はじめに
なんか最近の流行りっぽいので。
※色々セグフォらせてる記事の一覧は末尾に移動しました。
ということで、Perlでやってみました。環境は適当な x86_64 の Linux です。
どうやるの?
ほらこんなに簡単!
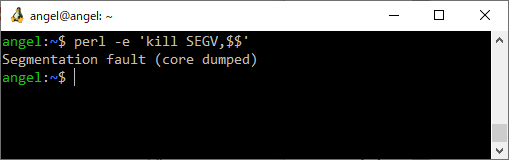
いやそういうことじゃなくて
気を取り直して。
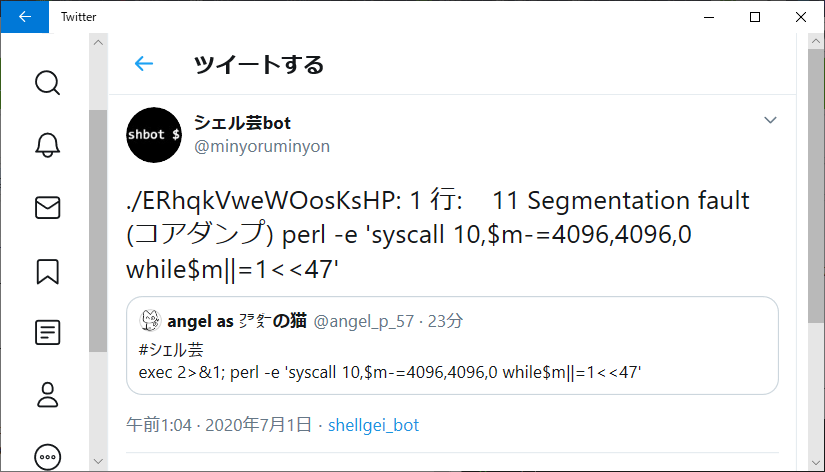
$ perl -e 'syscall 10,$m-=4096,4096,0 while$m||=1<<47'
Segmentation fault (core dumped)
シェル芸botで試すとこんな感じ。こっちでもめでたくセグフォになりました。
なにやってるの?
これをもうちょっと見やすくするとこんな感じです。
require 'syscall.ph';
$m=0x800000000000;
while ( 1 ) {
$m-=0x1000;
syscall &SYS_mprotect,$m,0x1000,0;
}
つまり、さっきのワンライナーは、あるアドレス値を起点として、延々と mprotect システムコールを発行するものだったということです。
※syscallがシステムコールを呼び出す関数で、10 というのが mprotect に相当する番号。
これでどんな効果があるかというと、指定したメモリ領域の保護属性の変更です。
第3引数の 0 は、PROT_NONE 相当なので、そのメモリ領域に対する、読み書き・プログラム実行全ての許可が失われます。なので、メモリアクセスした瞬間にSEGVが飛んでくるようになるわけです。
なお、開始アドレスとしている 0x800000000000 は、64bitプロセスのメモリの末尾 ( heap,stack,vdso ) が大体ここの直前に配置されることから決めてます。
$ perl -e 'system "cat","/proc/$$/maps"'
7f11879f0000-7f11879f9000 r-xp 00000000 00:00 121160 /lib/x86_64-linux-gnu/libcrypt-2.27.so
7f11879f9000-7f11879fa000 ---p 00009000 00:00 121160 /lib/x86_64-linux-gnu/libcrypt-2.27.so
7f11879fa000-7f1187bf8000 ---p 0000000a 00:00 121160 /lib/x86_64-linux-gnu/libcrypt-2.27.so
(略)
7f1188c00000-7f1188df7000 r-xp 00000000 00:00 135847 /usr/bin/perl
7f1188df7000-7f1188df8000 r-xp 001f7000 00:00 135847 /usr/bin/perl
7f1188ff8000-7f1188ffe000 r--p 001f8000 00:00 135847 /usr/bin/perl
7f1188ffe000-7f1189000000 rw-p 001fe000 00:00 135847 /usr/bin/perl
7fffbe41b000-7fffbe45d000 rw-p 00000000 00:00 0 [heap]
7fffc523e000-7fffc5a3e000 rw-p 00000000 00:00 0 [stack]
7fffc6124000-7fffc6125000 r-xp 00000000 00:00 0 [vdso]
もっとやばいの
※7/2追加
もっと面白かったり短かったりする方法はないのかな、と探していてやばいのを見つけてしまいました。
$ perl -e 'unpack p,1x8'
Segmentation fault (core dumped)
…なんじゃこりゃ?? と思い、調べてみました。
まず、unpack というのは pack と対になる組み込み関数であり、端的に言うとデータのシリアライズ ( pack ) と、デシリアライズ ( unpack ) を担当するものです。
これは、単数~複数のデータをまとめて文字列化し持ち運べるようにしたり、また逆に文字列からデータを取り出すために使います。
ここで p は文字列 'p' を裸で指定したものです。これはまとめる/まとめたデータの種類を表すものですが、マニュアルによるとこうあります。
packのマニュアルより:
p ヌル文字で終端する文字列へのポインタ。
…ポインタ?? あなた「ポインタ」言いましたか!?
なんと、こんなところで裸のポインタを使うための機能が隠れているとは。流石Perl。どこで使うんだコレ。
気を取り直して。packで使った場合、どうやら文字列データを保持している内部的なアドレス値をシリアライズして文字列化するようです。次のようにデバッガで見てみると、見事に一致します。
$ perl -e '$x="angel_p_57";print pack "p",$x;close STDOUT;sleep 1200'|od -tx8 & sleep 1
[2] 1067
0000000 00007fffbc94a320
0000010
$ ps -fC perl
UID PID PPID C STIME TTY TIME CMD
angel 1066 12 0 23:53 pts/0 00:00:00 perl -e $x="angel_p_57";print pack "p",$x;close STDOUT;
$ sudo gdb perl
…(略)…
(gdb) attach 1066
…(略)…
(gdb) x/s 0x00007fffbc94a320
0x7fffbc94a320: "angel_p_57"
※x/sコマンドで指定している 0x00007fffbc94a320 というのが、packで生成された文字列の元になったアドレスで、出力させたものを od -tx8 によって16進で見ているわけです。
ということは逆にunpackで使うと、文字列をデシリアライズしてアドレス値として解釈しそこにある文字列の複製を生成する、ということになります。なので、デタラメな文字列を指定すると、即不正メモリアクセスというわけです。
ただ、おそらく x86_64-Linux な Perl だと、アドレス値のデシリアライズには8文字を要するようで、なので 1x8 で 11111111 という文字列を使っています。( xは文字列繰り返しの演算子 )
いや、packにそんな機能があるなんて知らなかったよまだまだPerlも奥が深いな、と思うことしきりでした。
おわりに
意外と不正メモリアクセスを作るのに苦戦し、思いついた手法がコレでした。
メモリ領域自体を不正扱いにしちゃえばいいじゃんと。
その後知った unpack にはPerlの深淵のさわりに触れた感じでした。
何か他にも面白い方法があればぜひ。
なお、セグフォらせてる記事の一覧です。