序論
本稿は 元市役所職員がWEBプログラマに転職するまでのロードマップ の連載記事の一部です。
Webの要素
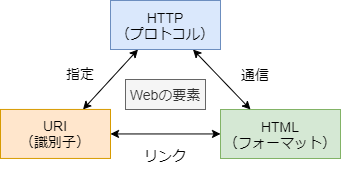
- UI
- 人間向けのインターフェイス
- ハイパーメディア: テキスト、画像等のコンテンツをハイパーリンクで接続したシステム
- ユーザーがリンクを自分で選択できる(非線形的情報取得)
-
Memex, Xanadu, HyperCard: 相互リンク(複雑)<=>Web: 単方向リンク(単純)- Webが普及したのは、そのシンプルさが要因
- API
- プログラム向けのインターフェイス
- 分散システム: 複数のコンピュータで処理を分散することで効率的なプログラム実行を実現(<=> 集中システム)
- RPC(分散関数) < CORBA, DCOM(分散オブジェクト) < REST(分散リソース)
-
SOUP/WS-*: 関数、メソッド単位の呼び出し(粒度小)<=>REST: リソースの状態を呼び出し(粒度大)- 情報の粒度が小さいと呼び出し回数が増えるためオーバーヘッド増大
- Webが成功したのは、オーバーヘッドの小ささが要因
REST
-
Representational State Transfer
- HTTPが転送しているのは、単なるHyperTextだけでなく「リソース状態の表現」であるという主張
RESTの基幹思想
-
接続性
- リソースをリンクで接続することで1つのアプリケーションを構成
- ハイパーメディアとしてのREST
- メディアリソースへURIを通じてアクセス
- 分散システムとしてのREST
- URIを通じてアプリケーションリソース呼び出し
RESTfulな設計
- アドレス指定可能なURIで公開されていること
- インターフェイスの統一がされていること(HTTPメソッドの利用)
- ステートレスであること
-
ステートレス: クライアントのアプリケーション状態をサーバー側で管理しないこと
- メリット: クライアント数が増加してもサーバーのコストは変わらない
- デメリット: リクエストごとにすべての情報をサーバーへ送信するため、通信コストがかかる
- REST的にはCookieを使ったセッション管理は悪
- 毎回情報を送信しなければならないのはコストが高いため、実用上はセッション管理は有用である
-
ステートレス: クライアントのアプリケーション状態をサーバー側で管理しないこと
- 処理結果がHTTPステータスコードで通知されること
URI
-
URI (Uniform Resource Identifier)
- URL(Uniform Resource Locator) + URN(Uniform Resource Name) の総称
-
URL
- Web上で最もよく使われている識別子
- ドメインによりリソースの場所を指定
-
URN
- ドメインを変更するとURLアドレスも変更されるなどの問題点を解決するために検討された使用
- 例) 書籍のISBN:
urn:isbn:9784774142043
URIの基本構造
<URIスキーム>//[[ユーザー名]:[パスワード]@]<IPアドレス or ホスト名>[:[ポート番号]][/[パス]][?[クエリパラメータ]][#[URIフラグメント]]
(例) http://user:pass@example.jp:8000/search?q=test&debug=true#n10
URIの設計指針
- プログラミング言語依存の拡張子を利用しない
- 日本語や英語の指定をするなど、表現指定のための拡張子利用はあり
- 実装依存のパス名を利用しない(cgi-bin, servletなど)
- プログラミング言語のメソッド名を利用しない
- セッションIDを含めない
- リソースを表現する名詞で構成する
URI実装の注意点
- 相対URIと絶対URI
