はじめに
「自動運転シミュレーション」は車を壁や他の車に衝突させないように運転させる学習環境です。
車が壁やほかの車に衝突するとエピソードが完了し、長く運転し続けた方が報酬が多くなるように設定している。
使ったもの
- ML-Agents(https://unity3d.com/jp/machine-learning)
- AnacondaNavigator(https://anaconda.org/anaconda/anaconda-navigator)
- 自動運転車の3Dモデル(https://assetstore.unity.com/packages/3d/vehicles/land/car-20128)
方法
学習実行のコマンド
※MacでUnity ML-Agentsの環境を構築する(v0.5.0対応)を参照
AnacondaNavigatorから作成した環境のTermialを起動する。
Terminal上で .../ml-agents-master/ml-agentsまで移動して、
$mlagents-learn trainer_config.yamlのパス --env=hoge1 --run-id=hoge2 --train
hoge1はUnityでBuildした実行ファイルの名前。ただし、拡張子(.exe, .app)は抜く。
hoge2は出力される学習モデル(ml-agents-master/ml-agents/models/hoge2-0/hoge1_hoge2.bytes)の名前。
ソースコードの構成
- CarAcademy.cs:Academy(Academy.csのオーバーライド)
- Brain.cs:Brain(ML-Agents/Scripts/Brain.cs)
- CarAgent.cs:Agent
- RayPerception.cs:Agentの衝突判定(ML-Agents/Examples/SharedAssets/Scripts/RayPerception.cs)
ソースコードの詳細
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using MLAgents;
public class CarAcademy : Academy
{
public override void AcademyReset()
{
}
public override void AcademyStep()
{
}
}
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.Sprites;
using MLAgents;
public class CarAgent : Agent {
// 参照
private CarRayPerception rayPer;
private Rigidbody rigidbody;
// 変数
private Vector3 initPosition; //初期位置
private Quaternion initRotation; // 初期向き
private bool crush; //衝突フラグ
//初期化時に呼ばれる
