単なる OCR ではなくドキュメントに含まれるフォーム(表)データを取得できる Cognitive Services の Form Recognizer。請求書や発注書のようなドキュメントやレシートなど、PDF や 画像(JPG, PNG, TIFF) からデータを読み取ることが出来る Web API です。
また、Azure Logic Apps を使うと、トリガー(ドキュメントのアップロード、メール送付や Web API Callなど)で起動するワークフロー処理を GUI で作成できます。
今回は、定型フォーマットで作成されたお客様からの発注書(PDF)を読み取って、DB に自動取り込みするまでを Cognitive Services Form Recognizer と Azure Logic Apps で作ってみます。
手順
-
- 準備
-
- Form Recognizer でカスタムモデルの作成
-
- Azure Logic Apps 編 (後日公開)
0. 準備
Azure サブスクリプション
Azure Logic App の利用に必要です。
また、Form Recognizer の利用申し込み時に有効な Azure サブスクリプション ID を申請する必要があります。
利用準備: Microsoft Azure & Cognitive Services 利用準備
Azure サブスクリプションが利用できるようになったら、今回作成するサービスをまとめておくためのリソースグループを作成しておきます。
Azure Portal から [+新規作成] 、または [リソースグループ] > [+作成] をクリックします。

分かりやすい名前をつけます。ロケーションは日本なら東日本または西日本から選択して [確認および作成] をクリックします。
[作成] をクリックするとリソースグループが作成されます。
Form Recognizer のサービス作成
現在プライベートプレビューのため、Form Recognizer プレビュー利用申し込み のサイトから申請します。
メールで Form Recognizer プレビュー参加OKの連絡が来ますので、メール本文に書かれた URL から Form Recoginzer のサービスを作成します。