- クライアント側で相対URIを解決するのは面倒なので、可能な限り絶対URIで記述する
- %エンコーディング
- ASCII文字以外を含める場合はUTF-8で%エンコーディングするのが基本
- 長さ制限
- InternetExpolorerの制限である2038バイト以内に収めるのが無難
HTTP
-
HTTP (HypertText Trasfer Protocol)
- ハイパーテキスト転送プロトコルとして規定されたプロトコル
- 実際は画像や音楽などコンピュータで扱えるデータは全て転送可能
TCP/IP
HTTPはTCP/IPをベースとする階層型プロトコル
階層型プロトコル
- アプリケーション層: 階層の一番上。メールやDNS等のアプリケーションおよびHTTPを実現
- HTTP, NTP, SSH, SMTP, DNS
- トランスポート層: IPが保証しなかったデータの転送を保証する部分
-
UDP (User Datagram Protocol)
- 送信相手との接続確認を行わず、一方的にパケットを送りつけるコネクションレス型の通信プロトコル
- データの信頼性には欠けるが高速
-
TCP (Transmission Control Protocol)
- 接続先の相手に対してコネクションを張る
- コネクションを使い、データの到達を保証
- 接続先のどのアプリケーションにデータを渡すか決めるのがポート番号
- ポート番号は1~65535
- HTTP: 80番ポート
- HTTPS: 443番ポート
- SSH: 22番ポート(変更可能)
- ポート番号は1~65535
-
UDP (User Datagram Protocol)
- インターネット層: ネットワークで実際にデータをやりとりする部分
-
IP (Internet Protocol)
- 指定したIPアドレスを送り先として、パケット単位(データの基本単位)でデータを送る
- IPはデータを送ることだけを保証し、最終的な送り先まで届くかどうかは保証しない
-
IP (Internet Protocol)
- ネットワークインターフェイス層: 階層の一番下。物理的なケーブルやネットワークアダプタに相当
- イーサネット
階層型プロトコルの利点・欠点
- 利点
- 構造が単純かつ柔軟
- 各機能の隠蔽と独立したバージョンアップが可能
- 異種ネットワークの相互接続が可能
- 欠点
- 動作時の性能を高くすることができない
- カプセル化処理によるメモリ管理・データ管理が困難
OSI基本参照モデルとLAN間接続装置
-
OSI基本参照モデル
- データ通信を7つの層に切り分け、各層の機能を規定したもの
-
LAN間接続装置
- 装置と装置、ネットワークとネットワークをつなぐジョイントの役割を果たす装置
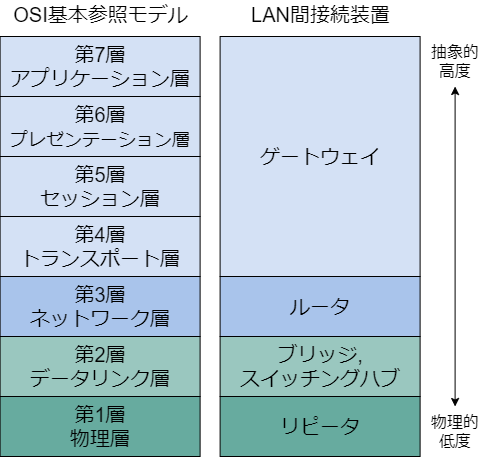
-
ゲートウェイ
- プロトコルの異なるネットワーク同士を接続する装置
- 例: 電話回線とインターネットなど
-
ルータ
- 特定の端末に宛てたデータ(=パケット)を、IPアドレスを基にして中継する装置
- ネットワーク同士をつなぎ、複数のルータを経由してデータを別のネットワーク上にある端末に届けることができる
-
IPアドレス
- ネットワークに接続する機器を一意に識別するためのアドレス
-
ブリッジ, スイッチングハブ(レイヤ2スイッチ)
- 特定の端末に宛てたデータ(=フレーム)を、MACアドレスを基にして中継する装置
- 接続された端末同士は、1つのネットワーク(セグメント)を構成する
-
MACアドレス (Media Access Control address)
- ネットワークに接続するための装置やカードに書き込まれた48ビット長の固有アドレス
- 前半24ビット(
XX:XX:XX)がベンダID、後半24ビット(YY:ZZ:ZZ)が機種IDとシリアル番号を表す -
