目的
拡張のインポートノードを使用してデータを読み込む際には、データセットに応じたデータモデルを毎回作成する必要があります。
今回はpandasを使用して、データタイプからデータモデルを自動生成するスクリプトを作成しました。
対象読者
・SPSS Modeler 18.5の導入を検討されている方
・SPSS Modeler上でPythonを使用してデータ分析を行いたい方
・SPSS Modeler上でのデータモデル作成に困っている方
データモデルについて
SPSS Modelerでは入力データセットのメタデータ (フィールド数、フィールド名、フィールド・ストレージ・タイプなど) をデータモデルと呼びます。
通常可変長ファイルなどで読み込んだ際には自動でデータモデルが作成されます。

一方で、拡張のインポートノードを使用してデータを読み込んだ際には自動でデータモデルが作成されないためノード内に記述する必要があります。
目次
1章 データモデルと自動生成について
SPSS Modeler18.5の公式ドキュメントを参照するとデータモデルの作成例が載っています。
読み込むデータセットのそれぞれの列について、列名・ストレージタイプ・データ型を指定する必要があります。
dataModel = modelerpy.DataModel([
# %FieldName%, %StorageType%, %MeasurementType%
modelerpy.Field(‘StringField’, ‘string’, ‘nominal’),
modelerpy.Field(‘FloatField’, ‘real’, ‘continuous’),
modelerpy.Field(‘IntegerField’, ‘integer’, ‘ordinal’),
modelerpy.Field(‘BooleanField’, ‘integer’, ‘flag’),
modelerpy.Field(‘DatetimeField’, ‘timestamp’, ‘continuous’),
modelerpy.Field(‘TimeField’, ‘time’, ‘continuous’),
modelerpy.Field(‘DateField’, ‘date’, ‘continuous’),
])
# StorageType could be: integer, real, string, date, time, timestamp
# MeasurementType could be: discrete, flag, nominal, ordinal, continuous
ここではpandasのdtypes関数を使用してデータ型を取得し、それをSPSS Modelerのストレージタイプ・データ型にマッピングすることで、データモデルを自動生成する仕組みを作成してみたいと思います。
下記はdtypes関数で取得できるデータ型の例です。
| データ型 | 説明 |
|---|---|
| int64 | 64ビットの整数型。整数値を格納する列に使用されます。 |
| float64 | 64ビットの浮動小数点型。小数点を含む数値データに使用されます。 |
| object | 一般的に文字列型データを表します。ただし、任意のPythonオブジェクトも格納可能。 |
| bool | 真偽値型(True / False)データ。 |
