
自然非言語処理とは
みなさんは、友達と出会ったら、「おはよう」と言いながら手をあげたり、職場の人に会ったら、「お疲れ様です」と言いながら会釈したりした経験はないでしょうか。
これまでの研究によると、人と人とのコミュニケーションには、「おはよう」といった言語的コミュニケーションと、手をあげるといった非言語コミュニケーション ( Non-verval communicaiton) に大別されることが分かっています。
しかし、人と機械がコミュニケーションする場合はどうなのでしょうか?
一般に、人と機械とで言語的コミュニケーションを図る技術は自然言語処理と呼ばれており、研究分野として確立されています。一方で人と機械とで非言語コミュニケーションを図る技術はいまだに研究分野として確立されていません。
そこでそのような研究分野を自然非言語処理と勝手に作りました。
そもそもまず非言語コミュニケーションとはどうやって行うのでしょうか。
非言語コミュニケーションの取り方
コミュニケーションとは記号論において、記号表現を交換することにより相互に記号内容を思い出させる行為であると話しました。
ここで記号とは「世界にある物や事そのものの“代わり”に自分や相手の頭の中にイメージさせてくれる物事(記号表現)とその脳内イメージ(記号内容)のこと」を指します。
記号表現は言語でも良いですが、写真やイラスト、音声など非言語情報も含まれます。
具体的には以下の過程をへて、記号によるコミュニケーションは行われます。

- 送り手は何かを動機として記号内容が脳内に浮かぶ。
- 送り手は記号内容を記号表現に変換する
- 送り手は記号表現を基に音声やジェスチャーなどの運動に変換して、記号表現として実世界にて表現する。
- 受け手はそれぞれの記号表現を感覚器をつうじて、記号内容を脳内に浮かばせます。
- こうして送り手の記号を受け手の中に浮かばせて、送り手が送りたかった記号を理解するのです。
しかし、そもそもこれらの記号表現はどのようにして人間に認識され、どのように表出されるのでしょうか。
エージェントモデルによる人間のモデル化
人間を入力と出力、その間に何らかの処理が入っているというモデル、エージェントモデルで表現できると考えましょう。
非言語情報を入力するためには様々な感覚を入力する必要があります。
たとえば、イラストであれば視覚、音声であれば聴覚と言った具合になります。
しかし、それらの感覚は単一で認識されるだけではなく、統合されても認識されます。
これをマルチモーダル認識と呼びます。マルチモーダル認識や概念システムと連携することで、
刺激が概念などの記号内容と結びつくことができると考えられています。
逆に、運動野や小脳などが連携し、記号表現を運動計画に変換することで、記号表現を表出することができます。
