TL;DR
以下何ヶ所か配置してあるこのような Note 部分だけ拾って読んでもOK!
初めに
この記事は、Julia Advent Calendar 2023 の14日目の記事です。
今年、私が少しずつ書いてきた Julia の入門書(『実践Julia入門』)が出版(商業出版)されました。
これ早く出したかったんです。できる限り早く Julia ユーザの皆さんに届けたかった。
その理由は、『これさえ読んでおけば Julia の基本はばっちり押さえられる』言い換えると 『「それこの本に書いてあるよ」と言う言葉で Julia の基礎知識を共有できる』 ことを目指して書いてきたからです。
特に Julia の概念と仕様と基本機能については広く深く丁寧に書き切ったつもりであり、ある程度「それこの本に書いてあるよ」と言えるような内容になっていると自負しています。
とは言え、見てほしい読者全てにはまだまだ行き渡っていないのだろうな、というのが正直な実感です。
なぜなら、今年(拙著が出版された3月以降)投稿された各 Julia の技術記事(Qiita、Zenn、その他個人ブログ等)を見ても「それこの本に書いてあるよ」という内容や、それどころか 「そんなことこの本に書いてないよ!(もっと良い方法があるよ)」 という内容さえ割と散見されるからです![]()
そこで、この記事を書くことにしました。
全てではありませんが、拙著『実践Julia入門』(長いので以下 JJN と略記しますw)に記載の内容をベースに、「(こういう記事内容をよく見かけるけれど)こうした方が良いよ」もしくは「こういう方法もあるよ」といったことを思いつくままに書いていきます。
シチュエーション1: Julia のインストール
まずは Julia のインストールから(!)
よく見かけるのは以下のような内容です:
公式サイト(Download Julia)からバイナリをダウンロードして指示に従ってインストールする。
はい。これはこれでもちろん間違っていませんし、JJN にもその方法も記載しています。
でも。JJN にも記載しているし、このダウンロードサイトでも言及されている、もう1つの(より簡単な)方法があるの、ご存じですか? それが以下の方法です:
-
juliaup を利用してインストールする:
- Windows の場合:Microsoft Store から julia をインストールすればOK(
juliaupコマンドと、その時点の最新版の Julia がインストールされます)(wingetによるコマンドラインでのインストールももちろんOK) - Linux/macOS 等の場合:juliaup の github ページ の README に記載のコマンド一発でOK(
juliaupコマンドと、その時点の最新版の Julia がインストールされます)
- Windows の場合:Microsoft Store から julia をインストールすればOK(
juliaup を利用した Julia のインストールの利点は以下の通りです。
- 常に Julia の最新安定版がインストールされる。
- Julia のアップデートもコマンド一発でできる。
- release/lts/beta 等、チャンネル ごとの最新版がインストール・更新できる。
- 自動的に
juliaコマンドにパスが通る(特に Windows の場合地味に便利!)
チャンネル について簡単に補足しておきます。
これは「リリースされる Julia のカテゴリー」を表すものです。主なチャンネルを以下の表に記しておきます。
| チャンネル名 | 説明 | バージョン(2023/12/14 時点) |
|---|---|---|
| release | 最新安定版(Current Stable Release) | v1.9.4 |
| lts | LTS版(Long-Term Support Release) | v1.6.7 |
| beta | 次期版(Upcoming Release)1 | v1.10.0-rc2 |
juliaup は各チャンネルごとに、そのチャンネルの範囲内の最新バージョンをインストール/更新することができます。
デフォルトでは release チャンネルのみが追加されており、なので初回インストール時にはその時点の最新安定版の Julia が同時にインストールされます。また公式サイト等で「バージョンが上がった」というアナウンスがあった場合は、コマンドラインで juliaup up(または juliaup up release)とするだけで Julia のバージョンアップ(更新)ができます。とても便利です。
私自身も Windows/Ubuntu (on WSL)/macOS では juliaup を利用しています。個人で使う分にはまた実験的に使う分には、これで十分です。
(なお Linux 専用マシンでは自分で管理したいのでバイナリをダウンロードして手作業でインストールしています)
Julia はセマンティックバージョニングを採用しており、バージョンが上がっても(メジャーバージョンが上がらない限りは)破壊的な仕様変更は(原則として)ありません。
ユーザはいつでも「その時点の最新安定版 Julia」を使えば基本的にはOKです。
juliaup のチャンネルに基づくバージョン更新機構はその思想の元に成り立っています。
「juliaup up すれば常に最新安定版の Julia が利用できる」ということをぜひ覚えておいてください。
詳細は JJN 第1章「1-2-2. juliaup を利用したインストール2」や、各種情報を参照してください。
【2024/01/05 追記】
公式サイトの Download Julia ページのトップも juliaup によるインストール(コマンドラインからのインストール方法の紹介)になりました!
