。
この差はデカい。
SonarQubeとの使い分け
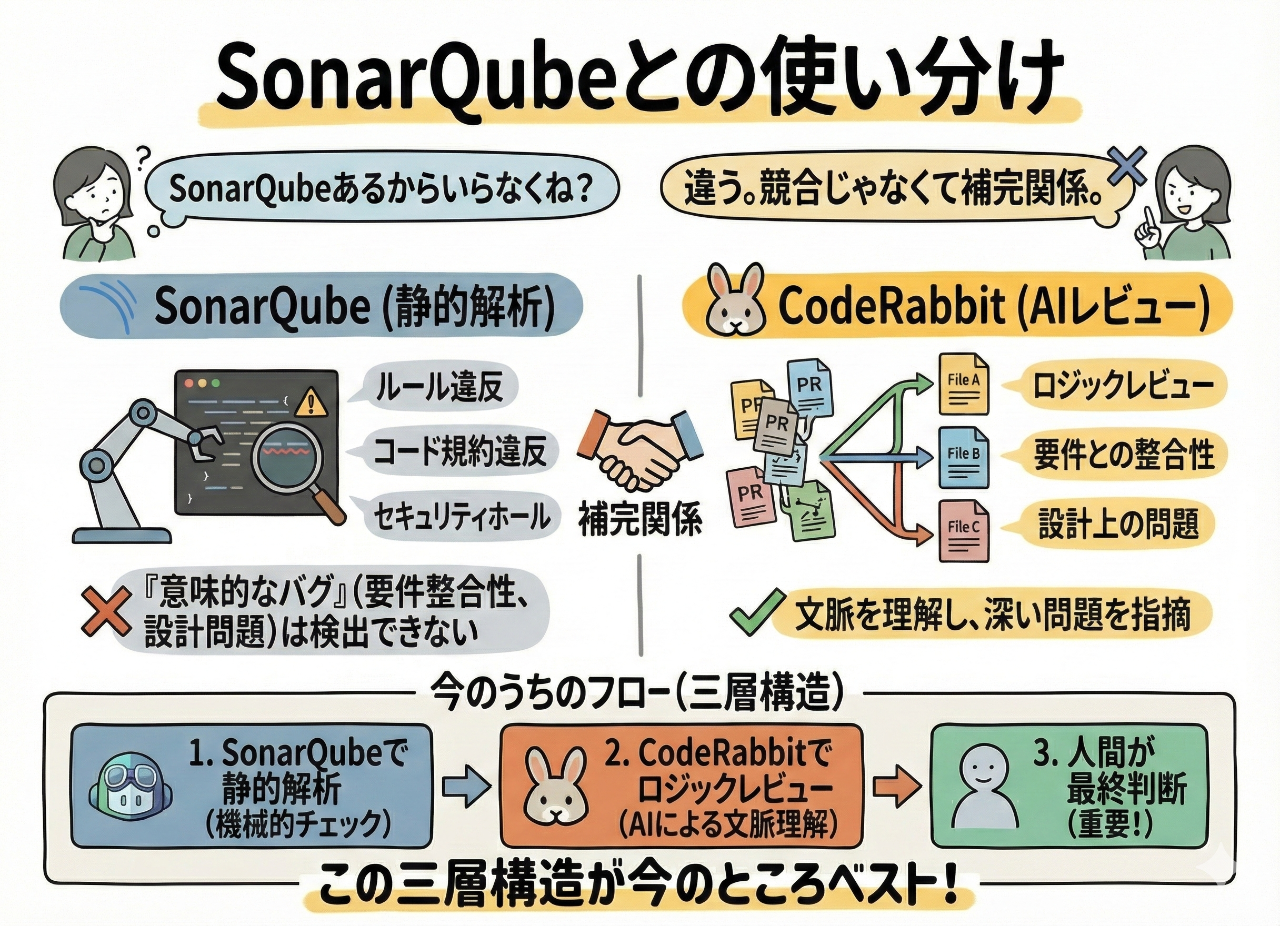
「SonarQubeあるからいらなくね?」って言われた。
違う。CodeRabbitとSonarQubeは競合じゃなくて補完関係。
SonarQubeは「ルール違反」の機械的検出が得意。コード規約違反とかセキュリティホールとか。でも、要件との整合性とか設計上の問題みたいな「意味的なバグ」は検出できない。
今のうちのフローはこう:
- SonarQubeで静的解析
- CodeRabbitでロジックレビュー
- 人間が最終判断
この三層構造が今のところベスト。
AIモデルの使い分けで勝負が決まる
CodeRabbitは内部で複数のAIモデルを使い分けてる。最初は全然理解できてなかったけど、1年使ってようやく各モデルの「クセ」が分かってきた。

Gemini 3:詳細分析マン
断定的で詳細な技術分析が得意。「並行処理のロック順序が不適切でデッドロックの可能性がある」みたいな、具体的な因果関係まで含めた指摘をしてくる。
実際、Gemini 3が検出したロックの問題が本番で顕在化したこともあった。
ただし、説得力が高すぎて間違ってても信じちゃうリスクがある。CodeRabbitチーム自身が「Gemini 3は正しいときは驚くほど正確だけど、間違ってる時でももっともらしく聞こえる」って言ってる。
だから「Gemini 3の指摘は必ず一度検証する」というルールを作った。修正提案の約65%はそのまま使えるパッチが付いてくるけど、残りは要検証。
使いどころ:複雑なバグ修正、スレッド同期、リソース管理周り
Opus 4.5:アーキテクト気質
個別実装よりシステム全体の設計整合性を見る。「この実装では認証の責務が分散しすぎてて、将来的な保守性に課題がある」みたいなアーキテクチャレベルの指摘が特徴。
大規模リファクタリングの時にOpus 4.5を使ったら、人間のアーキテクトによる監査に近いレビューが返ってきた。
Important-share(本質的に重要な指摘の割合)が他モデルより高いというベンチマーク結果も出てる。Opus系列は50%前後で、ノイズが少ない。
