はじめに
昔ヨーロッパに住んでいたことがあるのですが、マルチリンガルな方が多くて驚かされた経験が沢山あります。一方で、例えばパイナップルという単語がフランスでもオランダでもイタリアでもAnanasだったりという共通点もあり、各国の言葉は結構似てるのかしらと不思議に思ったものです。
そこで今日は、レーベンシュタイン距離のお勉強の題材として各国の言語をチョイスし、それらを比較してみることにします。
レーベンシュタイン距離とは?
レーベンシュタイン距離とは、編集距離とも言うのですが、2つの文字列がどの程度異なっているかを示す距離の一種です。具体的には、1文字の挿入・削除・置換によって、一方の文字列をもう一方の文字列に変形するのに必要な手順の最小回数を計算します。
例えば"analytics"と"analysis"の間の距離を計算するとしましょう。この場合、①analyticsのtをsへ置換 ②analyticsのcを削除 の2回の操作によって"analytics"を"analysis"に変換できるので、レーベンシュタイン距離は2となります。
analytics
↓ ①tをsへ置換
analysics
↓ ②cを削除
analysis
この距離を使って最近傍の単語を検索・置換することで、スペルミスを修正したりすることができます。
環境
MATLAB R2019bを使用しています。レーベンシュタイン距離の計算のためにText Analytics Toolboxも使います。
計算のステップ
データの読み込み
今回はお試し版として中1英単語・名詞1にある50語のみをピックアップ。英語をベースにして、Google翻訳にてオランダ語、ドイツ語、イタリア語、フランス語へ翻訳します。
(翻訳結果が正しいかは確認できていません)
データは下記の感じです。
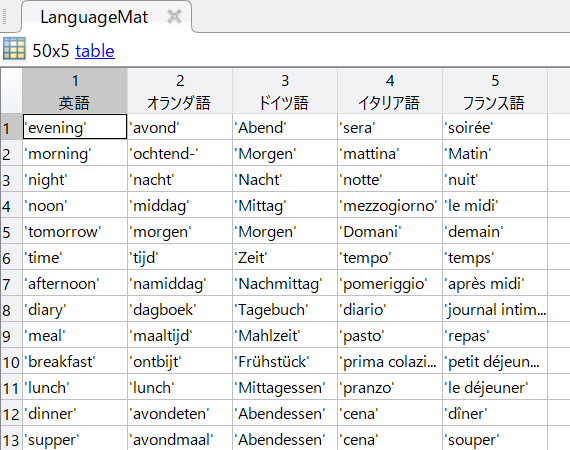
例えば5行目のtomorrowを見ると、オランダ語とドイツ語が同じ綴りだったり、イタリア語とフランス語が見た感じ似ていたり、という特徴がわかります。
レーベンシュタイン距離の計算