ARP (Address Resolution Protocol)
- IPアドレスに対応するMACアドレスを取得するプロトコル
-
リピータ
- 物理層レベルで機器を接続し、信号を増幅してネットワークの伝送距離を延長する装置
IPについて
-
サブネットマスク
- ネットワークを、より小さい規模の複数のネットワークに分割するためのビット列
-
DHCP (Dynamic Host Configuration Protocol)
- IPアドレスの割り当てなどのネットワーク設定作業を自動化するためのプロトコル
-
NAT (Network Address Translation)
- グローバルIPアドレスとプライベートIPアドレスを1対1で結びつけて、相互に変換を行う機器
- 同時にインターネット接続できるのは、グローバルIPアドレスの個数分のみ
-
NAPT (Network Address and Port Translation)
- グローバルIPアドレスに複数のプライベートIPアドレスを1対多で結びつけて変換を行う機器(IPマスカレードとも呼ぶ)
- 1つのグローバルIPアドレスに対して複数のコンピュータが同時にインターネット接続可能
- IPアドレスのクラス: IPアドレスは使用するネットワーク規模によって大まかに3つのクラスに分けられる
-
クラスA
- 大規模ネットワーク用:
0.0.0.0〜127.255.255.255 [ネットワーク部8ビット(0.......); ホストアドレス部24ビット]- ネットワーク部の最大値:
01111111 = 127 - ホスト部:
224 - 2 = 16,777,214台に割り当て可能- ※ ホスト部が全て0のアドレスはネットワークアドレスに予約されているため除外
- ※ ホスト部が全て1のアドレスはブロードキャストアドレスに予約されているため除外
- 大規模ネットワーク用:
-
クラスB
- 中規模ネットワーク用:
128.0.0.0〜191.255.255.255 [ネットワーク部16ビット(10......); ホストアドレス部24ビット]- ネットワーク部の最大値:
10111111 = 191 - ホスト部:
216 - 2 = 65,534台に割り当て可能
- 中規模ネットワーク用:
-
クラスC
- 小規模ネットワーク用:
192.0.0.0〜223.255.255.255 [ネットワーク部24ビット(110.....); ホストアドレス部8ビット]- ネットワーク部の最大値:
11011111 = 223 - ホスト部:
28 - 2 = 254台に割り当て可能
- 小規模ネットワーク用:
-
クラスA
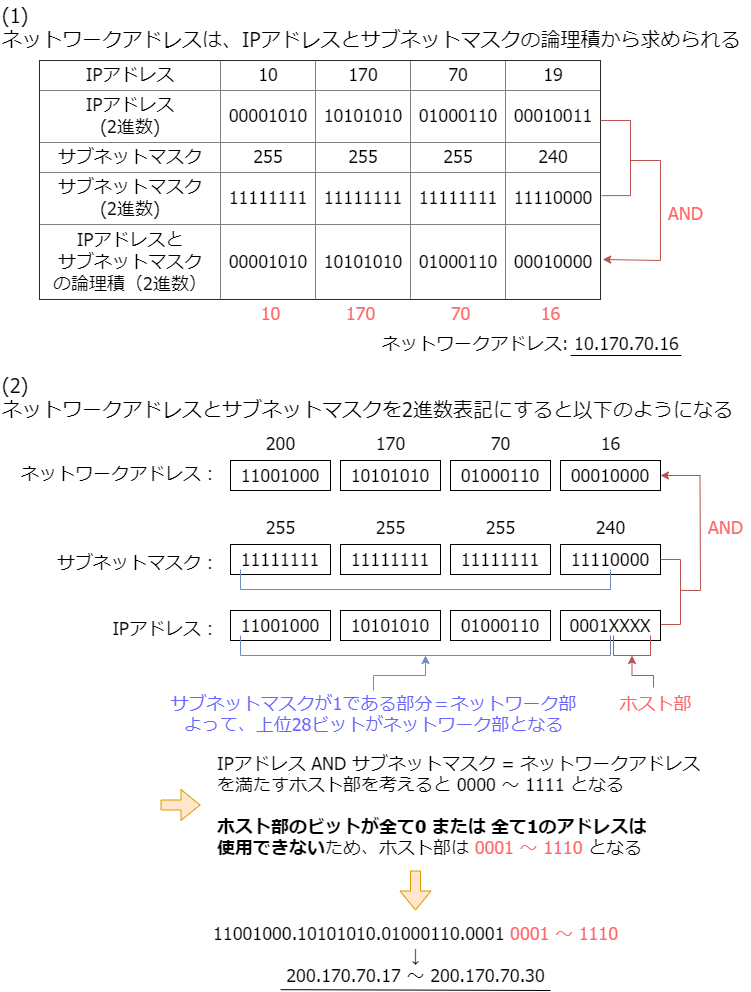
IPアドレス演習
- 以下のPCのネットワークアドレスを求めよ
- IPアドレス:
10.170.70.19 - サブネットマスク:
255.255.255.240
- IPアドレス:
- 以下のネットワークにおいて割り当て可能なIPアドレスの範囲を求めよ
- ネットワークアドレス:
200.170.70.16 - サブネットマスク:
255.255.255.240
- ネットワークアドレス:
HTTPメッセージ
リクエストメッセージ
# 基本構造
<メソッド> <URI> <プロトコルバージョン> # リクエストライン
<ヘッダ> # ヘッダ: メッセージのメタデータ。複数行指定可能
(空行)
[ボディ] # ボディ: メッセージの本質的な情報
# 単純な例
GET /test HTTP/1.1
Host: example.jp:8000
# => http://example.jp:8000/test にGETをリクエスト
レスポンスメッセージ
# 基本構造
<プロトコルバージョン> <ステータスコード> <テキストフレーズ> # ステータスライン
<ヘッダ>
(空行)
[ボディ]
# 単純な例
HTTP/1.1 200 OK # リクエストが正常に処理されたことを示す
Content-Type: application/xhtml+xml; charset=utf-8 # レスポンスのメディアタイプと文字エンコーディングを指定
(空行)
<html xmls="http://www.w3.org/1999/xhtml">
...
</html>
HTTPメソッド
HTTP1.1で定義されているメソッド
| メソッド | CRUDとの対応 | 意味 |
|---|---|---|
| POST | Create | 子リソースの作成、データの追加等 |
| GET | Read | リソースの取得 |
| PUT | Update | リソースの更新 |
| DELETE | Delete | リソースの削除 |
| HEAD | リソースヘッダ(メタデータ)の取得 | |
| OPTIONS | リソースがサポートしているメソッドの取得 | |
| TRACE | プロキシ動作の確認 | |
| CONNECT | プロキシ動作のトンネル接続への変更 |
べき等性と安全性
- べき等性
- ある操作を何回行っても結果が同じこと
- 安全性
- 捜査対象のリソースの状態を変化させないこと(副作用がないこと)
| メソッド | べき等性 | 安全性 |
|---|---|---|
| GET | ○ | ○ |
| PUT | ○ | × |
| DELETE | ○ | × |
| POST | × | × |
HTTPS
-
HTTPS (Secure HypertText Trasfer Protocol)
- HTTP はデータを送受信するためのプロトコルだが、通信中のデータは暗号化されておらず、通信を傍受された場合、データの中身がそのまま盗まれてしまう問題がある
- これは特にパスワードやクレジットカード番号等の個人情報を送信する際に大きな問題となる
- この通信中のデータを SSL/TLS 暗号化させたプロトコルが HTTPS である
- HTTP はデータを送受信するためのプロトコルだが、通信中のデータは暗号化されておらず、通信を傍受された場合、データの中身がそのまま盗まれてしまう問題がある
SSL/TLS
- SSL (Secure Sockets Layer) と TLS (Transport Layer Security) は共に、インターネット上で通信を暗号化し、第三者による通信内容の盗み見や改ざんを防ぐ技術である
- SSLとTLSは、大枠の仕組みは同じもの
- SSLがバージョンアップを重ねて「SSL 3.0」となり、その次のバージョンから「TLS 1.0」という名称で呼ばれるようになった
- SSLの名称はインターネットユーザの間で広く普及しているため、TLSを指していても、SSLまたはSSL/TLSと表記することが多くなっている
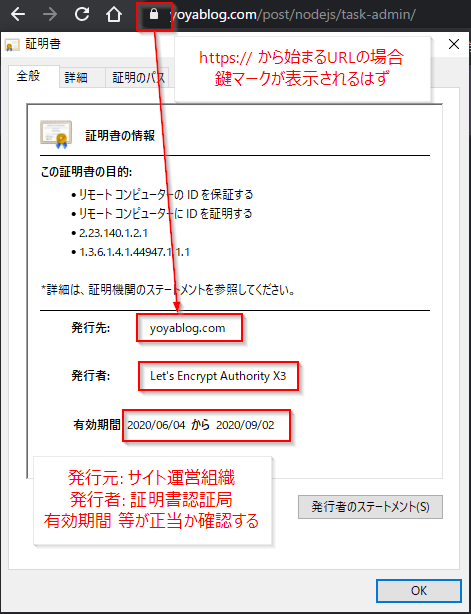
SSLサーバ証明書
- 前述の通り、SSLの名称が広く普及しているため、SSL/TLS技術を利用した電子証明書を一般に SSLサーバ証明書 と呼ぶ
- SSLサーバ証明書とは、情報を暗号化するSSL/TLSの機能に加え、WEBサイトを運営する組織の身元を確認できる機能を備えた電子証明書
- クライアントとWEBサーバ間のデータ通信の暗号化
- SSLサーバ証明書のお申込み準備の際、SSL/TLSを導入するサーバで「公開鍵」と「秘密鍵」を生成する
- クライアント(ブラウザなど)はSSLサーバ証明書に含まれる「公開鍵」を利用して入力情報を暗号化し、サーバにリクエストデータを送信する
- データがサーバに到着した後は、サーバ側で保管している「秘密鍵」を使ってデータ復号を行い情報を解読する
- WEBサイト運営組織の身分証明
- サーバとクライアント(ブラウザなど)がSSL/TLSによる通信を始めるときは、まずサーバが「SSLサーバ証明書」をクライアントに送信する
- クライアントはその証明書を調べ、次のことを確認する
- 証明書が正しい「認証局」(DigiCert, GlobalSign, Let's Encrypt 等)から発行されているか
- 今通信しているサーバが、証明書に記載されているサーバと一致しているか
- 正しいサーバであると確認できれば、安心して通信を始めることができる
- クライアントとWEBサーバ間のデータ通信の暗号化
SSH
-
ssh (Secure Shell)
- 遠隔からコンピュータを操作するためのコマンドラインインターフェイス
- サーバコンピュータを操作する場合は基本的にこのシェルを使ってコマンドを実行する
- 公開鍵暗号と秘密鍵暗号を組み合わせて通信経路を暗号化し、パスワードなどの認証情報や入力されるコマンド、出力された処理結果などをすべて暗号化して送受信することが可能
-
sshd (ssh daemon)
- UNIX系OSなどで、外部からの ssh による接続を受け付ける常駐プログラムのことを慣習的に sshd と呼ぶ
- sshd は ssh クライアントからの接続要求を受け付け、通信経路の暗号化や利用者の認証、操作コマンドの受信と実行などを行なう
-
scp (secure copy / secure copy protocol)
- ネットワークを介して別のコンピュータを操作するsshの機能の一つで、手元のコンピュータとの間でファイルをコピーするもの(およびそのプロトコル)
- scp は ssh 上でのファイルコピー機能で、接続先のコンピュータとの間で安全にファイルの送受信が行える
- scp のコマンドの形式などはUNIXの標準ファイルコピーコマンドである
cpやrcpとほぼ同じで、これらと同じ感覚で使うことができる - 一方、ssh 上でファイル転送を行なうコマンドおよびプロトコルには SFTP と呼ばれるものもあり、これは FTP に似たコマンド体系で操作することができる
FTP, FTPS, SFTP の違い
-
FTP (File Transfer Protocol)
- ファイル転送専用のプロトコルで、FTPサーバを別途構築する必要がある
- クライアント側 (自分のパソコン) からFTPサーバーへファイルをアップロードしたり、逆にファイルをダウンロードしたりする事ができる
- FTP は HTTP より古くから使用されているプロトコルのためセキュリティのことをあまり考慮されていない
- 通信されるファイルデータが平文のままで暗号化されていない
- FTPサーバーにログインするために用いる「ユーザー名」「パスワード」も平文でやりとりされる
- そのため FTP のセキュリティ対策用に作られたのが FTPS・SFTP である
-
FTPS (File Transfer Protocol over SSL/TLS)
- FTPS は HTTPS と同じ SSL/TLS の暗号化・認証が使われている
- HTTP に対する HTTPS, FTP に対する FTPS のイメージ
- あくまで FTP の拡張であるため、FTPサーバを別途構築する必要がある
- そのため、構築の手間が最もかかる
- FTPS は HTTPS と同じ SSL/TLS の暗号化・認証が使われている
-
SFTP (SSH File Transfer Protocol)
- SSHで暗号化されて作られた通信路を通って安全にファイル送受信を行うプロトコル
- 現在は、SSHの標準機能として付属しているため、基本的にSFTPのみ使っておくのが安全で簡単である
- 別途FTPサーバを建てる必要のある FTP, FTPS をあえて選択する意味はあまりない
- FTP, FTPS を選択する場面があるとすれば、ファイル転送に使うクライアントソフトウェアに制限がある場合である
ドメイン
ドメインと名前解決
-
名前解決
- ドメイン名をIPアドレスに変換する仕組みのこと
- 名前解決が必要な理由
- サーバーやPCには、コンピュータを識別するための番号である「IPアドレス」が割り振られている
- IPアドレスは
123.45.67.89などのように数字を.で区切ったものである
- IPアドレスは
- ホームページやメールを利用するとき、このIPアドレスを指定すると直接サーバーにアクセスすることができる
- しかし、全てのIPアドレスを覚えておくのは現実的ではないため、ドメイン名の名前解決という仕組みが使われる
- サーバーやPCには、コンピュータを識別するための番号である「IPアドレス」が割り振られている
hostsファイル
- 1970年代、今のインターネットの原型となったARPAnet(Advanced Research Projects Agency:米国国防総省高等研究計画局)では、名前解決に
HOSTS.TXTというテキスト・ファイルを利用していた- UNIX/Linux の
/etc/hostsファイルは、その名残である - Windows OS にも
%Systemroot%\System32\drivers\etc\hostsという形で残されている - ローカルWEB開発時には今もこのファイルを利用して名前解決することが多い
- UNIX/Linux の
-
HOSTS.TXTのフォーマット127.0.0.1 localhost 211.2.246.25 ITPRO-WWW- 1行に「IPアドレス」と「ホスト名」の対が記載されている
- 現在UNIXなどで使用している hosts ファイルとフォーマットはほぼ同じ
- このファイルを自分のマシンに置いておけば、使用するアプリケーション(ブラウザ)が
HOSTS.TXTに全文検索をかけて、指定したホスト名に対応するIPアドレスを読み込み、そのIPアドレスに接続しようとする - ARPAnet上のすべてのホスト情報を収めた
HOSTS.TXTは、Stanford Research Institute(SRI)の Network Information Center(NIC)によって管理されていた- ARPAnetに新しいホストが加わると、その情報を、NICが
HOSTS.TXTに反映していた - そして、最新の
HOSTS.TXTを、「SRI-NIC」というホストに置き、必要な人間(ほかのホストと通信をするために、名前解決をしたいユーザー)は、SRI-NICから最新のHOSTS.TXTをFTP(File Transfer Protocol)で取得して、自分のホストに置くという流れで名前解決を行っていた
- ARPAnetに新しいホストが加わると、その情報を、NICが
- 当初、ARPAnetには、わずか数百台のホストしかなかったため、ネット上のホスト情報すべてを、1つの
HOST.TXTファイルに記載しておくことが可能だった - しかし、ARPAnetが現在のインターネットに近い形になった1983年には、ホスト数はおよそ数万台で、SRI-NICのFTPサービスは完全な過負荷状態になっていた
- 上記のような経緯により、現在ドメインの名前解決は DNS サーバによって行われる形となった
hosts ファイル演習
実際に hosts ファイルを書き換えて、名前解決の仕組みを体感する
-
Chrome 等の任意のブラウザで http://www.google.com にアクセス
- 普通にGoogleホームページが表示される
-
Public DNS Server List の中からHTTPアクセスできそうなIPアドレスをピックアップする
- ここではフランスのWEB広告会社のサイトらしき
91.121.143.182を選択 - 上記IPアドレスはずっと接続可能である保証はないため、必ず「Recentrly checked」の一覧にあるIPアドレスを選ぶこと
- ここではフランスのWEB広告会社のサイトらしき
-
hosts ファイルに「www.google.com」と「ピックアップしたIPアドレス」を紐づける設定を記述する
-
Win + X|>A=> 管理者権限 PowerShell 起動: 以下のコマンドを実行
-
# hosts ファイルに IP と ドメイン名 の紐づけ設定を追記(メモ帳で編集)
## - IP: 今回は 91.121.143.182
## - ドメイン名: www.google.com
## Windows の hosts ファイル: C:\Windows\System32\drivers\etc\hosts
> notepad C:\Windows\System32\drivers\etc\hosts
### <hosts>
# 以下の行を追記
91.121.143.182 www.google.com
### </hosts>
# hosts ファイルの設定をシステムに反映
> ipconfig /flushdns
-
再びブラウザで http://www.google.com にアクセス
- 強制的に https:// にリダイレクトされてしまう場合は、シークレットモード等でアクセスしてみる
- Googleホームページではなく、ピックアップしたIPアドレスのサイトが表示されるはず
- このままだとGoogleが使えなくなってしまうため、再び hosts ファイルを編集して、紐づけ設定を削除しておく
DNS (Domain Name System)
- DNSは、
HOSTS.TXTによるドメイン名前解決の一元管理の問題点を解決するために作られたシステム - DNSは、ルートゾーンを起点としたツリー構造を持つ、世界中に存在する多数のサーバが協調しあって動作する分散データベース
- これらのDNSサーバ群にアクセスすることで、ホスト名からIPアドレスを検索したり、メールアドレスから送信先メールサーバを特定したりする
- DNSでは、ある特定のサーバ1台がドメイン名情報をすべて持っているわけではなく、「委任」と呼ばれる仕組みでデータを階層ごとに分散化し、併せてサーバの冗長化を実現している
- DNSクライアントがデータを得るときは、この委任をルートゾーンから順次たどっていくことで、最終的に必要な情報を得る
- 名前解決で起点となるルートゾーンを管理するサーバは「ルートネームサーバ」と呼ばれ、世界に13機存在する
DNSルートゾーンのデータベース例
| ドメイン | 種別 | 値 (IPアドレス) | TTL |
|---|---|---|---|
| com. | NS | a.gtld-servers.net. | 172800 |
| com. | NS | b.gtld-servers.net. | 172800 |
| com. | NS | c.gtld-servers.net. | 172800 |
| : | : | : | : |
| a.gtld-servers.net. | A | 192.5.6.30 | 172800 |
| b.gtld-servers.net. | A | 192.33.14.30 | 172800 |
| c.gtld-servers.net. | A | 192.26.92.30 | 172800 |
| : | : | : | : |
DNSキャッシュサーバ
- 名前解決の際、検索の起点となるルートネームサーバには、検索のたびに問い合わせがされることになる
- そうするとDNSの名前解決を行う世界中のクライアントPCから、ルートサーバへ大量の問い合わせがきてしまう
- クライアントPCから見た場合、名前解決のたびに多数のサーバに対して問い合わせを行い、その回答を待つのに時間がかかる
- 上記問題を軽減するため、DNSではキャッシュと呼ばれる仕組みによって、手順を簡略化することができるようになっている
