1/16 に GA (General Availability: 一般提供) になった Azure OpenAI Service は、Azure 上で OpenAI が稼働するサービスです。Cognitive Services の一員として & Web API として利用できる、Studio と呼ばれる GUI が用意されており、テストや調整などが可能です。
今回は、Azure OpenAI Studio から操作できない Embedding 機能 (ご自身のデータを投入して、自然言語でセマンティック検索が可能な機能) を試してみます。まずは、Jupyter Notebook から Python ライブラリーを使って利用してみます。
3/10 現在、GA したとはいえ、Azure OpenAI Service を利用するには Web から利用申請が必要です。
Azure OpenAI Service の申し込み方法は 祝 Azure OpenAI Service GA! ① の記事をご覧ください。
Azure OpenAI Service 自体は GA ですが、3/10~ 利用可能になった ChatGPT, 3/22~ 利用可能になった GTP-4 は現在プレビュー中です。
準備
- Azure OpenAI Service の作成
- GPT-3 & ChatGPT を Azure OpenAI Studio からお試し と同様の手順で、Azure OpenAI Service 利用可能になった Azure サブスクリプションで、Azure OpenAI Studio サービスを作成します。この時、場所は South Central US (米国中南部) を選択してください。(3/23 現在、今回必要なモデルが East US には用意されていません)
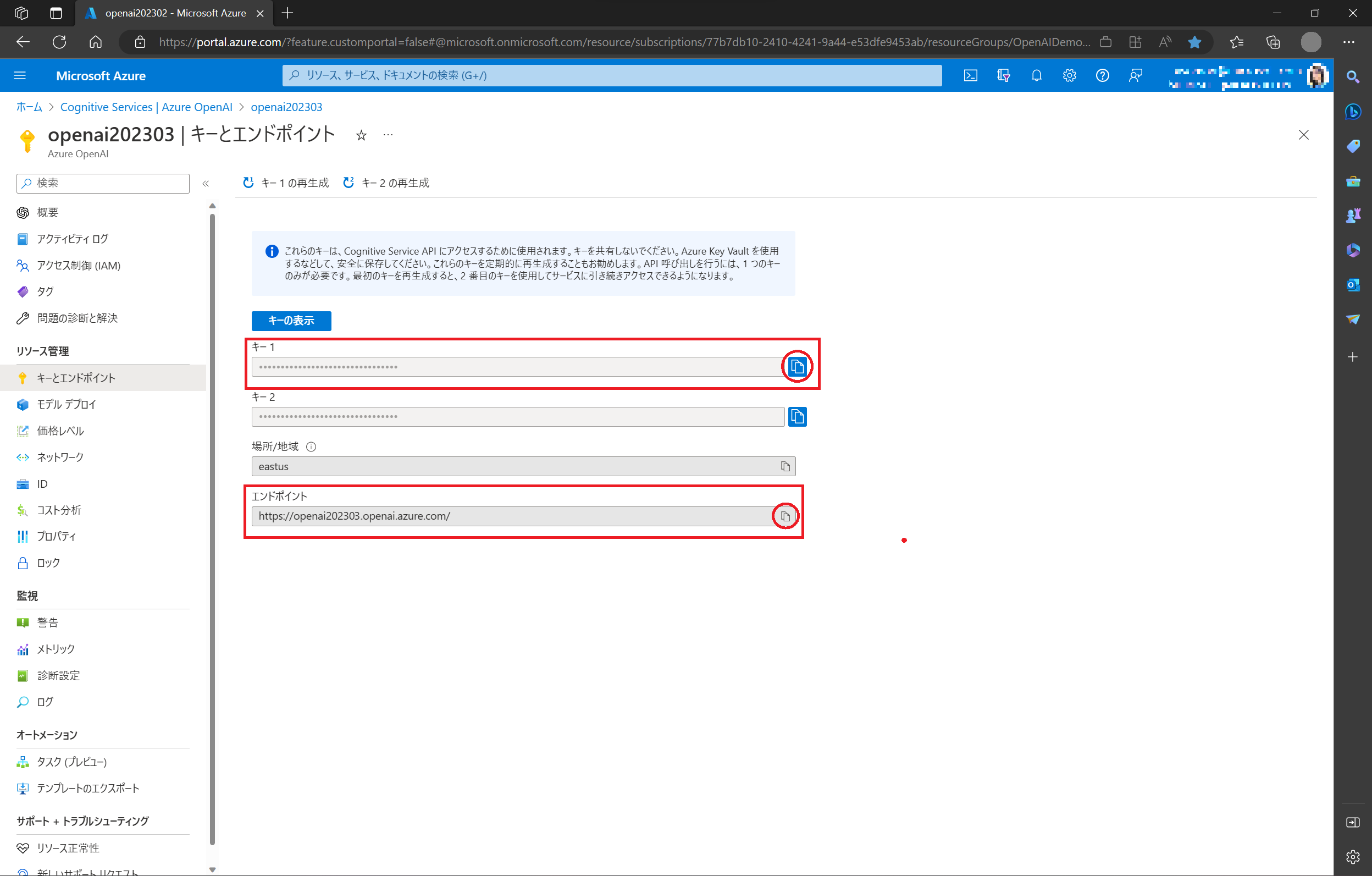
