🔍 Webスクレイピングとは
Webサイトから情報を抽出するコンピュータソフトウェア技術のこと。 @Wikipedia
Pythonは、スクレイピングに適したライブラリが揃っているのでオススメです。
基本どの言語でも可能なので、RubyやJavaScriptなどでも可能
今回は、基礎部分を分かりやすくまとめていこうと思います。
準備
● Python3
pip install beautifulsoup4
pip install requests
pip install urllib
「Beautiful Soup 4」は、PythonでWebスクレイピングに使うオススメのライブラリです。
エディタは何でも良いですがVSCodeが一番人気です。
さっそく実践してみよう
・ページすべてを取得
# ライブラリの読み込み
from bs4 import BeautifulSoup
import urllib.request
# URL
url = "https://www.yahoo.co.jp/"
# URLにアクセス
html = urllib.request.urlopen(url)
# HTMLをBeautifulSoupで扱う
soup = BeautifulSoup(html, "html.parser")
# 出力
print(soup)
結果(長いのでtitle以下略)

Yahoo!のHTMLがすべて表示されました、コードは驚くほど簡単です。
・目的の部分を取得 .find()
次にQiitaのアドベントカレンダーの以下の赤文字部分を取得してみよう。
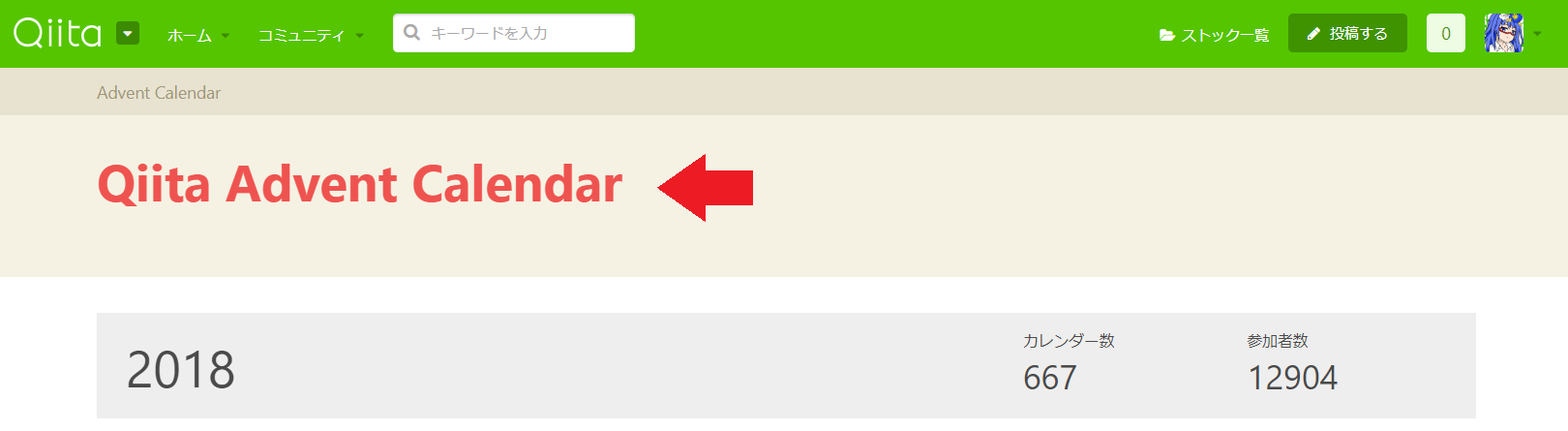
右クリック → 検証 でHTMLの構造を見ます。(Chromeの場合)
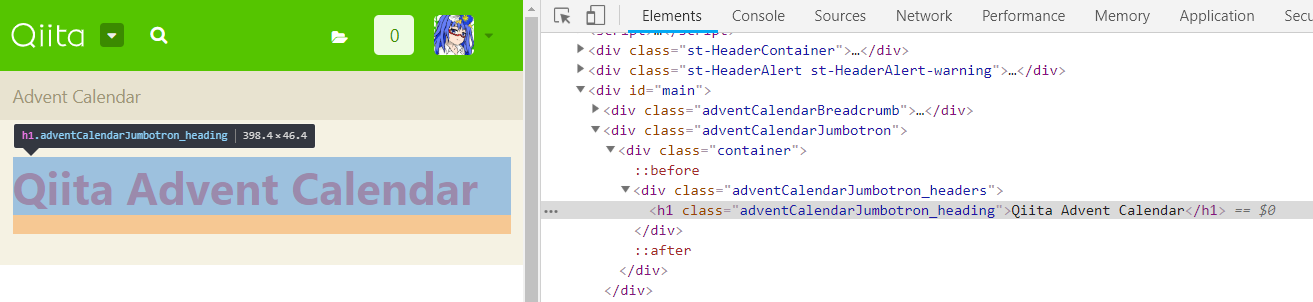
<h1>~</h1>な事が分ったので
# ライブラリの読み込み
from bs4 import BeautifulSoup
import urllib.request
# URL
url = "https://www.yahoo.co.jp/"
# URLにアクセス
html = urllib.request.urlopen(url)
# HTMLをBeautifulSoupで扱う
soup = BeautifulSoup(html, "html.parser")
# 出力
print(soup.find("h1"))
# .get_text()を付けて抽出
print(soup.find("h1").get_text())
結果
findを使って取得、1つだけ取得します。
複数あった場合は1つ目が取得され、.get_text()を使用する事でテキストを抽出できます。
・要素をすべて取得 .find_all()
