論文
読んだ理由
- NeurIPS 2025 に参加した際に気になった
- MASを個人的にも試したことがあるが、複数のAI同士のやり取りのせいでハルシネーションが増えたり、思ったような動きをしなかったりしたので、それらが自分だけの現象なのか確認しておきたかったから
- MASの課題点として何があるのかを知っておきたいから
概要
- MAST-Dataと呼ばれるマルチエージェントシステム (MAS) の失敗データセットを作成
- 7つの代表どころのMASフレームワーク (例:ChatDev, MetaGPT, OpenManus) から収集された1642の注釈付きトレースを含むデータセット。
- 将来的にMASの失敗に関する研究をするための包括的なデータセット。
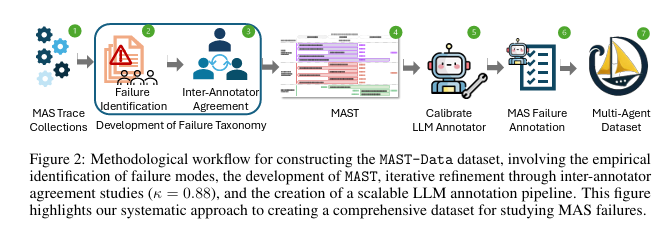
- データセット作成のために以下の手順を実施。 - 5つのMASフレームワークから150のトレースを実施。6人の専門家が詳細に検査する。 - 仮説を立てずにデータから失敗パターンを見出す Grounded Theory (GT) アプローチを実施。 - トレースデータで観察された失敗行動のラベル付けなどトレースを反復的に分析し、新たな洞察が得られないあたりまで続ける。 - 分析結果からMASTと呼ばれる分類法を作成。3人のアノテーターによる議論で分類法の改善を実施。 - MASTや人間の注釈をつけたデータをfew-shot的に提示し、o1モデルで観察された失敗内容を分類させるLLMアノテーターを作成。 - 初期のMAST開発に含まれなかった2つのMASと2つのベンチマークを使って評価し、MASTとLLMアノテーターの有効性を確認し、最後に7つのMASと1642の注釈付きトレースからMAST-Dataを作成。
マルチエージェントシステムの失敗の分類
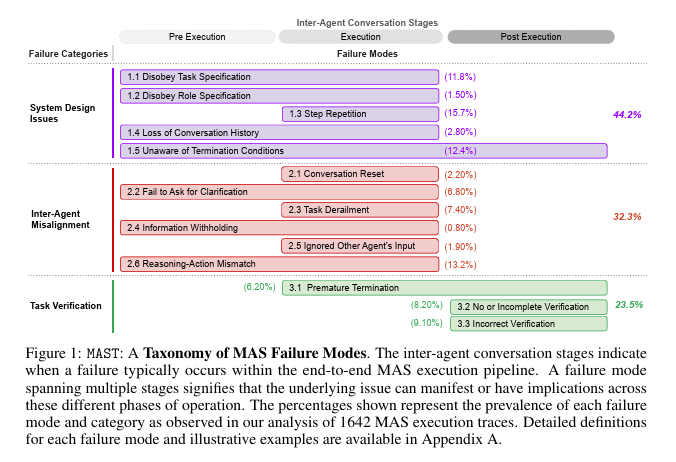
主に3つの分類がされる。
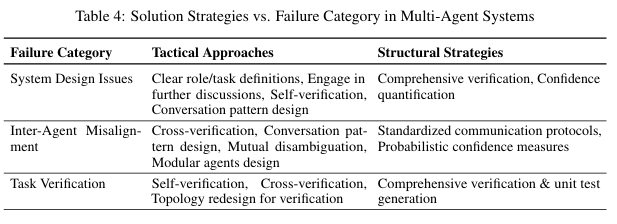
- システムデザインの問題
- エージェント間の連携の失敗
- タスク検証 (の失敗)
1. システムデザインの問題
- タスク要件 (11.8%) やエージェントの役割 (1.5%) に従わない
- ステップの繰り返し (15.7%)
- コンテキストの喪失 (2.80%)
特にタスク要件やエージェントの役割に従わない原因として以下の3つの原因がある。
- エージェントの役割とワークフローに関するMAS設計の欠陥
- ユーザーのプロンプト仕様の不備
- 基盤となるLLMの制限
本研究ではエージェント役割仕様を改善するだけで、同じプロンプトとLLMを使った場合でもChatDevの成功率が+9.4% 増加することが示されている。
2. エージェント間の連携の失敗
- 予期しない会話のリセット (2.2%)
- 誤った仮定に基づいて進行する (6.8%)
- タスクの脱線 (7.4%)
- 重要な情報の秘匿 (0.85%)
- 他のエージェントからの意見を無視すること (1.9%)
- 推論と行動の間の不一致 (13.2%)
これらのエラーは同じフレームワーク内のエージェントが自然言語を使ってやり取りした場合でも起こり得る。