- キー1 と エンドポイント が利用するのに必要になりますので、ローカルに保存しておきます。(右端のコピーボタンをクリックすると、内容がコピーできます。)
-
Embededding して検索したいデータ
- id, text, ... といった形式のデータを CSV で準備しておきます。今回は "bing検索" で Tweet 検索したデータを利用しました (100件)
-
[4/11 ハンズオン開催期間限定]
- 利用したサンプルデータ をダウンロード可能です (4/15(金)0:00 まで)。
-
開発環境
- 今回はローカル環境ではなく、Azure Machine Learning の Azure Machine Learning Studio にある Jupyter Notebook を使いました。クイックスタート: Azure Machine Learning の利用を開始するために必要なワークスペース リソースを作成する の手順で、ワークスペースとコンピューティングインスタンス(VM)を作成します。
- クイック スタート: スタジオで Jupyter ノートブックを実行する を参照して、新しいフォルダーと Jupyter ノートブックを作成し、検索したい CSV データを同じフォルダーにアップロードしておきます。カーネルは Azure Machine Learning Studio で用意されている環境である Python3.8 - AzureML を使います。
手順
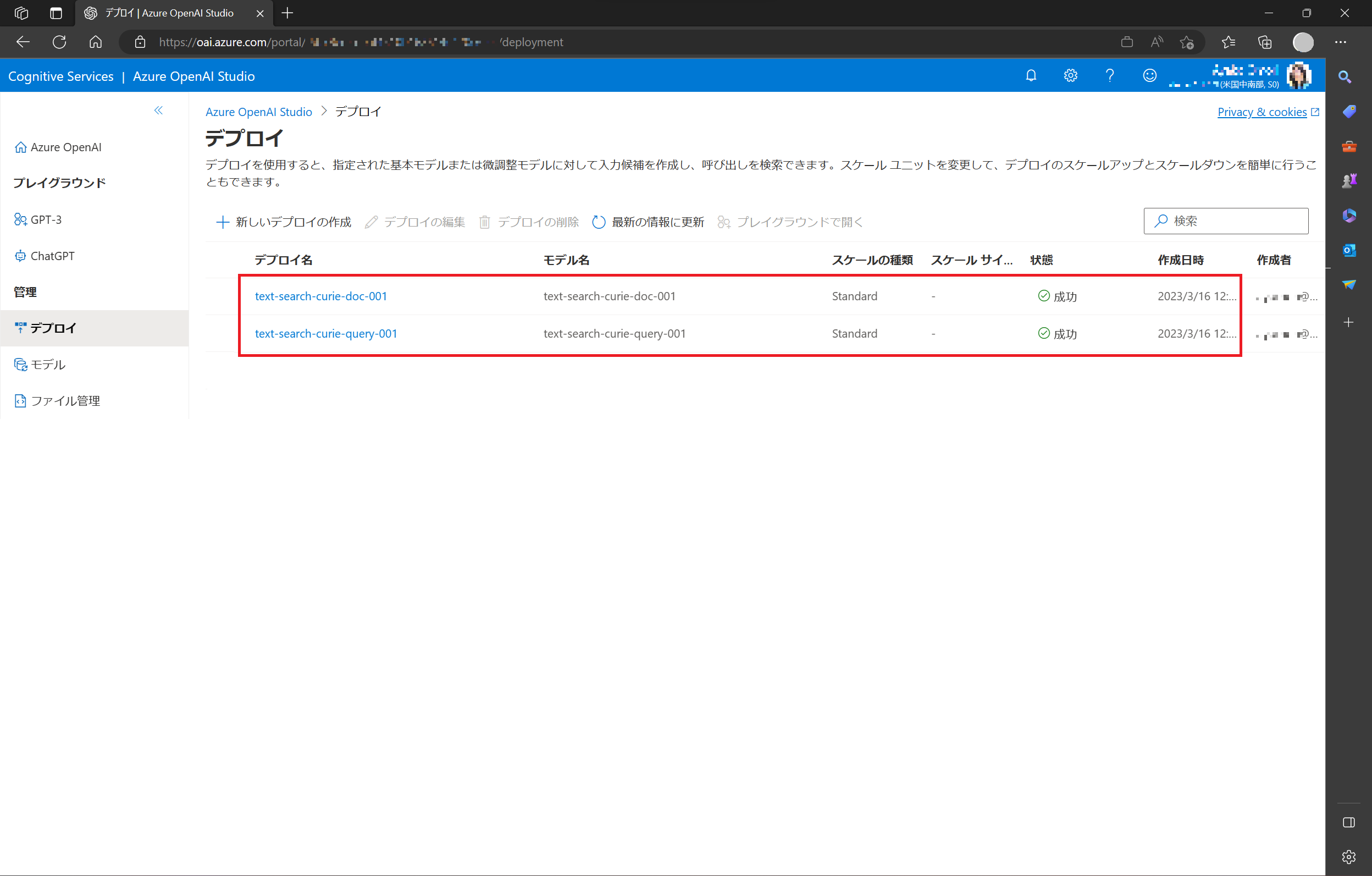
1. Azure OpenML Studio から Text Search Curie モデルのデプロイ
Azure OpenAI Studio を開き、Azure OpenAI Service を作成した (or 利用するためのロールを持っている) アカウントでサインインします。