私のGitHubのTOPにある6つのリポジトリ名の部分の要素すべて取得してみます。
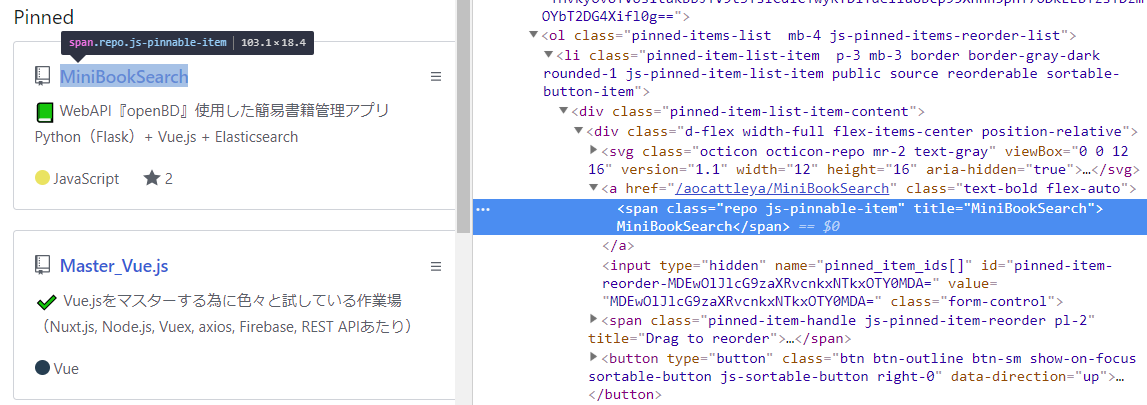
<span>タグのクラスrepo js-pinnable-itemという事が確認できました。
# ライブラリの読み込み
from bs4 import BeautifulSoup
import urllib.request
# URL
url = "https://github.com/aocattleya"
# URLにアクセス
html = urllib.request.urlopen(url)
# HTMLをBeautifulSoupで扱う
soup = BeautifulSoup(html, "html.parser")
# 出力する
print(soup.find_all('span',class_='repo js-pinnable-item'))
# 一つ目の要素を抽出する
print(soup.find_all('span',class_='repo js-pinnable-item')[0].get_text())
find_allを使う事で要素すべてをリスト化して返します。

リストなので[0]で1つ目を指定し.get_test()で、MiniBookSerch を取得できた。
・CSSなどを指定して要素を取得 .select()
私のGitHubのリポジトリ1つ目の説明文を取得してみます。
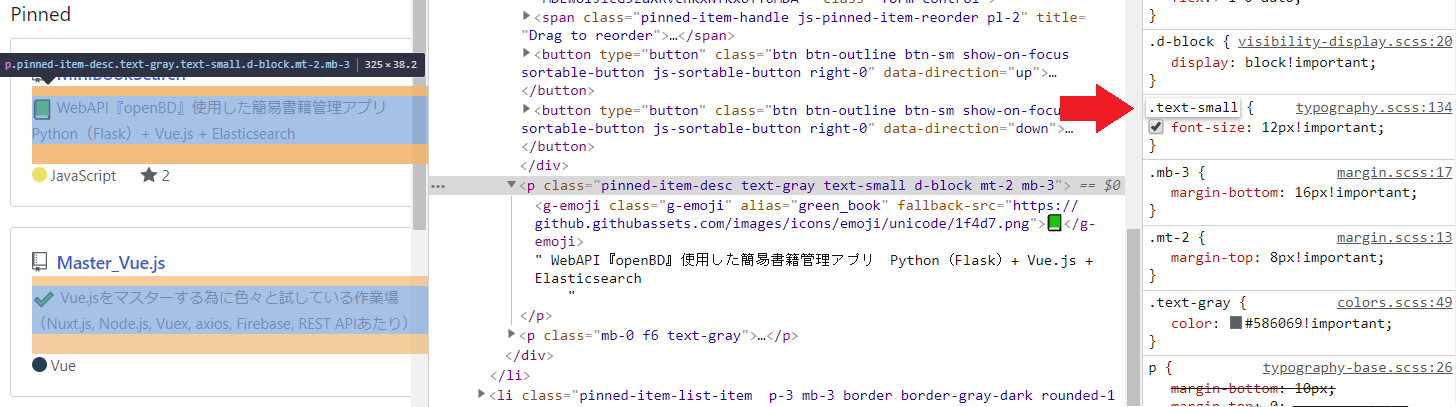
cssで.text-smallが使われているのが確認できました。
# ライブラリの読み込み
from bs4 import BeautifulSoup
import urllib.request
# URL
url = "https://github.com/aocattleya"
# URLにアクセス
html = urllib.request.urlopen(url)
# HTMLをBeautifulSoupで扱う
soup = BeautifulSoup(html, "html.parser")
# 出力する
print(soup.select(".text-small")[1].get_text())
selectを使用する事で、cssのidやクラスを指定して要素を取得できる。
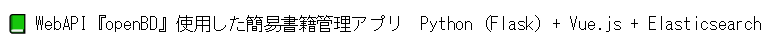
無事、1つ目のリポジトリの説明文を取得が成功!
💬 スクレイピング注意事項
・Webスクレイピングの注意事項一覧
読んでおき利用には注意を払いましょう。
・岡崎市立中央図書館事件
常識的なアクセス頻度で蔵書検索システムを使い勝手良くしてた所、
サイトの脆弱さが相まって閲覧困難になってしまい逮捕された事件です。
🌐 WebAPIの利用