使いどころ:設計変更、アーキテクチャレビュー、大規模リファクタリング
GPT-5.1:日常使い最強
日常のPRレビューはこれ一択。
理由はシグナル対ノイズ比の高さ。取るに足らない指摘が少なくて、本当に修正が必要な問題だけを出してくれる。
「警告の1割でも誤検知があると、開発者は全警告を無視し始める」という現象(アラート疲れ)があるけど、GPT-5.1はFalse Positiveが少ない。
使いどころ:日常の全てのPR(デフォルトでこれ)
.coderabbit.yamlの魔力
Web UIでポチポチ設定するだけじゃ、CodeRabbitの性能を30%も引き出せない。断言する。
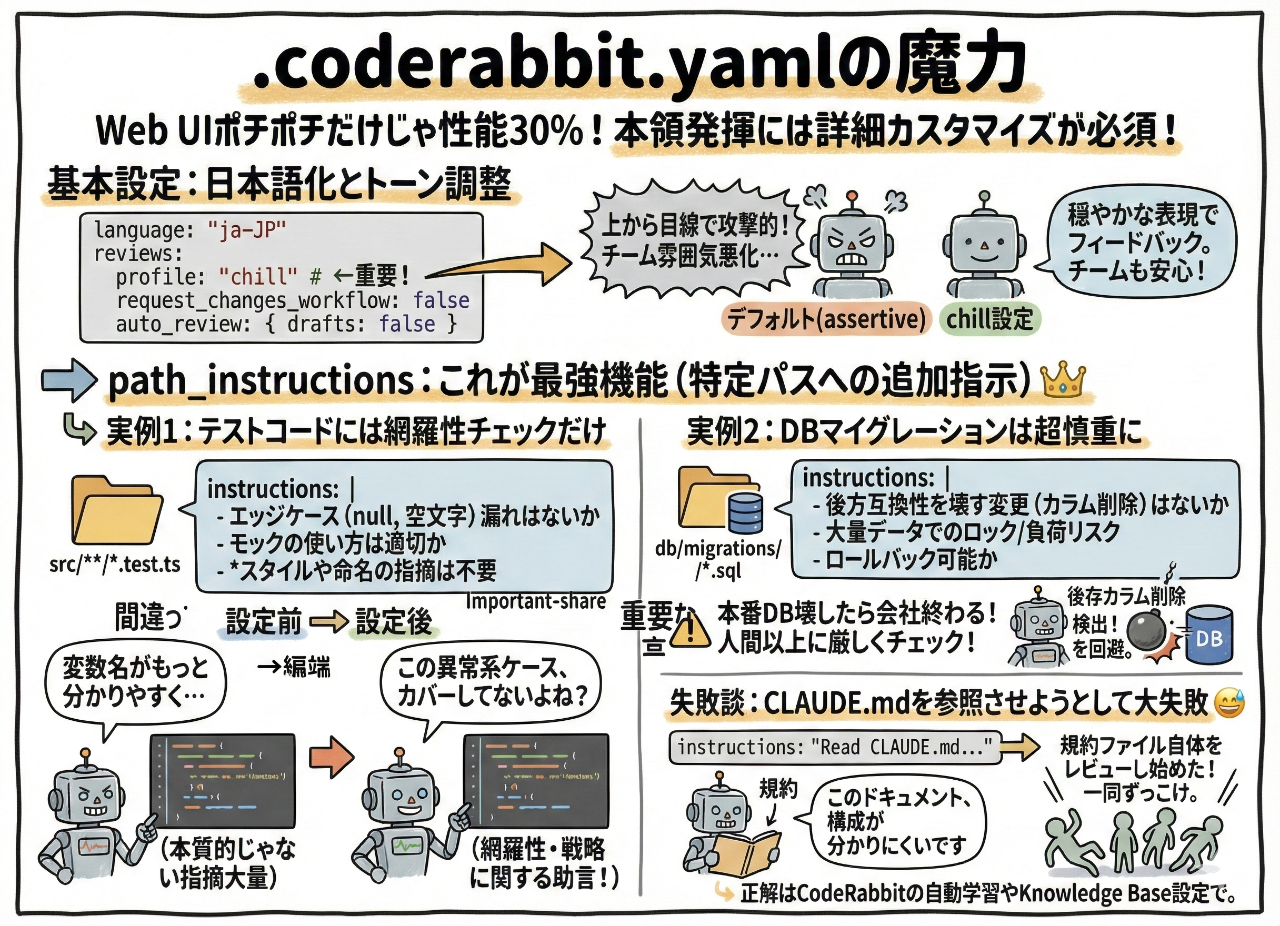
本領発揮には.coderabbit.yamlでの詳細カスタマイズが必須。
基本設定:日本語化とトーン調整
language: "ja-JP"
early_access: true
reviews:
profile: "chill" # "assertive"だとコメントが攻撃的になりすぎた
request_changes_workflow: false # AIにPRをブロックさせない
high_level_summary: true
poem: false # 業務でポエムはいらない
auto_review:
enabled: true
drafts: false # ドラフトPRはレビューしない(ノイズ削減)
profile: "chill"がポイント。デフォルト(assertive)だとコメントが上から目線で攻撃的になりがち。実際チームの雰囲気が悪くなった。
だから穏やかな表現でフィードバックが出るように設定した。
path_instructions:これが最強機能
CodeRabbitの真の最強機能はpath_instructions。これを知る前は「まぁまぁ使える」レベル。知った後は「手放せない」ツールになった。
特定のパスパターンのファイルに対してレビュー時の追加指示を与えられる。
実例1:テストコードには網羅性チェックだけ
reviews:
