本記事はこちらのブログを参考にしています。
翻訳にはアリババクラウドのModelStudio(Qwen)を使用しております。
PolarDB-Xの列指向クエリ加速とPkIndexの詳細
By Chenyu
背景
PolarDB-X V2.4 は、列指向クエリの高速化をサポートしています。このバージョンでは、低コストのOSSストレージ基盤上に成熟した列指向ストレージSQLエンジンを構築し、より優れたパフォーマンスとコスト効率でクエリ分析を加速します。列指向クエリの高速化は、ストレージとコンピューティングを分離するアーキテクチャに基づいています。列指向エンジンはクラスタ化された列インデックスを構築し、分散トランザクションのbinlogを消費してそれらをクラスタ化された列インデックスに同期し、OSSに保存します。Compute Engine (CN) は、列指向クエリおよびトランザクション管理をサポートします。列インデックスのストレージにはDelta + Main + Delete-and-Insertの組織構造が採用されており、構築されたデータはCSV + ORC + Deleteビットマップ形式でOSSに保存されます。このモードは、Copy-on-WriteやMerge-on-Readと比較して、行ストレージから列ストレージへの低遅延同期を実現します。また、クエリ側に過度なオーバーヘッドを課しません。詳細については、PolarDB-X Clustered Columnar Index | The Birth of the Columnar Engine を参照してください。
列ストレージにおけるDelete-and-Insertスキームの効率的な更新を実現するためには、削除マークが付けられた歴史的に有効なデータの位置を迅速に特定する必要があります。これにより、この列ストレージにおいて唯一のステートフルなオブジェクトであるPrimary Index (PkIndex) が導入されました。同時に、PkIndexの高性能と永続性は、単一ノードでの大規模列ストレージを実現する上で重要であり、大きな技術的課題となっています。