Application Programming Interfaceの略
何かしらのサービス提供者が、そのサービスを利用するために提供するインタフェース
Webサイトの提供者によって、データを提供してくれているサイトも多いです。
せっかくなのでここでまとめておきます。
openBD の場合は、書籍情報や書影をだれでも自由に使える。
書籍:リーダブルコード ISBNコード:4873115655
※ ISBNコードは、本の裏に書かれているコードでamazonなどでも確認できる。
そしてURLはコードを、=の後に繋げて下記のようになる。
https://api.openbd.jp/v1/get?isbn=4873115655
# ライブラリの読み込み
import json
import urllib.request
# URL
url = 'https://api.openbd.jp/v1/get?isbn=4873115655'
# URLにアクセス
response = urllib.request.urlopen(url)
# JSONデータをcontentに代入
content = json.loads(response.read().decode('utf8'))
# 欲しいデータを指定
text = content[0]['onix']['CollateralDetail']['TextContent'][0]['Text']
# 出力
print(text)
APIから書籍は、json形式で帰ってきます。
#欲しいデータを指定 の所で今回は書籍の説明文を指定して取得しています。

これで書籍『リーダブルコード』の説明文が取得できました。
実際アプリに組みこむ場合は、直接に書籍URLをコードに書くわけにはいかないので、
url = 'https://api.openbd.jp/v1/get?isbn=' + ISBN
このようなISBN部分を変数で連結してプログラムを実行します。
終わりに
今回、Pythonによるスクレイピング基礎をまとめてみました。
最初はやっぱり想像以上のシンプルさに驚きました。
Pandasライブラリを使用して表をパパっと取得したりもしてみましたが、ズレが生じやすいみたいでサンプルに良さそうなサイトを見つけられなかったのでここでは扱っていません。
ここでの内容は基礎なので、面白そうに感じてくれれば応用してもっと難しいものに挑戦してみてください!私も挑戦してみようと思います。
リンク
![]() 今回のコードのまとめ
今回のコードのまとめ
https://github.com/aocattleya/WebScraping
![]() GitHub
GitHub
https://github.com/aocattleya
📗 Qiita
https://qiita.com/aocattleya