本記事はこちらのブログを参考にしています。
翻訳にはアリババクラウドのModelStudio(Qwen)を使用しております。
PolarDBがTPC-Cベンチマークで世界記録を達成!技術的秘訣シリーズ 第1弾:スタンドアロンパフォーマンス最適化
最近、PolarDB はTPC-Cベンチマークテストのランキングで、前回の記録を2.5倍上回るパフォーマンスを達成し、1分あたり20億5500万トランザクション(tpmC)のパフォーマンスと1tpmCあたり0.8元のコストという結果で、パフォーマンスとコスト効率の世界記録を樹立しました。各数字の背後には、データベースのパフォーマンス、コスト効率、安定性に対する無数の技術者の究極の追求があります。PolarDBの革新の歩みは止まることなく続いており、「TPC-Cトップ獲得の技術的秘訣」に関する一連の記事を公開します。この「ダブル第1位」の裏側にある物語にご期待ください!本記事はこのシリーズの最初の記事であり、スタンドアロンパフォーマンスの最適化について説明します。
1. TPC-Cベンチマークモデル
TPC-Cは、トランザクション処理性能評議会(TPC)によって開発されたOLTPシステムのパフォーマンスを測定するためのベンチマークテストです。これは、データベースの追加、削除、変更、および照会などの典型的な処理パスをカバーしており、最終的なパフォーマンスはtpmC(1分あたりのトランザクション数)によって測定されます。TPC-Cテストモデルは、データベースのパフォーマンスを直接かつ客観的に評価でき、世界で最も信頼できるテスト基準です。今回のTPC-Cベンチマークテストでは、PolarDB for MySQL 8.0.2を使用しました。Alibaba Cloud ApsaraDBが開発したフラッグシップ製品であるPolarDBは、90以上のスタンドアロン最適化とパフォーマンス向上手法を通じて、単一コアのパフォーマンスを前回の記録から1.8倍に向上させ、データベース分野でのマイルストーンを達成しました。この記事では、PolarDBのスタンドアロン最適化の技術的な内部に迫ります。ランキングプロセスの中で、データベースの負荷モデルを深く分析した結果、以下の4つの主要な特徴とそれに対応する最適化ソリューションを整理しました:
- 膨大なユーザー接続 → 高並列最適化
- 高いCPU使用率とメモリアクセス → CPUおよびメモリ効率の最適化
- 高いI/Oスループット → I/Oリンクの最適化
- より長いログ書き込みリンク → レプリケーションパフォーマンスの最適化
これらの4つの特徴は、オンラインユーザービジネスにおいても一般的なパフォーマンスボトルネックです。以下では、PolarDB全体のパフォーマンスリンクを説明し、これらの4つの典型的な特徴に基づいてスタンドアロンインスタンスのパフォーマンスリンクに対して行われた主要な最適化を紹介します。
2. PolarDBパフォーマンスリンク
共有ストレージを持つクラウドネイティブデータベースとして、PolarDBはソフトウェアとハードウェアの共進化により、超高速な使いやすさ(高速バックアップと復旧、高可用性)、強力な弾力性(ストレージとコンピューティングの分離)、ローカルディスクと同等の一貫したI/Oレイテンシ、および高いIOPSを提供します。これにより、パフォーマンス、使いやすさ、および拡張性の極限を実現しています。ローカルディスクに展開された従来のMySQLアーキテクチャは、ローカルディスクの低I/Oレイテンシの恩恵を受けますが、ストレージ容量の制限やスケールアップの困難さといった課題にも直面します。さらに、クロスマシンのプライマリ/セカンダリレプリケーションの高レイテンシは、ローカルディスクのパフォーマンス上の利点を曖昧にします。クラウドディスクに直接デプロイされたMySQLアーキテクチャは、クラウドディスクのストレージリソースのスケーラビリティと高可用性を利用できますが、クラウドディスクの高レイテンシによりMySQLのパフォーマンスを十分に引き出すことができず、計算リソースをスケールアウトできません。パフォーマンスとスケーラビリティの問題を解決するために、ユーザーは分散データベースを検討しますが、これらには大きなビジネス変革や高い運用コストといった問題が伴います。PolarDBは、プロキシから基盤となるストレージまで、エンドツーエンドのハードウェアとソフトウェアの協調最適化により、これら3つの問題を解決します。
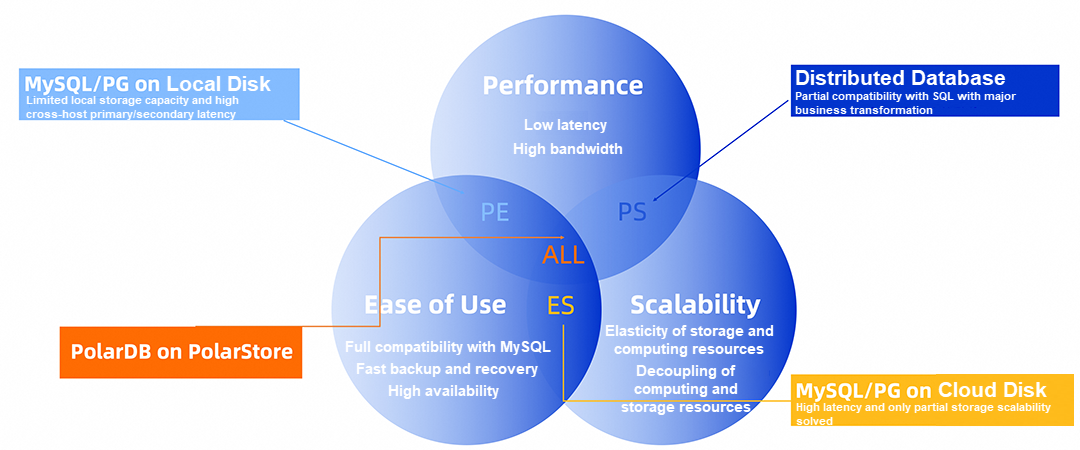