↓(Windows でサイトにアクセスした場合の表示)
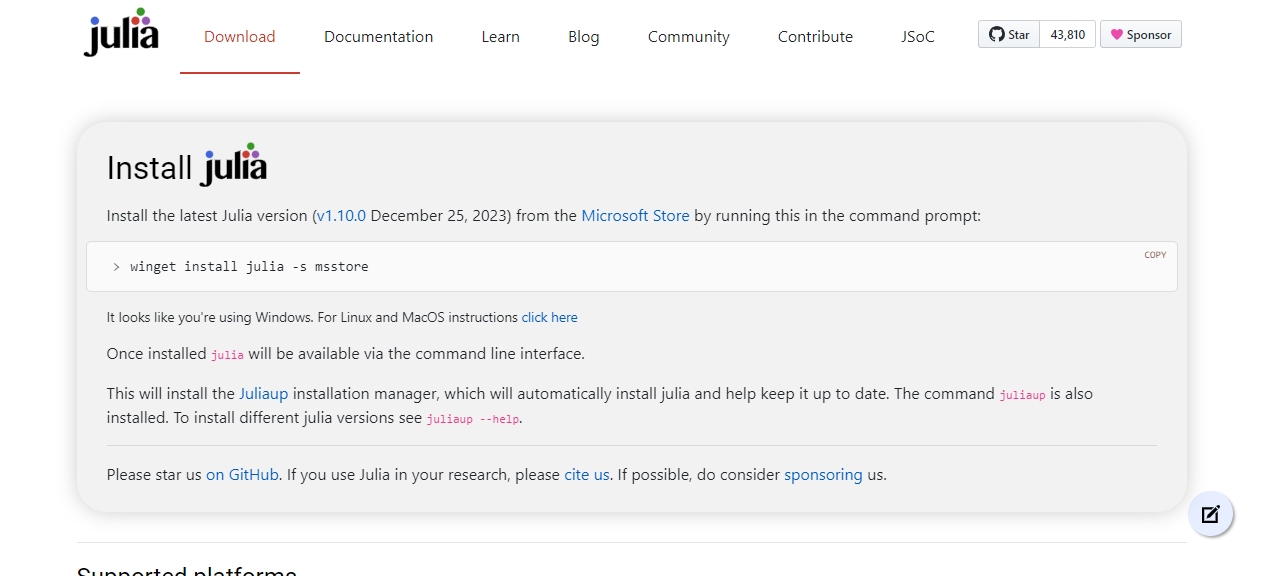
↓(Linux/macOS でサイトにアクセスした場合の表示)
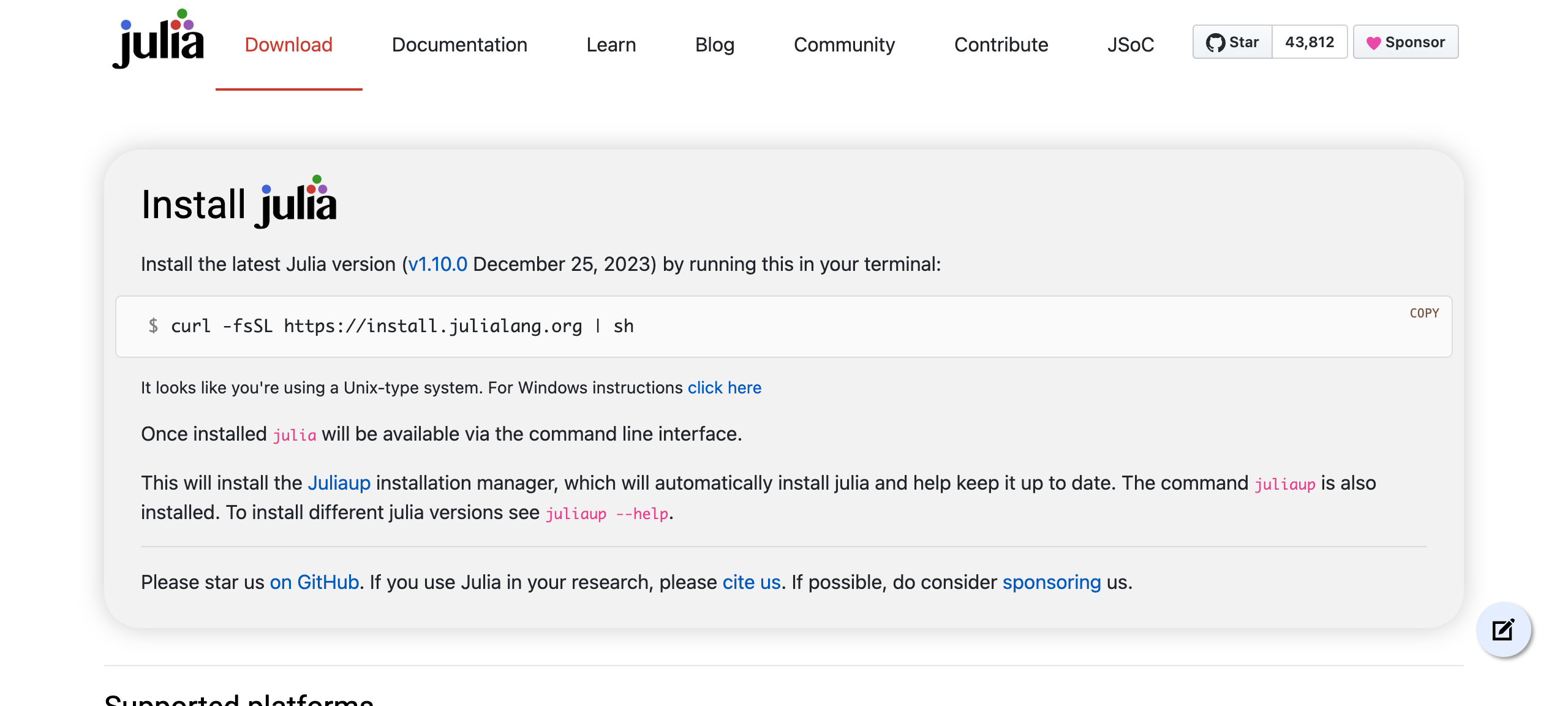
これで「初めて Julia に触れる方」にも juliaup 利用が推進されていきそうですね。
シチュエーション2: 文字列化
ユーザ定義型を定義したとき、その文字列表現をどう実装するか、というのはプログラミング言語あるあるですよね。その言語に合った方法が用意されていますが、よくある(クラスベースの)オブジェクト指向言語の場合 .toString() 的なメソッドのオーバーライドで対応することが多いです(Python なら __str__()、Ruby なら to_s とかですね)。
これに対応するのは、Julia では Base.show() 関数の多重定義(=メソッド追加) です。
struct Person
name::String
age::Int
weight::Float64
end
function Base.show(io::IO, person::Person)
print(io, person.name, '(', person.age, ')')
end
alice = Person("Alice", 14, 48.0);
println(alice) ## Alice(14)
alice_str = string(alice) #> "Alice(14)"
@show alice_str; ## alice_str = "Alice(14)"
Alice(14)
alice_str = "Alice(14)"
復唱します(これだけを覚えてください)。
『Julia で文字列化の定義は show() の多重定義(=メソッド追加)!』
他言語に引っ張られると、string(alice) で "Alice(14)" という文字列が返るようにうまく定義すべき? と思うかもしれません。
もしくは、標準出力への出力だけが目的なら println(alice) で Alice(14) と出力されるように定義すべき? と考えてしまうかもしれません。
Base.show() の多重定義(メソッド追加)は、その両方に対応しています!