| datetime64[ns] | 日付と時刻を表す型。Pandasの日時操作に適しています。 |
2章 データモデル自動作成スクリプトについて
-
使用するライブラリとファイルの読み込み
今回はSPSS Modelerでのpythonを制御するmodelerpyとデータ操作のためのpandasの二つのライブラリをインポートします
また、読み込むcsvファイルを指定します。こちらは任意のファイルで構いません# ネイティブ Python APIのパッケージ import modelerpy import pandas as pd # CSVファイルを読み込む df = pd.read_csv("D:/train2.csv") # 適切なファイルパスに置き換えてください
-
データモデル変換表の作成
dtypes関数で取得した各列のデータ型に応じて、SPSS Modelerのストレージタイプとデータ型に割り当てるための変換表を作成します# 修正された変換表を作成 mapping_data = { 'dtypes': ['int64', 'float64', 'object', 'bool', 'datetime64[ns]'], 'StorageType': ['integer', 'real', 'string', 'integer', 'timestamp'], 'Measurement': ['ordinal', 'continuous', 'nominal', 'flag', 'continuous'] } mapping_df = pd.DataFrame(mapping_data)
-
データモデルを自動生成する関数を作成します
変換表から「[%FieldName%, %StorageType%, %MeasurementType%]」をそれぞれの列について作成しています。# データモデル生成関数 def generate_data_model(df, mapping): # Convert mapping DataFrame to a dictionary for easier lookup type_mapping = mapping.set_index('dtypes').to_dict(orient='index') # Generate modelerpy.Field entries field_entries = [] for column in df.columns: dtype = str(df[column].dtypes) if dtype in type_mapping: storage_type = type_mapping[dtype]['StorageType'] measurement = type_mapping[dtype]['Measurement'] field_entries.append( f"modelerpy.Field('{column}', '{storage_type}', '{measurement}')" ) else: print(f"Warning: No mapping found for dtype '{dtype}' in column '{column}'") # Create the dataModel string data_model = "modelerpy.DataModel([\n " + ",\n ".join(field_entries) + "\n])" return data_model
