目次
概要
本記事では、ローカル版のDifyでVertexAIにあるLlama3.2-Vision-Instruct-90BのAPIを呼び出す方法を記載している。
Vertex AIではLlamaシリーズのAPIが提供されている。
但し2025/1/11時点で、DifyでVertexAIから呼び出せるモデルはGemini, Claudeシリーズとなっている。
そのため他のモデルのAPIを利用したい場合は、自分でyamlファイルを追加する必要がある。
Difyの公式ドキュメントには、モデルの追加方法が記載されているが個人的には分かりにくく、モデルの設定ファイル作成からDify上に追加したモデルを表示させるまで苦労したため本記事を作成した。
飽くまで応急処置的にモデルを呼び出しているため、最適化された手法ではないことを予め記載しておく。
但し、今回紹介する方法はVertex AIに限った方法ではないため、各ベンダーで公開されているがDifyでは使えないモデルを使いたい時に役に立つと考えられる。
また検証してはいないが、カスタムモデルをDify上で使いたい場合も同様の手順で実行できると思われる。
(※少なくともLlamaシリーズに関しては、計算リソースを確保できるのであればOllama等を利用してDifyと接続するほうが早いし確実と思われる。
今回は計算リソースを持ってない、Google CloudのLlama3.2は2025/1/11時点でプレビュー公開中であり、無料で使えたためコストが抑えられる等の理由でVertex AIから呼び出している)
方法
前提としてDifyのインストール・起動は済んでおり、DifyとVertex AIとの接続設定も完了しているものとする。
(DifyでVertexAIを使用する手順は以下の記事を参考)
今回は起動中のコンテナ内にファイルを追加し、コンテナを再起動させる形で設定を反映させている。
当初は大まかに
- Dify内に設定ファイルを追加
- Dockerfileを編集し再ビルド
- docker composeでコンテナを立ち上げ直す
という手順で行ったのだが、やり方が悪かったのか、作成したファイルがコンテナ内に追加されておらずモデルを呼び出せなかったため、最終的に以下のような手順となった。
手順
コンテナ docker-api-1 に接続し各プロパイダのモデルの設定ファイルが格納されているディレクトリまで移動
docker composeでDifyを起動させた後、docker-api-1内に入る。
docker-api-1 には、エディタがインストールされていないので、適当なエディタをインストールした後、各プロパイダのモデルの設定ファイルが格納されているディレクトリまで移動する。
docker exec -it docker-api-1 bash
apt update
apt install vim
cd core/model_runtime/model_providers
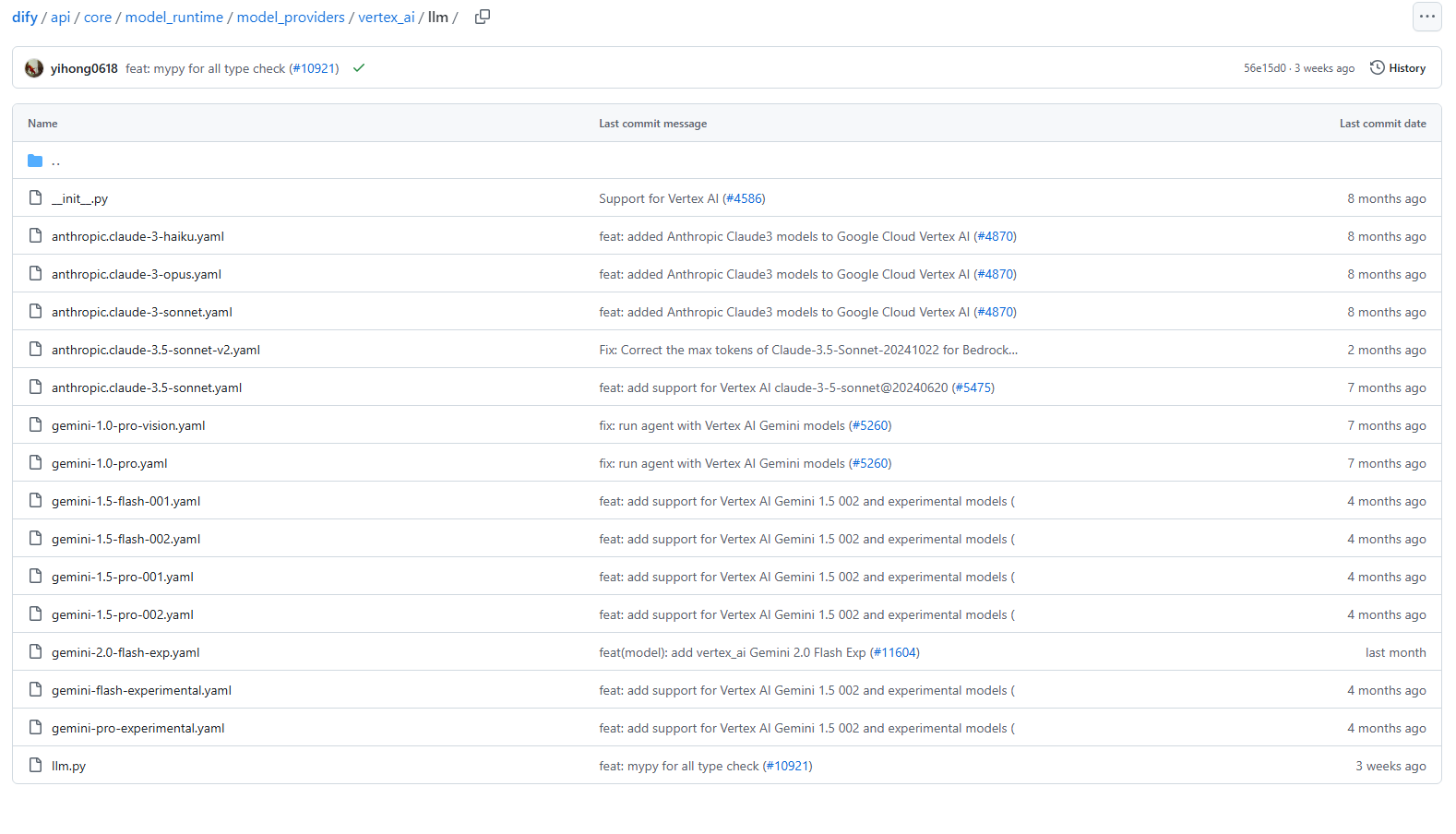
移動すると、画像のようにプロパイダごとにディレクトリが存在している。
各ディレクトリの中身は、モデルの種類ごとにディレクトリが存在し、追加したいモデルの種類に合わせて対応するディレクトリ内に設定ファイルを追加する。
例えば、vertex_ai にはllm、text_embeddingが存在する。

今回はLlama3.2を追加するのでllm に移動し、yamlファイルを追加する。
llm に移動しyamlファイルを追加
cd vertex_ai/llm
vi meta-llama-3.2-90b-vision-instruct-maas.yaml