1. 永続的なPkIndex
PkIndexは列ストレージメンテナンスのメインパス上に位置しており、その読み書き性能は低遅延列ストレージのSLA上限を直接決定します。また、フルビルドや増分メンテナンス中の列指向データの正確性を確保する役割も果たします。以下の図は、PkIndex全体のモジュールとクラスタ化された列インデックスの構築におけるその役割を示しています。
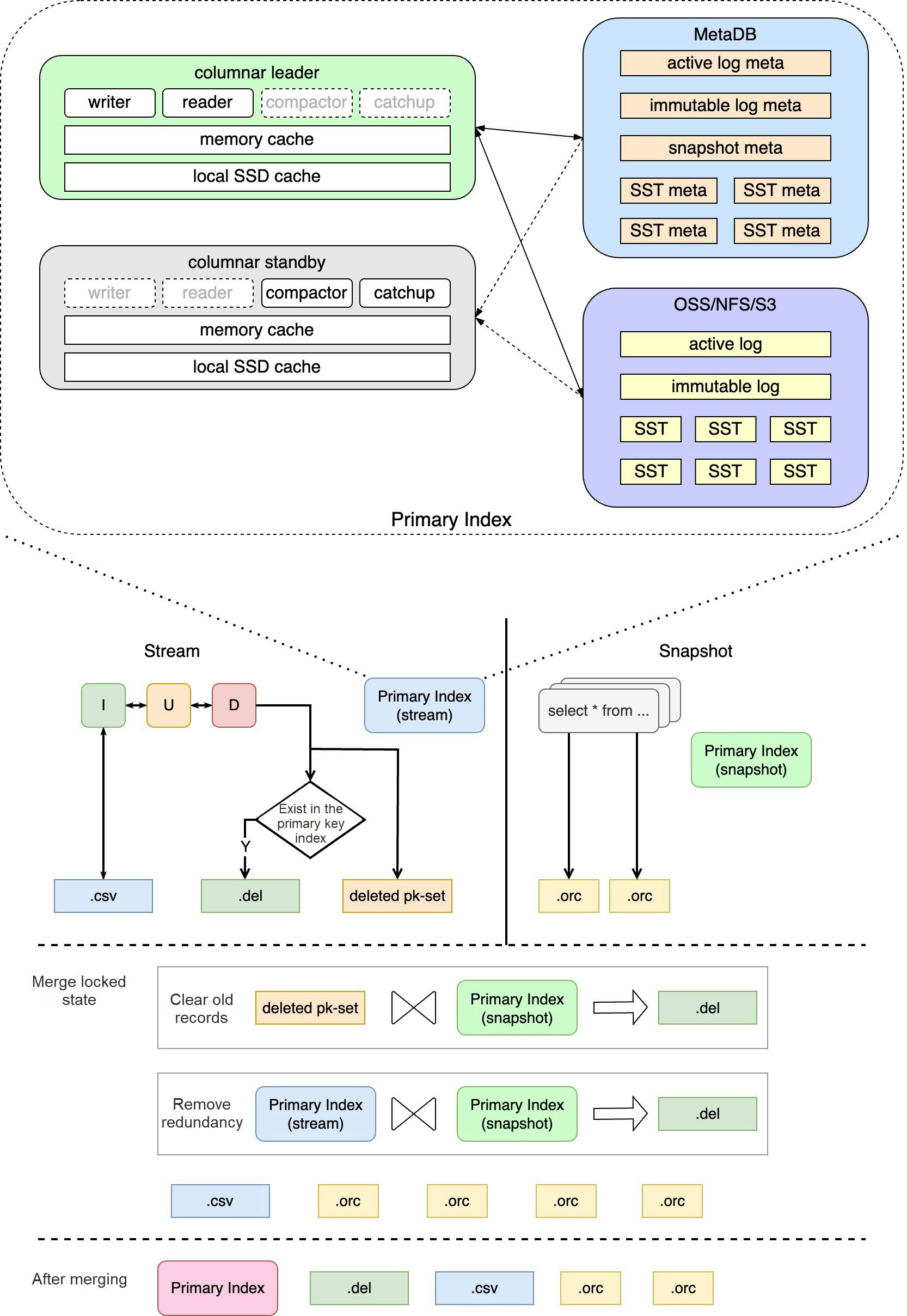
1.1 ストレージモデル
列指向エンジンノードの低ストレージコストとステートレスな移行要件を満たすために、PolarDB-XはPkIndexデータをOSSに保存し、メタデータはMetaDBに保存します。オブジェクトストレージの特徴と業界でのストレージエンジンの実装を考慮し、独自のPkIndexストレージエンジンを開発しました。これはLSM-treeデータ構造に基づいており、OSSの特徴に合わせて一連の最適化を行っています。これにより、高スループットの書き込みと低遅延のクエリという列指向エンジンのニーズに対応しています。
1.2 ストレージエンコーディング
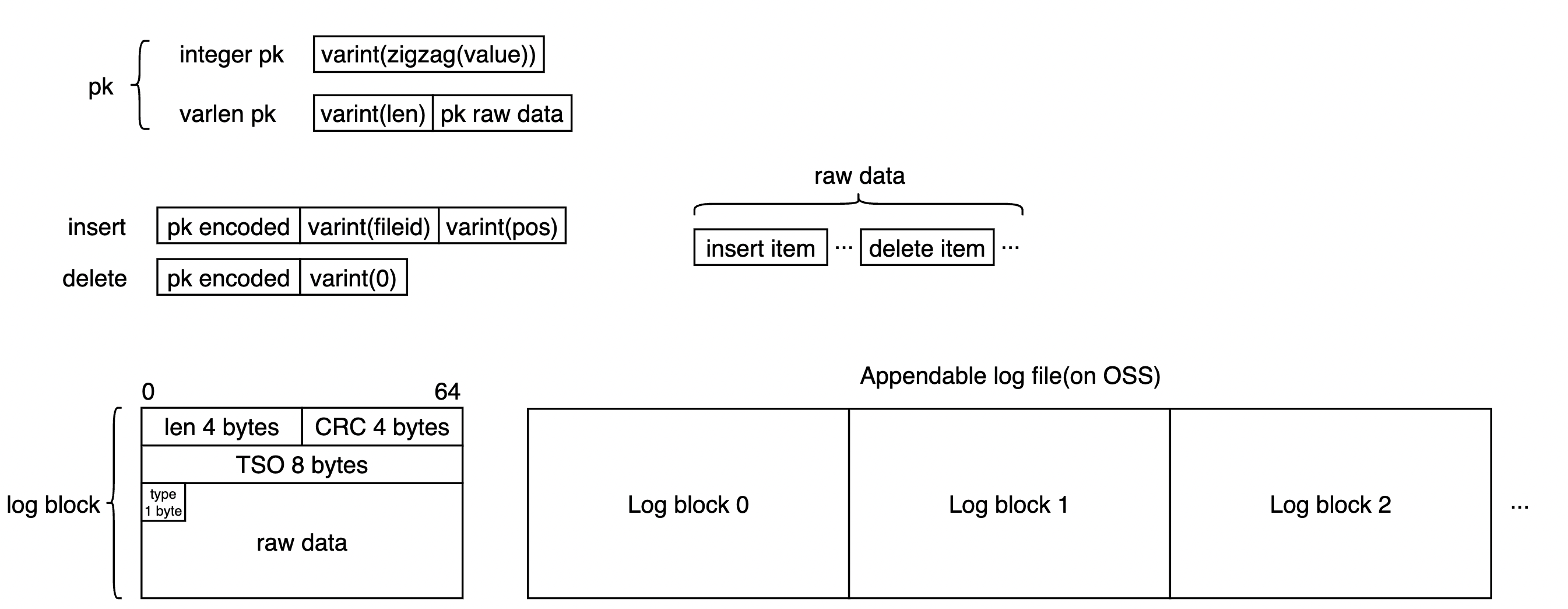
PkIndexはデータの特性に基づいて圧縮およびエンコードされ、ストレージ空間の圧縮を最大化し、有効データの密度を向上させます。PkIndexでは、Keyはデータレコードの主キーであり、主に次の2つのタイプをサポートします:
- 整数型の主キーは、ジグザグエンコーディングを経て可変長整数として圧縮・保存されます。