Julia では「(出力機構に)どう出力するか」という仕組みの追加(=Base.show() へのメソッド追加)が先にあり、文字列化はその仕組みを利用している、というわけです(その方が内部的に効率の良いコードになるのです)。
(他言語だとまず「文字列化するにはこうする」という仕組みを追加(=toString() 系のメソッドのオーバーライド)をして、print() 系の出力関数(メソッド)がその結果を利用するのとは対称的です)
その仕組み上、2引数の Base.show(io, hoge) を(多重)定義する必要があることに注意が必要です。
ユーザ定義型の文字列化は、多重ディスパッチの一例として JJN でも紹介しています(第5章「5-2-3. 実例」、p302 あたり)が、『文字列化』というトピックで扱ってはいないので多少分かりにくかったかな、とは思います。
公式ドキュメントには「Custom pretty-printing(Manual - Types 内)」というトピックできちんと記述がありますので、詳細はそちらを参照してください3。
補足:『多重定義』とか『メソッド追加』という用語について
Julia はクラスベースの言語ではありません。他言語のように「まずクラスを定義してデータ構造と振る舞いをどうこうする」という流れではなく、「まず 関数(=機能) を考えて、そこにどんな値(=データ)を渡すかを考える」という設計思想の方がフィットします。
Julia は関数の『多重定義(Multiple Definition)』ができます。これは同名の関数を引数の違い(型シグニチャ と言います)によって複数定義する(型シグニチャが異なれば上書きではなく共存定義となる)という機能を指す言葉です。それを実行時に、引数の型に合わせて「どの型シグニチャに合致するか」で実装実体が選択されて実行される仕組みになっています(これを 多重ディスパッチ(Multiple Dispatch)と言います)。
またそのような仕様となっているため、Julia では「メソッド」というのはその(関数の型シグニチャに合致した)実装実体 のことを指す言葉になっています。
つまり Julia において「メソッドを追加する」というのは「(既存の)関数を(引数の違いで)多重定義する」ことによって得られます。
この記事でも随所で「多重定義」とか「メソッド追加」という言葉が出てきますが、以下のように覚えておいてください:
- Julia では関数を 多重定義 することによって メソッドを追加 できる
- Julia で メソッドを追加 すると言ったら、それは既存の関数を新しいシグニチャで 多重定義 することを指す
シチュエーション3: Int(floor(~)) ではなく floor(Int, ~)
他言語の常識に引っ張られすぎて、計算結果を小数点以下切り捨て(切り下げ)して整数にするコードを Int(floor(~)) と書く方、いませんか?
これもやっぱり Julia でもこう書いても動いてしまうのですが、もっと良い方法があります。floor(Int, ~) と書けばOK。ほんの少し効率の良いバイトコードにコンパイルされますし、何よりタイプ数が1~2ストローク短くて済みます。
以下、似たような「《何か処理をする関数名》(《処理後の型》, ~)」と書ける関数をいくつか紹介します。
floor(Int, 1.5) #> 1 # `Int` は他の整数型もOK(例:`UInt8`)(以下同様)
ceil(Int, 1.5) #> 2
trunc(Int, 1.5) #> 1
round(Int, 1.5) #> 2
ついでなので似たようなパターンとして、Julia で文字列を数値に変換したい場合、例えば Int("123") と書いたらエラーになります。parseInt(~) という関数も用意されていません。
その代わりこちらも同様に、parse() という1つの関数があり、第1引数に型を受け取ることにより「指定した型の値に parse する」という機能を提供しています。多重ディスパッチの恩恵ですね。
parse(Int, "123") #> 123 # `Int` は他の整数型もOK(例:`UInt8`)(以下同様)
parse(Float64, "3.14") #> 3.14
Julia で「~して整数を得る」系は大抵 ~(Int, …) と書けます(例:floor(Int, 3.14)、parse(Int, "123") など)。
第1引数の型も色々指定できるし便利です、ぜひ覚えておきましょう!
これらは JJN 第3章(「3-3-1. 文字列→数値変換」、「3-3-2. 数値の丸め処理」)などで解説しています。
シチュエーション4: 配列、そしてその要素の型
Python のサンプルコードがすでにあってそれを翻訳したのであろう、以下のような Julia のコードをブログ記事でよく見かけます。
arr = []
for v in some_iterator
push!(arr, v)
end
これはこれで動いてしまうのですが、Julia ではこの書き方には問題点がいくつかあります。
- Julia の
[]は(リストではなく)配列 なので、そこにただただpush!()で要素を追加していくコードは決してパフォーマンスが良くない。 -
[]とだけ書くと、その配列の要素の型はAnyとなり、どんな値でも格納できる反面メモリ効率等が良くない。
このようなコードに対して、Julia らしい書き方がいくつかあります。
1. 配列の要素の型を指定する