yamlファイルについては、vertex_ai/llm/Gemini-1.0-pro-vision.yamlをベースにしつつ、パラメータ等はbedrock/llm/us.meta.llama3-2-90b-instruct-v1.0.yamlの内容を参考にして作成した。
model の部分は、以下のリンク先にあるGoogle Cloudのllama3.2-apiのモデルID llama-3.2-90b-vision-instruct-maas に設定した。
また、features 部分に -vision を追記することで、画像入力の機能も利用できるようにした。
以下は実際に作成したyamlファイルの中身である。
model: llama-3.2-90b-vision-instruct-maas
label:
en_US: Meta Llama 3.2 90B Instruct
model_type: llm
features:
- vision
- tool-call
model_properties:
mode: chat
context_size: 128000
parameter_rules:
- name: temperature
use_template: temperature
default: 0.5
min: 0.0
max: 1
- name: top_p
use_template: top_p
default: 0.9
min: 0
max: 1
- name: max_output_tokens
use_template: max_tokens
required: true
default: 512
min: 1
max: 2048
参考ファイル
Gemini-1.0-pro-vision.yaml
Bedrock:us.meta.llama3-2-90b-instruct-v1.0.yaml
llm.py を編集し、画像入力時にllama3.2-vision-instructが正しく動くようにする (読み飛ばしても可)
※ 本セクションでは、Difyにて画像入力を行うアプリを作成する際にLlama3.2が正しく動くようにするための設定を紹介している。厳密にはモデルの追加に関する話ではないため、マルチモーダルモデル等を利用しないのであれば、無視しても構わない。
llmディレクトリには、llm.pyファイルが存在する。
簡単に言うとモデル呼び出しに関するコードが記載されたファイルであり、モデル用にメッセージを作成、送信するなどの処理も記載されている。
Difyはテキストだけではなく、画像の入力も受け付けており、マルチモーダルに対応したAIアプリを作成することも可能である。
そしてvertex_ai/llm にあるllm.pyは、現状画像とテキストが入力されると、テキスト→画像 の順番でモデルにメッセージを送信するようになっている。
厳密には違うが、以下のような形でメッセージは作られる。
## messageの例
messages = [
{"role":"user","content":[
{"type":"text","text":"test"}, # Difyでは先にtextを送る
{"type":"image"}
]
]
しかしLlama3.2-visionには、プロンプトに画像を含める場合、画像 →テキストの順番で送らないとモデルが入力を受け付けてくれないという仕様が存在する。
## messageの例
messages = [
{"role":"user","content":[
{"type":"image"}, # Llama3.2-visionでは画像が先
{"type":"text","text":"test"}
]
]
実際、Google CloudのLlamaシリーズに関するドキュメントにも、仕様に関する記述がある。