path_instructions:
- path: "src/**/*.test.ts"
instructions: |
これはテストコードのレビューです。以下の点に集中してください:
- エッジケース(null、空文字、境界値)のテストが漏れていないか
- any型や@ts-ignoreの乱用がないか
- モックの使い方は適切か
* スタイルや命名への細かい指摘は不要です
これ設定する前は、テストコードに対しても「変数名がもっと分かりやすく…」とか本質的じゃない指摘が大量に出てた。
本当に欲しかったのは「このテスト、異常系ケースをカバーしてないよね?」という指摘。
設定後は、網羅性やテスト戦略に関する助言だけを出してくれるようになった。
実例2:DBマイグレーションは超慎重に
- path: "db/migrations/*.sql"
instructions: |
これはDBマイグレーションファイルです。以下を厳しくチェックしてください:
- 後方互換性を壊す変更(カラム削除、テーブル削除)がないか
- 大量データ環境でのロックや負荷のリスクはないか
- 適切なインデックスが付与されているか
- ロールバックが可能かどうか
本番DB壊したら会社終わる。だからマイグレーションSQLだけは人間以上に厳しい視点でレビューさせた。
実際、既存カラム削除による後方互換性問題も自動で検出できて、ヒヤリとする変更を事前に防げてる。
失敗談:CLAUDE.mdを参照させようとして大失敗
チーム独自のコーディング規約を記したCLAUDE.mdがあって、それに沿ってレビューさせようとした。
# (うまくいかなかった例)
path_instructions:
- path: "src/**/*.ts"
instructions: "Read CLAUDE.md and follow the guidelines"
結果?CodeRabbitがCLAUDE.mdファイル自体をレビューし始めた。
「このドキュメント、構成が分かりにくいです」って規約ファイルにコメントが付いた。一同ずっこけ。