エージェントモデルの実装
エージェントモデルを利用して人間の機能を模倣するために作られたアーキテクチャを認知アーキテクチャといいます。その認知アーキテクチャは脳機能の局在化により、ROSなどのモジュールで分割し、それらを統合するモジュールで構成できそうです。たとえば、以下の図1のようになります。図1では画像認識や音声認識を独立のモジュールで行っていながらもそれらを統合するマルチモーダル認識モジュールが付け加わっています。このように単一のモダリティだけではなく、複数のモダリティも統合して実現することが好ましいでしょう。
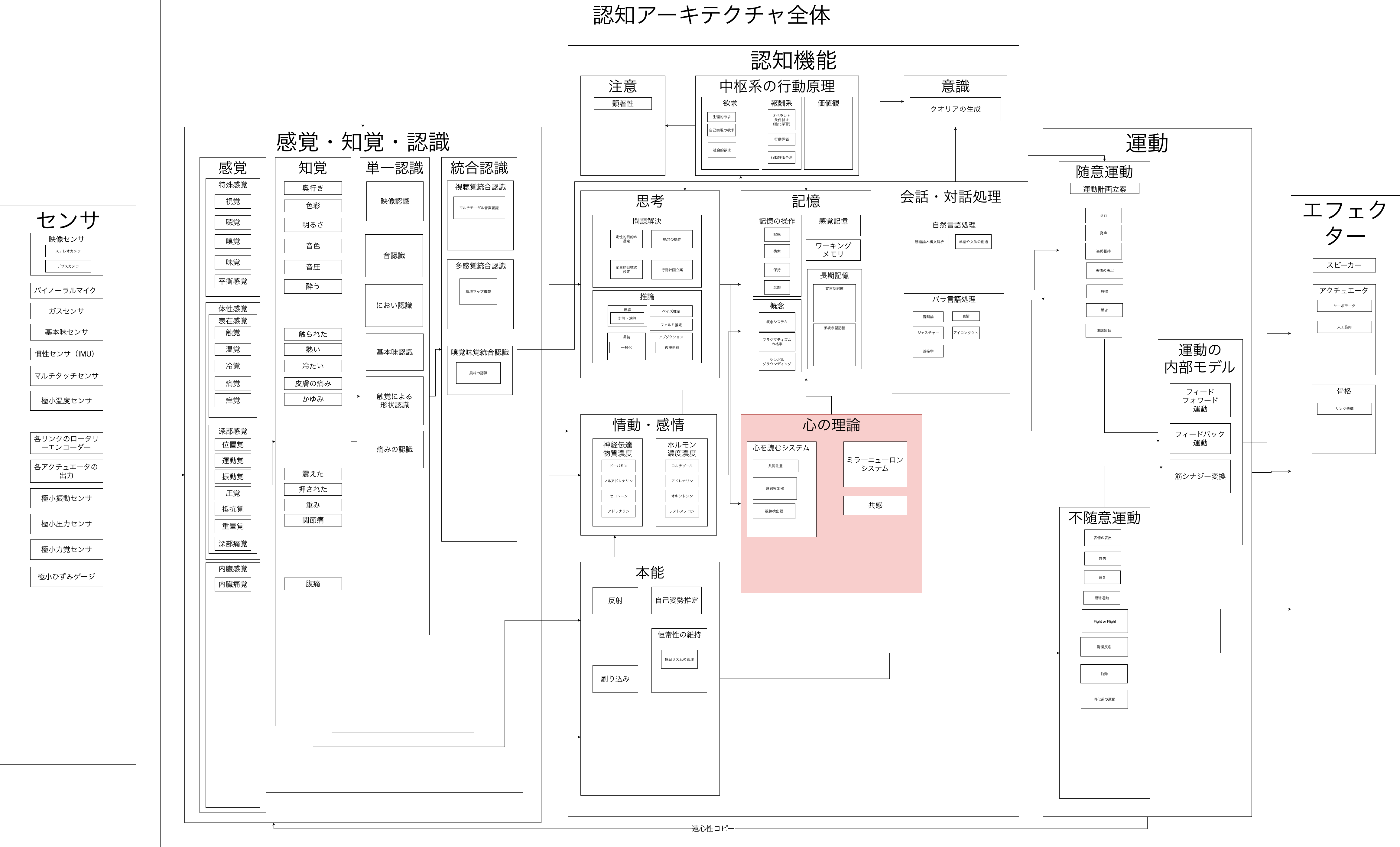
図1 認知アーキテクチャの例
なぜ我々はコミュニケーションを行うのか。
ではなぜそんな複雑な機構になっている我々はコミュニケーションを行うのでしょうか。
それは人類の恒常性を維持するためです。
コミュニケーションとは生態系を含む環境に生きる人間というエージェントモデルが他のエージェントモデルと意志決定するためのツールであり、それは人類というマルチエージェントシステムが環境から淘汰されないようにエージェント間を制御するための手段であろうと考えられます。
ではなぜ我々は機械とコミュニケーションを行うのでしょうか。
たぶん操作するよりもコミュニケーションで済ませたほうが楽だからです。
そして、それは人類の恒常性を維持するためでもあるのです。
しかし、コミュニケーションにも限界はあります。それは意識そのものの伝達です。
意識を伝える方法とは
子供の頃からおそらく脳をくっつけないと意識は共有できないと思われます。
そういう意味では脳活動を共有している双子の姉妹は意識を伝えあっていることができているのだと思います。

しかし、その意識を我々にそのまま伝えることは現代ではできないでしょう。
たとえば、意識の一部であるクオリアを共有することを考えてみると、同じ赤いリンゴを同じ視点で見てても、個々人では脳活動が微妙に異なるため、どのような脳活動を引き起こせば、同じクオリアを共有できるのかよくわかりません。
我々がこの壁を超えなければ、つまり、質そのものを取り扱う技術を確立しなければ、この問題には太刀打ち出来ないと考えられます。
我々はなぜコミュニケーションしてまで人類の恒常性を維持する必要があったのか。
じゃあ、なぜ我々はなぜコミュニケーションしてまで人類は恒常性を維持する必要があったのでしょうか。
逆です。進化論を前提とするならば、人類が生きる機能に優れていなければ、そもそも進化の過程で淘汰されてしまっているのです。
つまり、人類が生きている、人間が生きているというのはただの結果論の1つであって、高尚な理由なんてないのです。