- その他のタイプの主キーは、長さが可変長整数として記録され、その後バイナリエンコードされた主キーが続き、任意のカスタム定義タイプをサポートします。
Valueは列指向データの位置であり、次の2つのタイプがあります:
- 対応する列指向データが有効な場合、それは列ストレージ内の対応する行データが保存されているファイル(fileId)とオフセット(pos)で構成され、両方とも可変長整数を使用して圧縮・保存されます。
- 対応する列指向データが削除された場合は、単一バイト「0」でマークされます。
書き込みはバッチで送信されます。バッチデータには挿入エントリと削除エントリが含まれます。同じキーを持つ操作は1つのレコードに圧縮され、上述のようにエンコードされ、ログブロック内の操作順に密に配置されます。各ログブロックヘッダーには、ブロック長、チェックサム、送信タイムスタンプ、および主キータイプが格納されます。全体的な機能は以下の図に示されています。
1.3 データの階層化と分散
より多くのデータが書き込まれると、ログが長くなり、読み取りと復旧時間が減少します。Compactionモジュールはログモジュールをマージおよび分割して下位レベルのSSTにします。全体のLSMツリーは以下の図に示されています。
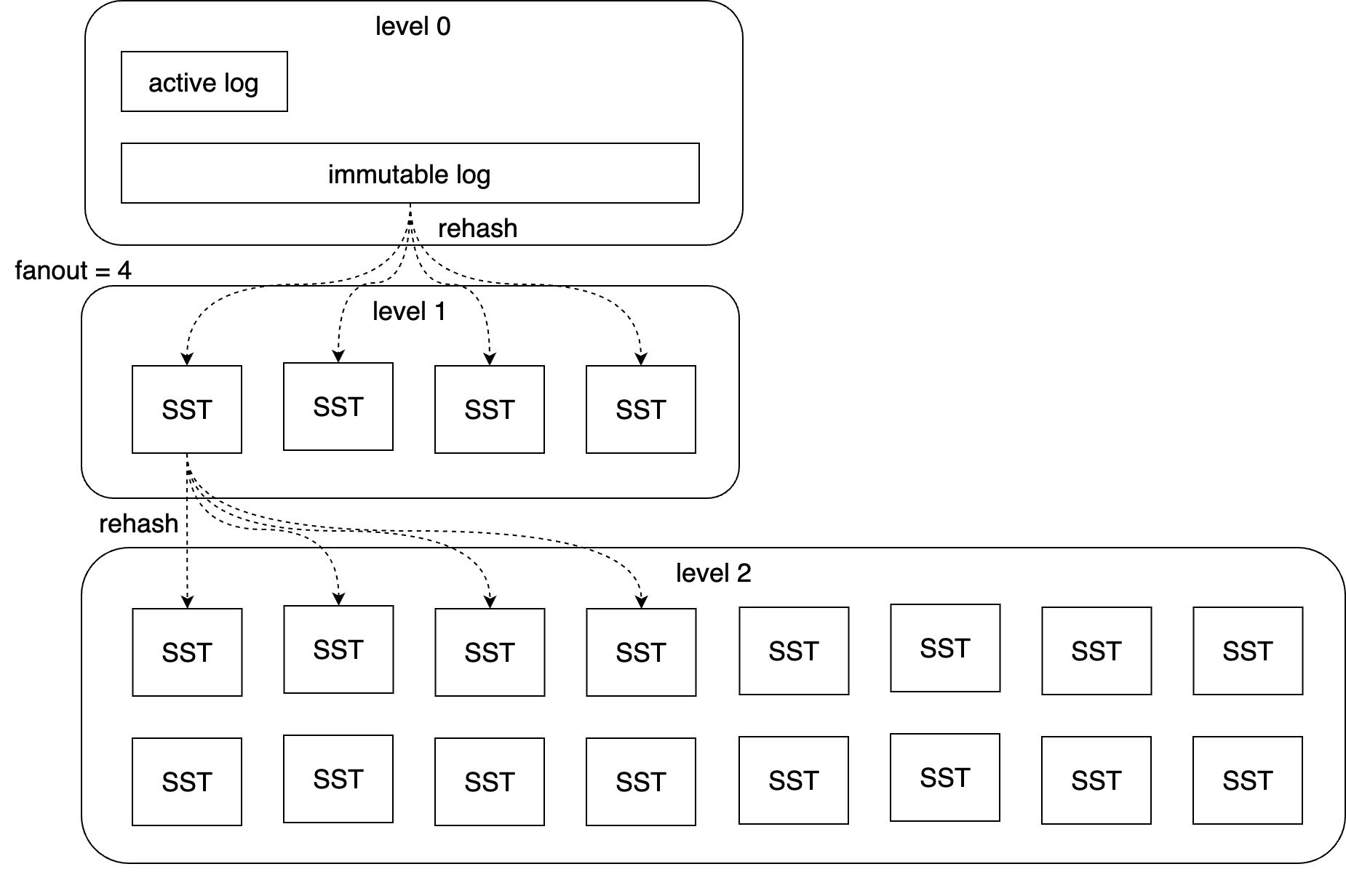
これはLSMツリーの概念に基づいています。WALの永続化は、追加可能なファイルを使用してOSSベースで実装されます。階層型アーキテクチャはホットデータとコールドデータの分離を実現します。Level 0はログ層であり、データは交錯し、順序付けられていません。データは順次書き込まれ、コミット時にバッチで書き込まれます。Compactionを容易にし、書き込みに影響を与えないために、ログはアクティブログと不変ログの2種類に分けられます。アクティブログは常に1つだけ存在し、新しいデータはアクティブログにのみ追加できます。