正解は、Knowledge Baseの「Code Guidelines」にファイルを指定するか、CodeRabbitの自動学習機能に任せること。デフォルトでもリポジトリ内のCLAUDE.mdやCODING_STANDARDS.mdは自動検出される。
ツール統合:AIと静的解析の合わせ技
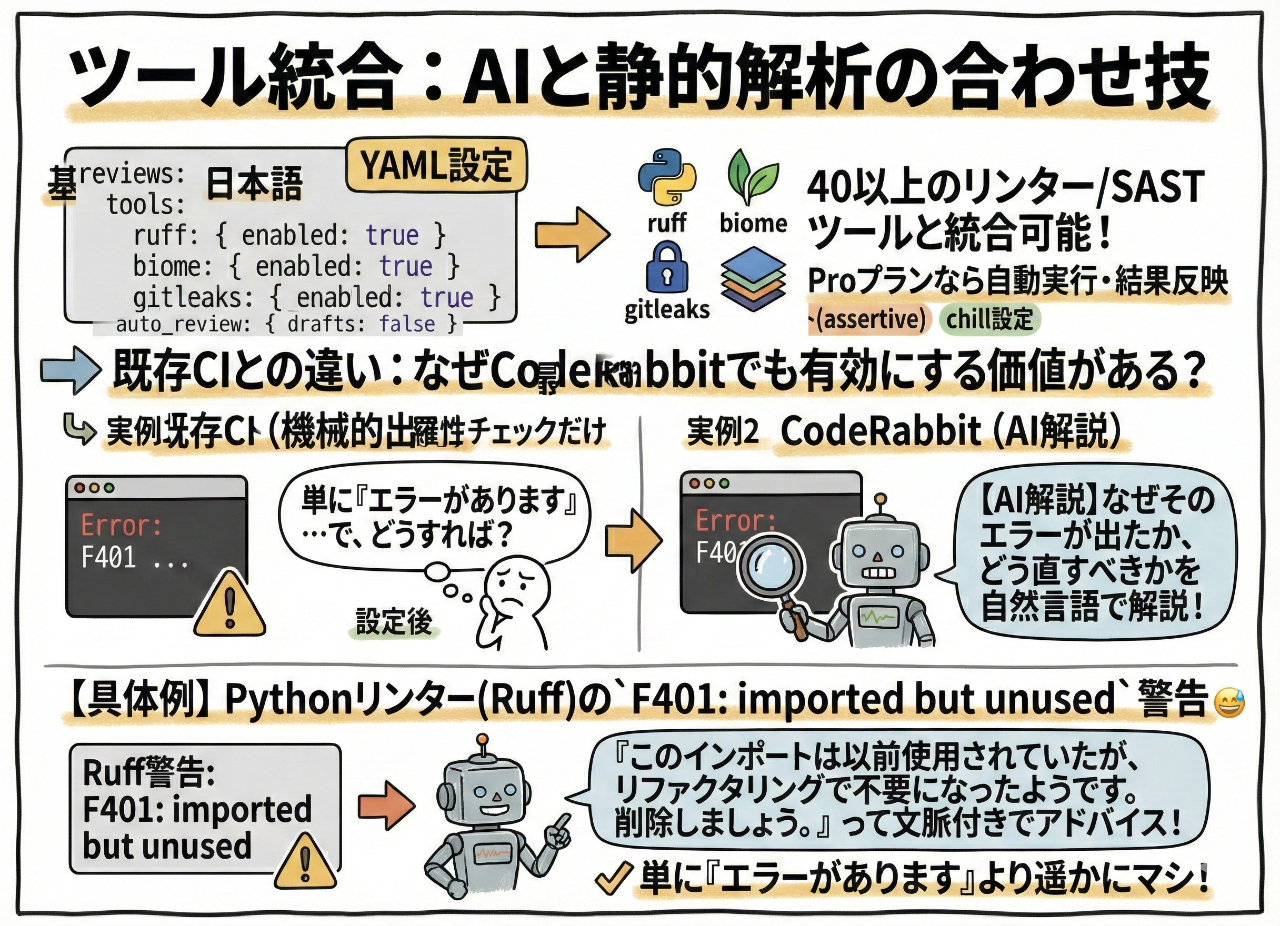
reviews:
tools:
ruff:
enabled: true
biome:
enabled: true
gitleaks:
enabled: true
CodeRabbitは40以上のリンターやSASTツールと統合できる。Proプランなら自動実行して結果をレビューコメントに反映できる。
既存CIでも同じツールを回してるけど、CodeRabbit側でも有効にする価値は大いにある。
なぜなら、CodeRabbitはツールのエラー出力を読み取って「なぜそのエラーが出たか」「どう直すべきか」を自然言語で解説してくれるから。
例えば、PythonリンターのRuffがF401: imported but unusedという警告を出したとする。CodeRabbitは「このインポートは以前使用されていたが、リファクタリングで不要になったようです。削除しましょう。」って文脈付きでアドバイスしてくれる。
単に「エラーがあります」より遥かにマシ。
AIがAIをレビューする世界
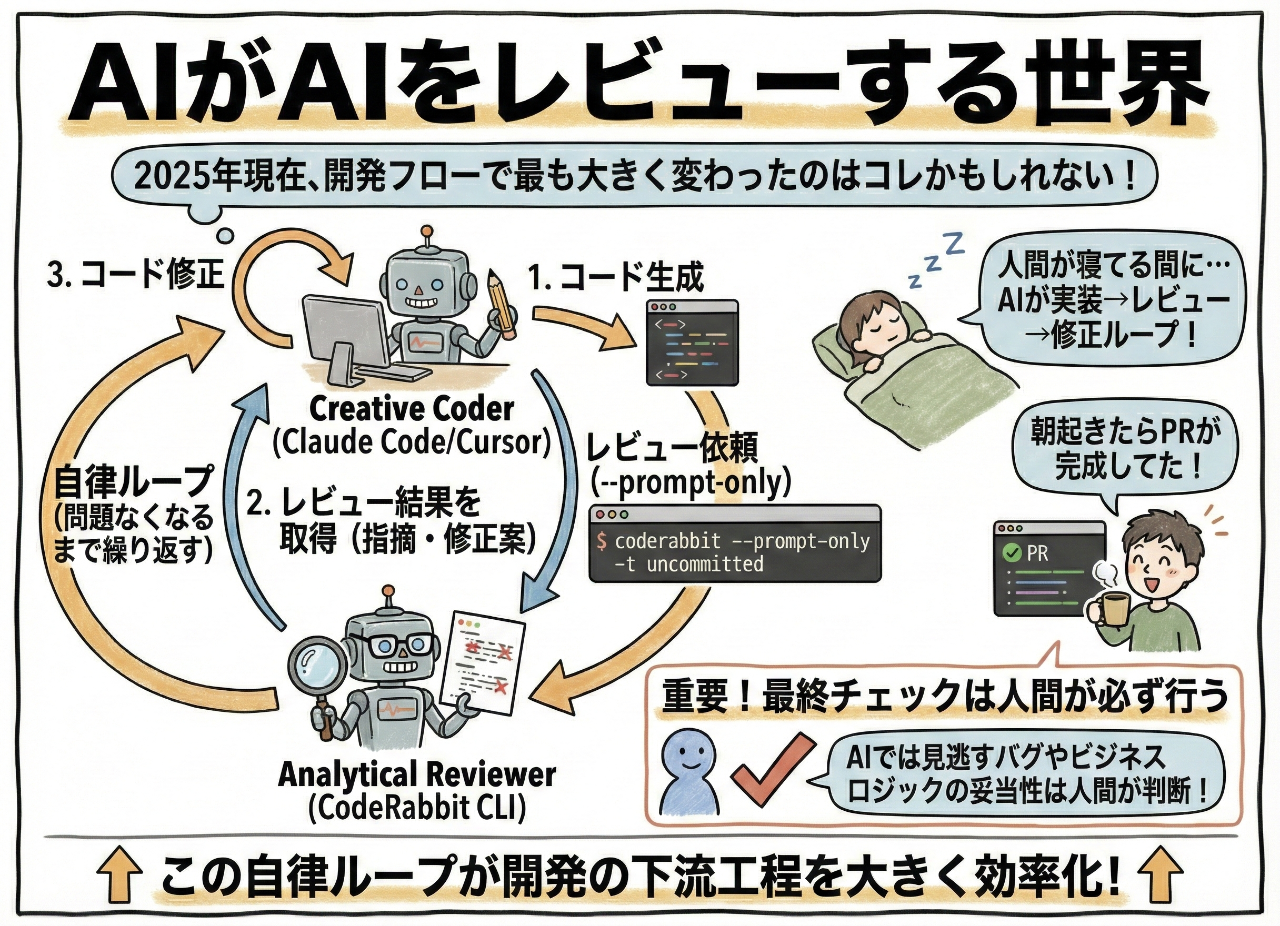
2025年現在、開発フローで最も大きく変わったのは「AIがAIをレビューする」部分かもしれない。
Claude CodeとCodeRabbitの自律ループ
Claude CodeやCursorを使ってる人には朗報。CodeRabbit CLIの--prompt-onlyモードを使えば、AIエージェント同士が自律的に会話しながらコード品質を高められる。
Claude Codeに以下のようなプロンプトを与える:
タスク7.3を実装して。終わったら
`coderabbit --prompt-only -t uncommitted`
でレビューさせて。問題があれば修正して、
問題なくなるまでこのループを繰り返して。
