この記事はJX通信社Advent Calendarの6日目です。
JX通信社で機械学習エンジニアとしてインターンしているandmohikoです。
機械学習でよくある、ニュース記事をカテゴリーで分類するやつをやりました。
偏った学習データにナイーブベイズを使った時に陥る問題とその解決策の話です。
目的
ニュース記事のタイトルからカテゴリーに分類します。
カテゴリーはエンタメ、グルメ、国内、国際、政治、経済、スポーツ、テクノロジーの8つがあります。
手法
ナイーブベイズを使います。
詳しいコードはこちらに載っているので割愛します。
scikit-learnとgensimでニュース記事を分類する
4.機械学習 でRandomForestClassifierを使っているところを、自分はMultinomialNaiveBayesを使いました。
スムージング問題
学習データが大きく偏っていると、カテゴリーの出現頻度を考慮しないよう(class_prior=None)にしても、謎の学習をしてしまう問題があります。俗に言うスムージング問題です。
これは端的に言うとスムージングの値が不適切だからです。
スムージングとはナイーブベイズで未知単語への対処法で、コーパスにない単語も学習データ中に一度は出現したとして扱うために微小な値を加算するものです。
このスムージングの値alphaが大き過ぎても小さ過ぎても発生するのがスムージング問題です。
スムージングが大きいときに、学習データの偏りがあまりにも大きいと、ある単語についてのカテゴリーの尤度の分母が小さく、分子がスムージングによって大きくなってしまいます。
その結果、尤度が逆転し、なぜかそのカテゴリーに出現していない単語ほど、そのカテゴリーの尤度が高くなってしまいます。
これを回避するためにはスムージングを小さくすればよく、小さくすればするほど未知語への誤った学習が軽減されます。しかし、ここで第2の問題が発生します。
スムージングをあまりにも小さくすると、未知語が出現するたびにそのカテゴリーの尤度が大きく下がり、今度は減点されないゲームになってしまいます。
これはこれで問題であり、スムージングを小さ過ぎず大き過ぎない値に設定することが大切です。
例えば、「スーパーで“豊洲”の魚・野菜のセール 新市場オープンで」というタイトルの記事はグルメに分類されるべきですが、
スムージングが小さいと、学習データに登場しなかった「豊洲」という単語へのペナルティが大きくなってしまい、結果的にgourmetよりもmoneyやnationalの対数尤度の方が大きくなってしまっています。
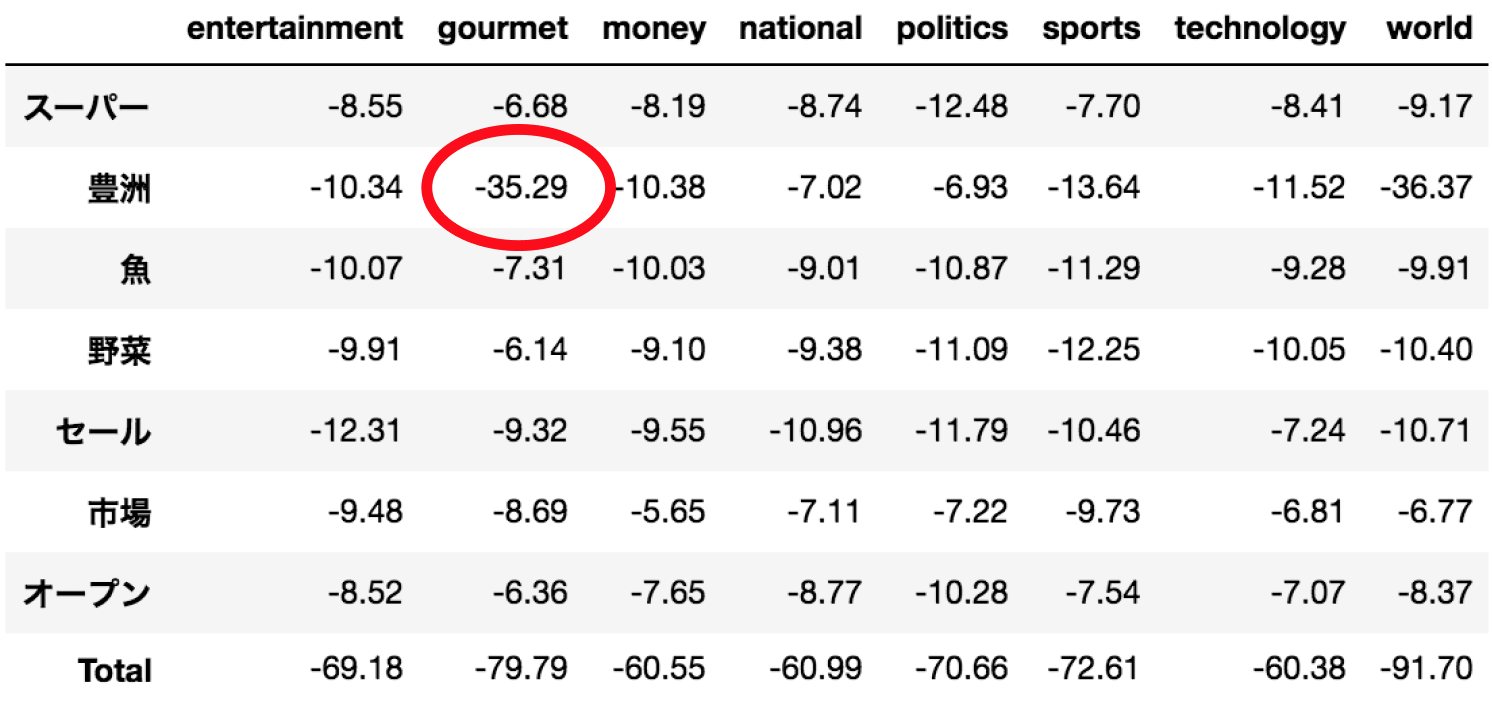
そこで、スムージングを小さ過ぎない値にすることでペナルティーを小さく抑えられ、無事gourmetカテゴリーの対数尤度が最も大きくなりました。

最後に
スムージングは大き過ぎても小さ過ぎてもよくないですね。
そのうち数式で説明したものを書きたいな...