push!(arr, v) のようにして要素を追加する場合、追加する要素 v の型が常に同じ(例えば Float64)ならば、その要素の型を指定して配列を初期化した方が良いです。
arr = Float64[]
# または↓でもOK
# arr = Vector{Float64}()
for v in float64_iterator
push!(arr, v)
end
2. 要素数が(概数でも良いので)分かっていればそれをヒントに設定する
配列なのでリストと違い、要素を後ろに追加するときはリンクノードの追加のイメージではなく「領域を拡張して要素を格納」するイメージになります。
sizehint!() という関数を適用すると、その全要素数のヒントを与えることができ、無駄な領域拡張処理(に伴うパフォーマンス低下)を抑制することができます。
arr = Float64[]
# または↓でもOK
# arr = Vector{Float64}()
sizehint!(arr, N) # ← `N` は `certain_iterator` の要素数の目安となる整数値
for v in certain_iterator
push!(arr, v)
end
3. 単純なものなら内包表記使いましょう
Python のリスト内包表記と同様な仕様の 内包表記(Comprehension)4 が Julia にも用意されています。ある程度単純な「要素を加工・フィルターして配列を生成」するなら、内包表記の方が記述もコンパクトでしかも高パフォーマンスとなる場合も多いです。
arr = [v^2 for v in number_iterator if isodd(v)]
# ↑は以下↓と同等(結果的には)(でも↑の方が高パフォーマンス)
# arr = []
# for v in number_iterator
# if isodd(v)
# push!(arr, v^2)
# end
# end
# arr
こちらも要素の型が分かっている場合は arr = Float64[v^2 for v in number_iterator if isodd(v)] のように書くこともできます。
補足:内包表記で作られた配列の要素の型
上の例のような arr = [v^2 for v in number_iterator if isodd(v)] という書き方でも、各要素の型が安定(一定)している場合にはできる配列の要素の型は自然とその型になるようになっています。
つまり上では「結果的には同等」と書いた下のコードと実際には少し異なります。内包表記の方は(各算出値がすべて Float64 なら)typeof(arr) === Vector{Float64} になりますが、後者は Vector{Any} になってしまいます。
こういう便利さ・手軽さも内包表記のメリットの1つです。
Julia の内包表記は、記述もコンパクトでメリットも多いです。
対応する for 文を考えれば構造の理解もそんなに難しくないので、敬遠しないでどんどん使いましょう!
4. 要素数が確定していてパフォーマンスにこだわるなら
要素数が確定(N)している(要素型も確定(例: Float64))なら、「先に要素数 N の(Float64型の)配列を確保して、各インデックスに対応する値を代入する(push!() 使わない)」というのが最もパフォーマンスが良くなります。
arr = Vector{Float64}(undef, N) # 要素数 `N` の(要素未定義の)`Float64` の1次元配列を確保
for index in axes(arr, 1)
arr[indx] = certain_value(index)
end
補足:undef って何?
この「先に要素数 N の配列を確保」するやり方として、以下のようなコードもよく見かけます。
arr = zeros(Float64, N) # 要素数 `N` の `Float64` の1次元配列を確保(すると同時に全部 `0.0` で初期化)
for index in axes(arr, 1)
arr[indx] = certain_value(index)
end
これも間違いではありませんが、非常に効率悪いです。なぜなら、「一旦明示的にすべて 0.0 で初期化した配列を用意して、それに正しい値をすべて代入しなおす」という二度手間が発生しているからです。
Vector{Float64}(undef, N) というのは純粋に「要素数 N の配列(1次元配列)を確保」するだけです。(今回のように)すぐ後に別の方法で各要素を代入する場合にはこちらを使いましょう。
なお undef は「未定義」を意味するだけの定数であり、配列のコンストラクタに渡した場合は「要素を初期化しない」ということを指示するただのマーカーの役割をします(この定数値で初期化するというワケではありません)。
5. ブロードキャスティングを利用する
Julia には ブロードキャスティング(Broadcasting)という機能もあります。こちらも記述がコンパクトになるだけでなく、場合によっては内包表記に匹敵するくらい高パフォーマンスとなることもあります。
arr = sin.(1:N)
# ↑は↓と同等
# arr = [sin(x) for x in 1:n]
arr2 = randn(N) .* σ .+ μ
# ↑は↓と同等
# arr2 = [randn() * σ + μ for _ in 1:N]
Julia のブロードキャスティング(ベクタ化演算、および次元の自動拡張)も強力であり直感的に書けてしかも高フォーマンスが期待できます。
使いこなせると便利ですので色々書いて試してみてください!
