本記事はこちらのブログを参考にしています。
翻訳にはアリババクラウドのModelStudio(Qwen)を使用しております。
PolarDB-XにおけるCCIベースのクエリの一貫性スナップショット構築とキャッシュ最適化
By Siyun
背景
PolarDB-X V2.4 は、クラスタ型カラムインデックス(CCI)に基づくクエリ高速化機能をサポートしています。この機能は、低コストのOSSストレージ基盤上に成熟した列指向SQLエンジンを構築し、優れたパフォーマンス、高いコスト効率、およびクエリ分析用の高速化能力を提供します。CCIベースのクエリ高速化は、ストレージとコンピュートを分離するアーキテクチャに基づいています。列指向エンジンはCCIを構築し、分散トランザクションのbinlogをリアルタイムで消費してCCIに同期し、Object Storage Service (OSS) に保存します。コンピュートエンジン(CN)は、CCIベースのクエリやトランザクションを管理します。CCIベースのクエリの場合、CNはリモートOSSストレージから対応するデータを取得し、MPP(Massively Parallel Processing)計算を行います。コンピュートとストレージの分離アーキテクチャがもたらす便利さと拡張性を享受しつつ、我々は新しい課題にも直面しており、その1つがクエリのトランザクション一貫性と互換性です。これを解決するために、CCIベースのクエリの一貫性、新鮮さ、および互換性を確保するために広範な取り組みが行われています。
一貫性のあるスナップショット構築の原則
CCI ストレージモデル
列指向の一貫性のあるスナップショット読み取りの原理を紹介する前に、まずCCIストレージモデルについて学ぶ必要があります。
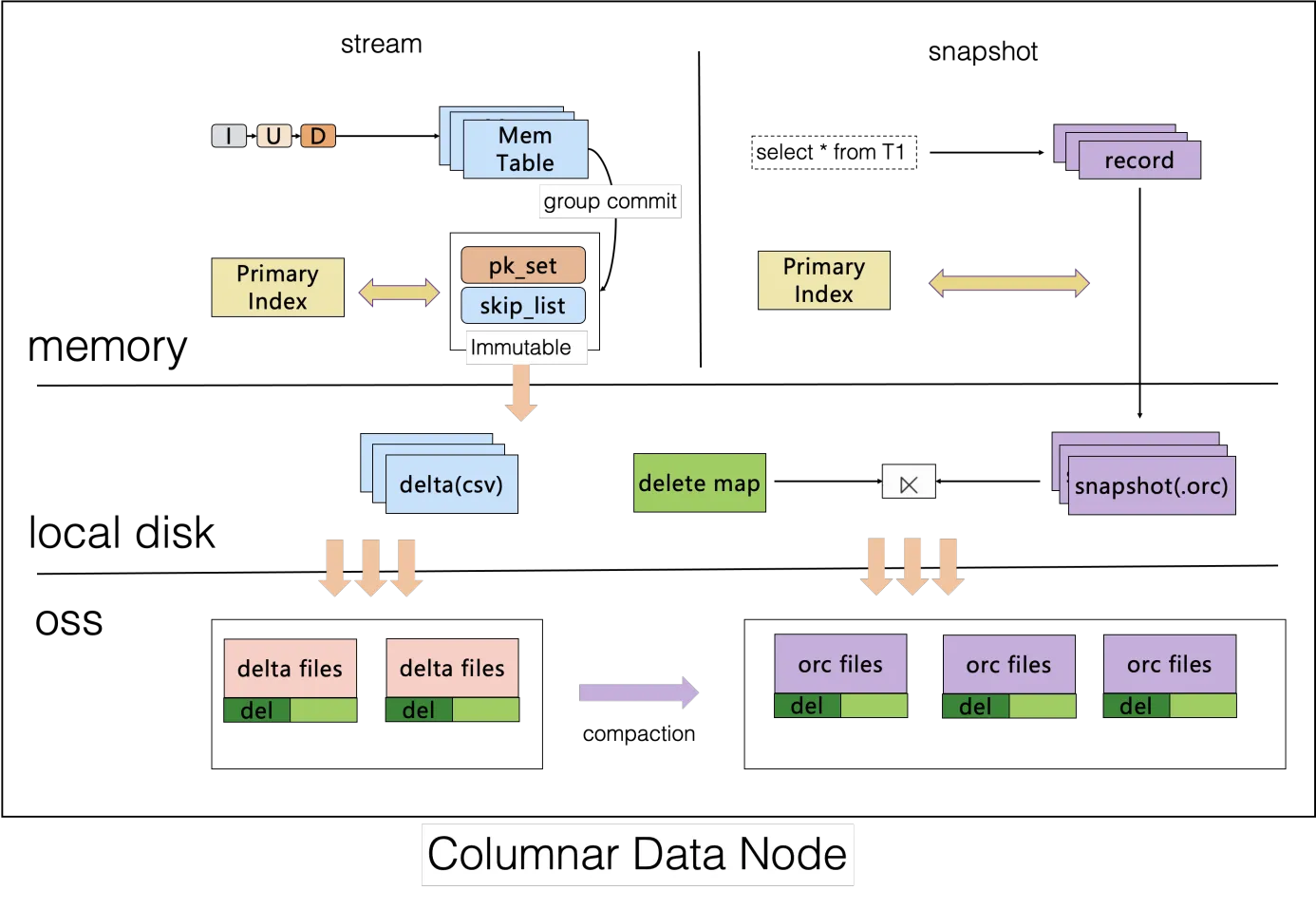
PolarDB-X のCCIは、Delta + Main + Delete-and-Insert 構造で保存されています。データはCSV + ORC + Deleteビットマップ形式でOSSに保存されます。CSVとDeleteビットマップは追記書き込みをサポートしています。増分データのUpdate操作はInsertとDelete操作に分割されます。各グループコミットサイクルでは、InsertデータはCSVファイルの末尾に追加され、Delete操作は主キーインデックスに基づいて削除されたデータを特定し、ビットマップを生成してDeleteビットマップの末尾に追加します。増分データが一定の閾値を超えると、列指向エンジンは非同期的に圧縮を行い、増分ファイルをクエリに適したORCファイルに変換します。Copy-on-WriteやMerge-on-Readのアプローチと比較すると、このモデルは行指向データから列指向データへの低遅延同期を実現し、クエリ側に過度のオーバーヘッドを導入しません。CCIの作成方法の詳細については、「PolarDB-X HTAPの新機能:クラスタ型カラムインデックス」を参照してください。
