はじめに
この記事は ちゅらデータ Advent Calendar 2021 6日目の記事です。
5日目の記事はこちら: ちゅらデータで推奨してるフィードバックとラップアップの紹介
背景
とあるプロジェクトにて物体検知技術を利用したアプリケーションを構築することになりました。プロジェクトでは以下の要件をクリアする必要がありました。
- モバイル端末上にてリアルタイムに動画を処理し、特定の物体を検知するシステムを作りたい
- 不特定多数のユーザーを想定しているが、ランニングコストは可能な限り抑えたい
- モデル開発にかけられる期間が限られている
上記要件を踏まえ、プロジェクトではDeep Learningを利用したエッジ向けの物体検知モデルを構築することとなりました。エッジ向けモデルを構築することでクラウドと比較して以下のようなメリットがあります。
- 推論時にサーバとの通信が発生しないため、ネットワークレイテンシが抑えられる
- 一連の推論処理がクライアント側で実施されるため、コストが抑えられる (画像 / 動画のアップロードに伴う費用が発生しない。また、推論用サーバを用意する必要がなくなる)
反面、エッジ向けモデルを開発する際には、動作環境 (e.g. CPU / GPU、メモリ) の制限を鑑みたモデル設計を行ったり、精度とレイテンシのトレードオフを設計したり、サーバ側で動作するDeep Learningモデルを構築するよりも気にすべきポイントが多く発生してしまいます。
なんとかもっとお手軽にモデルを作れないものか、、、そんな状況でおすすめなのが、AutoML Vision Edgeの利用です。
AutoML Vision Edge
Google Cloud AutoML Vision Edgeとは、機械学習モデルの設計や構築を自動的に行うAutoML技術の一つで、エッジデバイス向けの画像分類 / 物体検知に特化した機能を保有しています。
低レイテンシで軽量なモデルをトレーニングし、Edge向けの様々なフォーマットへのエクスポートが可能です。基本的にはGUI操作で非常に手軽にモデル構築が行えるため、低コストでクイックにモデルを構築したいケースにファーストステップとして選ぶには良い選択肢です。
- 対応フォーマット: TensorFlow Lite、TensorFlow.js、Core ML、コンテナエクスポート形式等
- サポート対象のハードウェアアーキテクチャ: Edge TPU、ARM、NVIDIA
百聞は一見にしかずということで、実際にモデル構築を試してみましょう。
AutoML Vision Edgeを利用した物体検知モデル構築
AutoML Vision EdgeはVertex AIに統合されています。
Vertex AIを利用することで、データセットの管理・作成からNotebookを活用したEDA、モデル構築・テスト、運用まで、一連の流れを管理できます。
1. Google Cloud Storage上にデータを用意
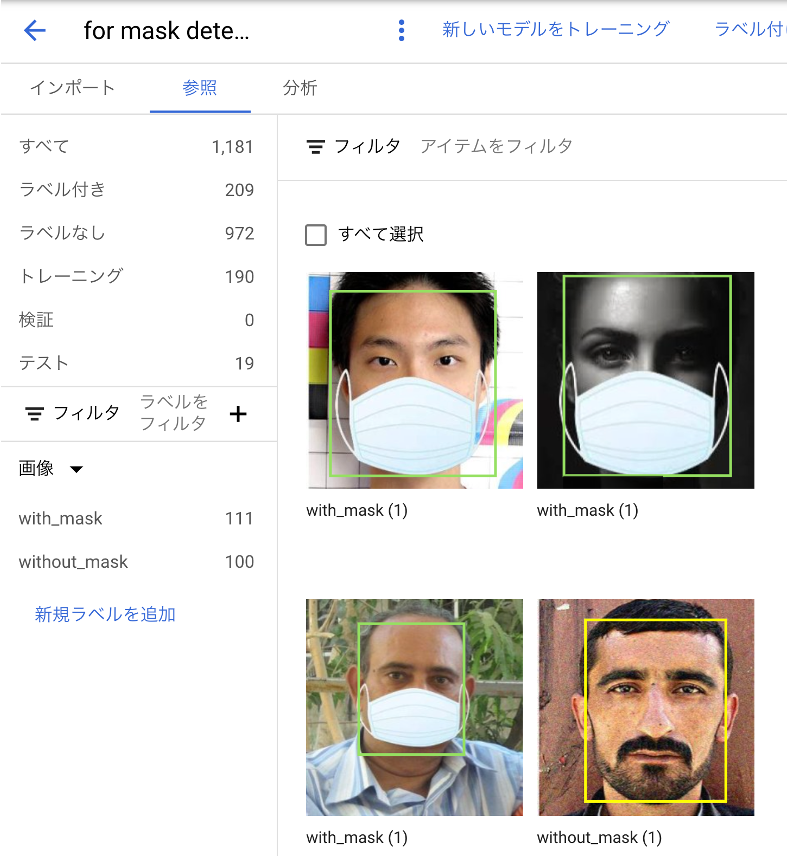
ここでは、デモとしてPrajna Bhandaryさんが公開している、Mask Classifier中のデータセットを用意しました: https://github.com/prajnasb/observations
このデータセットには、マスク有り画像690枚、マスクなし画像686枚の計1,376件の画像データが含まれます。上記のデータセットのうち、マスク有り画像111枚、マスクなし画像100枚を利用します。
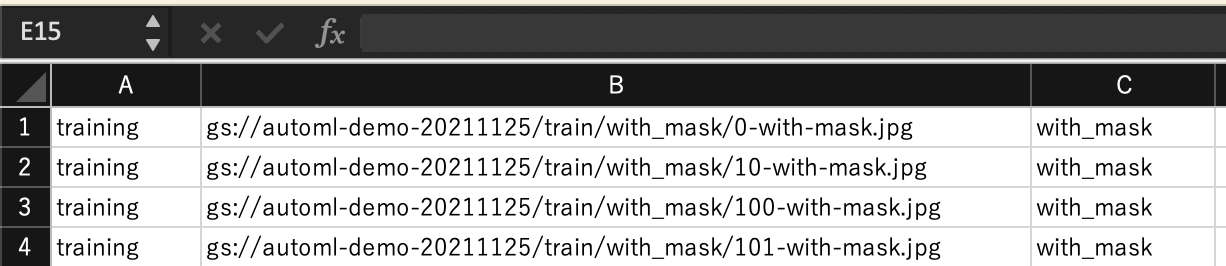
まず最初に、Google Cloud Storage上に学習用画像をアップロードします。このとき、各画像のパスと対応するクラス名を表現したCSVファイルを用意することで、データセットとして簡単に取り込むことができます。
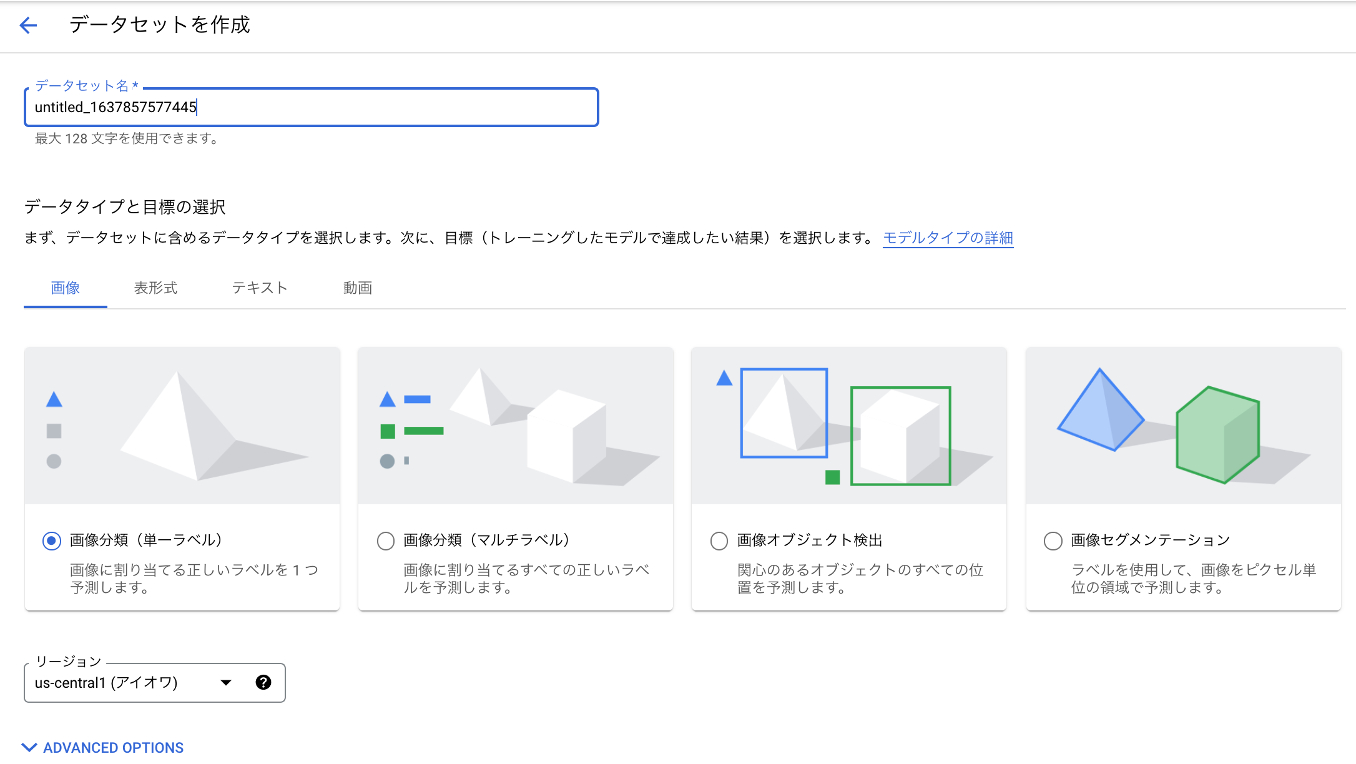
2. 学習用のデータセットの用意
次にモデル構築用のデータセットを用意します。タスクに応じてデータタイプが異なるため注意しましょう。
読み込んだデータに対し、必要であればGoogle Cloud上でラベル付与やアノテーション情報の付与作業を行えます。
3. AutoML Vision Edgeを利用した学習
トレーニング処理は、AutoML / AutoML Edge / カスタムトレーニングから選択することが出来、ここでは、AutoML Edgeを指定します。AutoML Edgeは、オンプレミス / オンデバイスで使用するためにエクスポートできるモデルをトレーニングします。
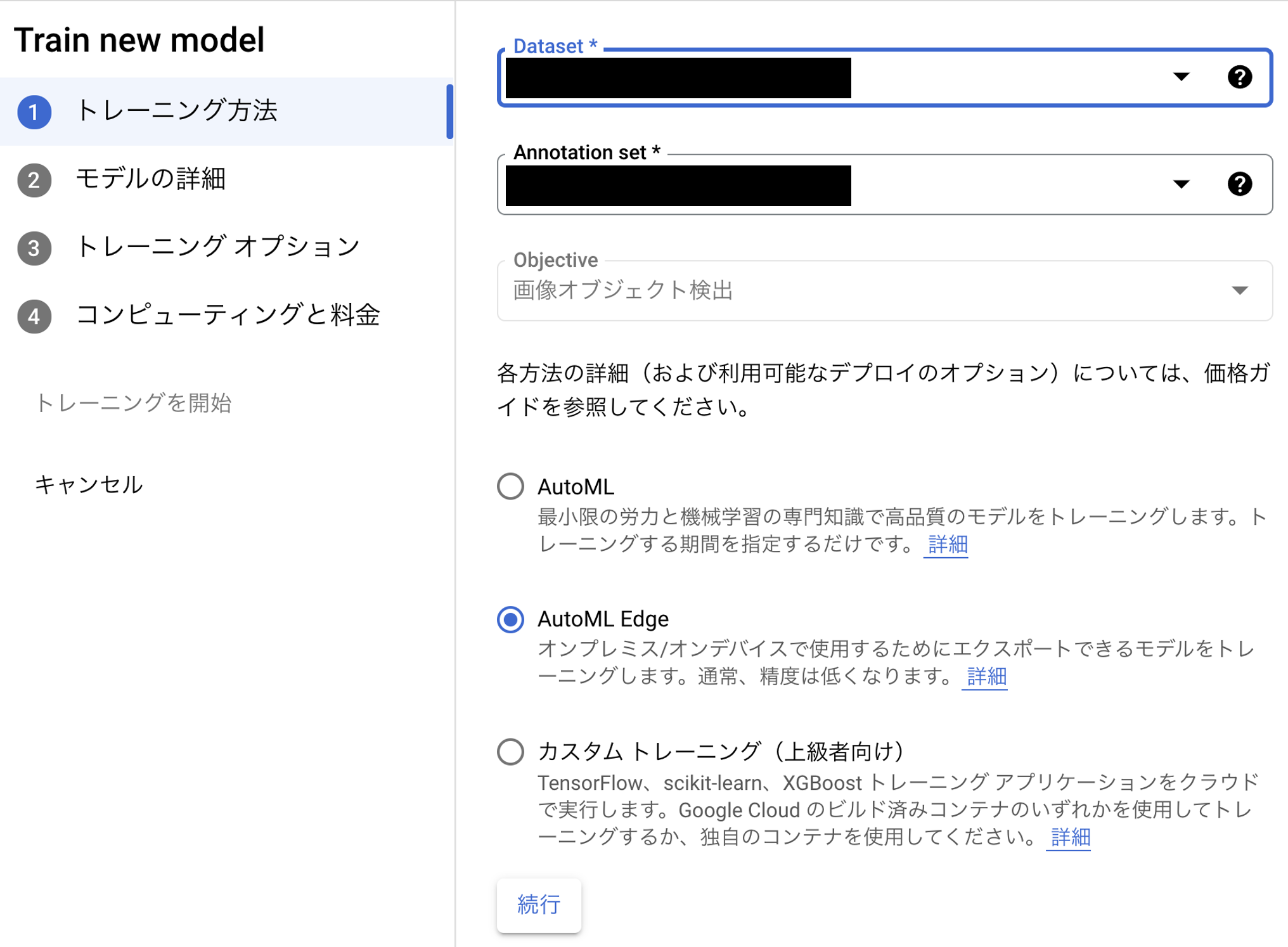
AutoML Edge専用のオプションもあります。
Neural Processing Unit (NPS) 別に最適化されるので、用途に応じたオプションを選択します。

モバイルにおける参考パフォーマンス指標は以下の通りです:
| オプション | レイテンシ | サイズ | 精度 |
|---|---|---|---|
| レイテンシ最低 | 22ミリ秒 | 557KB | 通常は高い |
| 汎用 | 65ミリ秒 | 3.1MB | 最良のトレードオフ |
| 高精度 | 105ミリ秒 | 5.6MB | 通常は低い |
[参考] オプションを変更して学習を実施させた結果
実際に、iPhone X向けにオプションを変更して学習を実施させてみた結果を共有します。
※問題が簡単過ぎたためかあまり有意義な比較結果にはなっていないですが、折角なので
| オプション | 平均適合率 | 精度 | 再現率 | サイズ | 学習時間 |
|---|---|---|---|---|---|
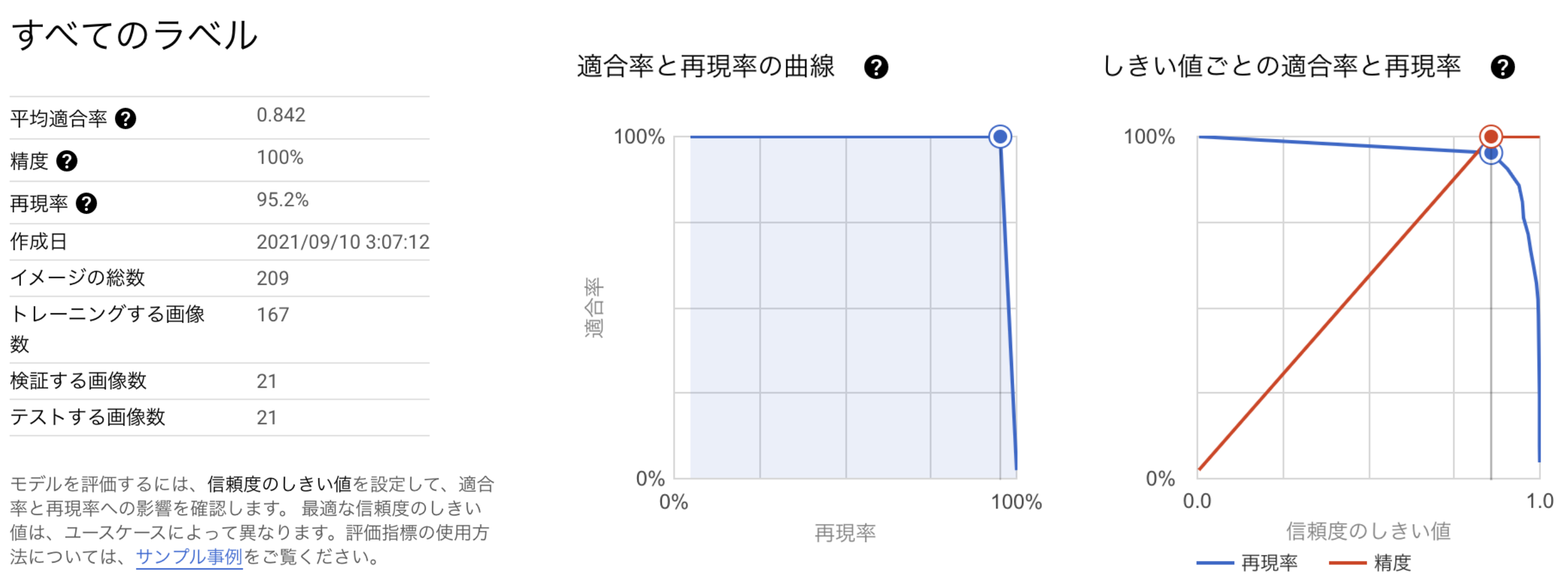
| レイテンシ最低 (1TPU) | 0.842% | 100% | 95.2% | 9.2MB | 1時間23分 |
| レイテンシ最低 | 0.864 | 100% | 95.2% | 9.2MB | 2時間3分 |
| 汎用 | 0.889 | 100% | 95.2% | 9.3MB | 2時間48分 |
| 高精度 | 0.862 | 100% | 95.2% | 9.5MB | 3時間48分 |
[参考] 利用に際してのコスト
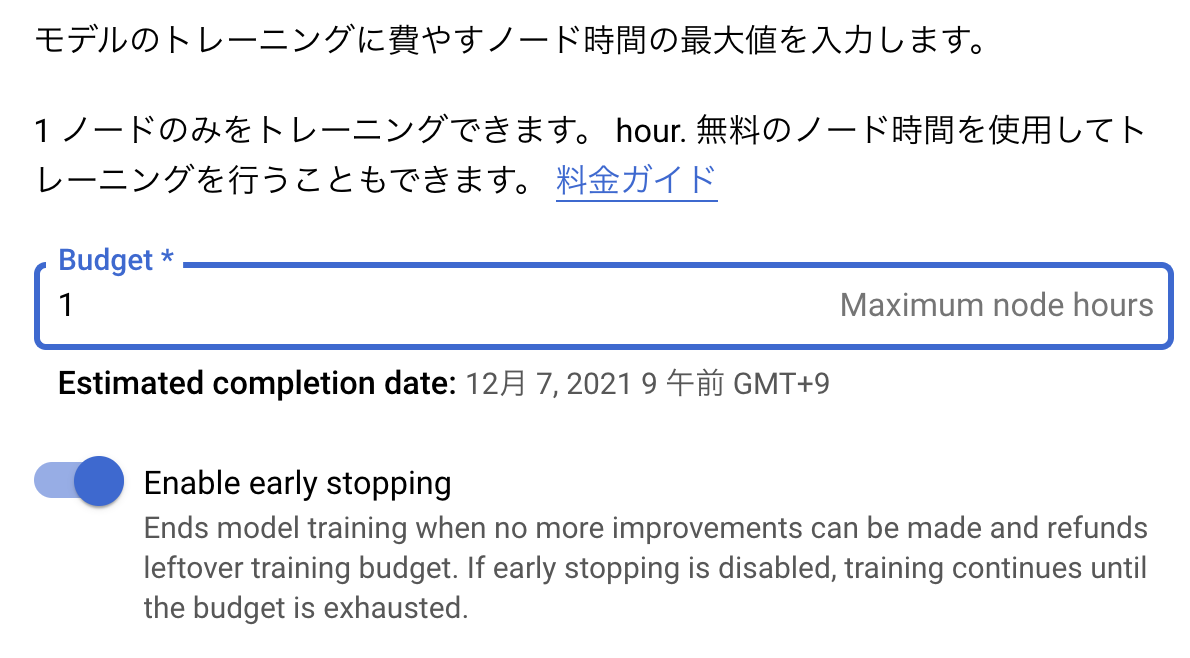
Edgeモデルの学習はTPU (Cloud TPU v2 マシン相当; 180 teraflops; 64GB High Bandwidth Memory) で実行されます。公式によると「5,000枚以下のラベル付き画像を使用したモデルの構築には3ノード時間あれば十分」とあります。
参考: Vertex AIの金額情報
- 画像分類の費用
- アカウントあたり15ノード時間の無料トレーニング (1回限り)
- 1時間あたり USD $4.95
- オブジェクト検出の費用
- アカウントあたり15ノード時間の無料トレーニング (1回限り)
- 1時間あたり USD $18.00
- エッジデバイスへのモデルのエクスポート
- 無料
学習時に最大ノード数を指定することで、予算以上の課金が発生してしまうのを抑制できます。
4. 学習した結果の確認
構築したモデルについて基本的な性能について確認することが出来ます(適合率 (precision) や再現率 (recall) 等)
作成したEdge向けモデルをエクスポートして利用することもできます。様々なフォーマットが選択可能です。
ここまでで、非常に簡単にEdge向けモデルが構築出来るのを確認しました。
作ったモデルを実際にWebブラウザ上に組み込んで確認してみた結果は以下の通りです。非常に少量なデータで学習を行いましたが、最低限のモデルを作ることができました!

おわりに
AutoML Vision Edgeは、優秀なMLエンジニアが作るモデルに精度としては勝てないことが多いですが、ベースラインとしてクイックにモデル構築するには最適なサービスかと思います。
また、MLを学び始めたユーザーが使う分にも最適で、(問題設定に依存しますが) 最低限ビジネス利用可能なラインの精度は発揮することが多いです。運用まで含めてスタートのコストとしても優秀かと思います。
皆様の現場でもぜひお気軽に試しください。