これで「Creative Coder(Claude Code)」と「Analytical Reviewer(CodeRabbit)」が対話する。
実際の挙動:
- Claude Codeがコード生成
-
coderabbit --prompt-only -t uncommittedでレビュー結果を取得 - Claudeがコードを修正
うちのチームで試したら、人間が寝てる間にAIが実装→レビュー→修正のループを回して、朝起きたらPRが完成してた。
もちろん最終チェックは人間が必ず行う。AIでは見逃すバグもあるし、ビジネスロジックの妥当性はAIには判断できないから。
でも、この自律ループは開発の下流工程を大きく効率化する。
セキュリティ:PwnedRabbitインシデント

2024年末、CodeRabbitに「PwnedRabbit」と名付けられた脆弱性が報告された。
Rubocop実行時に悪意ある設定ファイル(.rubocop.yml)を介して任意コードが実行される可能性があった。PRに細工をするとCodeRabbitのレビュー環境で任意のRubyコードが走り、機密情報を抜き取れた。
正直「やばくないか?」と思った。
でもCodeRabbitの対応は非常に迅速かつ徹底してた:
- 脆弱性判明後即座にRubocopの実行を停止
- 影響を受け得る全ての認証情報・シークレットを数時間以内にローテーション
- 恒久的な修正として、全てのツール実行環境を完全サンドボックス化
- PRごとに使い捨てコンテナで処理し、処理後は即座に破棄するアーキテクチャに強化
- 他にサンドボックス外で動いてるものが無いか全システムを再監査
要するに、仮にまた悪意あるコードが実行されてもコンテナ内に閉じ込められ、ホストや他の顧客データには一切アクセスできないようにした。
「PR環境は常にゼロトラストで隔離する」という原則を徹底。
データの取り扱いとプライバシー
「コードをクラウドAIに送るの不安…」という声もあるだろう。
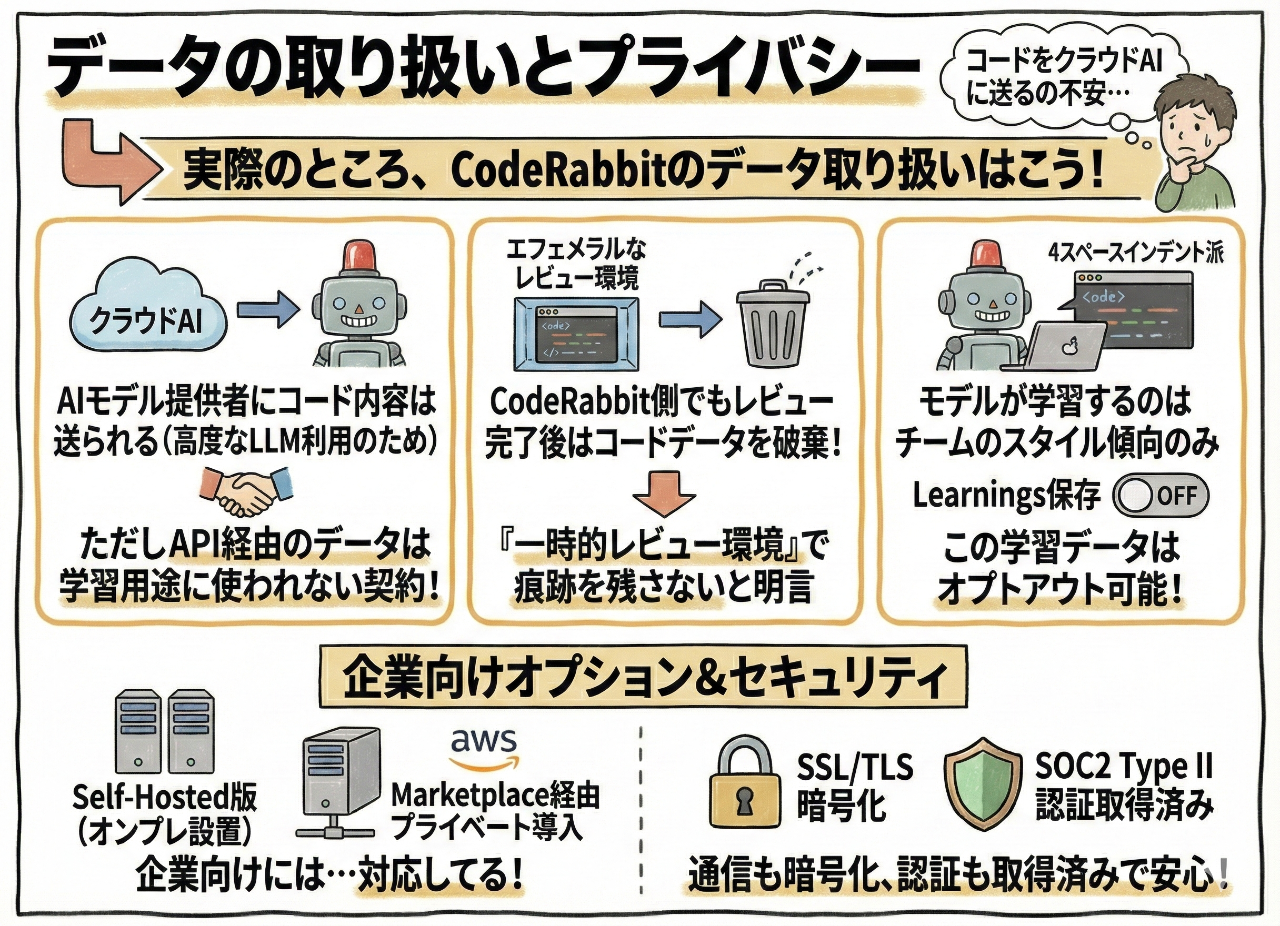
実際のところ、CodeRabbitのデータ取り扱いはこう:
- AIモデル提供者にコード内容は送られる:高度なLLMを利用してるため。ただしAPI経由のデータは学習用途に使われない契約
- CodeRabbit側でもレビュー完了後はコードデータを破棄:エフェメラルなレビュー環境で処理し、終わればデータを残さない。「コードを一切痕跡として残さない一時的レビュー環境」と明言されてる
- モデルが学習するのはチームのスタイル傾向のみ:「このチームは4スペースインデント派」みたいな。この学習データ(Learnings)を保存するかはオプトアウト可能
企業向けにはSelf-Hosted版(オンプレ設置)やAWS Marketplace経由でのプライベート導入にも対応してる。
通信もSSL/TLSで暗号化され、SOC2 Type II認証も取得済み。
実際どのくらい効果があったのか
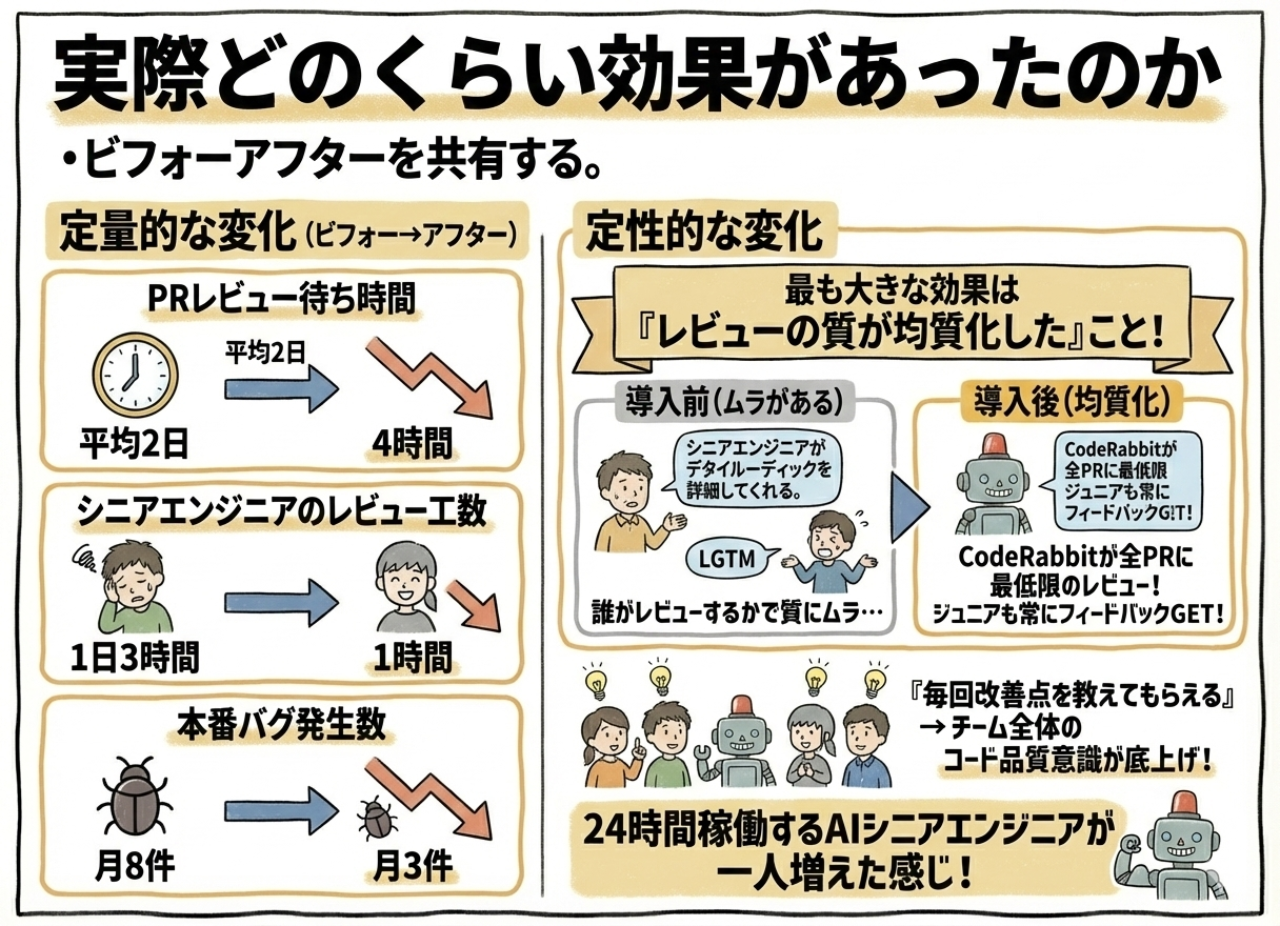
定量的な変化
- PRのレビュー待ち時間:平均2日 → 4時間
- シニアエンジニアのレビュー工数:1日3時間 → 1時間
- 本番バグ発生数:月8件 → 月3件
定性的な変化
最も大きな効果は「レビューの質が均質化した」こと。
導入前は誰がレビューするかでフィードバックの質にムラがあった。シニアがレビューしたPRは詳細な指摘がある一方、忙しい時など他のメンバーが「LGTM」と流しちゃうPRもあった。
CodeRabbitが全てのPRに最低限のレビューコメントを付けるようになったことで、ジュニアエンジニアも常に何かしらのフィードバックを受け取れるようになった。
「毎回なにか改善点を教えてもらえる」ことで、チーム全体のコード品質意識が底上げされた。
24時間稼働するAIシニアエンジニアが一人増えた感じ。
コストと投資対効果
料金は月額$30/ユーザー(Proプラン、月払いの場合)。
エンジニアの時給換算にすれば1時間分にも満たない。1日あたり10分でも開発者の時間節約につながれば元が取れる計算。
実際にはレビュー待ち時間が大幅短縮され、バグも減ったことを考えると、投資対効果は極めて高い。
オープンソース向けには無料プランもあるし、Enterprise向けにはボリュームディスカウントやセルフホスト版もある。