図1: 高性能、使いやすさ、スケーラビリティを兼ね備えたPolarDB
図2は、PolarDB全体のパフォーマンス最適化リンクの概要を示しています。ユーザーが接続するSQLクエリは、プロキシによってデータベースカーネルに転送され、SQLステートメントで解析され、インデックスで検索され、最終的にファイルシステムを介してディスクストレージに到達します。全体のパフォーマンス最適化リンクは、上層のプロキシから基盤のストレージまで広がっています。PolarDBは、エンドツーエンドのパフォーマンスを最適化し、高負荷のTPC-C条件下でも効率的なトランザクション処理性能を維持します。本記事では主に、データベースカーネルレベルでのスタンドアロン最適化について説明します。次回以降、PolarDBがどのようにソフトウェアとハードウェアを統合して協調進化を達成するかを紹介します。
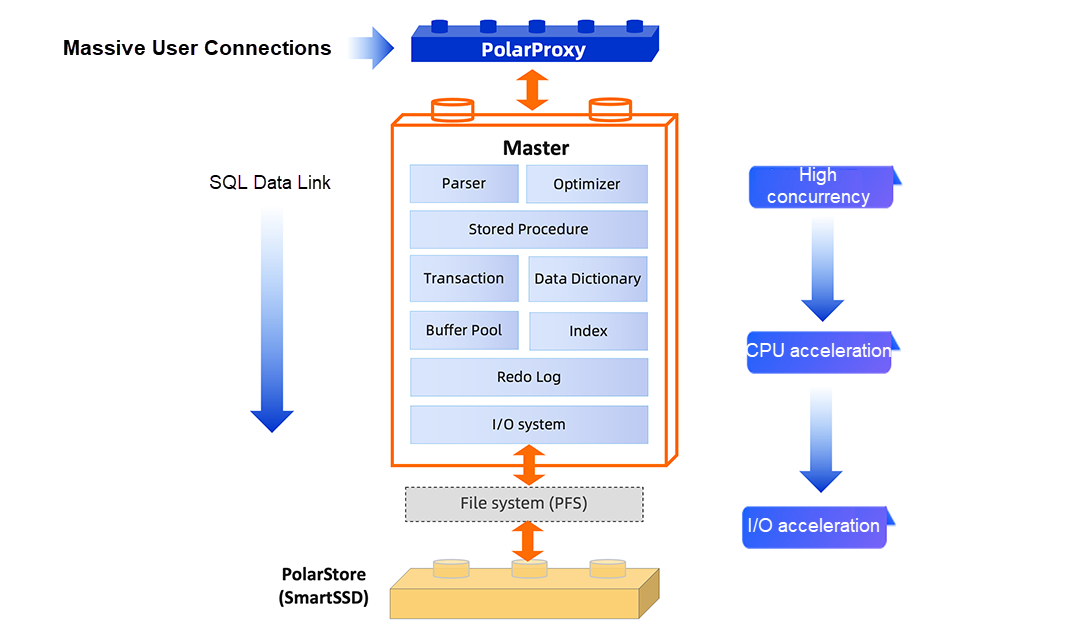
図2: PolarDBパフォーマンスリンクの概要
3. 高並列最適化
TPC-Cベンチマーク負荷の最初の典型的な特徴は膨大なユーザー接続です。PolarDBクラスターのテストでは、クライアント上に合計16億のユーザー接続が生成されました。マルチレベル接続プールを経由しても、単一データベースノードへのユーザー接続数は依然として7,000を超え、データベースの並列処理能力にとって試練となっています。
3.1 PolarIndex
多数の並行インデックス書き込みによるロックボトルネックを解決するために、PolarDBは高性能なPolar Indexを提供し、マルチスレッド並行シナリオでのインデックス読み書き性能を向上させます。Polar Index 1.0は、グローバルインデックスロックにより並行分割およびマージ操作(SMO)が許可されていない問題を解決します。インデックスをトラバースする際にはラッチ結合の原則に従い、次のノードの書き込みロックが正常に取得された場合にのみ親ノードの書き込みロックを解除します。SMOは複数の段階に分解され、SMO中の分割ノードの並行読み取りが可能になります。Polar Index 2.0では、PolarDBはさらにインデックスのロック粒度を最適化しています。ラッチ結合と比較して、PolarDBはbtreetopダウン方式でトラバースする際に一度に1つのノードのみをロックし、SMOを最適化
完全非同期アーキテクチャの設計
PolarDBは、コルーチン技術を使用して、ユーザー要求のライフサイクルを物理スレッドから分離し、完全に非同期な実行モデルに再構築します。
- コルーチンベースのリクエスト: トランザクション要求は独立したコルーチンとしてカプセル化され、ユーザーモードのスケジューラによって管理されます。
- 能動的な解放メカニズム: コルーチンが中断すると、実行権が解放され、スケジューラは即座に別の準備完了状態のコルーチンに切り替えます。
- 効率的なリソース再利用: 単一のスレッドで数百のコルーチンを並列に処理でき、スレッドスケジューリングのオーバーヘッドを削減します。
コルーチン通信メカニズム
PolarDBは、eventfdに基づく軽量な通信プロトコルを設計しています。各コルーチンは独立したeventfdにバインドされ、シグナル伝達チャンネルとして機能します。コルーチンが中断すると、epollスレッドがイベントをリアルタイムでキャプチャします。リソースが準備できた場合、eventfdに書き込むことで中断されたスレッドが即座に復帰し、シグナルがトリガーされます。このメカニズムは、従来のスレッドブロードキャストウェイクアップの制限を突破し、3つの主要な改善点を実現しました:ゼロ無効ウェイクアップ、ナノ秒レベルの応答、および数百万の同時操作を管理する能力。
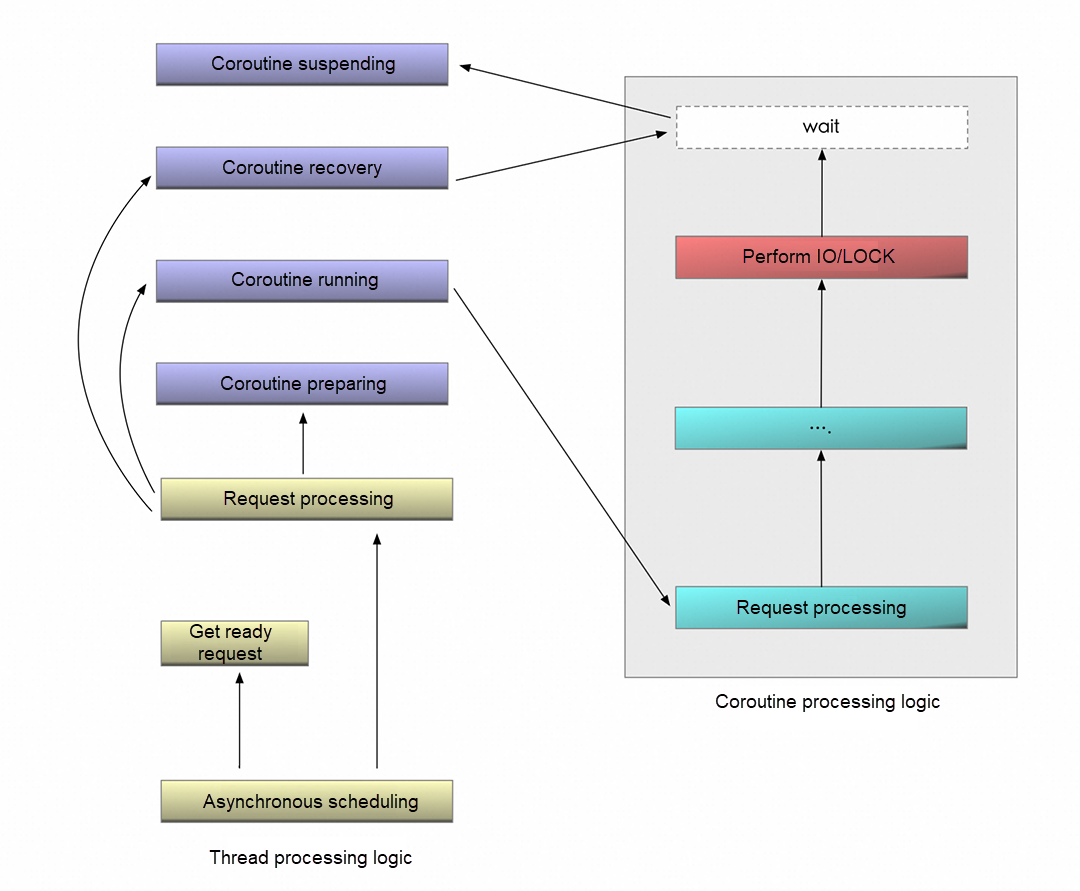
図6: 非同期実行ロジック
4. CPUとメモリ効率の最適化
TPC-Cベンチマークテストでは、大量のSQLステートメントの解析や実行、データテーブルへのアクセスが依然として多くのCPUおよびメモリリソースを消費します。PolarDBは、テーブルメタデータ管理やストアドプロシージャなどのモジュールを詳細に分析し、CPUリソースを節約し計算効率を向上させています。
4.1 楽観的オープンテーブル再利用
