概要
CoarrayとMPIライブラリを同時に使用して、ファイル入出力を行う方法について言及します。
mpi_init()とmpi_finalize()を呼び出さないことで、CoarrayとMPIライブラリは併用可能です。
すなわち、以下のコードはコンパイル・実行可能です。
program main
use, intrinsic :: iso_fortran_env
use mpi_f08
implicit none
integer(int32) :: rank, petot, ierr
integer(int32) :: array[*]
call mpi_comm_size(mpi_comm_world, petot, ierr)
call mpi_comm_rank(mpi_comm_world, rank, ierr)
print '(a,i2,a,i2,a,i2,a,i2)', &
'this rank is ', rank, ' of ', petot, &
' | this image is ', this_image(), ' of ', num_images()
end program main
-
mpi_comm_size手続きは、その実行のプロセス数を第2引数に格納します。 -
mpi_comm_rank手続きは、そのプロセスのプロセス番号を第2引数に格納します。 -
num_images()関数は、実行されたCoarrayプログラムのimageの総数を返します。 -
this_image()関数は、実行されたCoarrayプログラムの、そのプロセスのimage番号を返します。
上のプログラムを、以下のようにMPIライブラリの存在するディレクトリ(ここでは/usr/lib64)を-Iオプションで指定して、コンパイルします。
% caf main.f90 -I/usr/lib64 -o ./a.out
8プロセスで実行すると、以下の結果が得られます。
% cafrun -n 8 --hostfile ./hosts ./a.out
this rank is 0 of 8 | this image is 1 of 8
this rank is 1 of 8 | this image is 2 of 8
this rank is 2 of 8 | this image is 3 of 8
this rank is 4 of 8 | this image is 5 of 8
this rank is 5 of 8 | this image is 6 of 8
this rank is 6 of 8 | this image is 7 of 8
this rank is 7 of 8 | this image is 8 of 8
this rank is 3 of 8 | this image is 4 of 8
Coarrayを使ってプログラミングをする際にも、既存のMPIで書かれたライブラリを使用することができるのではないでしょうか。
はじめに
本稿では、
- Fortranプログラムの並列化を、【入出力(Input/Output, I/O)】の話題に限定して記述します。
- 分散メモリ型の並列処理を扱います。共有メモリ型(OpenMP等)については言及しません。
- Coarrayの基本的な記法の知識を前提とします。
- コードのコンパイルと実行は、gfortranとIntel oneAPIで確認しました。
- ただしIntelのマルチノードでの実行は未テストです。完了し次第、追記します。
- NAG社のコンパイラーをお持ちの方は、実行結果をコメントで知らせていただけると嬉しいです。