CCI バージョンチェーンとマルチバージョン同時実行制御
各グループコミットにおいて、列指向エンジンの追記書き込みや圧縮は、新しいバージョンの列指向スナップショットが公開されることを示します。各スナップショットはTimestamp Oracle (TSO)によって一意に識別されます。列指向スナップショットが生成されるたびに、列指向エンジンはGMSにそのスナップショットに関する情報を書き込みます。これには、TSO、追加されたファイルの場所と長さ、圧縮中に削除および追加されたファイルが含まれます。これらの列指向スナップショットは論理的にCCIバージョンチェーンを構成します。次の図をご覧ください。
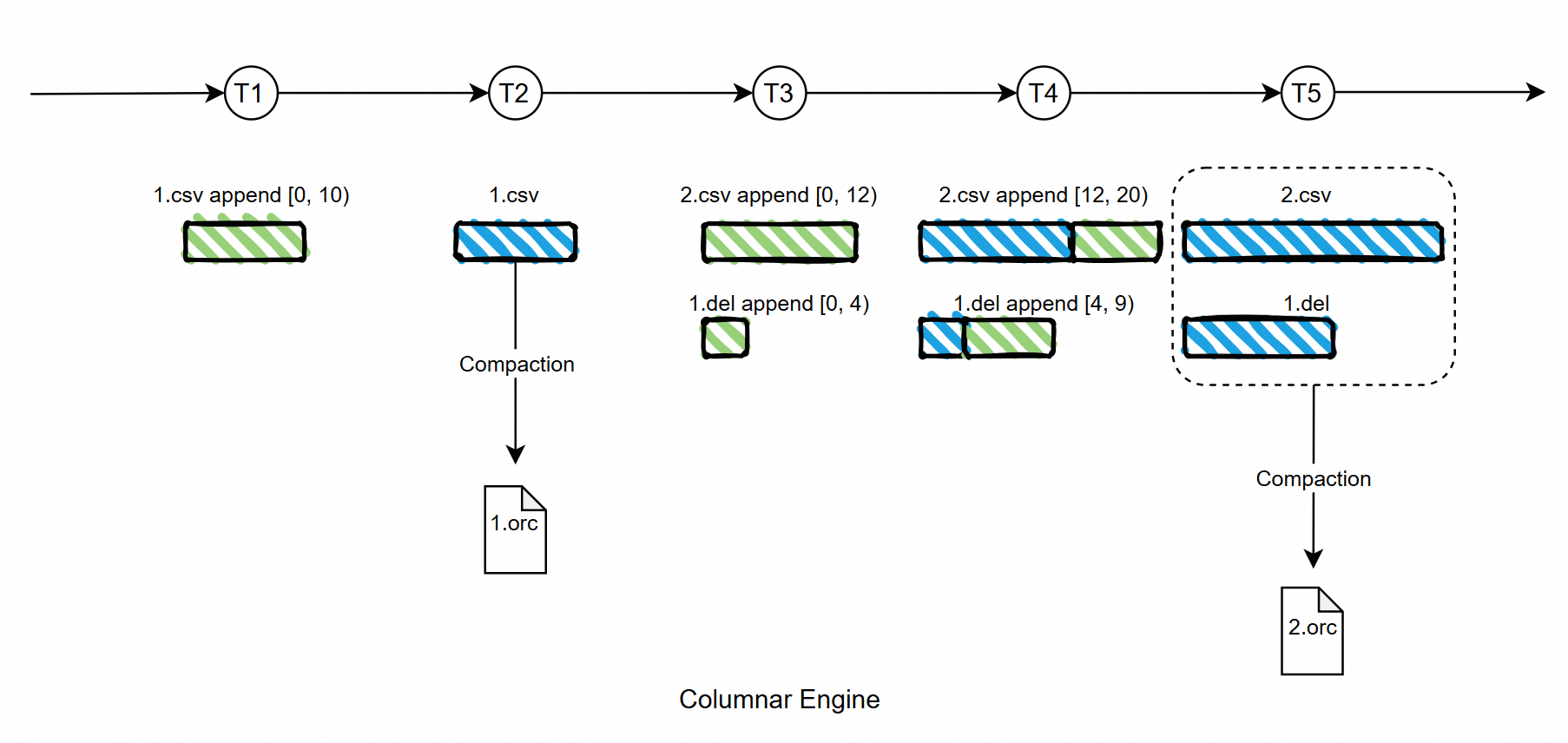
PolarDB-XのCCIベースのクエリでは、マルチバージョン同時実行制御(MVCC)も考慮する必要があります。行指向ストレージとは異なり、CCIへの書き込みリクエストは内部の列指向ノードから来ます。一方、読み取りリクエストはユーザーから直接来ます。結果として、以下のようなモデルに簡略化できます。
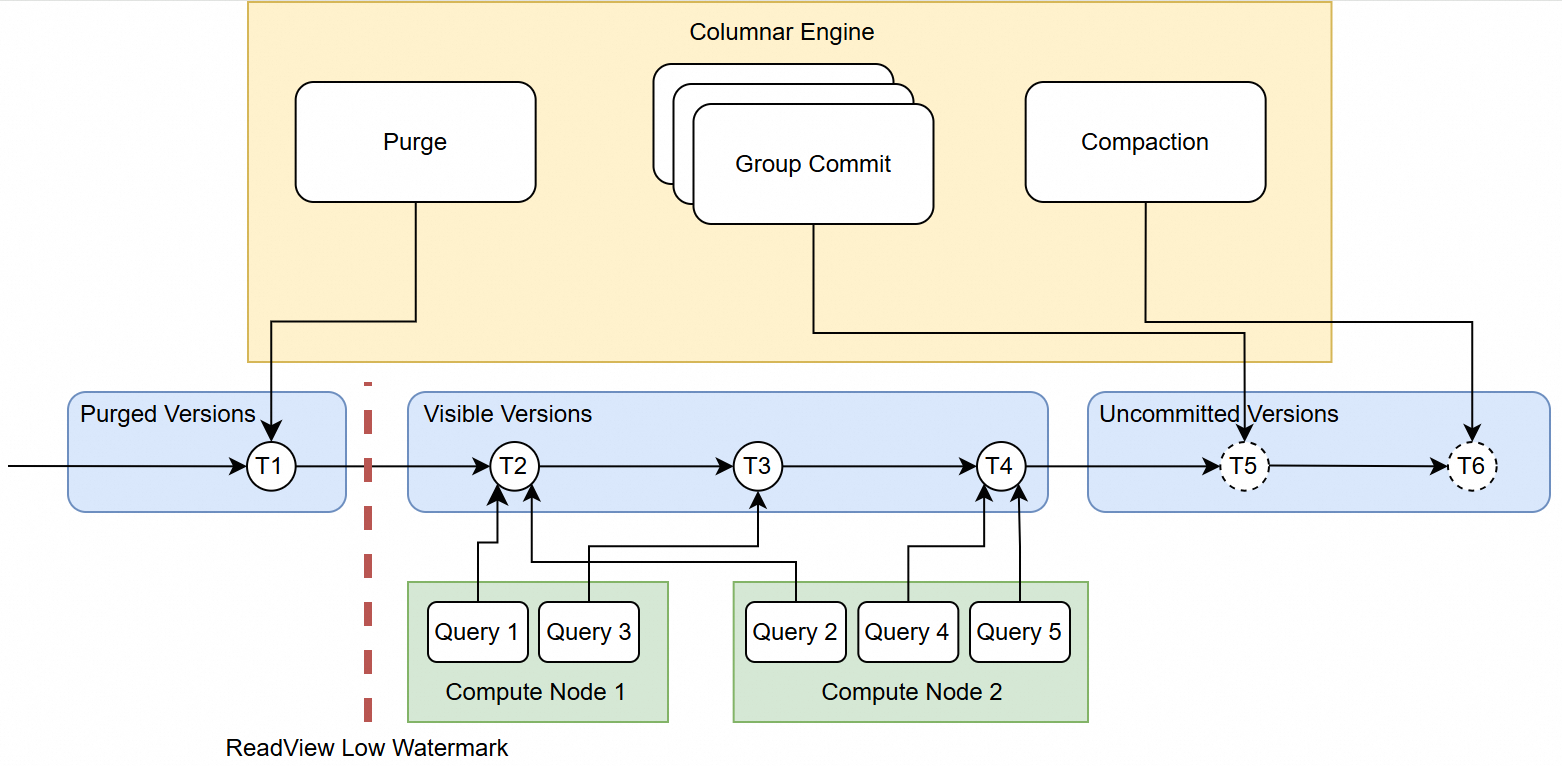
列指向エンジンのグループコミットと圧縮は、2フェーズコミットプロトコルを通じてバージョンチェーンを継続的に拡張します。準備フェーズでは、新しいバージョンがバージョンチェーンに適用されます。増分データがOSSに書き込まれると、コミット操作が行われ、このバージョンチェーン上のノードが外部に見えるようになります。さらに、バージョンチェーンが無限に拡張されるのを防ぐために、列指向エンジンは古いバージョンをクリーンアップする「purge」操作を実行し、GMSおよびOSSのスペースを解放します。列指向クエリエンジンは外部に並列クエリ能力を提供する必要があります。MPPクラスタ内のリーダーCNは、バージョンチェーン内の新しいバージョンを積極的に検出し、それを他のCNにブロードキャストします。これにより、どのCNがトラフィックを受け取ったとしても、そのバージョンの列指向スナップショットをクエリできるようになります。ユーザーからのCCIベースのクエリはランダムにCNにルーティングされます。