今回は Text Search Curie (text-search-curie-doc-001, text-search-curie-query-001) モデルを利用するので、モデルをデプロイしてから試用を行います。GPT-3 & ChatGPT を Azure OpenAI Studio からお試し と同様の手順で、text-search-curie-doc-001 と text-search-curie-query-001、2つのモデルを作成します。
現在、ひとつのモデルにつき、ひとつしかデプロイできません。
2. Azure Machine Learning Studio の Jupyter Notebook を使って、Python ライブラリーから Embededing 機能の実装とセマンティック検索をお試し
ライブラリーのインポート
今回利用する openai のライブラリー他、作業に必要なライブラリーをインポートします。
import openai
import re
import requests
import sys
from num2words import num2words
import os
import pandas as pd
import numpy as np
from openai.embeddings_utils import get_embedding, cosine_similarity
from transformers import GPT2TokenizerFast
Azure OpenAI Service の情報セット&接続確認
本来なら環境変数として設定すべきですが、お試しなので直接、ローカルに保存しておいた Azure OpenAI Service のキー と エンドポイントをコード内で設定します。
API_KEY = "YOUR_API_KEY"
RESOURCE_ENDPOINT = "https://YOUR_OPENAI_SERVICE.openai.azure.com/"
openai.api_type = "azure"
openai.api_key = API_KEY
openai.api_base = RESOURCE_ENDPOINT
openai.api_version = "2022-12-01"
url = openai.api_base + "/openai/deployments?api-version=2022-12-01"
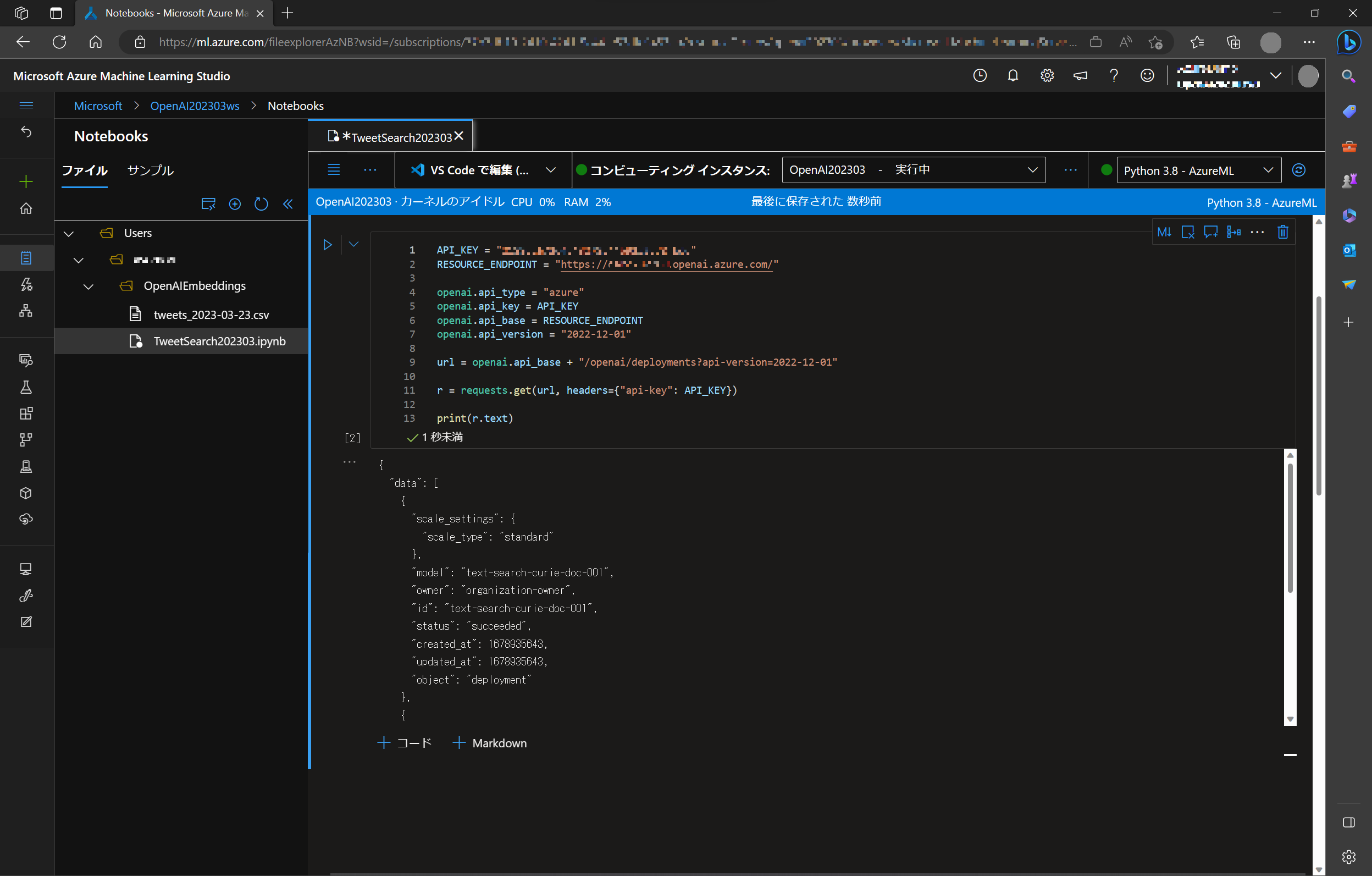
r = requests.get(url, headers={"api-key": API_KEY})
print(r.text)
print(r) で、以下のような Azure OpenAI Service のデプロイ情報などが取得できます (ので接続が確認できます。)
データの読み込みと前処理
用意した CSV ファイルを読み込みます。
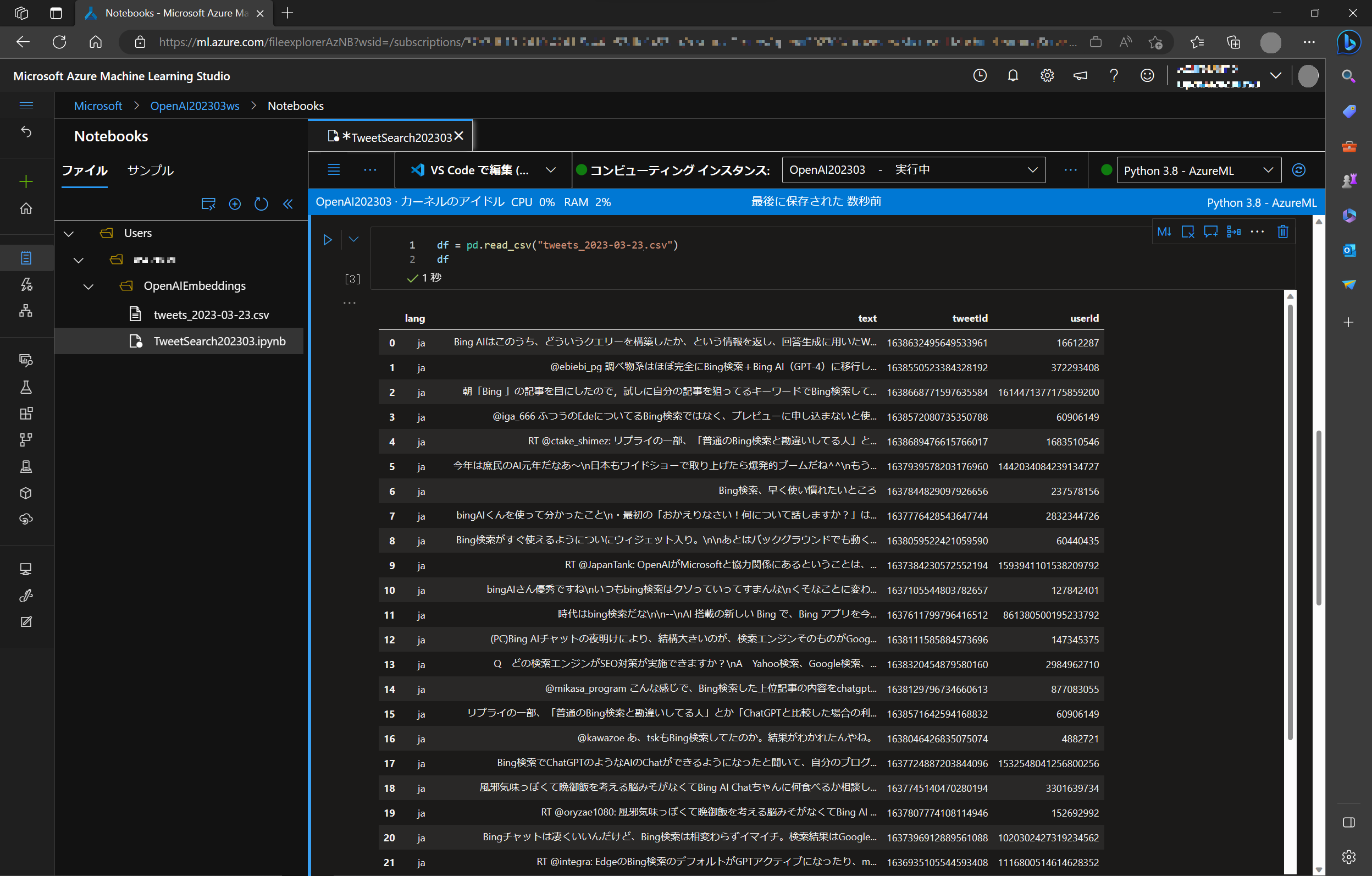
df = pd.read_csv("tweets_2023-03-23.csv")
df
今回は、tweetId, userId, text, lang という列を持つ (Tweet を取得した) CSV データであることが確認できます。
ここで、データから改行 (\n) や不要な文字などを削除する整形を行います。
# s is input text
def normalize_text(s, sep_token = " \n "):
s = re.sub(r'\s+', ' ', s).strip()
s = re.sub(r". ,","",s)
# remove all instances of multiple spaces
s = s.replace("..",".")
s = s.replace(". .",".")