- 動作確認を行った環境は末尾に記載してあります。
並列プログラムと入出力
プログラム並列化の話題においては、計算処理の並列化に焦点があてられることが多いです。しかし他方で、大規模データ(多数または巨大なファイル)を扱う場合は、データ入出力も無視できない処理です。並列プログラムにおいて入出力を扱う方法はいくつか考えられます。
- 「各プロセスで各ファイルに書き込む」方式
- 「1つのプロセスにデータを集約する」方式
- 「複数プロセスから1ファイルにダイレクトにアクセスする」方式
以下では、この3つの方式はどのような特徴があるかを検討し、「入出力を並列化」してボトルネックを解消する方法について考えていきます。
各プロセスで各ファイルに書き込む方式
Coarray変数を使う必要がなく、一番単純な方法です。並列で起動したプロセスがそれぞれ独立に、別のファイルへデータを書き込みます。下の図ではPE1, 2, 3, 4は、それぞれData File 1, 2, 3, 4に対応しています(PEはProcessor Elementの略です)。
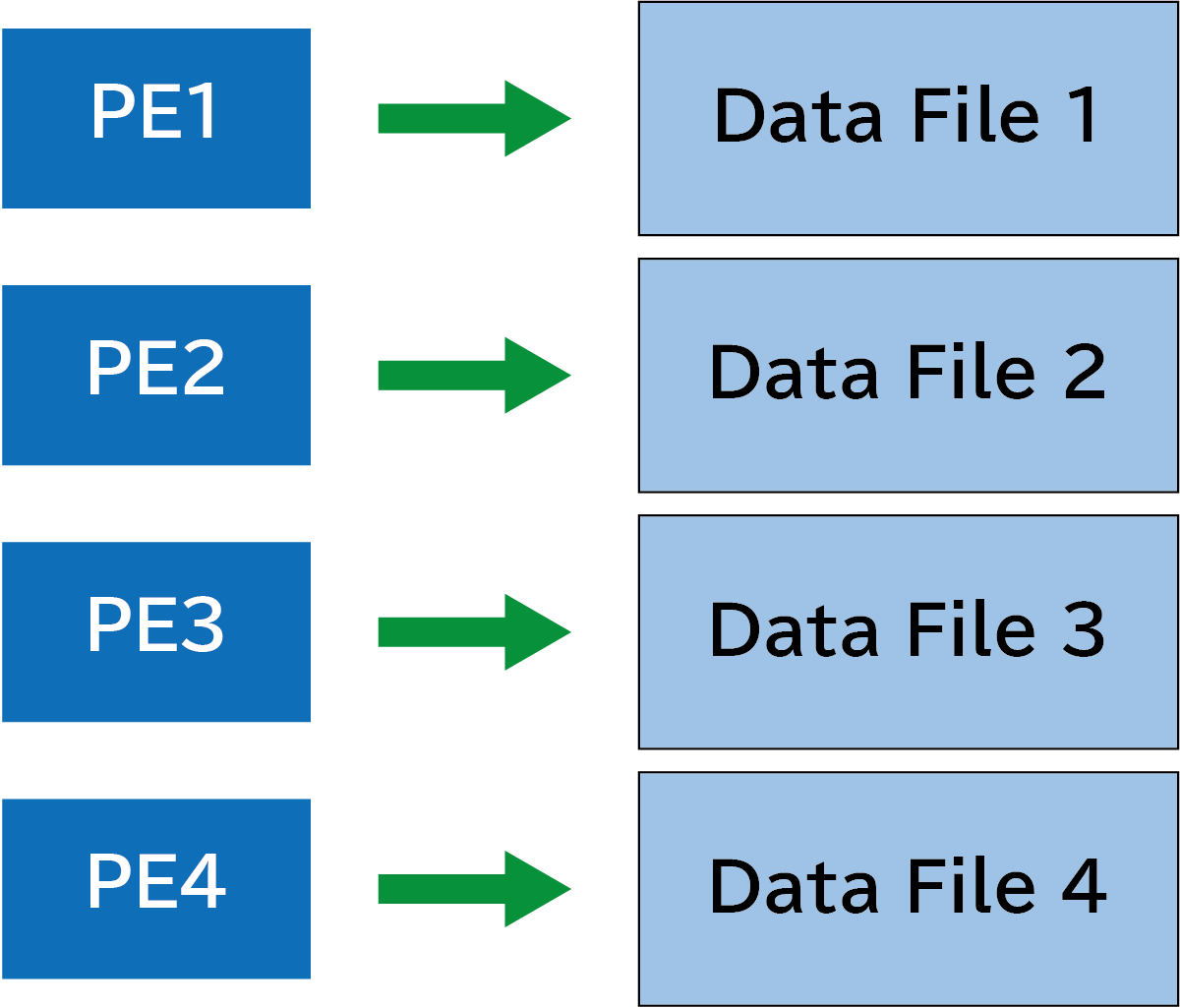
下のようなプログラムを書いてみました。各プロセスでopen文からclose文を実行し、それぞれでファイルに出力しています。
program main
use, intrinsic :: iso_fortran_env
implicit none
integer(int32) :: o_unit
character(len=12) :: filename
write(filename, '(a,i3.3,a)') 'file_', this_image(), '.bin'
open(newunit=o_unit, file=filename, form='unformatted', access='stream', status='replace')
! newunit=o_unit: 装置番号
! file=filename: ファイル名
! form='unformatted': バイナリ形式
! access='stream': C言語ストリーム入出力
! status='replace': 新規ファイルに置き換え
write(o_unit) this_image(), num_images()
close(o_unit)
end program main
上のプログラムを並列数8で実行すると、file_001.binからfile_008.binまでの計8つのファイルが出力されます。一つのバイナリには、関数this_image()とnum_images()の返り値(それぞれ4バイト)が8バイトに渡って格納されています。
% caf main.f90 -o ./a.out
% cafrun -n 8 --hostfile hosts ./a.out
% ls *.bin
file_001.bin file_003.bin file_005.bin file_007.bin
file_002.bin file_004.bin file_006.bin file_008.bin
% hexdump -x file_001.bin
0000000 0001 0000 0008 0000 <- image 1で作られたファイルには1と8が書き込まれている。
0000008
% hexdump -x file_005.bin
0000000 0005 0000 0008 0000 <- image 5で作られたファイルには5と8が書き込まれている。
0000008
この方式は以下のような特徴があります。
- 通信は不要
- スケール可能