-
データモデルの作成
作成した関数を実行し、データモデルをdata_model_scriptとして生成しますdata_model_script = generate_data_model(df, mapping_df)
-
データの参照
作成したデータモデルを読み込みます
この時に、data_model_scriptをデータモデルとして使用するためにeval()関数を使用してオブジェクトに変換しています# データモデルの参照時 if modelerpy.isComputeDataModelOnly(): outputDataModel = None ### Compute output data model here ### 出力データモデルの設定 eval_data_model = eval(data_model_script) # 文字列を評価してオブジェクトとして扱う modelerpy.setOutputDataModel(eval_data_model)
-
データの出力
ここまでで準備は完了しましたので、writePandasDataframe関数を使用して、データフレームをSPSS Modelerで読み込みます# データ出力時 else: outputData = None ### ファイルからデータの読み込み outputData = df ### データの出力 modelerpy.writePandasDataframe(df)
以上が拡張のインポートノード内で読み込んだデータセットのデータモデルを自動生成するスクリプトになります
3章 SPSS Modelerでの操作について
作成したスクリプトを使って、データモデルが自動生成されているかを確認します。
-
入力パレットから拡張のインポートノードをキャンバスへ追加します
-
Pythonを選択し、2章で作成したスクリプトを貼り付けて、OKボタンをクリックします
(作成したスクリプトは下記です)
付録(スクリプト)

-
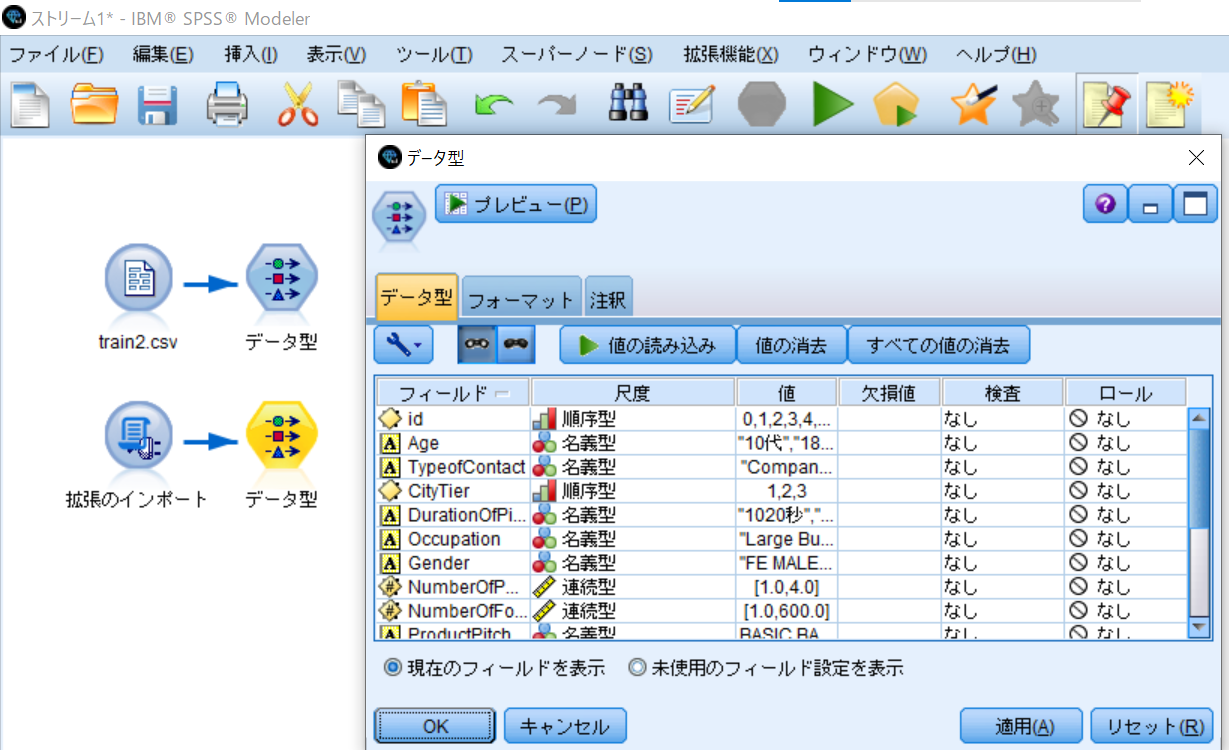
データ型ノードをダブルクリックして、編集画面を開き、データモデルが生成されSPSS Modelerにデータが読み込まれていることを確認します
-
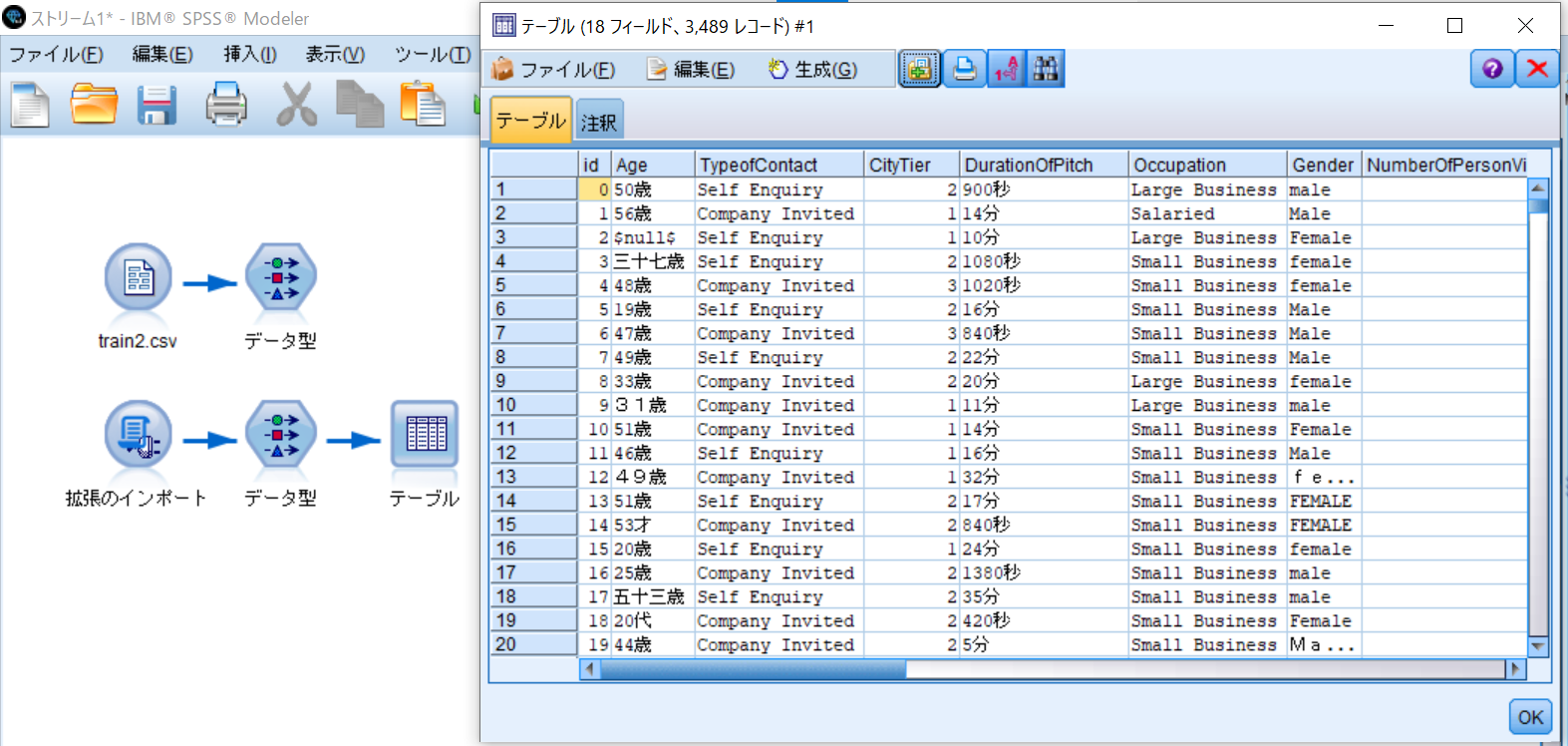
出力パレットからテーブルノードをキャンバスに追加し、データ型ノードからリンクして、テーブルノードを実行します
4章 活用例について
3章ではcsvファイルを指定して読み込んでいましたが、拡張のインポートノードを使用するとフォルダ配下のcsvファイルを全て結合した上でSPSS Modelerに読み込むことが出来ます。
データ取得まではPythonを使用して、データ加工についてはSPSS Modeler上で行う事が出来ますし、読み込み方を変更することでバッチ処理の中に組み込むなどの活用も出来ますのでご紹介させていただきました。

5章 あとがき
拡張のインポートノードを使用する際にデータモデルを毎回作るのが億劫ですが、今回の記事が少しでも使用のハードルを下げることに繋げれば幸いです。
データモデル用の変換表はdtypes関数の全てのデータ型を網羅しているわけではないので、必要に応じて追加しながら使用していただければと思います。
付録(スクリプト)
# ネイティブ Python APIのパッケージ
import modelerpy