失敗から学んだこと
1. AIを盲信しない
Gemini 3の項でも触れたけど、AIの指摘が常に正しいとは限らない。最終判断はあくまで人間が行う。
「AIが言ってるから間違いない」ではなく、「AIの意見も参考にしつつ自分の頭で検証する」姿勢が重要。
幸いCodeRabbitは指摘に対して「なぜそう思うのか?」と聞き返すと推論プロセスを説明してくれる。そこで初めてAIの指摘が的確か見当外れか判断できる。
2. 初期設定をサボらない
デフォルト設定のまま使うとノイズが多すぎて、チームがイヤになる。
導入最初の1〜2週間でYAML設定を徹底的に調整したことが成功の鍵だった。
自チームの開発スタイルや嗜好に合わせて、攻撃的すぎるならchillに、物足りなければassertiveに、重要なディレクトリには独自指示を…と手を入れることで、ようやく「使えるAI相棒」になる。
3. チーム文化との擦り合わせ
「AIにレビューされるなんてプライドが許さない」という反発も一部にはあった。特にベテラン勢から抵抗感。
でも「AIはあくまで補助で最終判断は人間が下す」「AIのおかげでレビュー待ちが減って生産性が上がった」という実感が広がるにつれ、徐々に受け入れられていった。
導入時にはチームメンバーへの十分な説明と合意形成も忘れずに。
今後の展開:MCP対応
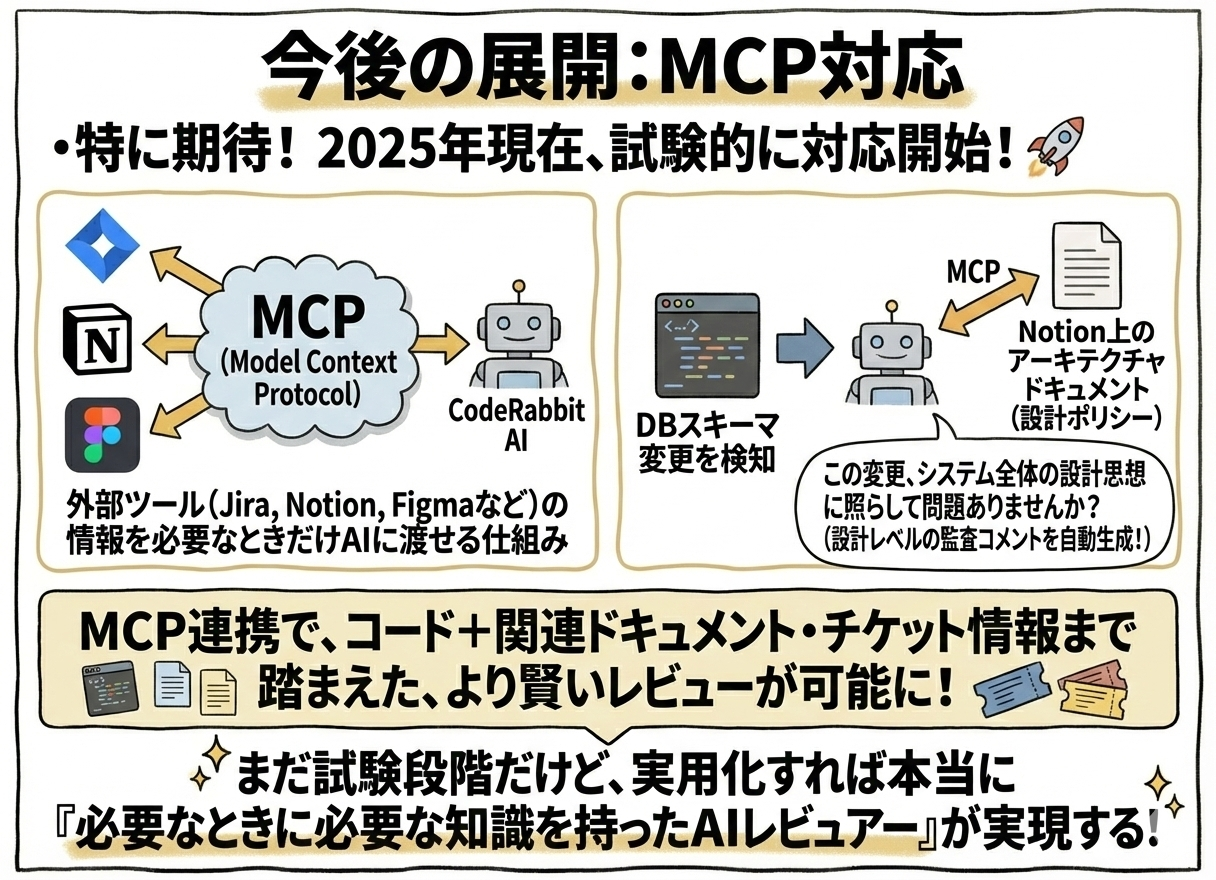
特に期待してるのはModel Context Protocol (MCP)対応。2025年現在、CodeRabbitはMCPに試験的に対応し始めてる。
MCPとは、JiraやNotion、Figmaといった外部ツールの情報を必要なときだけAIに渡せる仕組み。
例えば将来的に:DBスキーマ変更を検知したら、Notion上のアーキテクチャドキュメントから該当箇所の設計ポリシーを参照し、「この変更、システム全体の設計思想に照らして問題ありませんか?」といった設計レベルの監査コメントを自動生成する。
MCP連携により、CodeRabbitはコードだけでなく関連ドキュメントやチケット情報まで踏まえたより賢いレビューが可能になる。
