所属する研究室で、研究に必要な書籍を購入する時に、一度秘書さんにリストを送って発注をかけてもらうのだが、本の著者名、タイトル、出版社、URLをまとめておかないといけないので、冊数が増えるとこの作業が地味にめんどくさかった。
そこで(?)、最近話題の、LLVMベースのJITコンパイラでC並みの速度で計算ができる、Julia言語を無駄に使い、この作業を半自動化してみた。
正直Juliaを使う理由は特に無いが、練習がてら触ってみた。
まず最初に買いたい本のURLだけをコピペした。
url.txt
https://www.amazon.co.jp/dp/4274219992/
https://www.amazon.co.jp/dp/4274219348/
https://www.amazon.co.jp/dp/4785315709/
https://www.amazon.co.jp/dp/4621088173/
その後にurl.txtと同じディレクトリで、以下のプログラムを作成して、
julia AmazonOrder.jl
と打った。
AmazonOrder.jl
# Pkg.add("Requests")
# Pkg.add("Gumbo")
using Requests
using Gumbo
# 重複を除く
lines = open("url.txt", "r") do fpd
readlines(fpd)
end
lines = unique(lines)
open("new_url.txt", "w") do fpn
write(fpn, lines)
end
open("ToHoge.txt", "w") do fp1
# 定型文
write(fp1, "Hogeさん\n\n")
NoBook = length(readdlm("new_url.txt"))
write(fp1, "お疲れ様です、@antiplasticsです。\n")
write(fp1, "以下の" * string(NoBook) * "冊の書籍の購入を公費でお願いします。\n")
write(fp1, "全て揃ってからの受け取りで結構です。\n")
write(fp1, "受け取りは何時でもかまいません。\n")
write(fp1, "よろしくお願いします。\n\n")
write(fp1, "@antiplastics\n\n\n")
# Web scraping
counter1 = 0
open("new_url.txt", "r") do fp2
for line in eachline(fp2)
request = get(rstrip(line))
doc = parsehtml(Requests.text(request))
counter1 = counter1 + 1
print(string(counter1) * " / " * string(NoBook) * "\n")
write(fp1, string(counter1) * ".\n")
res = string(doc.root[1][19])
res = replace(res, "<meta name=\"keywords\"content=", "")
res = replace(res, "></meta>", "")
res = replace(res, "\"", "")
res = replace(res, "^ ", "")
res = split(res, ",")
counter2 = 0
for val = res
counter2 = counter2 + 1
if(match(r"[0-9]{9}", val) != nothing)
break
end
end
# 著者名
write(fp1, "著者名 : ")
write(fp1, join(res[1:counter2-3], " "))
write(fp1, "\n")
# タイトル
write(fp1, "タイトル : ")
write(fp1, res[counter2-2])
write(fp1, "\n")
# 出版社
write(fp1, "出版社 : ")
write(fp1, res[counter2-1])
write(fp1, "\n")
# URL
write(fp1, "URL : ")
write(fp1, line * "\n")
write(fp1, "\n")
# sleep
sleep(2)
end
end
end
うまく出力されると以下のような文章がファイルに書き出される。
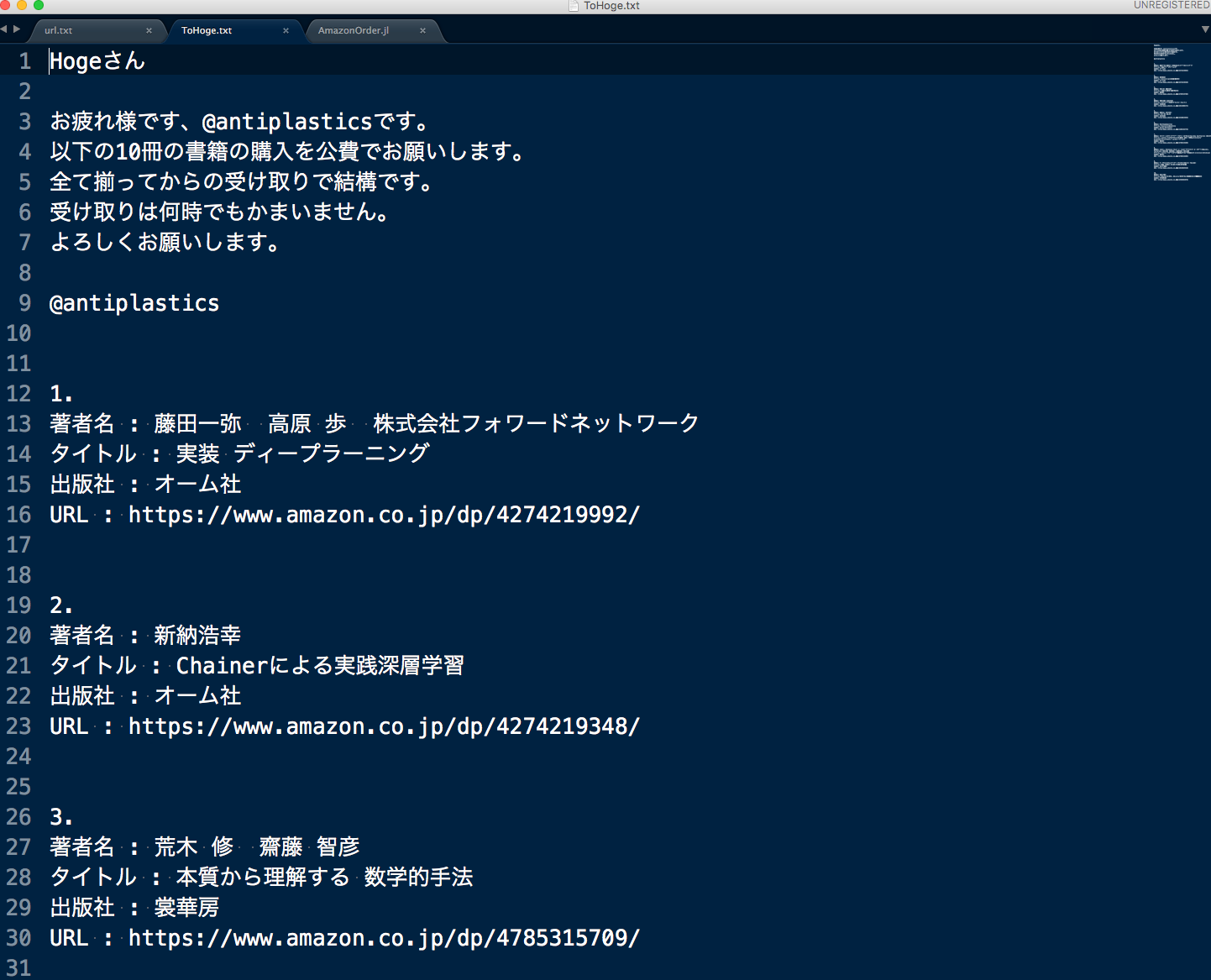
あとはこの文章をメールにコピペして、送信するだけ。
Julia便利!