そのため、llm.py を編集しないと、画像を送信した際にエラーが生じてしまい出力が得られない。
(テキストのみの場合は、特に変更しなくても問題ない。画像が入力されないとimageに関するメッセージが作られず、model側が自動でテキストのみと判断するため)
llm.pyの編集
vi llm.py
2025/1/11時点で、llm.py の649行あたりにある _format_message_to_glm_content がDifyの入力データからモデル用のメッセージに作成する関数となっている。

※注釈が記載されている部分は追加行
658~679行あたりが、利用者からの入力データを格納したuser メッセージを作成する処理に該当する。
入力データがテキストか画像かを判定した後、それぞれ適切なメッセージが作られ、user メッセージを格納するリスト (parts) に挿入される。
(※ ここで言う'user'メッセージとは、プロンプトの'user'ロールのメッセージを指している)
画像とテキストを同時に入力した場合、コード的には先に来た方から処理するようになっている。
つまり、画像→テキストかテキスト→画像の2パターンで送信されることが考えられる。
しかし基本的には テキスト →画像 の順でデータが送られているようであり、その順番で常にメッセージも作成されているようである。
そのためDifyでLlama3.2-visionを使って、画像入力をすると必ずエラーが生じてしまう (少なくとも自分は上手くいったケースを確認できなかった)。
今回は、textのメッセージを格納するリスト parts_text を別途用意し、ループ終了後parts の後ろに parts_textリストをくっつけることで対応した。
def _format_message_to_glm_content(self, message: PromptMessage) -> "glm.Content":
"""
Format a single message into glm.Content for Google API
:param message: one PromptMessage
:return: glm Content representation of message
"""
import vertexai.generative_models as glm
if isinstance(message, UserPromptMessage):
glm_content = glm.Content(role="user", parts=[])
if isinstance(message.content, str):
glm_content = glm.Content(role="user", parts=[glm.Part.from_text(message.content)])
else:
parts = []
parts_text = [] # text用のリスト
for c in message.content:
if c.type == PromptMessageContentType.TEXT:
parts_text.append(glm.Part.from_text(c.data))
else:
message_content = cast(ImagePromptMessageContent, c)
if not message_content.data.startswith("data:"):
url_arr = message_content.data.split(".")
mime_type = f"image/{url_arr[-1]}"
parts.append(glm.Part.from_uri(mime_type=mime_type, uri=message_content.data))