- 場所: 日本から近いのは東アジアになります。
- 料金プラン: F0(無料) と S0(有料) がありますので、まずは F0 で作成しておけばよいでしょう。
Form Recognizer のサービスが作成できたら、場所 と API Key をコピーしてローカルに保存しておきます。
発注書データ
Form Recognizer は 2019 年 12 月現在 ラテン文字(英数字) のみ対応なので、英語の発注書(PDF) データを利用します。
後述しますが、カスタムモデルを作成するための学習データと実際に分析を行うためのデータを準備します。
手順
1. Form Recognizer でカスタムモデルの作成
Form Recognizer には Prebuilt (マイクロソフトが作成したモデルを使うもの、利用者の準備不要) と Custom (学習データを読み込ませて独自モデルを作成) という 2 つのモードがあります。今回は Custom を使います。
1-1. Azure Blob Storage に学習データをアップロード
Custom モデルの学習用データは Azure Blob Storage にアップロードしておきます。
Azure Portal から Azure Storage (ストレージアカウント) を作成します。
新規作成 から 'Azure Storage' で検索、または表示一覧から Azure ストレージ を選択します。
作成をクリックして、Azure Storage の作成に進みます。
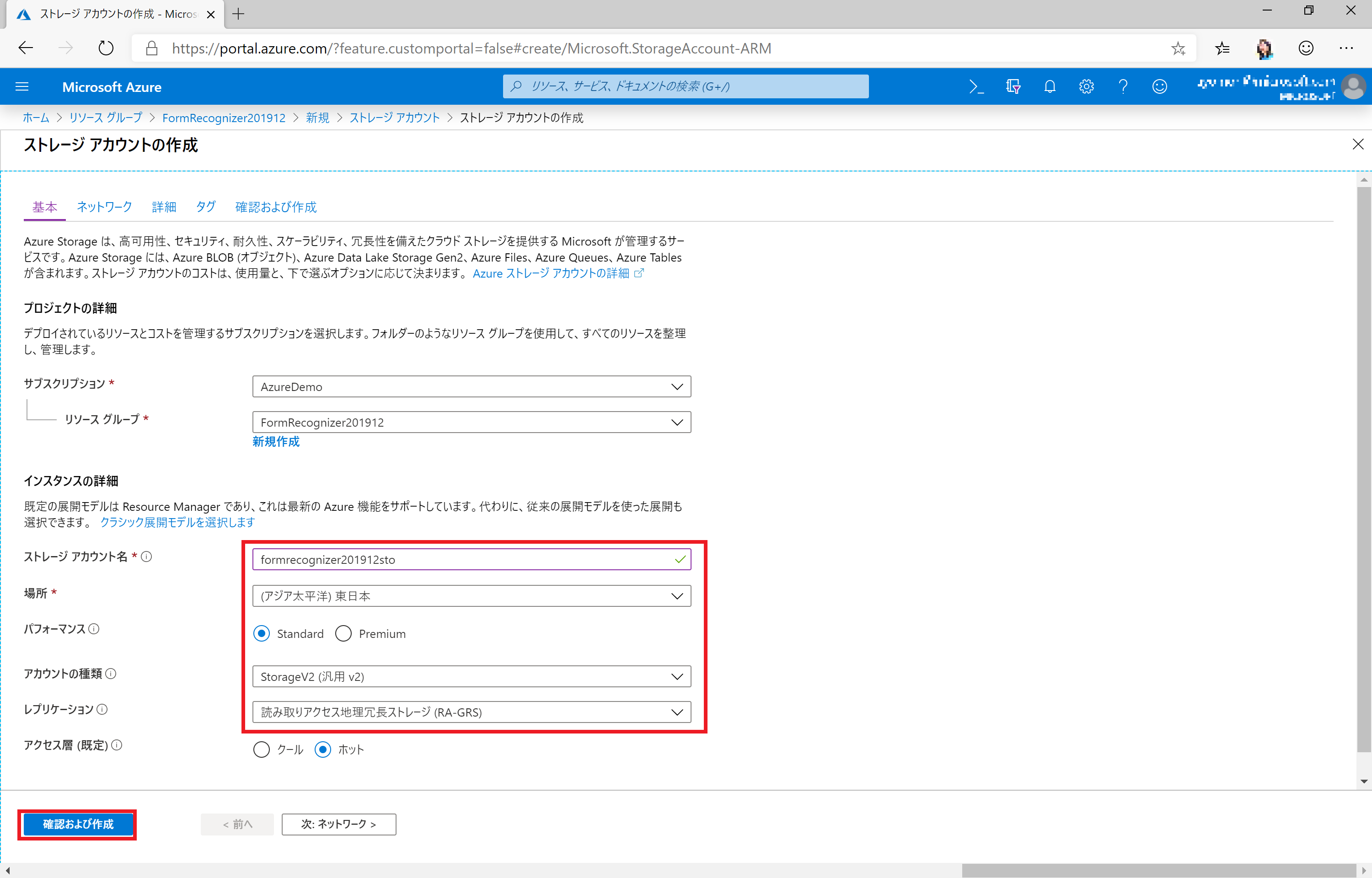
必要事項を入力します。
- 場所: リソースグループと揃えます(東日本 or 西日本)
- パフォーマンス: Standard
- ストレージの種類: Storage V2
- レプリケーション: RA-GRS
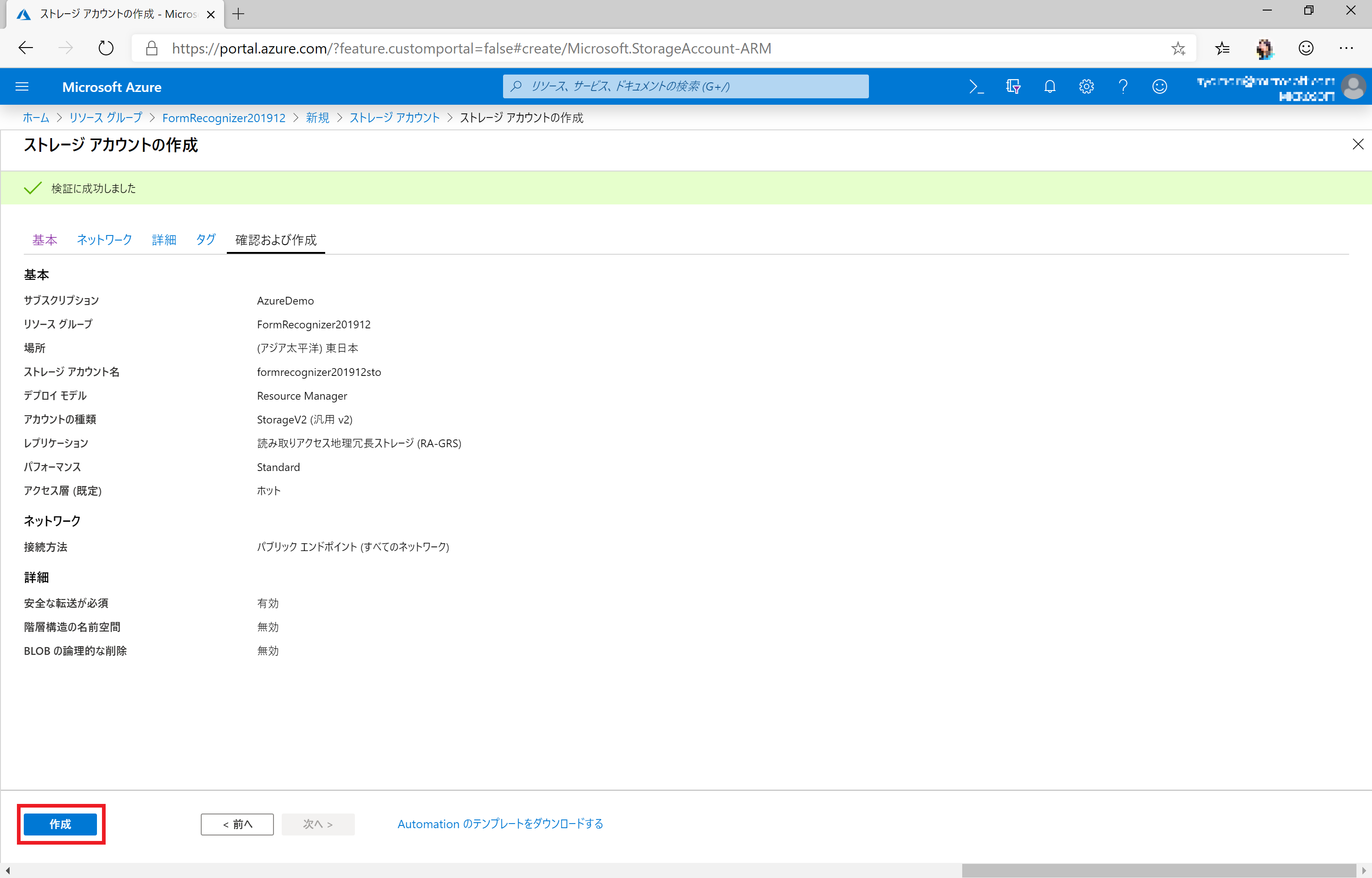
[確認および作成] をクリックして作成に進みます。
[作成] をクリックすると、Azure Storage が作成されます