不変ログは修復時(データとメタデータが不一致の場合、修復プロセスがトリガーされる)およびCompactionプロセス中に生成されます。不変ログファイルは変更不可です。Level 1 - nはSST層であり、データは重複せず、各ファイル内のデータはキーによってソートされています。OSSファイルは可変長エンコーディングを使用してデータを密に配置し、スパースインデックスを保存して高速なバイナリサーチによる位置特定を促進します。SSTファイルは変更不可です。メタデータベースはオブジェクトサイズ、CRC32、ハッシュバケット情報、およびBloomフィルターなどの情報を記録します。データストレージシャーディングは一貫性のあるハッシュ方式を使用し、n層の1つのSSTが厳密にn+1層のkファイルに対応することを保証します(kはfanoutパラメーター)。つまり、level 1には最大でfanout個のSSTファイルがあり、level nには最大でfanout ^ n個のSSTファイルがあります。SSTが下層にマージされるたびに、最大で1 + fanout個のSSTファイルを読み取り、fanout個のSSTファイルを書き込みます。読み書き量は厳密に制御可能であり、同じ層でのすべてのマージは交差しないため、タスク並列性に有利です。
1.4 書き込みの原子性保証
列指向エンジンにはプライマリノードやホットスタンバイノードなど複数のノードがあります。データのメタデータはOSSと
スケジューリングタスクとPolarDB-Xの詳細なプロセス
スケジューリングタスクは、低スペック構成に適応するため細分化されています。高スペック構成では、タスクタイプを使用してスレッドプールを分割し、並列スケジューリングを行うことで、OSSストレージの高スループットを最大化できます。また、高並列性、細かい粒度、多段階のタスクオーケストレーションを使用して、圧縮プロセスを加速することも可能です。
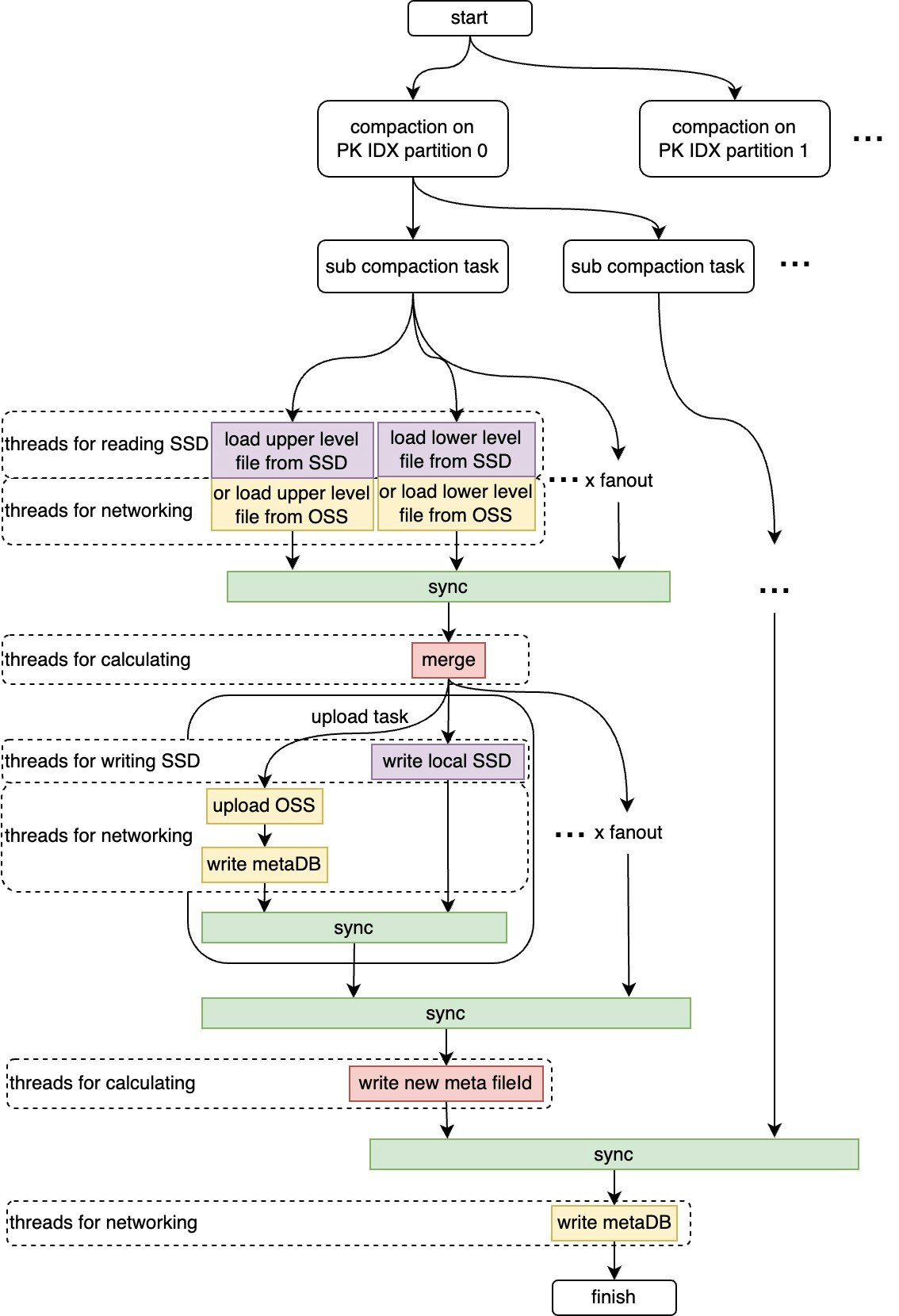
1.6 読み取りプロセス
PkIndexには、次の2つのアクセスモードしかありません。
- ポイントクエリは、削除が必要な列指向データの場所を見つけて、削除フラグでマークするために使用されます。
- フルトラバーサルは、クラスタ化された列指向インデックスを作成しながらデータを重複排除し、増分データと完全データをマージするために使用されます。
この特別なアクセスモードは、PkIndexが選択する一貫性ハッシュの階層分布ルールの重要な理由でもあります。ポイントクエリは列指向データ更新のメインパスにおける高頻度リクエストであり、これはLSMツリーの弱点でもあります。この問題を解決するために、PkIndexは次のように最適化されています:
- ホットデータとコールドデータのアクセス頻度に基づく仮定により、LSMツリーはホットデータとコールドデータを自然に分離できます。
- 一貫性ハッシュの階層分布アルゴリズムでは、各レイヤーで1回のポイントクエリだけで済み、キーのハッシュを使用してSSTファイルを迅速かつ一意に特定できます。
- メタデータには、各SST用のブルームフィルターが格納され、不要なSST読み取りをさらに減らします。
- SSTファイルサイズのしきい値は、OSSの最適サイズに適合し、OSSアクセス効率を向上させます。
- マルチレイヤーキャッシュが採用されており、すべてのレベル0ログはメモリ内に存在し、ハッシュテーブルによって高速化されています。レベル1〜nのSSTに対しては、メモリ、SSD、およびOSSを使用した3層キャッシュ構造が使用され、キャッシュミスのコストを可能な限り最小限に抑えます。