else:
metadata, data = c.data.split(",", 1)
mime_type = metadata.split(";", 1)[0].split(":")[1]
parts.append(glm.Part.from_data(mime_type=mime_type, data=data))
parts += parts_text # 画像, text の順で格納
glm_content = glm.Content(role="user", parts=parts)
return glm_content
飽くまでも応急処置的ではあり、本来はllama用に関数など別途作成した方が良いと考えられる。
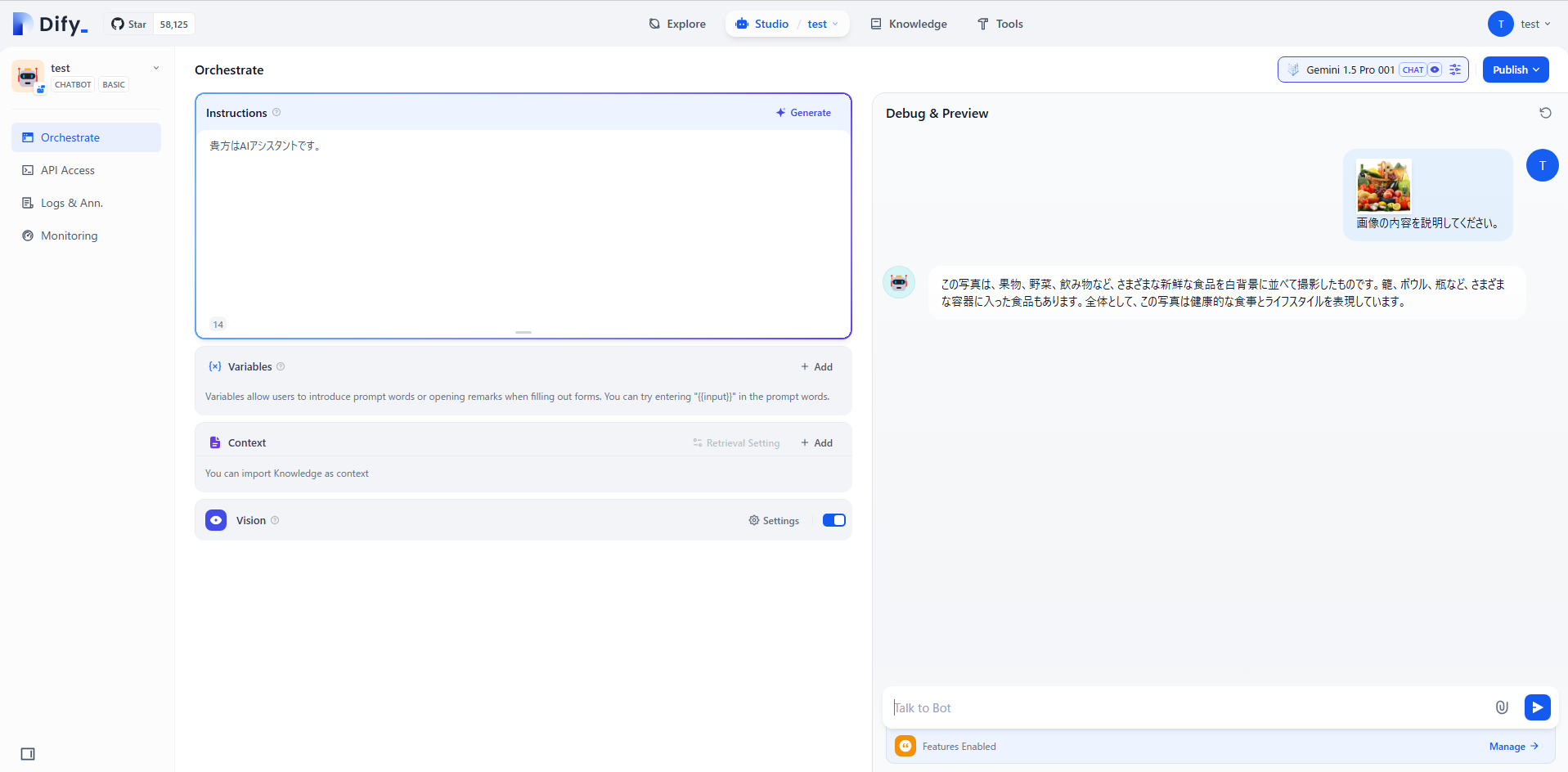
一応編集後でも、下記の画像のようにデフォルトで対応しているモデルも正しく動いているため大丈夫と思われる。
(画像は、llm.py編集後に、Gemini-1.5-pro-001に画像とテキストを入力した結果を表す)
但し、今後Difyのアップデート次第でどうなるか分からないため、既存のファイルを編集する場合は慎重に行ったほうが良いと考えられる。
コンテナから離れ docker-api-1 を再起動する
exit
docker restart docker-api-1
少し時間を置いて、ブラウザからDifyを開けるか確認する。特に問題なければ以下の画像のように開くはずである。

動作確認
Dify上でVertex AI のmodel providerにllama3.2が追加されているかを確認する。
今回の場合、Meta Llama 3.2 90B Instruct が追加モデルに該当する (yamlファイルのlabel で設定した名前が表示される)。

テンプレート等から簡単なアプリを作成して、モデルが正しく動くか確かめる。

上図は、Vision機能をONにして右側のテスト用画面で画像とテキストを入力した結果を表している。
画像の内容を説明してくれており、正しくモデルを呼び出せることを確認できた。
まとめと課題
まとめ
Vertex AIのLlama3.2-vision-instruct-90BのAPIをDifyから呼び出すことが出来た。手順の内容を少し変えるだけで、Model Gardenで提供されているモデルも同様の手順で呼び出すことが出来るはずである。
Vertex AIでは自身で作成したモデルをデプロイして、エンドポイントを作成することも出来たはずなので、カスタムモデルも同様の手順で呼び出すことも出来ると思われる。
また、Vertex AIに限らず他のプロパイダも同様に追加できるはずである。
Difyは今も盛んにアップデートされているため、基本的には利用したいモデルの対応待ちで大丈夫と思われるが、直ぐに非対応モデルを使いたい場合や、マイナーなモデルやカスタムモデルを利用したい場合は、このように設定することで対応が可能である。
課題
- 何度も記述した通り、紹介した手順は飽くまでも応急処置的な手法であり、もう少し冴えたやり方があると思われる
- 現状コンテナから直接修正しているため、コンテナを立て直す等すると再度設定し直す必要がある
- 一度コンテナの外でファイルを作成しておき、コンテナ内にファイルをコピーする等を行うと多少はマシかもしれない
- 再ビルドでイメージを作り直してコンテナを立て直すと良いと思うのだが、うまくいかず……
- 現状コンテナから直接修正しているため、コンテナを立て直す等すると再度設定し直す必要がある
- Difyのアップデート次第では上記手順で対応できない可能性がある
- 特にモデルの呼び出しに関するコードについては、内容が変化すると思われる