- 例えば、クライアントPCがすでに
www.example.jpのIPアドレス情報を得ている場合、それを再利用することで、名前解決の手順を省略できる - 同様に、クライアントPCとDNSサーバの間に、名前解決済みの情報を保持する DNSキャッシュサーバ を置くことで名前解決を高速化している
- 例えば、クライアントPCがすでに
DNSキャッシュとTTL
- DNSは分散データベースであり、そのデータは任意のタイミングで変更される可能性がある
- そのため、クライアントPCやキャッシュサーバが手元に残したキャッシュをずっと使用していると、実際の状態と不整合が起きる
- 上記問題を解決するため、DNSでは「どのくらいの期間までキャッシュとして利用してよいか」という、TTL (Time To Live) と呼ばれるパラメータが、それぞれのデータ(レコード)に設定されている
レコードの書き換えとキャッシュ
- TTLの仕組みにより、定期的にキャッシュが更新されることになっているが、タイミングによっては古い情報を参照してしまう場合があるため、レコード書き換えの際に戸惑ってしまう例が散見される
- 例えばWEBサイトを運営しているサーバを新しくする際は、ドメインとIPアドレスの紐づけを切り替える必要がある
- こういった場合、経由するキャッシュサーバが、TTL 期間中のキャッシュ(古い情報)をもっていると、サーバが切り替わっていないように見える
- この問題は、DNS切り替え(ドメインとIPアドレスの紐づけ設定の更新)前に、TTL を十分短くしておくことである程度軽減できる
DNS切り替えの浸透期間という迷信
- ネット上の情報の中には「DNS切り替えが浸透するのに最大で3日以上かかる場合がある」などのようなデマ情報もある
- これは、DNSキャッシュと TTL の仕様をよく分かっていない人間が広めた迷信である
- 大昔のDNSキャッシュサーバの中には TTL キャッシュ期間を守らず、ずっとキャッシュを保持しているようなサーバもあったため、そういった事情も絡んでいるかもしれない
- 現在のDNSキャッシュサーバは、基本的にちゃんと TTL を守ってキャッシュを保持しているため、DNS切り替えに TTL 期間以上の時間かかることはない
- DNS切り替えの際は、世界の主要なDNS(キャッシュ)サーバの参照しているデータを確認するのが良い
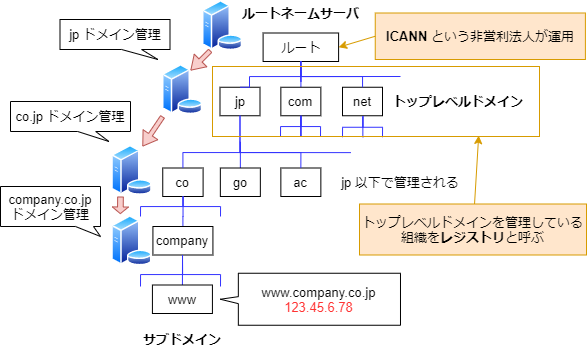
レジストリとレジストラ
-
レジストリ
- トップレベルドメイン(
.com,.net,.jpなど)を管理・運用している元締め組織 - 1,000以上あるトップレベルドメインごとにレジストリが存在する
- レジストリは ICANN から認定を受ける必要がある
- ICANN: 全世界のドメインとIPアドレスを統括するアメリカの非営利法人
-
レジストリの役割
- 申請要求のあったドメイン名に空きがあるかどうか確認し、新規発行する
- ドメイン名とドメイン申請者の関連情報を レジストリデータベース として管理する
- このデータベースは WHOIS 情報と呼ばれる
- DNSデータベースとは別物なので注意
- DNSサーバも運用しており、名前解決要求が来た際は、上位のルートネームサーバに問い合わせを行う
- トップレベルドメイン(
-
レジストラ
- ドメインを一般ユーザーに向けて販売する業者(お名前.com や ムームードメイン など)
- 活動する際は ICANN と契約を結ぶ必要がある
- レジストラは契約しているレジストリのデータベースに直接情報の問い合わせをする権限もっている
- レジストラはドメインの販売価格やオプションサービスを自在に決められ、一般ユーザー側は都合の良いレジストラを選んで購入する
- ドメインを一般ユーザーに向けて販売する業者(お名前.com や ムームードメイン など)