s = s.replace("\n", "")
s = s.strip()
return s
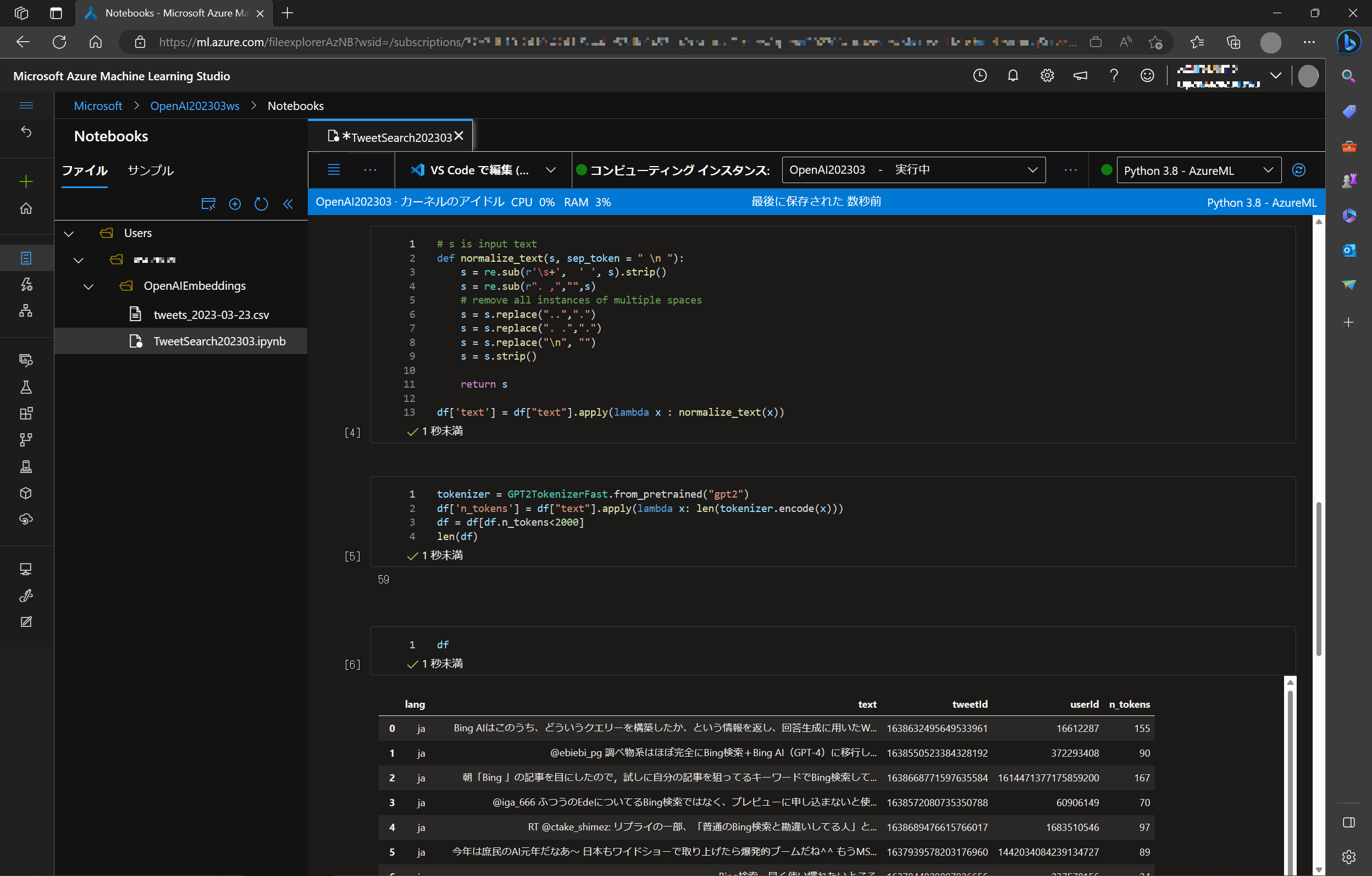
df['text'] = df["text"].apply(lambda x : normalize_text(x))
Tokenizer によるトークン化とトークン数の算出
Tokenizer を使ってトークン化と、トークン数の計算を行い、text のトークン(数)を n_token 列に追加します。
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
df['n_tokens'] = df["text"].apply(lambda x: len(tokenizer.encode(x)))
df = df[df.n_tokens<2000]
len(df)
n_tokens<2000 としているのは、一度に利用できるトークンの上限が 2000 だからです。
トークンが2000 以下のデータは 59件、調べてみるとデータに n_token 列が追加されたのが分かります。
text-curie-search-doc を使った埋め込み (Embedding)