作成できたら、Azure Storage のブレードで [コンテナー] をクリックして、新規 Blob ストレージを作成します。
[+コンテナーの追加] をクリックして、Blob Storage を追加します。ここでは train という名前にしておきます。

train コンテナーを表示し、[アップロード] をクリックします。
アップロード のブレードで学習データ(PDF)を選択、[アップロード] をクリックします。
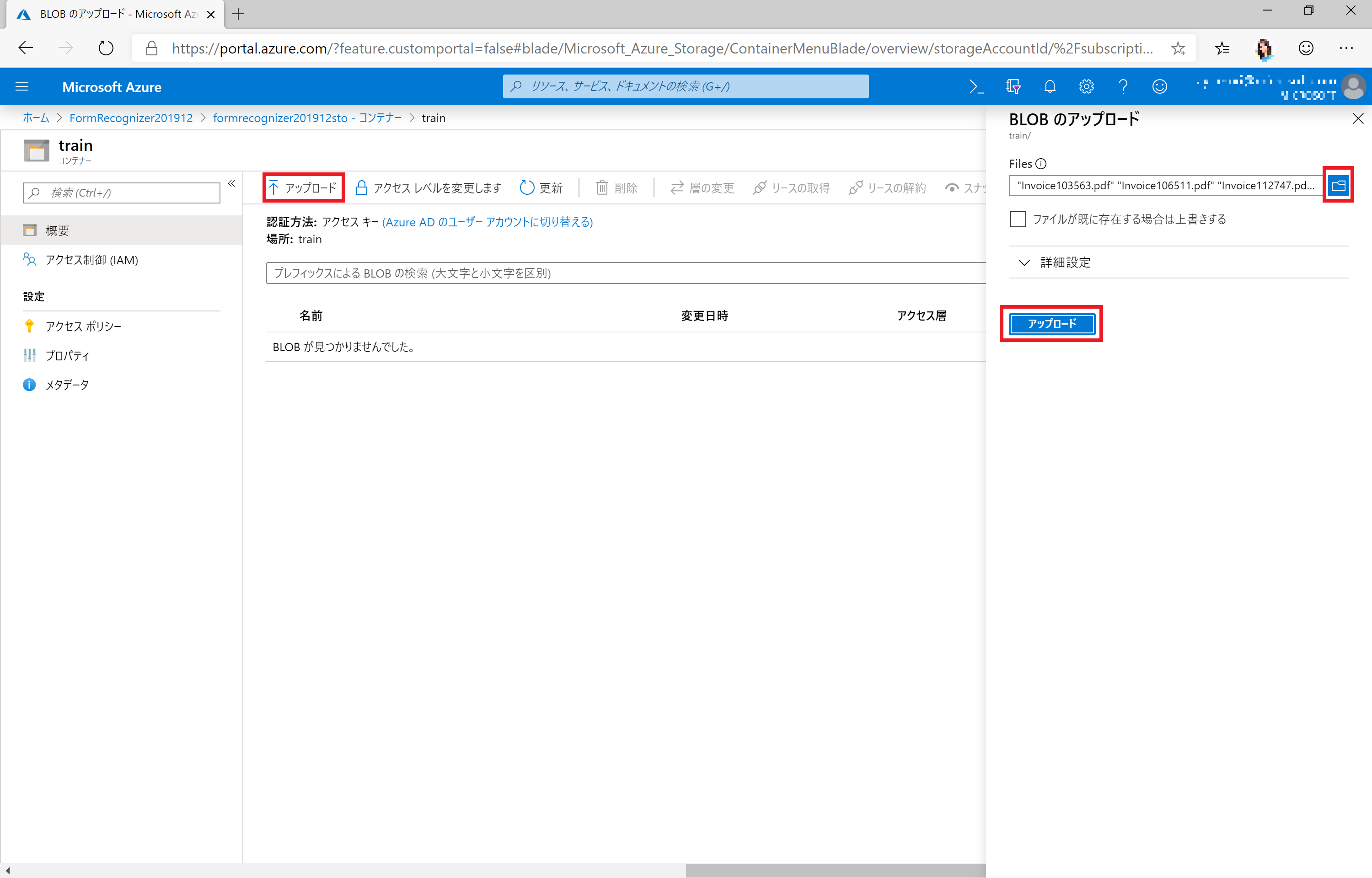
学習データ(PDF)が表示されたら、アップロードは完了です。

1-2. Form Recognizer の Web API からカスタムモデルの作成
Postman など Rest API ツールを用いて、学習データ(を保存した Blob Storage URL) を送信し、カスタムモデルを生成します。
- YOUR_RECOGNIZER_ENDPOINT: Form Recognizer を作成したロケーションが東アジアの場合は、eastasia.api.cognitive.microsoft.com になります。
- YOUR_RECOGNIZER_KEY: ローカルに保存しておいた Form Recognizer の API Key
- YOUR_STORAGE: 学習データを保存した Azure Storage の名前
POST https://YOUR_RECOGNIZER_ENDPOINT/formrecognizer/v1.0-preview/custom/train
Ocp-Apim-Subscription-Key: YOUR_RECOGNIER_KEY
Content-Type: application/json
{
"source": "https://YOUR_STORAGE.blob.core.windows.net/train",
"sourceFilter": {
"includeSubFolders": false
}
}
以下のようなレスポンスが戻り、modelId が取得できます。この Model Id をつかって、カスタムモデルを使ったフォーム読み取りを行いますので、コピーしてローカルに保存しておきます。
{