import pandas as pd
# CSVファイルを読み込む
df = pd.read_csv("D:/train2.csv") # 適切なファイルパスに置き換えてください
# 修正された変換表を作成
mapping_data = {
'dtypes': ['int64', 'float64', 'object', 'bool', 'datetime64[ns]'],
'StorageType': ['integer', 'real', 'string', 'integer', 'timestamp'],
'Measurement': ['ordinal', 'continuous', 'nominal', 'flag', 'continuous']
}
mapping_df = pd.DataFrame(mapping_data)
# データモデル生成関数
def generate_data_model(df, mapping):
# Convert mapping DataFrame to a dictionary for easier lookup
type_mapping = mapping.set_index('dtypes').to_dict(orient='index')
# Generate modelerpy.Field entries
field_entries = []
for column in df.columns:
dtype = str(df[column].dtypes)
if dtype in type_mapping:
storage_type = type_mapping[dtype]['StorageType']
measurement = type_mapping[dtype]['Measurement']
field_entries.append(
f"modelerpy.Field('{column}', '{storage_type}', '{measurement}')"
)
else:
print(f"Warning: No mapping found for dtype '{dtype}' in column '{column}'")
# Create the dataModel string
data_model = "modelerpy.DataModel([\n " + ",\n ".join(field_entries) + "\n])"
return data_model
data_model_script = generate_data_model(df, mapping_df)
# データモデルの参照時
if modelerpy.isComputeDataModelOnly():
outputDataModel = None
### Compute output data model here
### 出力データモデルの設定
eval_data_model = eval(data_model_script) # 文字列を評価してオブジェクトとして扱う
modelerpy.setOutputDataModel(eval_data_model)
# データ出力時
else:
outputData = None
### ファイルからデータの読み込み
outputData = df
### データの出力
modelerpy.writePandasDataframe(df)