はじめに
前回記事「レーベンシュタイン距離から言語間の類似度を比較してみた」にて、各国の言語を解析したのですが、その時は英語の文字列を手動でGoogle翻訳にかけて各国のデータを準備しており、解析以前にそのデータセットを用意する所が面倒だったので、MATLABから自動化できないかなと試みたので覚書として残しておきます。
せっかくなので1行ずつ解説
単語リストの読み込み
単語リストはこちらのThe Online Plain Text English Dictionaryを拝借しました。
各アルファベットから始まる単語がずらっと表になっているので、まずはこの中で"A"から始まるものをダウンロードします。Aのリンクをクリックするとcsvファイルがダウンロードされます。

Aword.csvを開くと下記のような感じで単語がずらっと並んでいます。

なので、このファイルをreadtable関数で読んでいきます。
aword = readtable('Aword.csv');
そうすると変数awordに先ほどのcsvの中身が格納されます。
データの確認
続いて、データの中身を見ていきます。毎回思うのですが、このステップが非常に大切で、例えば下記2896行目のような誤りデータが混じっていたりするので、こういうのは削除します。(とはいえ、削除の基準を明確に言葉にできないのは個人的に少しモヤモヤするのですが...)
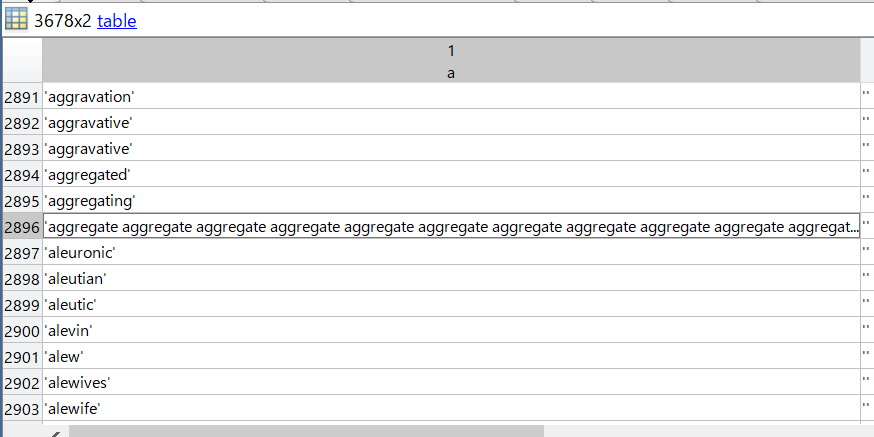
2896行目以外にもちらほらあるので、手作業で削除していきます。
aword([1958 2896 3074 3504 3535 3536 3606 3607 3650],:) = [];
重複データの削除
既にお気づきの方もいらっしゃると思いますが、どういう意図かわからないのですが、単語データが所々重複しているんですよね。なので、重複を削除するuniqueという関数で重複を取り除いていきます。
aword = unique(aword(:,1),'stable');
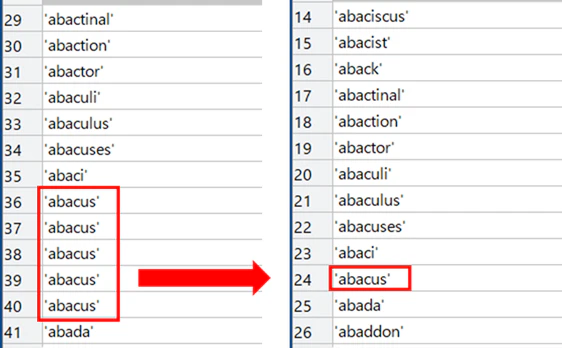
ちなみに'abacus'は、そろばんて意味らしいですね。変な単語じゃなくてよかった
Google翻訳のAPIへアクセス
無料でGoogle翻訳のAPIを作る方法はこちらの素敵すぎる記事を参考にさせて頂きました。(というか、自分でも記事を真似てデプロイを試しましたが、後述で紹介しているコードではURLまでお借りしています。ありがとうございます。)
MATLABにはRESTful Webサービスからのコンテンツの読み込み用の関数webreadがあるのでこちらを利用します。
baseurl = 'https://script.google.com/macros/s/AKfycbweJFfBqKUs5gGNnkV2xwTZtZPptI6ebEhcCU2_JvOmHwM2TCk/exec';
text = aword;
source = 'en';
target = 'nl';
for ii = 1:height(text)
url = [baseurl '?text=' char(table2array(text(ii,1))) '&source=' source '&target=' target];
options = weboptions('Timeout',15); % 任意で設定
str{ii} = webread(url, options);
end
sourceとtargetを上記のように設定すると、英語からオランダ語への翻訳ができます。こちらのコードは、翻訳したい言語によって下記のように適宜変えていくことになります。
英語:en
オランダ語:nl
ドイツ語:de
フランス語:fr
イタリア語:it
その他の言語のコードについてはこちらを参照ください。
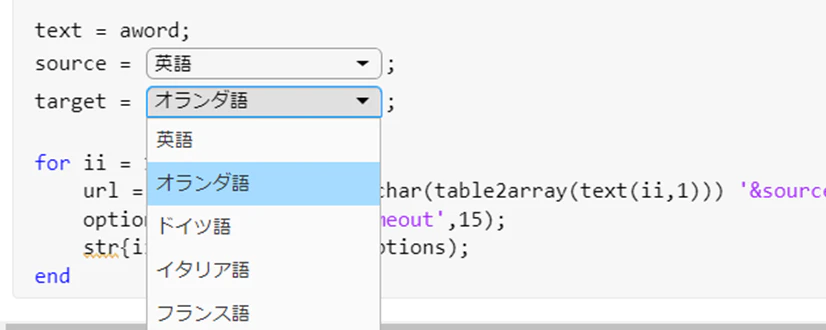
おまけ:Live Scriptのドロップダウンを使ってみた
ということで、targetの値を変えて色々な言語に翻訳していくわけですが、後々言語コードを忘れてしまうかもしれないので、Live Scriptに付けられるドロップダウンリストなるものを作成してみました。ドロップダウンリストはこちらを参考に作っています。これで、他の人にソースコードを渡しても簡単に使ってもらえそうです。
結果の表示
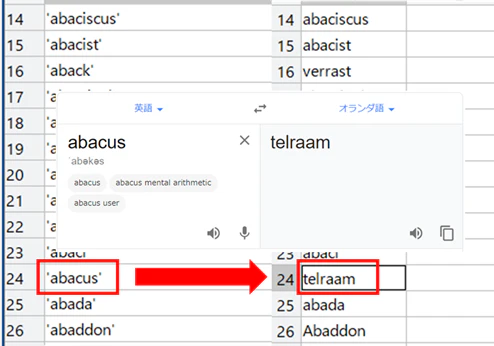
結果の格納されているstrを、見やすいように転置させて中身を確認してみましょう。
str = str';
普段使っているGoogle翻訳のGUIも重ね書きして見ましたが、うまく結果を取得できていることがわかりました。
おわりに
前回の記事の最後の方で、他の言語でも類似度を比較してみたいと書きましたが、今回作ったスクリプトを使うことで、単語数が増えても、そして、展開する言語の数が増えても、効率よく作業が進められそうです。また機会を見つけて、前回の記事の続きも試してみたいと思います。