"modelId": "d6c0380b-8ff0-455f-999e-36df8952e723",
"trainingDocuments": [
{
"documentName": "Invoice103563.pdf",
"pages": 1,
"errors": [],
"status": "success"
},
:
1-3. カスタムモデルのテスト
生成されたモデルをつかって、PDFのフォームを読み取りできるか確認してみます。
以下のようなフォーマットで Body に分析したい PDF を追加してリクエストを送信します。
- YOUR_RECOGNIZER_ENDPOINT: ローカルに保存しておいた Form Recognizer のエンドポイント
- YOUR_RECOGNIZER_KEY: ローカルに保存しておいた Form Recognizer の API Key
- YOUR_MODEL_ID: ローカルに保存しておいた Form Recognizer で生成した Model ID
POST https://YOUR_RECOGNIZER_ENDPOINT/formrecognizer/v1.0-preview/custom/models/YOUR_MODEL_ID/analyze
Ocp-Apim-Subscription-Key: YOUR_RECOGNIER_KEY
Content-Type: application/pdf
(PDFをバイナリーで送付)
以下のようなレスポンスが戻り、Key と Value のセットでフォームのデータ(と表示されている位置など)が取得できます。
{
"status": "success",
"pages": [
{
"number": 1,
"height": 792,
"width": 612,
"clusterId": 0,
"keyValuePairs": [
{
"key": [
{
"text": "Name",
"boundingBox": [
80.6,
:
]
}
],
"value": [
{
"text": "Kaylee Carter",
"boundingBox": [
80.6,
:
],
"confidence": 0.34
}
]
},
: