目的
SPSS ModelerからAthena経由でS3のデータを読み取り、簡単な分析レポートを作成する方法をご紹介します。
SPSS Modeler18.5から追加されたネイティブPythonの機能を活用し、ファイルの変換とライブラリを使用した分析レポートの作成方法をまとめています。
対象読者
・日常業務でSPSS Modeler 18.5を使用しているデータ分析初級者~中級者の方
・簡単な週次レポートをSPSS Modelerで作成したい方
・今後SPSS Modeler18.5の導入を検討されている方
前提
-
boto3を使用したSPSS Modeler上でのS3への出力方法について
こちらの記事の内容を実施したことを想定しています。
シナリオについて
架空のショップの支店毎の売上データを週次で分析するケースを想定しています。
日時売上データがcsvファイルで作成されているケースを想定し、SPSS Modelerでparquet形式に変換し、S3にはbranch/year/month/day/.parquetの形で保存することによってパーティション機能を有効にし、コストを削減します。
目次
- 1章 SPSS Modeler環境に関する初期設定について
- 2章 SPSS Modelerでのファイル変換とパーティション機能について
- 3章 Athena環境の構築について
- 4章 SPSS ModelerでのAthenaテーブルの読み取り方法について
- 5章 拡張の出力ノードを使用した週次レポートの作成方法について
1章 SPSS Modeler環境に関する初期設定について
Athena用のドライバーの取得とODBCの設定をこの章では行います。
最初にAthena用のドライバーを取得しましょう。
下記が公式ドキュメントになります。本記事内ではWindows用のドライバーを取得しています。

ドライバーをダウンロードできましたら、次にインストールします。
特に設定項目はありませんので、指示に従って「next」をクリックし、最後に「install」をクリックしてください。
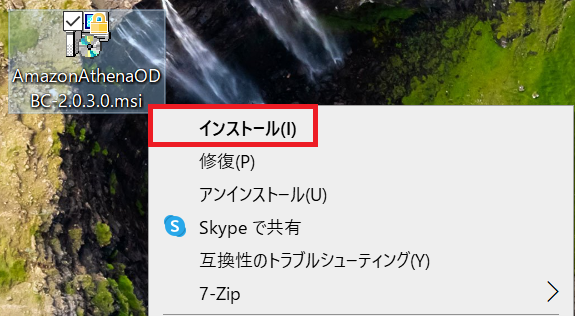
ドライバーのインストールが完了しましたのでODBCの設定に移ります。
スタートメニューから「ODBC データソースアドミニストレーター(64ビット)」を開いていただき、追加ボタンをクリックすると先ほどインストールした「Amazon Athena ODBC(x64)」が選択できます。
選択し、完了ボタンをクリックしてください。

次にDSNの設定をしていきましょう。
Data Source Name: このデータソースの名前を入力してください。
Description: このデータソースに関する情報を任意で入力してください。
Region: Athenaを使用して、アクセスするS3のあるリージョンを入力してください。
S3 Output Location: クエリの結果を保存する場所を指定できます。ここでは前回の記事で作成したバケットとフォルダを指定しています。
Catalog, Database, Workgroupの欄はデフォルトのままで構いません。
ここまで設定できましたら、左下の「Authentication Options」を選択してください。

Authentication Typeには「IAM Credentials」を選択してください。
UsernameとPasswordにはアクセスキーとシークレットキーを入力して、OKボタンをクリックしてください。
未作成の方はこちらを参考に作成してください。

一つ前のウィンドウに戻りましたら、左下のTestボタンをクリックし、「Successfully connected」と出力されれば成功です。
Testボタンの隣のOKボタンをクリックするとDSNの一覧の中にAthenaDSNが追加されます。
SPSS Modeler環境に関する設定は以上になります。