フルトラバーサルリクエストの場合、ボトムアップトラバーサルアプローチが上位レイヤーで見つかったデータをフィルタリングして有効なデータトラバーサルを実現します。同時に、一貫性ハッシュの分布に基づいてスキャンスレッドの配置を並列化することで、キャッシュヒット率を最大化できます。
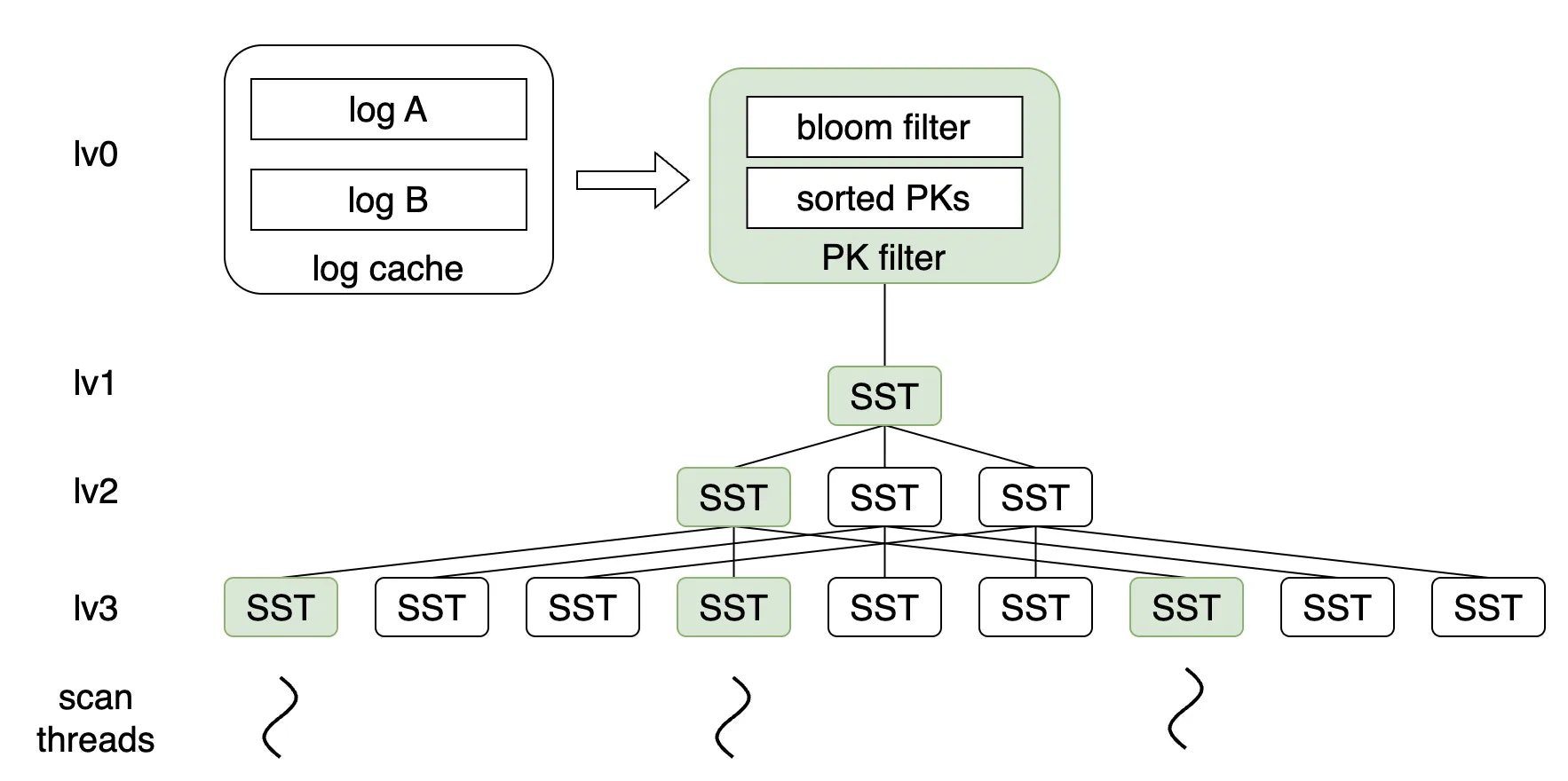
1.7 ログ/SSTキャッシュ
データ構造内で唯一の変更可能、順不同、かつ重複の可能性があるコンテナとして、ログ層のデータには読み取りパフォーマンスを高速化するための補助データ構造が必要です。PolarDB-XのPkIndexでは、この機能をハッシュテーブルを使用して実現しています。従来のLSMツリーがまずMemTableに書き込み、その後ログを生成するのに対し、我々は最初にデルタログを作成し、アトミックコミット後にそれをハッシュテーブルに再公開します。ハッシュテーブルはログキャッシュとしてのみ存在します。この特徴に基づき、圧縮プロセスはログキャッシュ内のデータイテレーションを促進します。
ログキャッシュは複数のハッシュテーブルに分割されます。ログ切り替えやログのSSTへのプッシュ後、ハッシュテーブルはメモリ解放のためにロールアウトされます。SSTキャッシュは比較的シンプルです。SSTは不変のデータ構造で、内部に順序があり、スパースインデックスを持っています。キャッシュはバイナリSSTデータのみを格納します。ポイントクエリでもトラバーサルでも、カーソルを維持し、スパースインデックスを使用してバイナリサーチによる位置決めを行い、その後データをデコードしながら出力するだけです。
さらに、PolarDB-Xの列指向エンジンはJavaで開発されているため、Javaを使用してストレージエンジンを開発する際の厄介な問題であるメモリ管理があります。基本データ構造ではないハッシュテーブルの場合、キャッシュデータは多くの小規模オブジェクト、長いライフサイクル、大量のメモリを持つシナリオで簡単に古い世代に陥りがちです。