その後、CNはMPPクエリのコーディネーターとして動作し、バージョンチェーン内の最新の列指向バージョンを見つけ、列指向ReadViewを構築します。列指向ReadViewには、TSO、バージョンに対応する可視ファイルのリスト、および増分ファイルの可視オフセットが含まれます。次に、コーディネーターはReadViewに基づいて列指向スキャンオペレーターを構築し、これらのファイルのスキャントスクをすべてのコンピュートノード(Worker)に特定のルールに従って送信します。ファイルハッシュやパーティションハッシュによるスケジューリングルールに基づき、各コンピュートノードのローカルキャッシュアフィニティを保証します。この機能については次の章で説明します。
スナップショットが早期にクリアされることによるクエリの失敗を防ぐために、リーダーCNは定期的にCN上でアクティブなすべての列指向ReadViewを収集し、アクティブな列指向トランザクションの下位ウォーターマークを取得し、列指向エンジンにそのウォーターマーク以下のバージョンのみをpurgeできるように通知します。CCIバージョンチェーンに基づいて、一貫性のある行・列ハイブリッドスナップショットの機能も提供します。グループコミットメカニズムにより、列指向ストレージへの1回の追記書き込みは複数の行指向トランザクションに対応します。そのため、ハイブリッド行・列クエリでは、行指向と列指向スナップショットの一貫性を確保するために、列指向スナップショットの最新のTSOを使用し、行指向ストレージInnoDBのMVCCメカニズムを利用して行指向ストレージのスナップショットを読み取ります。
MPP一貫性スナップショットの迅速な構築
書き込みキャッシュを使用して増分データをその場でクエリするコンピュート・ストレージ統合システムとは異なり、PolarDB-Xのコンピュートノードは依然として増分データをクエリする際にリモートOSSからデータをプルする必要があります。これには、CCIクエリのレイテンシを減らし、ユーザーエクスペリエン
CSVマルチバージョンキャッシュ設計
書き込み性能とクエリの鮮度を確保するため、増分データには追記可能なCSVファイルを使用します。行ストレージ形式であるため、CSVのクエリ性能はORCよりも劣ります。一方で、CSVファイルは最新の増分データを反映しており、そのクエリ性能がCCIベースのクエリにおけるユーザーエクスペリエンスに直接影響します。増分ファイルの読み取り時にボトルネックが発生すると、データ書き込み時にユーザー側でクエリ性能のジッターが発生します。この問題に対処するため、CSVキャッシュの設計ではデータをできるだけ再利用し、スペースを犠牲にして時間を節約することを目指します。具体的には、行単位で保存されたCSVをコンピュートノード上での列単位で保存されるチャンクキャッシュに変換して、増分データ読み取りコストを削減します。