- データの一貫性を保持できる
デメリットとして、並列数の増加とともにファイルの数が増えるのでデータの書き込みをした後の処理が必要となります。
1つのプロセスにデータを集約する方式
次に、書き込むデータを1つのプロセスに集約する方法について考えてみます。各プロセスの保持するデータを特定の1つのプロセスに集める必要があります。下図のようにPE2からPE4が持つデータをPE1に転送して、その後にPE1がファイルに書き込みます。
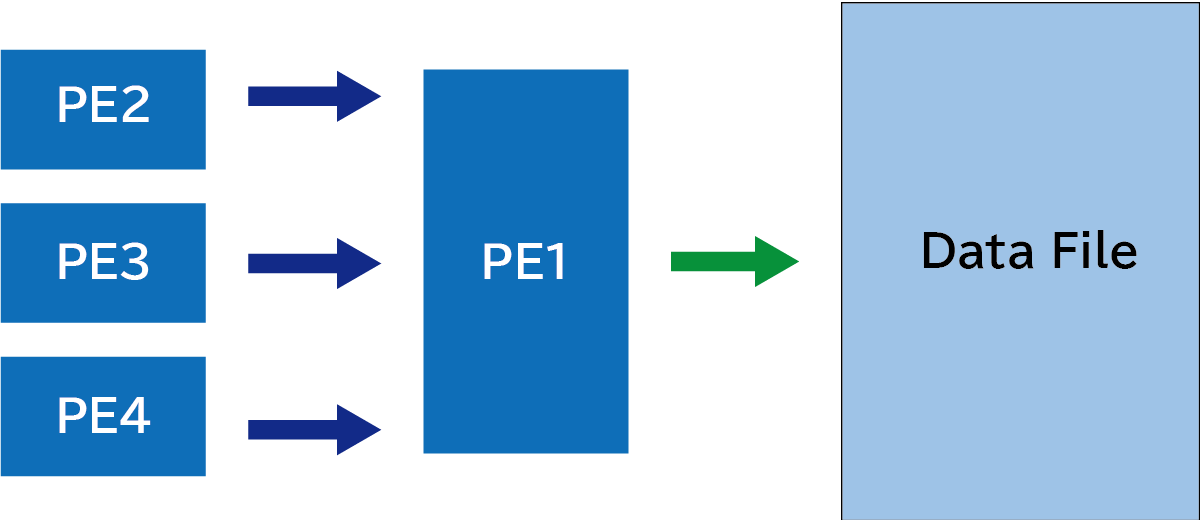
下のコードでは、image 1にのみデータを受け取るための配列recvを用意して、ほかのimageからデータを受け取っています。
program main
use, intrinsic :: iso_fortran_env
implicit none
integer(int32) :: i, o_unit
integer(int32) :: item[*] ! 整数型のCoarray変数
integer(int32), allocatable :: recv(:) ! データを受け取る割付可能な配列
if (this_image() == 1) then
allocate(recv(num_images()))
end if
item = this_image() ! 各imageにおいて、変数itemにimage番号を書き込む
if (this_image() == 1) then
recv(1) = item ! 配列recvの第1要素に、(image1での)itemの値を代入する。
do i = 2, num_images()
recv(i) = item[i] ! MPIで言うところのGather
end do
! ファイル出力
open(newunit=o_unit, file='out.bin', form='unformatted', access='stream', status='replace')
write(o_unit) recv(:)
close(o_unit)
deallocate(recv)
end if
end program main
実行するとファイルout.binを出力します。out.binには4バイト整数が8個、32バイトにわたって格納されています。
% caf main.f90
% cafrun -n 8 --hostfile ./hosts ./a.out
% ls out.bin
out.bin
% hexdump -x ./out.bin
0000000 0001 0000 0002 0000 0003 0000 0004 0000
0000010 0005 0000 0006 0000 0007 0000 0008 0000
0000020
この方法では1個のファイルにまとめられます。Coarrayを使っても簡単に書けるのがメリットで、データの一貫性を保持できます。ただし、次のようなデメリットがあります。
- 大きな変数を用意する必要がある(特定の1プロセスのメモリ割付が過大に)。
- スケールしない。
- データの通信が必要となる。
複数プロセスから1ファイルにダイレクトにアクセスする方式
各プロセスから単一のファイルを直接アクセスする方法です。「直接」とは、書き込むファイルをバイト列としてみなした上で、位置を指定してその場所にデータを書き込みます。下図のように、PE1からPE4がそれぞれ独立に、ただし同じファイルを扱います。
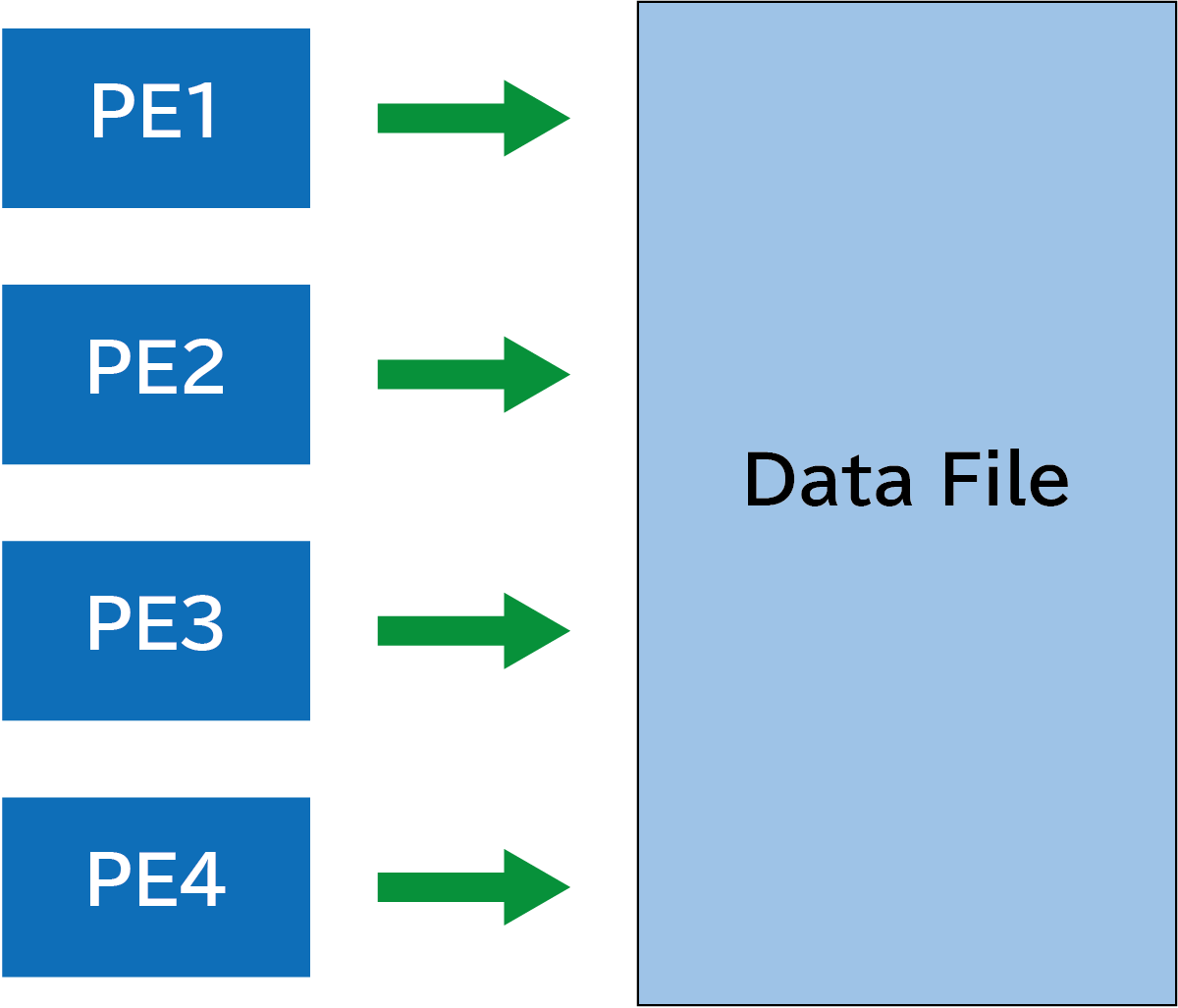
下のコードでは、前処理においてファイルを0xffff(補数表現で-1)で埋めた上で、その後に各プロセスがそれぞれ個別のオフセットだけずらした位置に、2バイト分書き込んでいます。
program main
use, intrinsic :: iso_fortran_env
implicit none
integer(int32) :: length, o_unit
integer(int16) :: a, b(64) ! 2バイト整数
integer(int32) :: rank, petot, ierr, offset
character(len=8), parameter :: file='out.bin'
a = int2(this_image()) ! this_image関数の返り値を2バイト整数に変換して代入する。
b(:) = -1 ! -1 -> 0xffff
! 前処理: ファイルを-1で埋める
if (this_image() == 1) then
open(newunit=o_unit, file=file, form='unformatted', &
access='stream', status='replace')
write(o_unit) b
close(o_unit)
end if
sync all ! 同期する
! -- 前処理ここまで
inquire(iolength=length) a ! 変数aのバイト長さを読み取って変数lengthに格納する
open(newunit=o_unit, file=file, access='direct', recl=length, status='old')
! access='direct': 直接探査ファイル
! recl: record length (1レコードの長さ、バイナリ書き込みの単位)
! 各imageでオフセットをずらして代入する
offset = 1 + (this_image() - 1)*2
! 装置番号o_unitのファイルに、先頭からoffsetバイトずらした位置へ、2バイト整数型変数aの値を書き込む
write(o_unit, rec=offset) a
close(o_unit)
sync all
end program main
このコードを並列数8で実行し、出力を見ると以下のようになります。先頭2バイトには1, そこから2バイトおきにimage番号が書き込まれているのがわかります。
% caf direct.f90 -o a.out
% cafrun -n 8 ./a.out
% hexdump ./out.bin
0000000 0001 ffff 0002 ffff 0003 ffff 0004 ffff
0000010 0005 ffff 0006 ffff 0007 ffff 0008 ffff
0000020 ffff ffff ffff ffff ffff ffff ffff ffff
0000030 ffff ffff ffff ffff ffff ffff ffff ffff
(略)
この方法には
- スケールする
- 通信を避けられる
- ファイルを1個に集約できる
というメリットがありますが、重大なデメリットとしてデータの一貫性を保持できないという問題があります。
注:Intel Fortranにおいては、1バイト単位で入出力をする場合にはコンパイルオプションで-assume bytereclを指定する必要があります(参考文献2)。
MPI I/Oを使う
MPI Input/Output(以下、MPI I/O)とは、MPIバージョン2(1997年)で導入された、並列入出力に関してのAPIを指します。ファイルを直接アクセスするのではなく、MPIで定義された手続きを介して間接的にデータの読み書きを行います。ファイルに直接アクセスする場合と比較して、ブロッキングやコレクティブ処理が充実しているので、一貫性を保持してデータを扱うことができます。
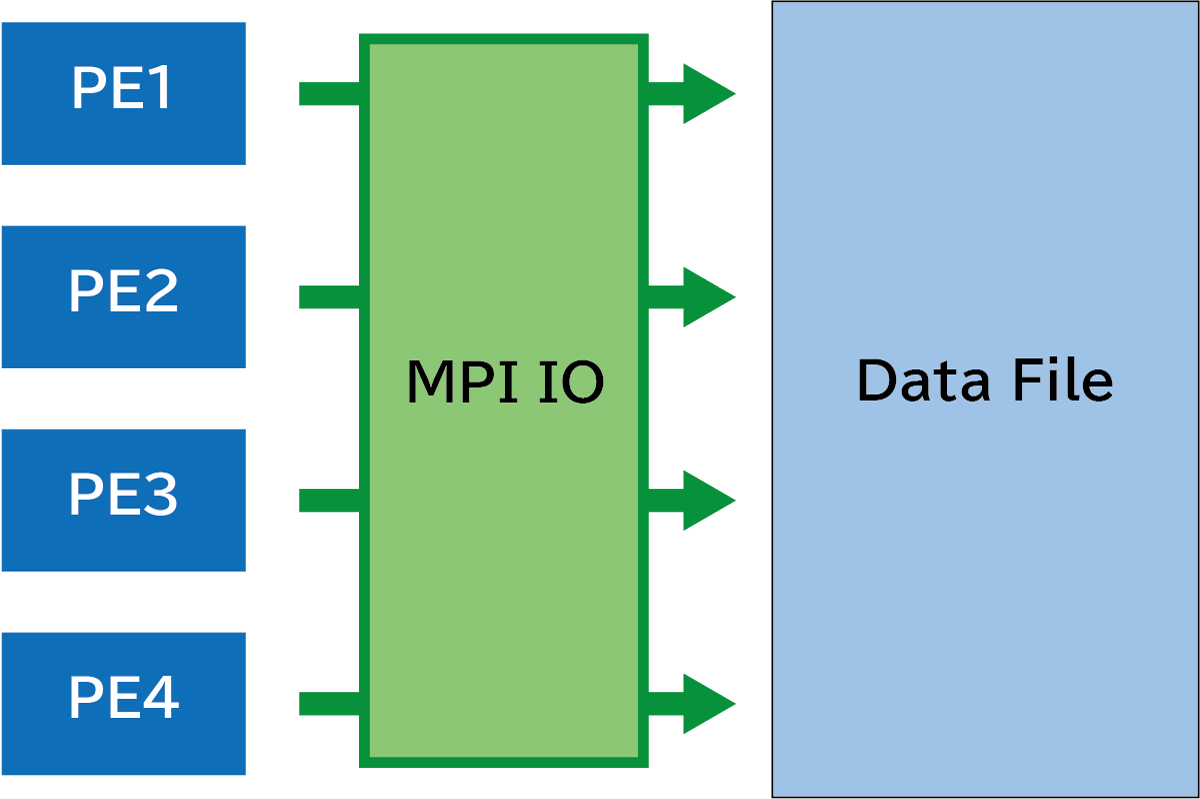
以下のようなコードを書いてみました。
program main
use, intrinsic :: iso_fortran_env
use mpi_f08
implicit none
integer(int32) :: i
character(len=7), parameter :: filename='out.bin'
integer(int32) :: o_unit
integer(int16) :: b(128)
integer(int32), parameter :: count=8
integer(int16) :: buf(count)[*]
! for MPI
integer(int32) :: ierr, amode, whence
integer(mpi_offset_kind) :: offset
type(mpi_info) :: info
type(mpi_file) :: fh
type(mpi_status) :: stat
!-- 前処理開始
b(:) = -1 ! -1 == 0xffff
if (this_image() == 1) then
open(newunit=o_unit, file=filename, form='unformatted', access='stream', status='replace')
write(o_unit) b
close(o_unit)
end if
sync all
!-- 前処理終わり
!-- データ作成開始
! image 1でデータ作成
if (this_image() == 1) then
buf(:) = int2(this_image()) !--> 1
end if
! Coarray変数bufをimage 1からブロードキャストする
call co_broadcast(buf, source_image=1)
! 全プロセスで変数bufの値を加工する
do i = 1, count
buf(i) = buf(i) * 2 * this_image()
end do
sync all
!-- データ作成終わり
!-- I/O処理開始
info = mpi_info_null
amode = mpi_mode_wronly + mpi_mode_create
! ファイルを開く
call mpi_file_open(mpi_comm_world, filename, amode, info, fh, ierr)
offset = 32
whence = mpi_seek_set
! fhのファイルポインターをシークする
call mpi_file_seek_shared(fh, offset, whence, ierr)
! fhのファイルに書き込む
call mpi_file_write_ordered(fh, buf, count, mpi_integer2, stat, ierr)
! fhのファイルを閉じる
call mpi_file_close(fh, ierr)
!-- I/O処理終了
end program main
MPI I/Oの手続きについて、どのような処理かを説明すると次の通りです(詳しくは参考文献3を参照してください)。
-
mpi_file_open手続きは、amodeで指定されたモードで、filenameで指定されたファイルをファイルヘッダーfhに紐づけて開く。 -
mpi_file_seek_shared手続きは、whenceにmpi_seek_setの値が設定されている場合、fhのファイルでの読み書き位置をoffsetの値にシークする。 -
mpi_file_write_ordered手続きは、変数bufのcount個の要素をmpi_integer2の型とみなし、fhの指すファイルにブロッキング処理をしてランクの昇順で書き込む。 -
mpi_file_close手続きは、fhの指すファイルを閉じる。
上のプログラムを並列数8で実行すると、1個のファイルout.binが出力されます。out.binの中身を見ると、最初の32バイトはスキップして、33バイト目から128バイトにわたって加工されたデータが順番に格納されていることが分かります。
% caf main.f90 -I/usr/lib64 -o a.out
% cafrun -n 8 --hostfile hosts ./a.out
% hexdump -xv out.bin
0000000 ffff ffff ffff ffff ffff ffff ffff ffff
0000010 ffff ffff ffff ffff ffff ffff ffff ffff
0000020 0002 0002 0002 0002 0002 0002 0002 0002
0000030 0004 0004 0004 0004 0004 0004 0004 0004
0000040 0006 0006 0006 0006 0006 0006 0006 0006
0000050 0008 0008 0008 0008 0008 0008 0008 0008
0000060 000a 000a 000a 000a 000a 000a 000a 000a
0000070 000c 000c 000c 000c 000c 000c 000c 000c
0000080 000e 000e 000e 000e 000e 000e 000e 000e
0000090 0010 0010 0010 0010 0010 0010 0010 0010
00000a0 ffff ffff ffff ffff ffff ffff ffff ffff
00000b0 ffff ffff ffff ffff ffff ffff ffff ffff
00000c0 ffff ffff ffff ffff ffff ffff ffff ffff
00000d0 ffff ffff ffff ffff ffff ffff ffff ffff
00000e0 ffff ffff ffff ffff ffff ffff ffff ffff
00000f0 ffff ffff ffff ffff ffff ffff ffff ffff
0000100
MPI I/Oによる並列入出力は次のような特徴があります。
- スケールできる
- 通信は明示的に書かなくてもよい
- 一貫性は(直接アクセスと比べて)保持しやすい
MPI I/Oで実装された、並列入出力をサポートするデータ形式にはNetCDFやHDF5などがあります。CoarrayでもMPI I/Oが使えることが分かったので、これらのライブラリも同様にCoarrayと併用できるのではないかと予想しています。
終わりに
Coarrayはプログラミング言語レベルでのデータ並列化を実現しました。しかしながら並列入出力は標準で定義されていないので、この部分についてはMPIのライブラリを使うことが選択肢の一つになると考えます。
筆者は「Coarray vs MPI」という先入観にとらわれていて「Coarray FortranでMPI I/Oを使う」という発想になかなか気付かなかったので、自分のプログラムで入出力の問題を解決するのに随分回り道をしていました(そしてその実装はこれからです)。本記事が皆さんのソフトウェアのアップデートに役立てば幸いです。
余談
- Q.
mpi_initとmpi_finalizeを呼び出さないことで、なぜCoarrayとMPIを併用できるのか?- OpenCoarraysだけでなく、おそらくですがIntel oneAPIも、Coarrayのバックエンドの実装にMPIを用いていると私は予想しています。そのため、プログラム中で生のMPI手続きを記述しても、コンパイルと実行が通るのだと思います。
- Q.
form='formatted'の並列入出力はあるか?- ありません。諦めてバイナリ入出力を使いましょう。
参考文献
- M. Metcalf, J. Reid, M. Cohen, Modern Fortran Explained: Incorporating Fortran 2018, Oxford University Press, 2018, https://doi.org/10.1093/oso/9780198811893.001.0001
- Record Length - Development Reference Guides | Intel Fortran Compiler Classic and Intel Fortran Compiler Developer Guide and Reference
- Open MPI v4.0.7 documentation
動作確認を行った環境
-
クラスター構成について
- 単ノード
- OS: Gentoo Linux (Linux kernel v5.15.59)
- CPU: Intel Core i5-4570 (4コア・4スレッド)
- NIC: Intel PRO/1000 PT Ethernet
- 使用したのは2ノード
- ノード間接続はイーサネット
- ファイルシステムはNFS
- 単ノード
-
コンパイラー等について
-
gfortran
- GNU Fortran コンパイラー
% gfortran --version GNU Fortran (Gentoo 11.3.0 p5) 11.3.0 Copyright (C) 2021 Free Software Foundation, Inc. - OpenCoarrays
% caf --version OpenCoarrays Coarray Fortran Compiler Wrapper (caf version 2.10.0-15-g9123d92) Copyright (C) 2015-2022 Sourcery Institute Copyright (C) 2015-2022 Archaeologic Inc. - OpenMPI
% mpirun --version mpirun (Open MPI) 4.1.2
- GNU Fortran コンパイラー
-
Intel oneAPI
% mpiifort --version ifort (IFORT) 2021.7.0 20220726 Copyright (C) 1985-2022 Intel Corporation. All rights reserved. % mpirun --version Intel(R) MPI Library for Linux* OS, Version 2021.7 Build 20220909 (id: 6b6f6425df) Copyright 2003-2022, Intel Corporation.
-