数十億の小規模オブジェクトは大量のCPUを消費し、FGC(Full Garbage Collection)プロセスでのスキャン時間を増加させ、深刻なパフォーマンス問題や長時間のStop-the-Worldポーズを引き起こします。この問題を解決するために、Arena、ハッシュテーブル、ソートアルゴリズムに基づいたメモリ管理システムを開発しました。これについては、後続の記事で説明します。
2. 高可用性ホットスタンバイモード
PolarDB-Xの列指向エンジンは、1つのマスターモードと1つのホットスタンバイノードを使用しており、マスター選定はリース競合に基づいて行われます。PkIndexはステートフルなデータ構造として機能し、ノードメモリのほぼ半分をバッファプールとして占有します。高可用性のためにマスターノードが切り替えられる場合、ホットスタンバイノードは迅速に引き継ぎ、列ストア構築サービスを提供できます。したがって、ホットスタンバイノードはマスターノードのリプレイログをタイムリーに追跡できる必要があります。コミットが完了すると、マスターノードは能動的に同期コマンドをブロードキャストし、ホットスタンバイノードはメタデータベース内のログチェックポイントに基づいて迅速にリプレイを完了します。
キャッチアップアルゴリズムは、現在の状態とターゲットチェックポイントに基づいて次の3つのシナリオに分類され、最小限のコストでリプレイを完了します:
- Catchup active: ホットスタンバイのリプレイチェックポイントが最新スナップショットのアクティブログ上にある場合、アクティブログの遅延部分のみをリプレイします。
- Catchup immutable: ホットスタンバイのリプレイチェックポイントが最新スナップショットの不変ログ上にある場合、不変ログの遅延部分と全体のアクティブログをリプレイします。
-