その他(この節のまとめ)
ここに書いた内容は大体 JJN の第2章(「2-1-6. 配列リテラル」、「2-6-1. 内包表記」、「2-6-2. ドット構文」)および一部第7章(「ブロードキャスティング」)で紹介しています。
(逆に push!() はその関数の存在を第3章(「3-1-7. 配列・集合演算」)で触れているだけです)
ぜひこれらを参考に、効率の良い配列の初期化ライフをお過ごしください。
シチュエーション5: モジュール化、あるいはファイル分割
例えば Python では、ソースファイル1ファイルごとに モジュール化 される仕組みになっています。
処理をまとめて個別のファイルに分割すると、それぞれが別のモジュールになりますが、ディレクトリ構造をうまく工夫することで「サブモジュール化」し、他のファイルからはそれを import ~ で読み込めば利用できる仕組みになっています。
julia で似たようなことをしたい場合、どうすれば良いでしょう?
もし「モジュール化とかそういう複雑なことは置いといて、ただファイル分割したい」というだけなら、話は簡単です。
単純にファイル分割して、include(~) で読み込めばOKです。
例:↓
include("types.jl") # ユーザ定義型をまとめたソースコードファイル
include("utils.jl") # ユーティリティ関数をまとめたソースコードファイル
# : 《略、例えば他にも入出力関係(文字列化含む)を扱う `include("io.jl")` など》
struct Foo{T}
attr::T
end
# : 《略》
function certain_utility(x::Foo)
# 何かよしなに処理するコード
end
# : 《略》
Julia の本体や各種パッケージのソースコードを見ると、このようなファイル構造をよく見かけます。ファイル名で「ここには 型定義/ユーティリティ関数 をどこどこ詰め込む」という目的がはっきり分かりますし、コーディングする側からしても「どこを編集していけば良いか」が分かりやすいです。
「モジュール化」したい、と言う場合は、これの応用で module キーワード を活用する感じになります:
module YYY
export Foo, hoge
include("ZZZ.jl")
using .ZZZ: hoge
include("types.jl")
include("utils.jl")
end
module ZZZ
function hoge(x)
# 何かしらの機能
end
end
↑例えばこのような構造にすると、ZZZ は YYY のサブモジュールになります(YYY.ZZZ という感じで参照できます)。
このコード例の場合、hoge() という関数は ZZZ モジュールで定義されていますが、YYY モジュール内で using .ZZZ: hoge としているので YYY.hoge() のようにして参照・実行もできますし、さらに YYY モジュールで export Foo, hoge としているので、外部で using .YYY とするとモジュールプレフィックスなしで hoge() を呼び出すこともできます。
概要としてはこんな感じですが、動作原理は実はずっと単純です。
inclue("~.jl") という記述は、その場所に "~.jl" というソースコードの内容をそのまま埋め込むだけ、と考えてもらえばOKです。
Julia では、ソースコードをファイル分割して include("~.jl") で読み込む(ことで結合する)のが一般的、ということだけでも覚えて帰ってください!
モジュールの仕組みや基本的な概念・仕様ついては、JJN の第2章「2-8. モジュール」や公式ドキュメントを参考にしてください。
もう少し複雑なでも効果的な『モジュールプログラミング』については、半年前の JuliaTokai #15 で発表しているのでその時の発表資料(Julia でモジュールプログラミング(初歩の初歩))なども参考にしてください。
まとめに変えて
他にもいくつか、「Julia ではこっちの方が常識だよ(こっちを常識にしようよ)!」というものがあるかもしれません。思いついたらまた記事を書いたりこの記事に追記したりするかもしれません。
皆さまもコメントや「この記事へのリンクを張った別記事」等で情報提供・共有をお願いします!
参考リンク
- JJN(実践Julia入門)(拙著)
-
The Julia Programming Language(公式サイト)
- Julia Documentation(公式ドキュメント)
- Download Julia(公式ダウンロードサイト)
- juliaup: Julia installer and version multiplexer(juliaup Github サイト)
- JuliaTokai - connpass(私の主催(共催)している Julia の勉強会コミュニティページ)
-
次期リリース予定のβ版もしくはRC版が未公開の場合は、 release チャンネル(最新安定版)がインストールされます。 ↩
-
拙著では『(Linux/macOS 版 juliaup は)執筆時点ではまだプレリリース版(Prerelease Version)とされている』と記載していますが、出版時点で正式版になっています
 ↩
↩ -
JuliaCon 2020 の発表(Youtube: JuliaCon 2020 | Display, show and print -- how Julia's display system works | Fredrik Ekre)も大変参考になると思います。 ↩
-
Julia では単に「内包表記」と言います。「リスト内包表記」とは言いません。理由は「1. 生成されるのはリストではなく配列だから」「2. 1次元配列だけでなく2次元や多次元の配列も生成できるから」等です。 ↩