構造化データベースでは、DML操作を行う前にテーブルのメタデータロック(MDL)を保持する必要があります。行構造を特定しつつ、他のDDL操作によるデータ不整合を防ぐ必要もあります。従来の悲観的ロックの場合、ユーザースレッドはSQLステートメントを実行してデータにアクセスする前に、すべてのテーブルのメタデータを生成し、MDLを追加し、トランザクション実行後に解放します。これには多くのCPU時間を要します。特に、トランザクションは通常数十のSQLステートメントで構成されるため、トランザクションを繰り返し実行するたびにCPU負荷がさらに増加します。
PolarDBは楽観的オープンテーブル再利用メカニズムを実装し、テーブルのメタデータを繰り返し構築・破棄したり、MDLロックを繰り返し追加・解放するオーバーヘッドを削減します。接続ごとのプライベートキャッシュを維持することで、トランザクションがアクセスするデータテーブルとユーザー接続情報を次のトランザクションで再利用できるように保存します。アクセスするデータテーブルがプライベートキャッシュのサブセットである場合、キャッシュされたテーブルメタデータとMDLロックを再利用できます。デッドロックを回避するために、新しいデータテーブルにアクセスするか切断された場合、プライベートキャッシュはクリアされ、対応するMDLロックが解放され、悲観的ロックプロセスが再開されます。
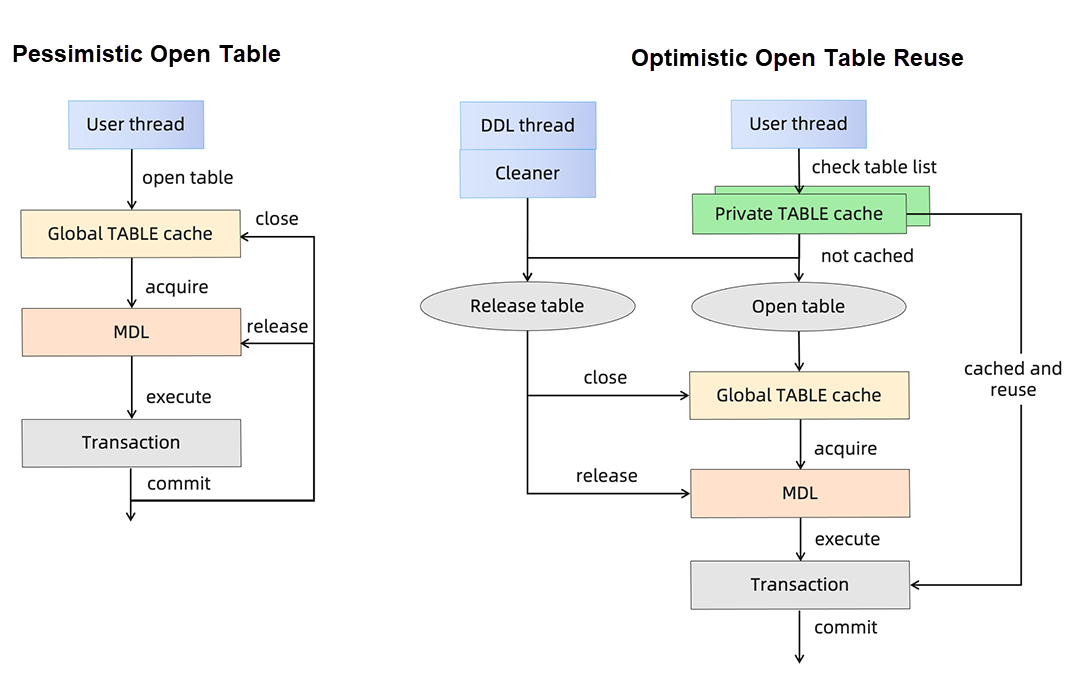
図7: 楽観的オープンテーブル再利用の最適化
4.2 ストアドプロシージャ内のキャッシングメカニズム
TPC-Cトランザクションの実行は、ストアドプロシージャの解析と実行に依存します。ストアドプロシージャの実行効率は、トランザクション処理性能を大きく決定します。ストアドプロシージャの実行効率を向上させるために、PolarDBは以下の方法でストアドプロシージャのキャッシングメカニズムを最適化しています:
- ユーザー接続レベルの構造キャッシュをグローバル構造キャッシュに変換し、多数の接続による過剰なメモリ使用を回避し、バッファプールのページメモリを増やしI/Oオーバーヘッドを削減します。
- SQLステートメントのprepare結果をキャッシュし、楽観的オープンテーブルと組み合わせて、バインドされるデータテーブルのカラム情報をSQL式のアイテム内にキャッシュします。これにより、ストアドプロシージャ呼び出し時の繰り返しのprepareオーバーヘッドを回避し、CPUリソースの浪費を防ぎます。