2章 SPSS Modelerでのファイル変換とパーティション機能について
SPSS ModelerからAthena経由でS3データを読み取る際に、デフォルトでは指定したS3内を全量スキャンします。
S3のデータ量が増えるごとにコストが増加してしまいますので、データをパーティション化することで、各クエリによってスキャンするデータ量を減らすことができ、コストも削減できます。
この章ではパーティション機能を活用するために、CSVファイルをParquetファイルに変換した上でS3へアップロードするスクリプトを作成し、SPSS Modeler上で実行します。
①
ここでは下記2つの条件を満たすPythonスクリプトを作成します。
・ローカル環境からcsvファイルをSPSS Modelerへ一括取得
・csvファイルをparquetファイルへ変換してローカル環境に保存
import pandas as pd
import os
from dotenv import load_dotenv
import boto3
import re
# 入力ディレクトリと出力ディレクトリの設定
input_dir = "D:/testdata/salesData"
output_dir = "D:/testdata/salesData_parquet"
# 出力ディレクトリの作成
os.makedirs(output_dir, exist_ok=True)
# 入力ディレクトリ内のすべてのCSVファイルを処理
for file_name in os.listdir(input_dir):
if file_name.endswith(".csv"): # CSVファイルのみを対象
csv_file = os.path.join(input_dir, file_name) # フルパスを作成
parquet_file = os.path.join(output_dir, file_name.replace(".csv", ".parquet")) # 出力ファイル名を生成
try:
# CSVファイルの読み込み
print(f"Loading CSV file: {csv_file}")
df = pd.read_csv(csv_file)
# Parquet形式で保存
print(f"Saving to Parquet file: {parquet_file}")
df.to_parquet(parquet_file, engine="pyarrow", index=False)
print(f"Conversion complete: {parquet_file}")
except FileNotFoundError:
print(f"Error: File not found - {csv_file}")
except ImportError as e:
print("Error: Missing required library. Ensure pyarrow or fastparquet is installed.")
print(f"Details: {e}")
except Exception as e:
print(f"An unexpected error occurred for file {csv_file}: {e}")
print("All files processed.")
②
次に、作成したparquetファイルをS3へアップロードするスクリプトを作成しましょう。
Pythonスクリプトを使用して、S3へファイルをアップロードする方法については、前回の- boto3を使用したSPSS Modeler上でのS3への出力方法についての記事を参考にしてください。
ここではパーティション機能を使用するために、branch/year/month/day/.parquetのフォルダ構成を自動で作成し、アップロードする流れになっています。
#環境変数からs3の情報を読み取る
load_dotenv()
s3 = boto3.client('s3')
bucket_name = "spsstos3"
local_folder = "D:/testdata/salesData_parquet"
base_s3_path = "spsstos3test1"
# ローカルフォルダ内のすべてのParquetファイルを処理
for file_name in os.listdir(local_folder):
# Parquetファイルだけを対象にする
if not file_name.endswith(".parquet"):
continue
# ファイル名から日付と支店名を抽出(例: 20241201tokyo.parquet)
match = re.match(r"(\d{4})(\d{2})(\d{2})([a-zA-Z]+)\.parquet", file_name)
if not match:
print(f"Skipping invalid file name: {file_name}")
continue
year, month, day, branch = match.groups()
# S3のアップロード先パスを生成
s3_path = f"{base_s3_path}/branch={branch}/year={year}/month={month}/day={day}/{file_name}"
# ローカルファイルのフルパス
local_file_path = os.path.join(local_folder, file_name)
# S3にアップロード
try:
s3.upload_file(local_file_path, bucket_name, s3_path)
print(f"Uploaded {file_name} to s3://{bucket_name}/{s3_path}")
except Exception as e:
print(f"Failed to upload {file_name}: {e}")
今回テストデータとして使用したのは2024/12/1~2024/12/10までの東京支店と埼玉支店のデータです。
このデータがそれぞれ支社と年月日ごとにパーティション化されてS3へアップロードされていれば成功です。

SPSS Modlerを起動し、ダミーの入力ノードを作成します。
入力パレットからユーザー入力ノードをキャンバスに追加し、下記の様に入力できましたら左下のOKボタンをクリックしてください。

出力パレットから拡張の出力ノードをキャンバスに追加し、ユーザー入力ノードからリンクしてください。
編集画面でPython Syntaxを選択し①と②で作成したスクリプトを貼り付けて実行ボタンをクリックしてください。

「All files processed.」と出力されれば成功です。
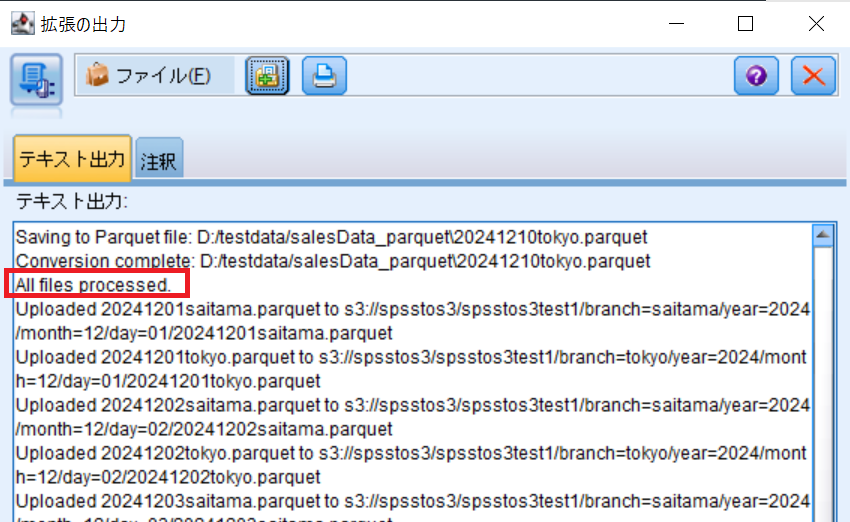
スクリプトで指定したローカル環境のフォルダに変換されたparquetファイルが保存されていることを確認します。
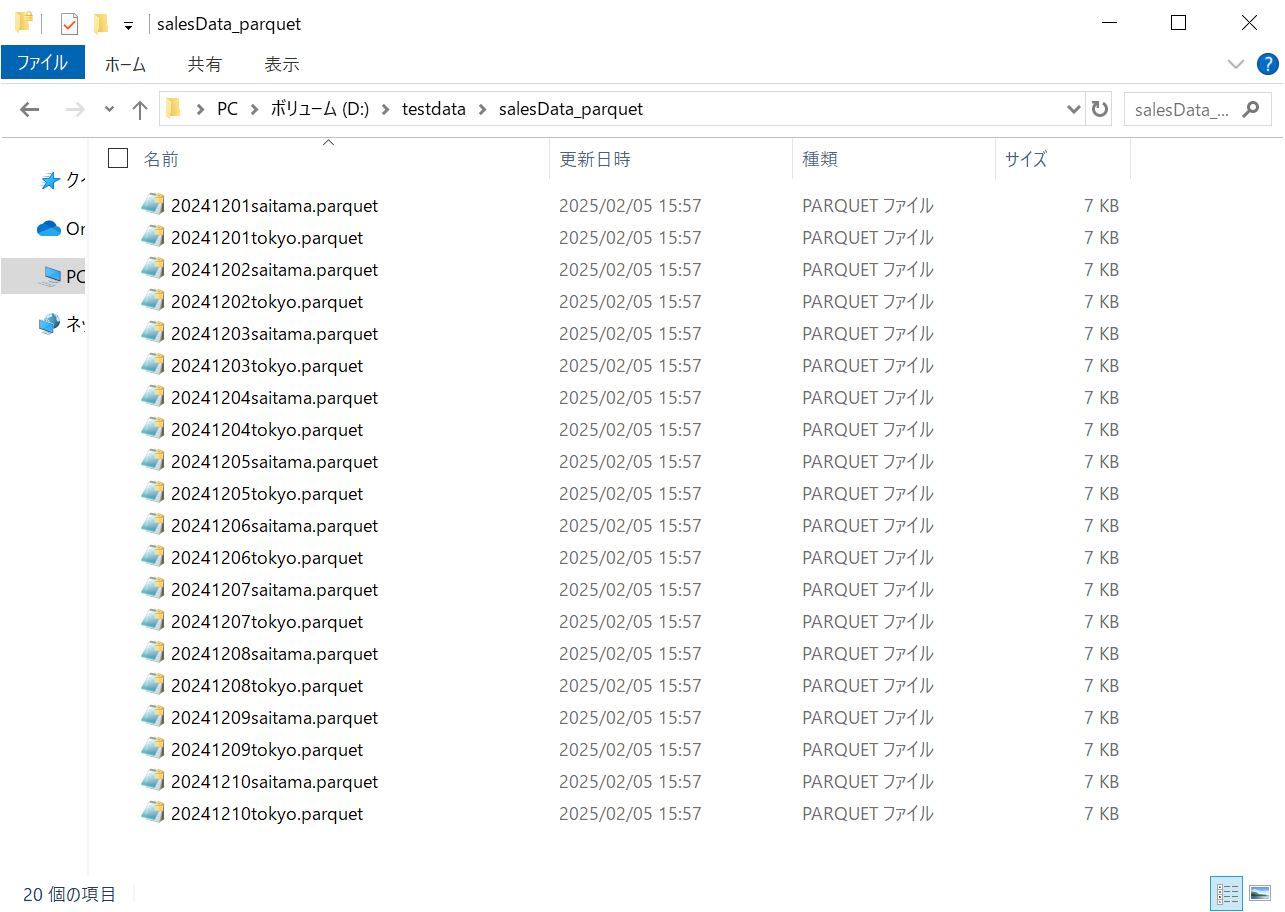
指定したS3フォルダを確認いただくと、パーティション化された上でS3にアップロードされていることが確認できます。

3章 Athena環境の構築について
この章ではSPSS Modelerから参照するAthenaテーブルを作成します。
AWSコンソールでAmazon Athena>クエリエディタを開きます。
最初に、今回の環境用のデータベースを作成しましょう。
クエリエディタでデータベースを作成します。(ex.sales_data_db)
CREATE DATABASE sales_data_db;

このデータベース内に2章でアップロードしたparquetファイルに対応するAthenaテーブルを作成します。
データ欄で先ほど作成したデータベースを指定してください。
クエリエディタ内ではテーブルの作成とパーティションの指定を行います。
LOCATIONにはパーティション化されたフォルダの親フォルダを指定して、クエリを実行するとテーブルが作成されます。
CREATE EXTERNAL TABLE sales_branchdata (
CustomerNumber BIGINT,
PurchaseDate STRING,
ItemCode INT,
Quantity INT,
Value INT
)
PARTITIONED BY (
branch STRING,
year STRING,
month STRING,
day STRING
)
STORED AS PARQUET
LOCATION 's3://spsstos3/spsstos3test1/';

下記のコードを実行して、メタデータにパーティション情報を追加します。
MSCK REPAIR TABLE sales_data;

ここまででテーブルの作成とパーティション情報の設定は完了です。
パーティション機能を使用してクエリが実行できているかを確認しましょう。
下記のクエリを実行し、完了済みと出力されていれば成功です。
SELECT *
FROM sales_data_db.sales_branchdata
WHERE branch = 'saitama' AND year = '2024' AND month = '12' AND day = '01';