public override void InitializeAgent()
{
// 参照
this.rayPer = GetComponent<CarRayPerception> ();
this.rigidbody = GetComponent<Rigidbody> ();
// 変数
this.initPosition = this.transform.position;
this.initRotation = this.transform.rotation;
}
public override void AgentReset(){
// 車の初期化
this.transform.position = this.initPosition;
this.transform.rotation = this.initRotation;
rigidbody.velocity = new Vector3 (0, 0, 0);
rigidbody.angularVelocity = new Vector3 (0, 0, 0);
this.crush = false;
}
//Stateの取得
public override void CollectObservations(){
float rayDistance = 50.0f;
float[] rayAngles = { 0f, 45f, 90f, 135f, 180f, 110f, 70f };
string[] detectableObjects;
detectableObjects = new string[] { "car", "wall" };
AddVectorObs (rayPer.Perceive (rayDistance, rayAngles, detectableObjects, 1f, 0f));
}
// フレーム毎に呼ばれる
public override void AgentAction(float[] vectorAction, string textAction){
// アクション
//float handle = Mathf.Clamp (vectorAction [0], -1.0f, 1.0f) * 1.5f; //教材のコードでは上手くいかなかった。
float handle = Random.Range(-1.0f,1.0f)*3.0f;
// 車の向きと加速度の指定
this.gameObject.transform.Rotate (0, handle, 0);
this.rigidbody.velocity = this.gameObject.transform.rotation * new Vector3 (0, 0, 20); //速度調整できる。
// 報酬
AddReward (0.001f);
// エピソード完了
if (this.crush)
Done ();
}
// オブジェクト衝突時に呼ばれる
void OnCollisionEnter(Collision collision){
this.crush = true;
}
}
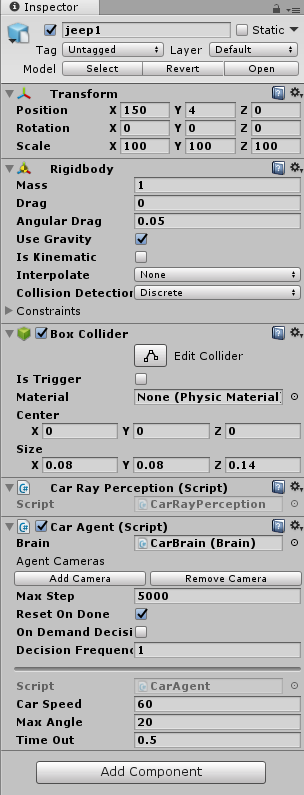