CSVの追記機能を考慮したシナリオを考えます。例えば、スナップショットT0時点のCSVファイルには2,700行含まれており、スナップショットT1で300行が追加され、さらにスナップショットT2で200行が追加された場合、T2およびT3のクエリに対して最初の2,700行および最初の3,000行のキャッシュを再利用できます。そのため、セグメント化されたマルチバージョンキャッシュ方式を採用し、キャッシュを最大限に再利用します。全体的な設計は次の図に示されています。
! 5
CSVキャッシュはスキップリストを使用して複数のバージョンのキャッシュノードを維持します。リーフノードでは、対応するバージョンに追加されたすべてのチャンクを指します。クエリエンジンでは、データと中間結果はチャンク形式でメモリ内に列単位で保存されます。デフォルトでは各チャンクは1,000行のデータを含みます。CSVキャッシュは直接チャンクを保持することで、CSV行から列への変換のオーバーヘッドなしに実行者がキャッシュデータを利用できるようにします。
前述のキャッシュ構造に基づき、主に以下の3つのプロセスについて説明します:クエリ、新しいバージョンのロード、キャッシュのパージ。
-
クエリ: ユーザーが特定のバージョン(例: T2)のデータをクエリする場合、システムはスキップリストを通じてそのバージョンのリーフノードを特定し、最も古いバージョンからそのバージョンまで順番に追加されたすべてのチャンクを返します。
-
新しいバージョンのロード: 新しいバージョンのデータをクエリするか、またはコンピュートノードがキャッシュを事前にウォームアップする場合、新しいバージョンをロードする必要があります。この場合、コンピュートノードはリモートストレージから追記されたCSV部分を取得し、解析後にチャンクに変換してスキップリストにノードを追加します。
-
キャッシュパージ: 一度に追加されるデータ量が小さい場合、多くのバージョンが生成され、各バージョンのチャンク行数が少なくなり、メモリ断片化が発生します。また、列指向計算の利点を活用できません。そのため、定期的に使用されない古いバージョンのキャッシュをパージし、断片化されたチャンクを大きなチャンクに統合します。削除されたCSVファイルはキャッシュから直接削除されます。
Delete Bitmapのマルチバージョンキャッシュ設計
削除操作の場合、カラムナエンジンは主キーインデックスを使用して、このバッチの削除操作に対応するすべての削除位置(つまり、どのファイルのどの行が削除されたか)を見つけ、ファイルごとに集計してビットマップを生成します。ここではRoaringBitmapをストレージ構造として選択しています。これは高い圧縮率と優れたパフォーマンスを持つためです。対応するRoaringBitmapが生成された後、カラムナエンジンはそれをシリアル化し、固定形式でDelete Bitmapファイルに追記します。クエリエンジンがプルするためです。
CSVと同様に、Delete Bitmapのキャッシュもマルチバージョン設計を採用しています。全体的な設計は次の図に示されています。
! 6
Delete Bitmapのマルチバージョンキャッシュでは、CSVキャッシュと同様に、各バージョンで追加および削除されたRoaringBitmap、対応するファイル(File ID)、およびバージョン(TSO)をロードして解析し、メモリ内でリンクドリストまたはスキップリストとして整理します。ただし、特定のバージョンのビットマップを生成する際、そのバージョン以前のすべての増分ビットマップをマージするのではなく、まず最新のビットマップTをメモリ内で維持し、その後、最新バージョンと異なるバージョンのビットマップを差し引きます(論理XOR)。ユーザーが一般的に新しいバージョンのデータをクエリするため、バージョンチェーンが長い場合、この最適化が顕著に効果を発揮します。
CCIベースのクエリを実行する際、ORCまたはCSVデータとDelete Bitmapをマージし、対応する行を削除して正しいスナップショットデータを取得します。下図に示すように、File ID 2のファイルのT1時点のスナップショットが必要な場合、Bitmap TからΔ3およびΔ2を差し引いてT1バージョンのビットマップを取得し、それをチャンクに適用してT1時点のスナップショットを生成します。
統合メモリ管理とスプライルによる大規模クエリのパフォーマンス低下防止
これらのキャッシュに対しては、過剰なメモリ消費を行う大規模クエリや一部の常駐キャッシュによって全体のパフォーマンスが低下しないよう、統一されたメモリ管理メカニズムを取り入れています。メモリが不足した場合、コンピュートノードはスプライルをトリガーしてキャッシュをディスクに格納し、メモリを解放します。
データプリヒート