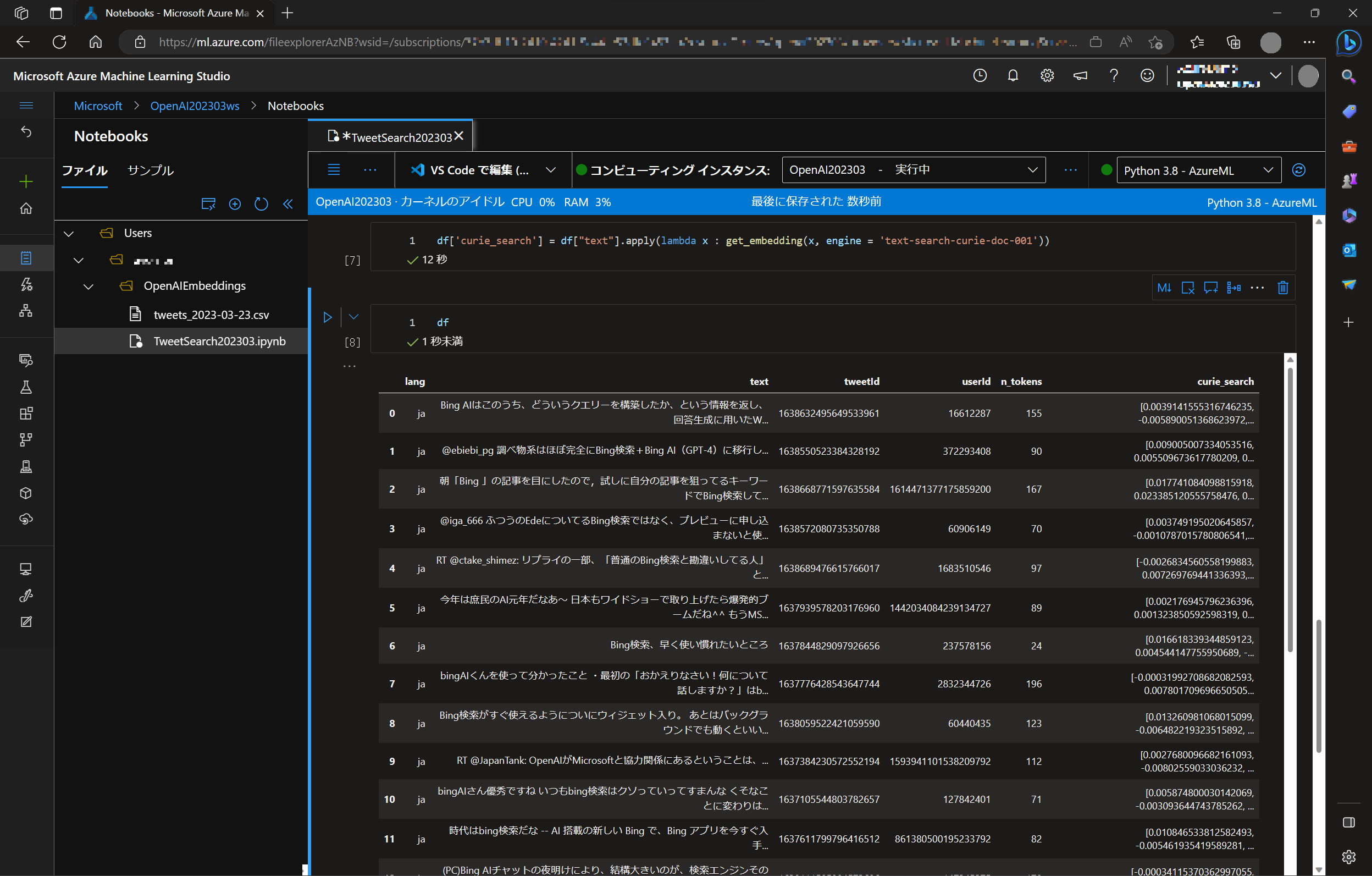
整形したデータを curie-search モデルに埋め込みます。これには text-curie-search-doc モデルを利用します。
df['curie_search'] = df["text"].apply(lambda x : get_embedding(x, engine = 'text-search-curie-doc-001'))
埋め込んだ検索データのベクトルが curie_search 列として追加されました。
text-curie-search-query を使ったセマンティック検索
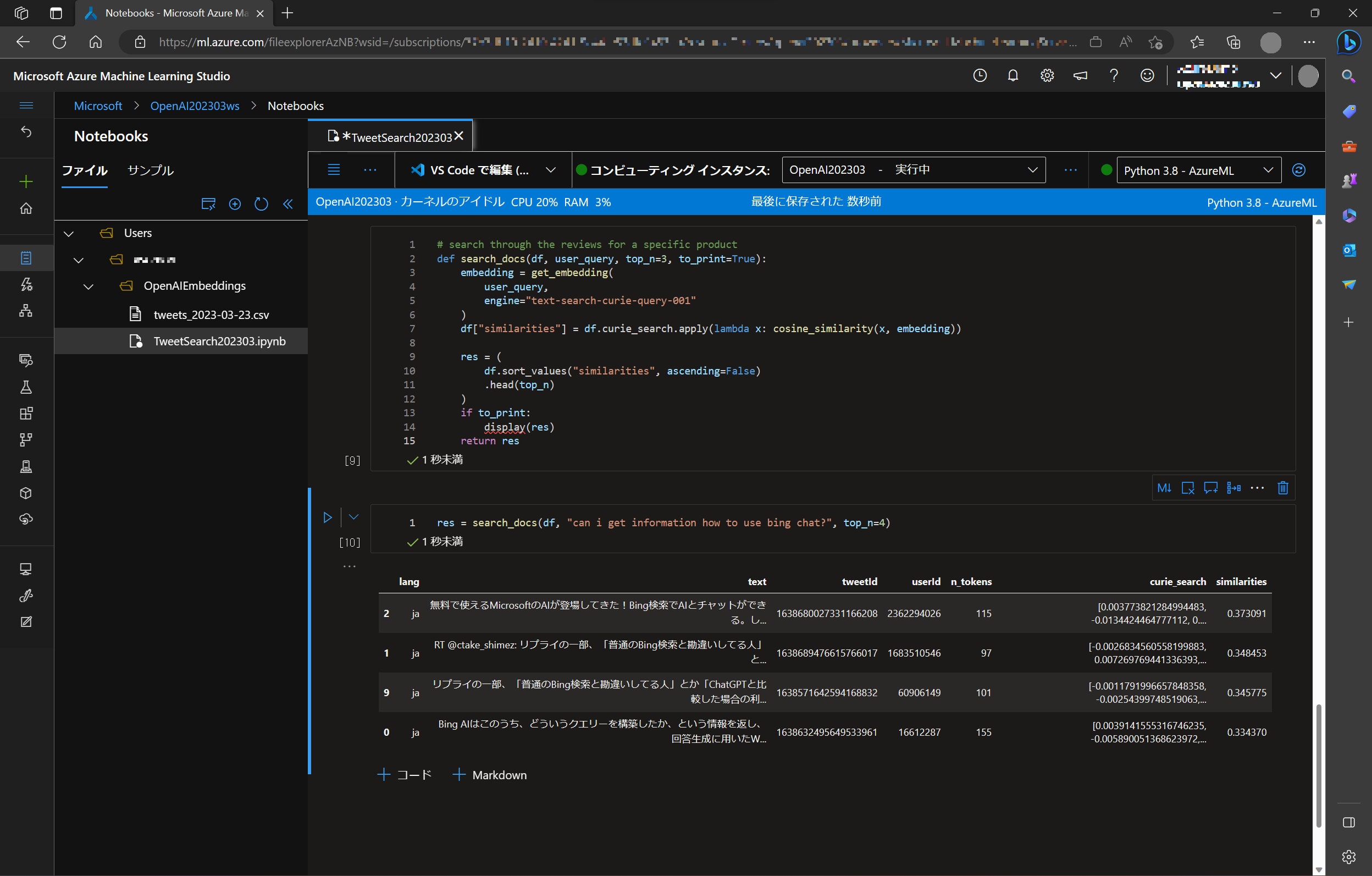
それでは、実際にこの Embedded Search の検索を行ってみます。text-curie-search-query モデルを利用して、search_docs という関数を作っておきます。コサイン類似度(cosine_similarity) で優先度をつけて、関連度の高い文章を検索します。
# search through the reviews for a specific product
def search_docs(df, user_query, top_n=3, to_print=True):