Unityの画面
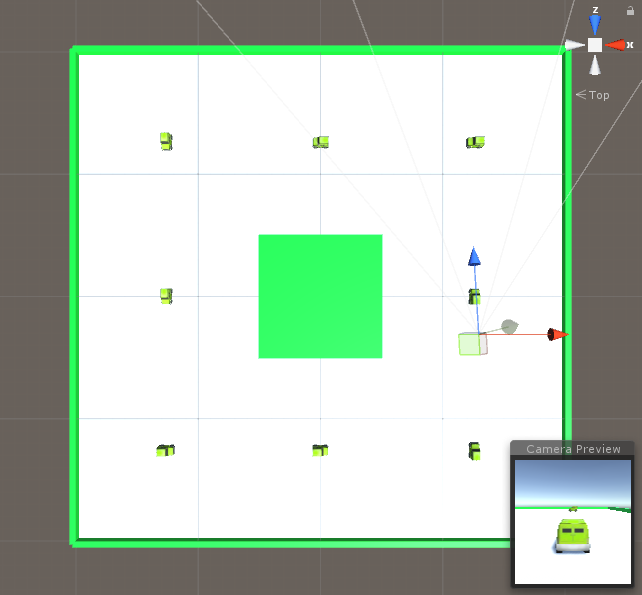
Hierarchy
学習環境内で独立して行動するAgent:jeep
学習環境を管理するAcademy:CarAcademy
Agentが観測した「状態」に応じて、Agentの「行動」を決定するBrain:CarBrain, PlayerBrain
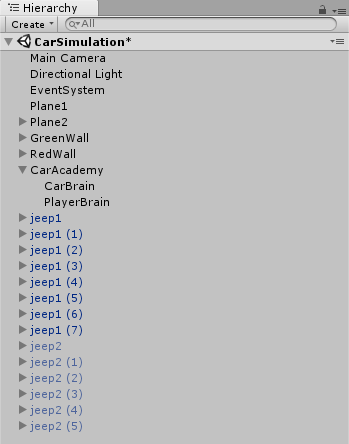
Scene
上から見下ろすと8台のjeepが原点を中心に配置される。
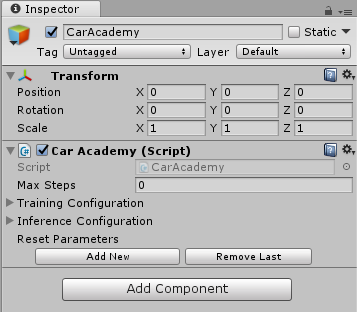
CarAcademy(Academy)
CarAcademy.csを加える。
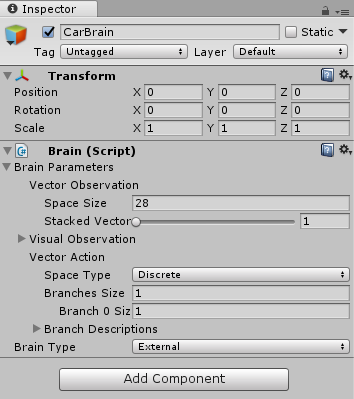
CarBrain(Brain)
Brain.csを加える。
jeep(Agent)
jeepを8台用意する。その内1台のjeepにCameraを加えて実行時の走行の様子を確認する。
また、CarAgent.csとRayPerception.csを加える。CarAgent.csは3つのパラメータを持ち、jeepがCarSpeedの速さでTimeOut秒ごとに最大でMaxAngle度向きを変える。
結果
100000回学習したもの

200000回学習したもの

300000回学習したもの

学習後、Terminalから下のコマンドを打ち込む。
$tensorboard --logdir=summaries
TensorBoard 1.7.0 at http://WINDOWS-1O4MM0L:6006 (Press CTRL+C to quit)が表示されたら、URL(http://WINDOWS-1O4MM0L:6006 )からTensorBoardに移動。
TensorBoardを開くと次のように学習状況のグラフが表示される。
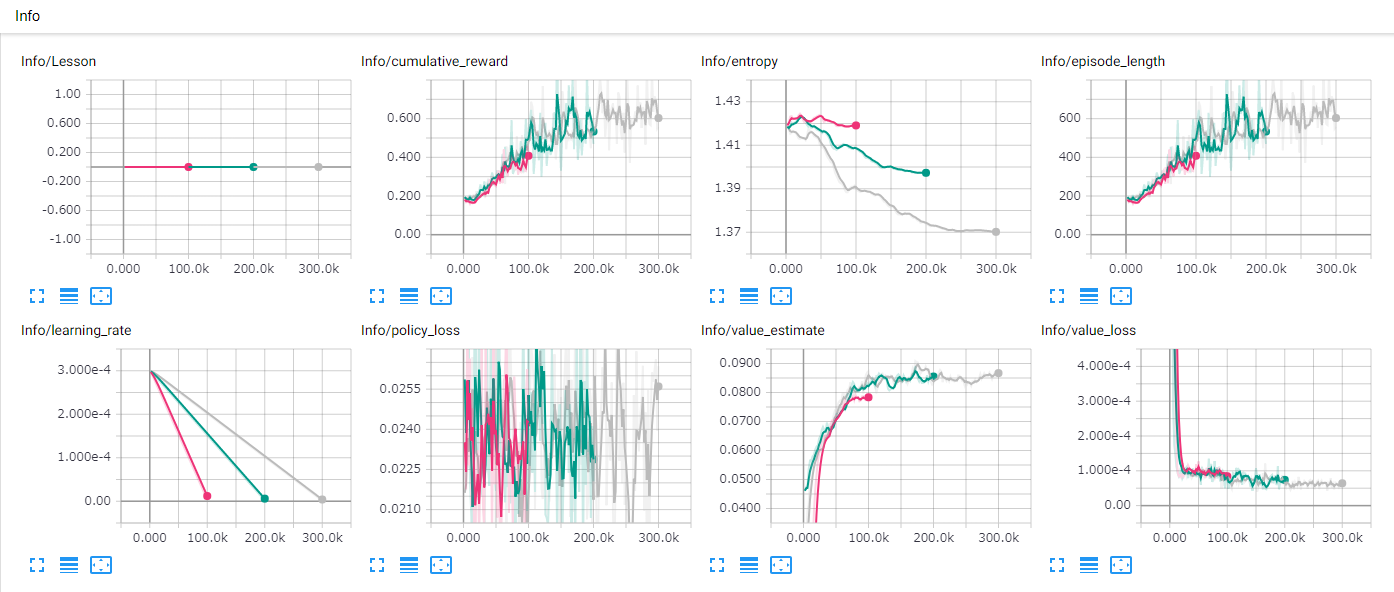
マゼンタ:100000回, 深緑:200000回, シルバー:300000回学習した結果。
以下がそれぞれのグラフの説明。
- Info/Lesson:レッスンの進捗状況(カリキュラム学習)
- Info/cumulative_reward:平均累積報酬のグラフ(継続して増加し上下の振れ幅が小さいことが期待される。)
- Info/entropy:Actionのランダムな動きの割合(継続的な減少が期待される。)
- Info/episode_length:エピソードの平均長(今回は長いほうが良いので増加が期待される。)
- Info/learning_rate:学習率のグラフ(時間とともに継続して減少する。)
- Info/policy_loss:Actionの方策の変化の割合(学習成功時に減少し継続して減少することが期待される。)
- Info/value_estimate:将来の報酬の予測(学習成功時に増加し継続して増加することが期待される。)
- Info/value_loss:将来の報酬予測と実際の報酬の乖離(報酬は安定したら減少することが期待される。)