Fully recover: ホットスタンバイのリプレイチェックポイントが最新スナップショット上に見つからない場合、大幅な遅延を示します。この場合、すべての状態データがクリアされ、SSTメタデータがリセットされ、すべてのログ部分がリプレイされて完全な状態復元が完了します。

さらに、ホットスタンバイノードはPkIndexの圧縮操作も担当し、マスターノードのCPUおよびI/O負荷を軽減し、すべてのノードリソースを最大限に活用します。
3. パフォーマンスデータ
PolarDB-Xの列指向エンジンのグループコミットモードについて、16c64gノード向けに2セットの書き込みパフォーマンスストレステストを設計しました:
- ケース1: 1億6千万の主キー範囲内のランダム書き込み、バッチサイズ3百万(30万QPS、10秒間のグループコミット)、100バッチ挿入で合計3億書き込み。
- ケース2: 100億の主キー範囲内のランダム書き込み、バッチサイズ3百万(30万QPS、10秒間のグループコミット)、1,000バッチ挿入で合計30
付録
列指向ストレージに関するシリーズの関連記事:
- PolarDB-X Clustered Columnar Index | The Birth of the Columnar Engine
- PolarDB-X Clustered Columnar Index | Snapshot Reads Meeting Transaction Consistency
- PolarDB-X Clustered Columnar Index | Full Support for Multi Schema
- PolarDB-X Columnar Query Engine
-
PolarDB-X Clustered Columnar Index | Analysis for TPC-H Execution Plans
注:リンクは原文と同じまま保持されています。