embedding = get_embedding(
user_query,
engine="text-search-curie-query-001"
)
df["similarities"] = df.curie_search.apply(lambda x: cosine_similarity(x, embedding))
res = (
df.sort_values("similarities", ascending=False)
.head(top_n)
)
if to_print:
display(res)
return res
コサイン類似度を利用した検索については Azure OpenAI Service の埋め込みについて に解説されています。
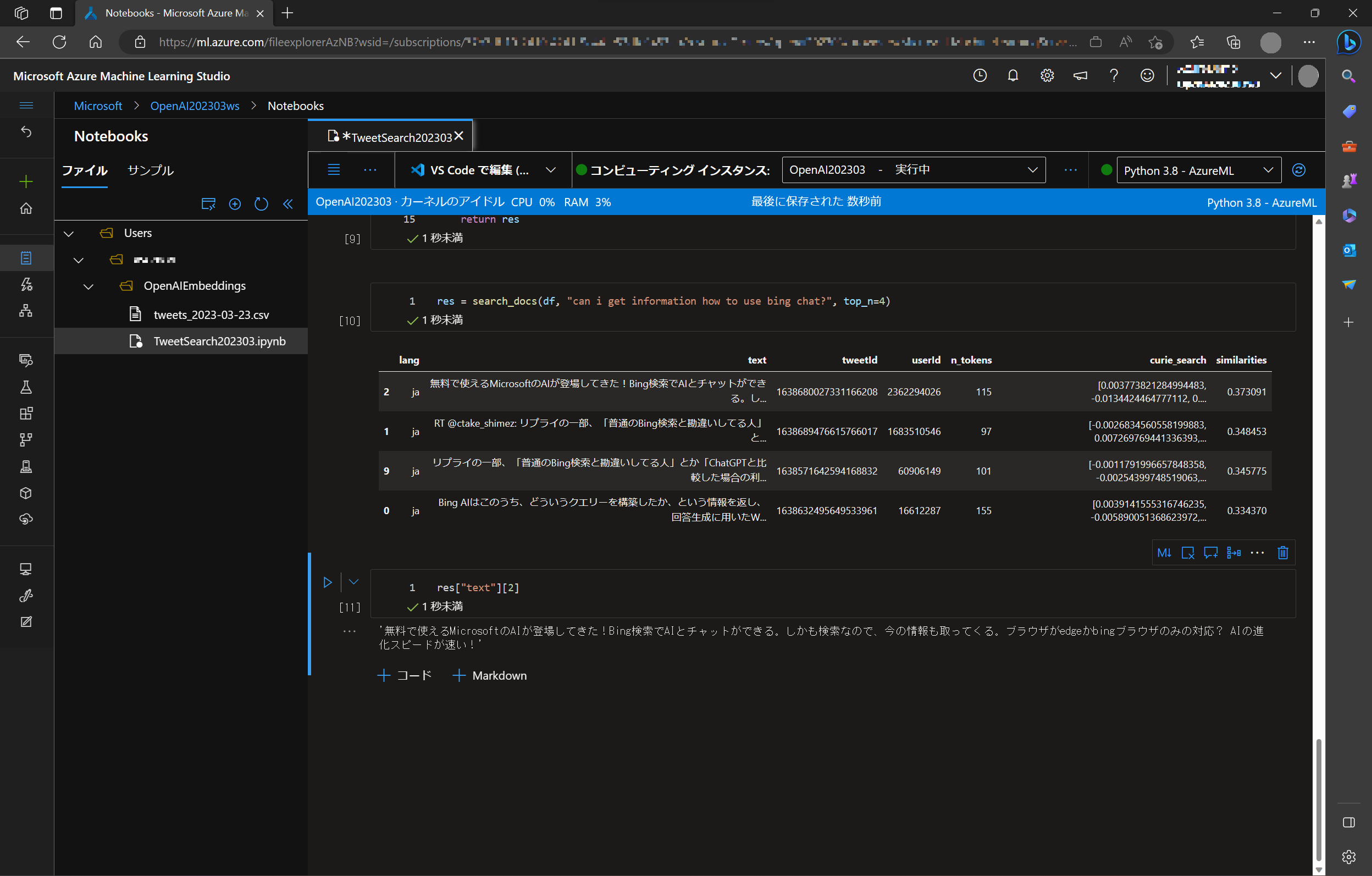
検索は自然言語で行います。search_docs に "can I get information how to use bing chat?" (Bing Chatの使い方について教えて?)、上位 4 件取得するようにセットします。