4章 SPSS ModelerでのAthenaテーブルの読み取り方法について
この章ではSPSS ModelerからAthenaテーブルに接続して、データを取得します。
SPSS Modelerを起動し、次の手順を実施してください。
- 入力パレットからデータベースノードをキャンバスへ追加します
- ダブルクリックで編集画面を開きます
- データソース欄をクリックし、「新規データベース接続の追加」をクリックします
- 1章で作成したODBCデータソースを選択します
- 認証の項目のユーザーIDにアクセスキー、パスワードにシークレットキーを入力し接続ボタンをクリックすると接続欄にデータソースが追加されますので、OKボタンをクリックしてください
ここまででがAthenaテーブルへの接続設定です。

データベースノードの編集画面を開き、モードにSQLクエリーを選択し、下記のクエリを貼り付けてください。
ここでは週次レポートを作成するために12月2日から12月8日までのデータを取得する形にしています。
from句の中では作成した環境に合わせて[データベース名].[テーブル名]で指定してください。
出力パレットからテーブルノードをキャンバスに追加し、データベースノードからリンクし実行すると表形式で出力できます。
SELECT *
FROM sales_data_db.sales_branchdata
WHERE branch = 'saitama'
AND year IN ('2024')
AND month IN ('12')
AND day BETWEEN '02' AND '08';
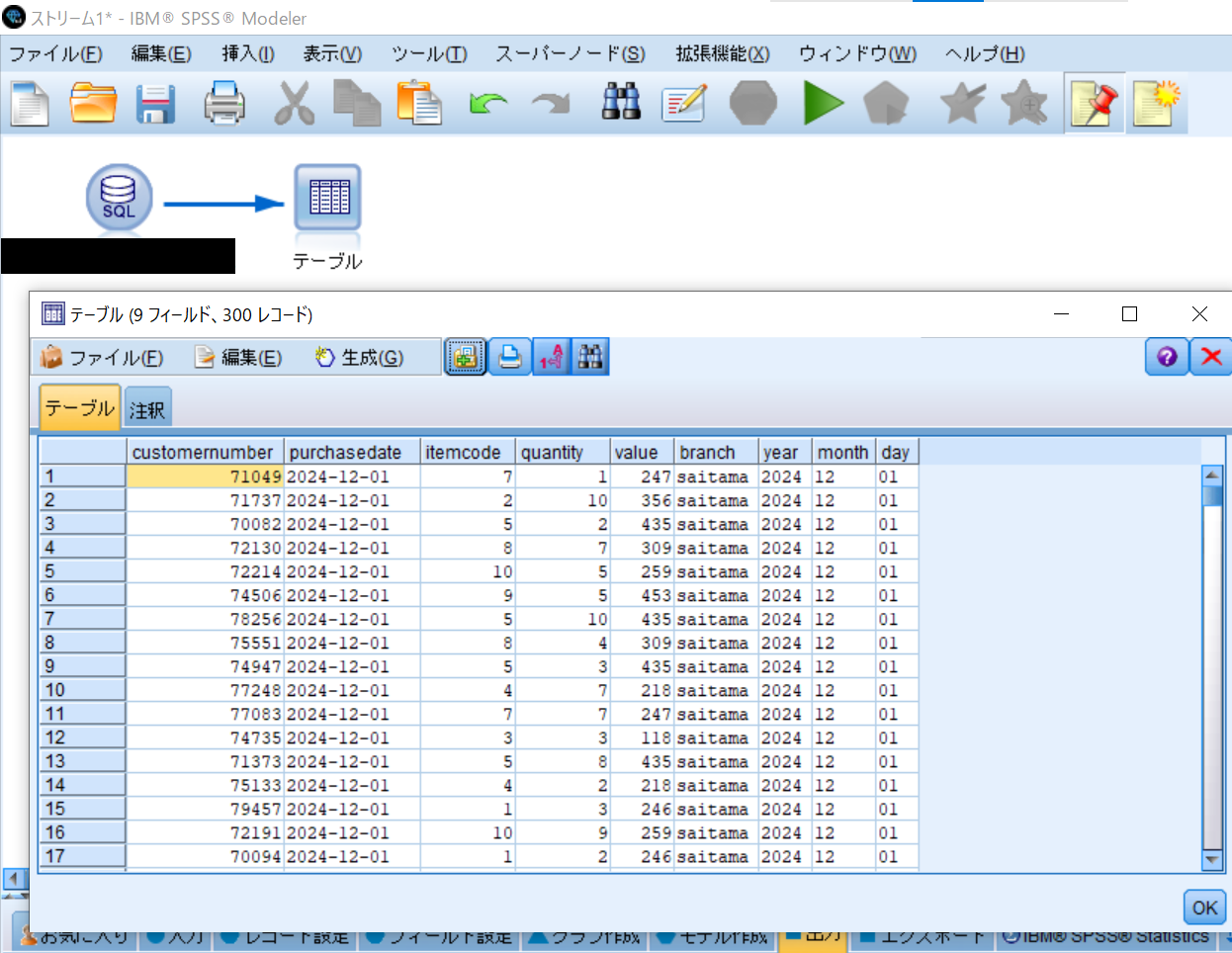
ここまでで、Athenaテーブルの読み取りを行えるようになりましたので、最後に簡単な週次レポートを作成してみましょう。
5章 拡張の出力ノードを使用した週次レポートの作成方法について
この章では拡張の出力ノード上でmatplotlibを使用して、簡単な週次レポートを作成し、PDF形式で保存しています。
日時単位の売上金額の折れ線グラフとItemCode別の積み上げ棒グラフを作成しています。
- 出力パレットから拡張の出力ノードをキャンバスに追加し、データベースノードからリンクしてください
- 拡張の出力ノードの編集画面を開いてください
- Python Syntaxを選択し、以下のコードを貼り付けて実行してください
- 指定したoutput_pdfにレポートが作成されます
import boto3
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.backends.backend_pdf import PdfPages
import modelerpy
# データ読み込み
df = modelerpy.readPandasDataframe()