まだ試験段階だけど、これが実用化すれば本当に「必要なときに必要な知識を持ったAIレビュアー」が実現する。
まとめ:AIとの付き合い方
CodeRabbitは「眠らないシニアエンジニア」のような存在。
24時間働いてくれて、疲れず、機嫌も悪くならない。でも時々間違える。
大事なのは、AIからの指摘を対話の起点にすること。「なぜそう思うのか?」と問い返し、AIの推論プロセスを聞くことで、初めてその指摘が的を射ているか判断できる。
2025年現在の開発現場は、人間だけでもAIだけでも回らない。人間がディレクターとして意思決定し、AIが実作業を担う。このバランスが今のところのベストプラクティス。
CodeRabbitはその最前線にいるツール。使いこなせば、コードレビューの風景が一変する。
導入チェックリスト
これからCodeRabbitを導入する方向けに:
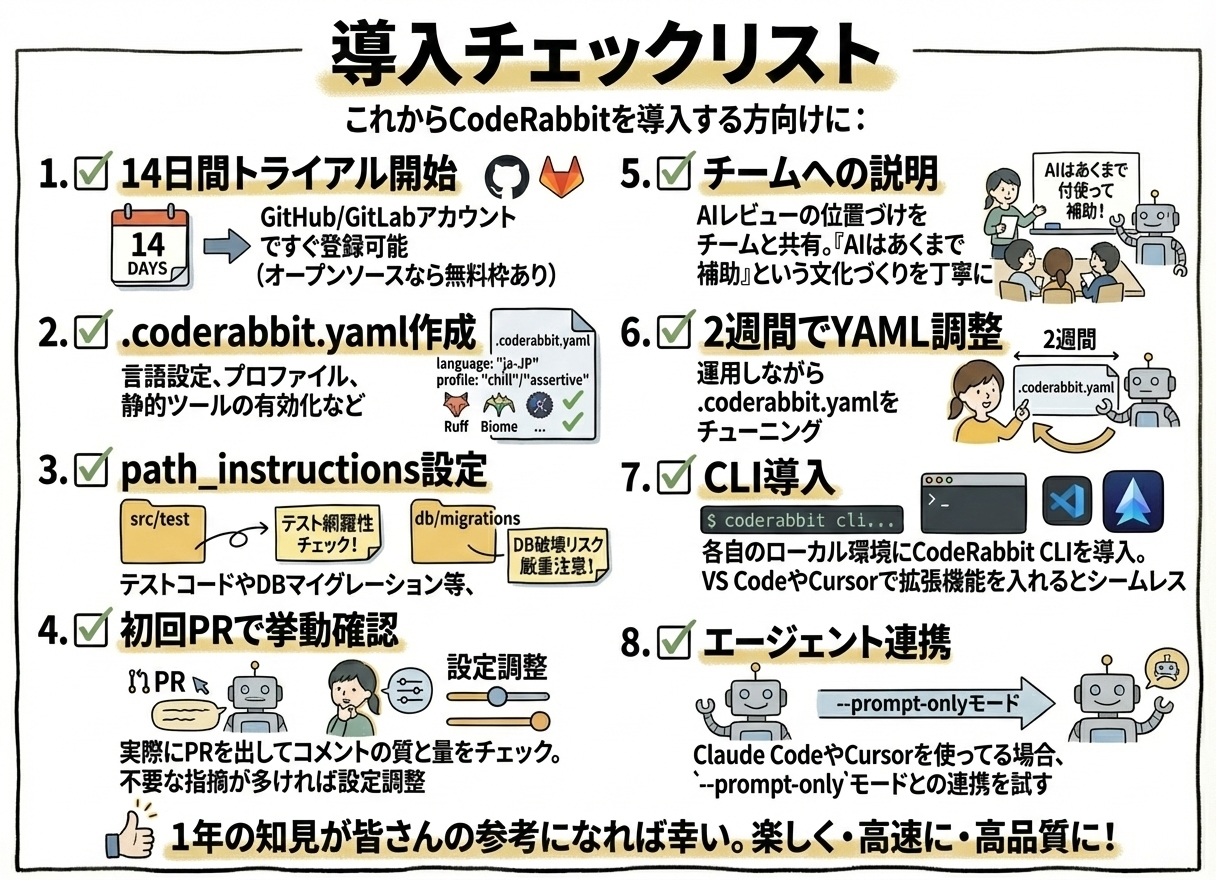
- 14日間トライアル開始:GitHub/GitLabアカウントですぐ登録可能(オープンソースなら無料枠あり)
-
.coderabbit.yaml作成:言語設定(日本語化)、プロファイル(chill/assertive)、静的ツールの有効化など -
path_instructions設定:テストコードやDBマイグレーション等、重点チェックしたいパスごとの指示を追加 - 初回PRで挙動確認:実際にPRを出してコメントの質と量をチェック。不要な指摘が多ければ設定調整
- チームへの説明:AIレビューの位置づけをチームと共有。「AIはあくまで補助」という文化づくりを丁寧に
-
2週間でYAML調整:運用しながら
.coderabbit.yamlをチューニング - CLI導入:各自のローカル環境にCodeRabbit CLIを導入。VS CodeやCursorで拡張機能を入れるとシームレス
-
エージェント連携:Claude CodeやCursorを使ってる場合、
--prompt-onlyモードとの連携を試す
1年の知見が皆さんの参考になれば幸い。
CodeRabbitの活用で、コードレビューが「楽しく・高速に・高品質に」なりますように。