res = search_docs(df, "can I get information how to use bing chat", top_n=4)
すると、関連度の高いデータ行が表示されます。(similarities 列に関連度が示されます)
text 列が省略されているので、確認します。
res["text"][2]
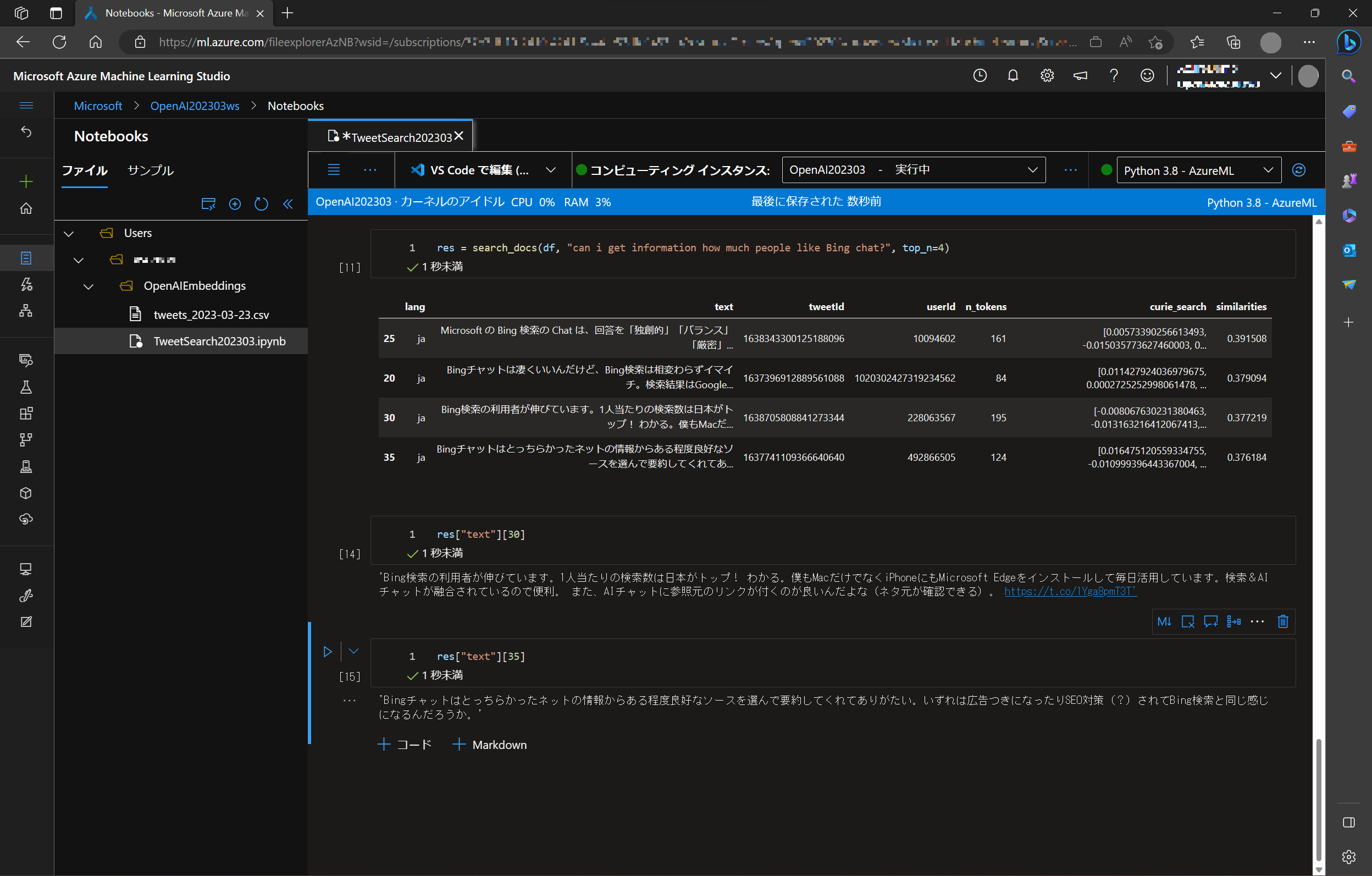
今度は質問を変えて、"can i get information how much people like Bing chat?" (どれくらい皆さんはBing Chat を気に入っているのかしら)、同じく上位 4 件を取得するようにセットします。
res = search_docs(df, "can i get information how much people like Bing chat?", top_n=4)
すると、違うデータが表示されるので、それぞれ Text 全文を確認します。
参考: ご自分の Jupyter Notebook 環境で試すとき
詳しい手順などは チュートリアル: Azure OpenAI Service の埋め込みとドキュメント検索を確認する に記載されています。ローカル環境など、ご自分の環境で試される場合はこちらをご確認ください。