# `purchasedate` を datetime 型に変換
df["purchasedate"] = pd.to_datetime(df["purchasedate"])
# 日々の売上合計金額の折れ線グラフ
daily_totals = df.groupby("purchasedate")["value"].sum()
# 日ごとの ItemCode 毎の積み上げ棒グラフ
pivot_data = df.pivot_table(values="value", index="purchasedate", columns="itemcode", aggfunc="sum", fill_value=0)
# PDFに出力
output_pdf = "D:/testdata/sales_analysis.pdf"
with PdfPages(output_pdf) as pdf:
# 1ページに2つのグラフを並べる
fig, axes = plt.subplots(nrows=2, ncols=1, figsize=(10, 10)) # 2行1列のレイアウト
# 折れ線グラフ
daily_totals.plot(ax=axes[0], kind="line", marker="o", title="Daily Total Sales", ylabel="Total Sales", xlabel="Date")
axes[0].tick_params(axis='x', rotation=45)
axes[0].grid(True)
# purchaseDate の日付フォーマットを YYYYMMDD に変更
pivot_data.index = pivot_data.index.strftime("%Y%m%d")
# 積み上げ棒グラフ
pivot_data.plot(ax=axes[1], kind="bar", stacked=True, title="Daily Sales by ItemCode", ylabel="Sales", xlabel="Date")
axes[1].tick_params(axis='x', rotation=45)
axes[1].legend(loc="upper left", bbox_to_anchor=(1, 1)) # 凡例の位置調整
# レイアウト調整
plt.tight_layout()
# PDFに保存
pdf.savefig(fig)
plt.close(fig)


あとがき
パーティション機能を使用するとAthenaを使用するコストを削減することが出来ます。
ローカル環境にデータを配置出来ない場合やDBを用意できない場合に分析を実施する例としてご紹介させていただきました。
日時を動的に取得するクエリにしたり、分析レポートを支社単位で自動作成にしたりすることで運用に繋げることも可能だと思います。
ご質問やご意見がございましたら、お気軽にコメントください。