それでは早速レーベンシュタイン距離を計算していきます。Text Analytics ToolboxにあるeditDistanceという関数を使います。
例えば英語とドイツ語の距離を計算させると、下記のように、各単語間の距離が50個分ずらっと計算されます。

言語間の距離を可視化
50単語しかないのでデータ数としては少ないのですが、手っ取り早く50語分の距離を平均し、heatmapにて可視化してみます。コードは下記。
load LanguageMat % table型で事前に用意しています。「データの読み込み」欄の画像を参照。
for ii = 1:width(LanguageMat)
for jj = 1:width(LanguageMat)
DistanceMat(ii,jj) = mean(editDistance(table2array(LanguageMat(:,ii)),table2array(LanguageMat(:,jj))));
end
end
figure;
h = heatmap(LanguageMat.Properties.VariableNames,LanguageMat.Properties.VariableNames,DistanceMat);
結果はこちら。距離の値が小さいほど類似度が高いです。
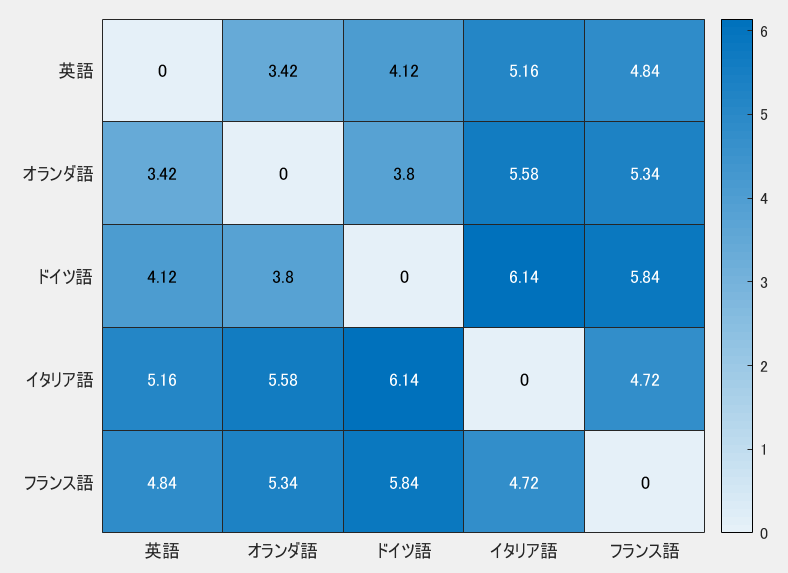
LanguageMatを見て直観的に感じる通り、レーベンシュタイン距離からも、
・英語とオランダ語が似ている
・オランダ語とドイツ語が似ている
・イタリア語とドイツ語はあまり似ていない
・フランス語とイタリア語は比較的似ている
などといった特徴を見て取ることができました。
おわりに
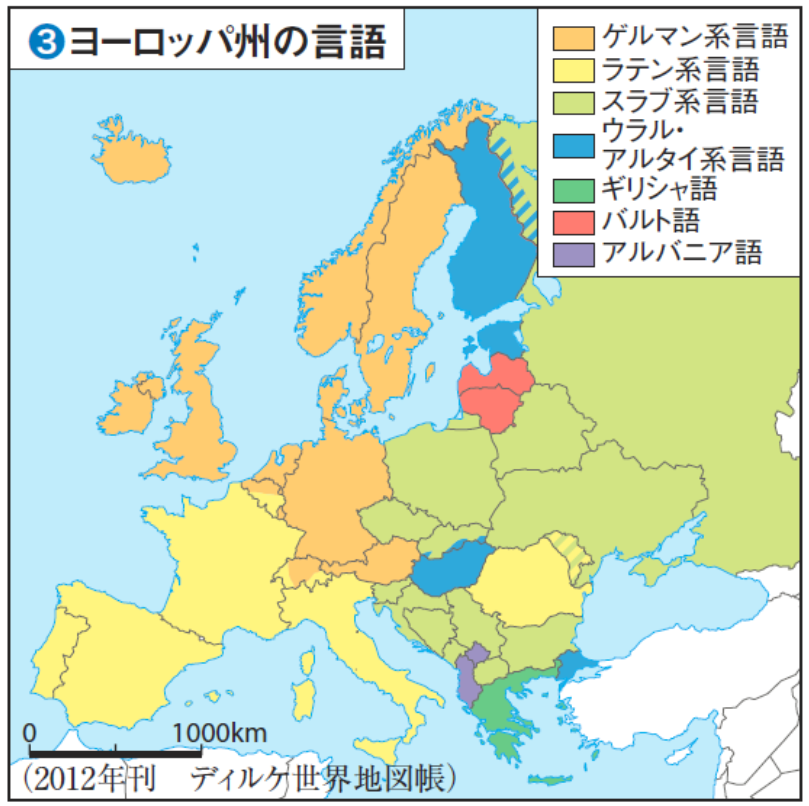
ヨーロッパの言語分布から見てみると(参考:ディルケ世界地図帳)、
・英語・オランダ語・ドイツ語=ゲルマン系言語
・イタリア語・フランス語=ラテン系言語
なので、なかなか腑に落ちる結果になったかなと思います。
他の言語でも試してみると、また面白い結果が得られそうですね。