カラムナクエリエンジンのキャッシュは、スペースを犠牲にして時間を節約することでパフォーマンスを最適化し、リモートストレージからのデータ取得コストを削減し、カラムストアスナップショットの生成とクエリを高速化します。しかし、新しいデータが書き込まれた際にユーザーが新しいバージョンのデータをクエリすると、そのバージョンのデータがキャッシュにまだロードされていないため、キャッシュミスが発生します。この場合、新しいデータはリモートOSSからしか取得できません。この問題により、CCIクエリにおいてパフォーマンスのジッターが発生します。新しいデータが書き込まれるたびに、対応するCCIクエリがキャッシュミスにより遅延し、ユーザー体験に大きく影響します。そこで、データプリヒートメカニズムを導入し、OSSからメタデータと増分データを能動的にプルして、コンピュートノードのローカルディスクおよびメモリキャッシュに配置します。
増分データのバイパスロード
増分データを処理する際、ネットワークI/Oの回数を減らしアップロード効率を向上させるために、カラムナエンジンはまずデータをローカルディスクにバッチ処理し、その後リモートOSSにアップロードします。比較的新しい増分データについては、OSSに永続化するだけでなく、カラムナエンジンはローカルディスクにもキャッシュを保持します。OSSの追記可能オブジェクトは、初めて新しく書き込まれた
前述の非同期DDLソリューションに基づくCCIクエリのコスト
前述の非同期DDLソリューションに基づくと、CCIベースのクエリのコストはDDL操作の数に正の相関があることが明らかです。特に、同じ列の列タイプを繰り返し変更する場合、最も古いバージョンのデータを複数のステップで変換する必要があり、これは受け入れられません。したがって、カラムナストレージの圧縮タスクも古いバージョンのデータ型を変換し、すべての古いバージョンのスキーマを最新バージョンに変換します。これにより、同じバージョンのスナップショットには複数のバージョンのスキーマが含まれなくなり、後続のCCIベースのクエリのオーバーヘッドが軽減されます。
フルタイプ互換性
MySQLエコシステムに基づき、PolarDB-X のCCIベースのクエリは、行指向クエリと同じタイプの互換性を提供します。CSVファイルの場合、MySQLネイティブのBinlog Write_rows_log_event と互換性のあるストレージ形式を採用し、クエリ中に解析します。ORCファイルの場合、ネイティブのORCフォーマットはMySQLのタイプシステムと直接互換性がないため、特にdecimal、timestamp、stringなどのタイプに対して大規模な修正と最適化を行いました。これにより、圧縮率が向上し、MySQLタイプとの互換性が確保されます。DDLが発生した後、列指向クエリエンジンはクエリ中にタイプを変換する必要があります。行指向クエリと同じMySQL互換性を確保するために、MySQLロジックに従い、数値精度やデータの切り捨てなどの問題を適切に処理します。