つまり、エージェントが他のエージェントのニーズを正確にモデル化出来ていないことを示している。
これらの解決方法として、エージェントメッセージの内容に構造的な改善を加えることや、モデルの文脈推論や他エージェントのニーズを推測するモデルの能力の強化が求められる。
3. タスク検証 (の失敗)
- 早期終了 (6.2%)
- 検証なしまたは不完全な検証 (8.2%)
- 不正確な検証 (9.1%)
出力の正確性と信頼性を確保する上での課題があることを示している。
MetaGPTやChatDevのような明示的な検証を行うシステムは一般的には総失敗数が少ないことを示しており、明示的なチェックが役に立つ。
しかし検証を行っても、全体的なMASの成功率は依然として低い。例としてChatDevが生成したチェスプログラムは表面的なチェックを通過するが、実際のゲームルールに対する検証に失敗するため、実行時のバグを含んでおり、レビューの段階を経ても出力は使えない。
分析中、多くの既存の検証ツールは徹底的な検証を求められているにも関わらず、コードがコンパイルされるかどうかやTODOコメントが残っているかどうかの確認などの表面的なチェックしかしないことが判明した。
MASの開発はプログラマーがコミット前にコードをテストする伝統的なソフトウェア開発から学ぶべきである。
具体的には、外部知識の活用、生成中のテスト出力の収集、低レベルの正確性と高レベルの目的に対する多層的なチェックなど、より厳格な検証が必要。
より良いMASへ
MAST-Dataにおける失敗の内訳

MASによって失敗に関する分布は異なる。
AppWorldはスター型トポロジーと定義済みのワークフローがないことにより終了条件が明確ではないため、しばしば早期終了がされる。
OpenManusはステップ繰り返しの傾向があり、HyeprAgentはステップ繰り返しと誤った検証の影響が強い。
MASによって傾向が異なるため、万能の解決策がないことを示している。
MASTについて
系統的な失敗の内訳を提供する構造化されたボキャブラリーを提供することでこの問題に対処する。
LLMアノテーターとMASTを使用することで、開発者が特定のシステムにおける失敗のプロファイルの定量的分析が可能になる。
システム設計の重要性
モデルの能力向上だけではMAST全体に対処するには不十分である。その代わりに、優れたMASの設計に組織的な理解が必要であると本論文では主張されている。
人間のように個人の能力が高くても、組織構造に結果があれば失敗を招くことがあるように。
本論文のケーススタディでは、MASシステムのワークフローとプロンプトの変更をそれぞれ適用した結果、同じモデルで最大15.6%の改善を達成した。
つまり、MASの失敗は優れたシステム設計で対処可能であることを示している。
ただし、全ての失敗が解決されるわけではなく、タスク完了率も以前低いままで、より大きな改善が必要であることを示している。
エージェントシステムの構造からモデル自体の改善まで、様々な変化が必要と考えられる。
MASTはMASの構造的弱点がどこにあるかを特定するのに役に立ち、より高度なMASアーキテクチャの設計と評価を導くことができると主張。