- 実行計画キャッシュを実装し、インデックス統計に基づいて単純なSQLステートメント(主キーインデックスクエリやインデックスなし範囲クエリなど)の実行パスを固定化します。これにより、オプティマイザがストレージエンジンに潜り込んで余分なI/OやCPUリソースを占有することを防ぎます。
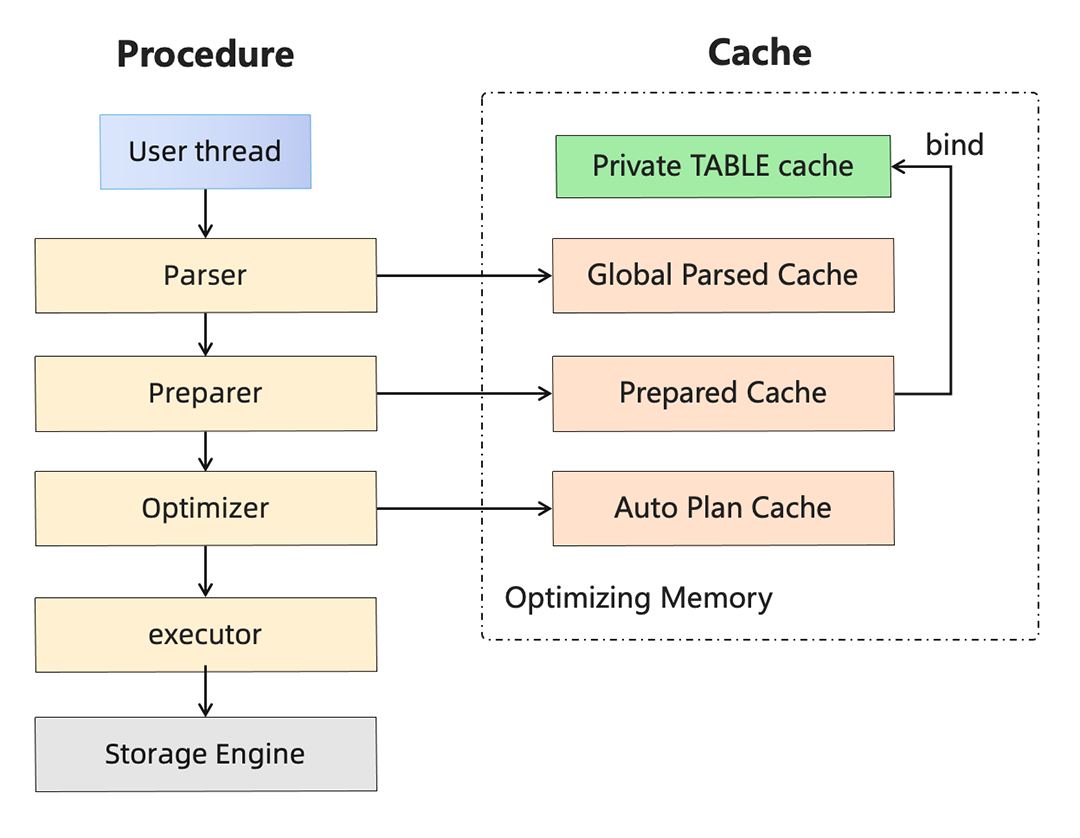
図8: PolarDBストアドプロシージャのキャッシングメカニズム
5. I/Oリンクの最適化
1つのTPC-Cトランザクションの実行には数十の読み取りI/Oが関与することがあり、トランザクションのデータアクセス性能はディスクI/Oの性能に大きく依存します。PolarDBは、I/Oリンクに対してPolarIOソリューションを提案しています(図9 (a) 参照)。PolarDBは、PageおよびRedo I/Oという2つの主要なストレージエンジンタイプから開始し、バッファプール、Redoバッファ、およびI/Oキューを変換します。最終的に、独自開発のユーザーモードファイルシステムPFSを使用して、これらを基盤となるElastic Cloud Storageに永続化します。
前述のバッファプールモジュールに加えて、図9 (b) はPolarDBの並列Redo書き込み設計を示しています。Redoバッファは複数のシャードに分割され、非同期I/Oタスクを並列に発行し、非同期Redo準備メカニズム(Redoアライメントやチェックサム計算など)と組み合わされています。高負荷のRedo環境での実際の測定では、PolarDBのRedoスループットは4GB/sに達します。
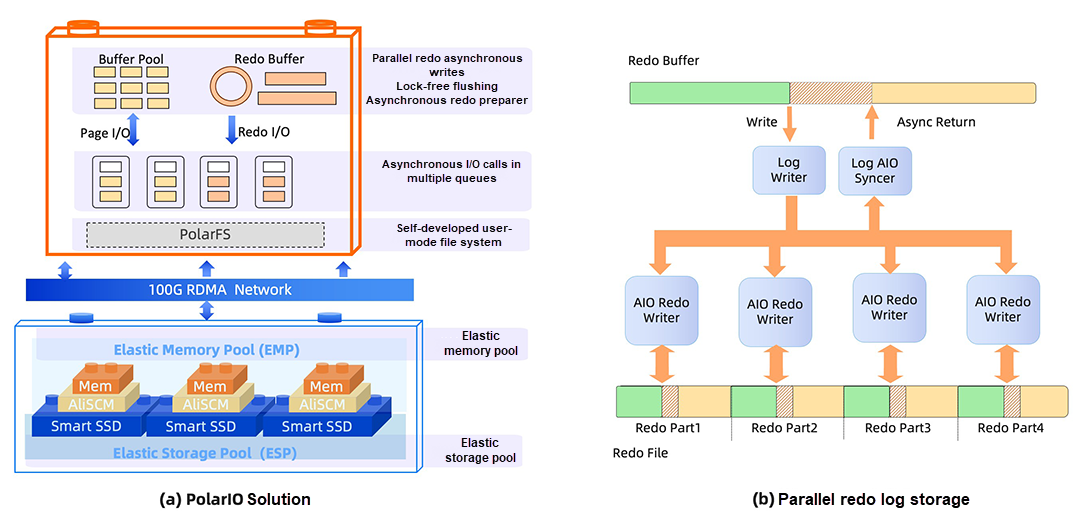
図9: PolarIOソリューションと並列Redoログストレージ
PolarIOソリューションにおけるもう1つの重要なポイントは、ファイルシステムと基盤ストレージの永続化です。書き込みパスでは、データはPolarFSを介してPolarStoreに書き込まれ、100Gb RDMAネットワーク上のAliSCM(メモリに近い低レイテンシの高速デバイス)に送られます。読み込みパスでは、DRAMとAliSCM上に構築された数百テラバイト規模の巨大な