「どうせ生きる意味なんてないんだから、自分でかってに作っちゃおうぜ」みたいなニーチェが言う積極的ニヒリズムが人生には必要なんだと思います。
まとめ
我々人間は人類の恒常性を維持するためコミュニケーションを行ってきました。
これまでは人類の恒常性を維持するため操作する一方だった機械もその機能が煩雑化していくに連れ、
人間のコミュニケーションのようになっていくでしょう。
そのとき、人類の恒常性を維持するため、人と機械はコミュニケーションを行っていくのでしょう。
労働から開放された人間は、人生にどのような意味付けをしていくのでしょうか。
今後の人間に託された課題なのだと思います。
あとがき
「自分とはなんだろう」
と疑問に思うことは読者の方にもあったとは思います。
私がそれを考え始めたのは、物心が付いた頃だったと思います。
当時は全くわかりませんでした。(今も全くわかりませんが)
「自分とはなんだろう」という疑問が結びついたのは、
とある漫画がきっかけだったと思います。
その漫画は医療に関する学習漫画でしたが、
**「ロボットを作ることで人間というものを合わせて知ることができる」ということが書かれていました。
おそらくその本はヒューマン・ロボット・インタラクションの世界的権威、石黒先生の発想を紹介されただけだと思います。
その発想を見て純粋だった私は、「自分を理解するためには自分を作ってしまえばいい」**と考えたのです。
今思うとなかなか頭のおかしい発想ですが、このアプローチは正解だったと今でも自信を持って言えます。
なにかと自信のない私ですが、この信念だけは自信があります。
やがて中学3年になった私は人工知能を作りたいというほんわかした思いを持ちながら、
普通高校ではなく、高専の情報工学科に進みました。
これは高校受験への勉強の無駄さに辟易していたところもあったためです。
情報工学科に進むと人工知能の現状を学ぶにつれ、
現代の人工知能はただ言葉という中身のない記号をいじくり回しているだけではないか。
と感じるようになり、言葉を超えた外の領域に着目すべきだと感じるようになりました。
この認識が最初の非言語コミュニケーションへのはっきりとした興味を示したときでした。
私が行った最初の研究は高専の卒業研究である表情認識でした。
当時、表情認識の技術はまだ発展途上にあり、
そこらへんのWebカメラとノートPC上で動いて手軽に試せる対話用のリアルタイムシステムは
そこら辺にはありませんでした。
そこで実際に開発し、認識精度を測った思い出があります。
何もかもが稚拙で今思うと恥ずかしい内容の研究でした。
そこから、属性認識による顔画像検索、画像情報と視線情報による画像の選好予測などの
研究を行いました。
どれも抽象的で非言語的要素が含まれる研究ではあります。
しかし、こうやって自分を作るには無限に近い課題、それを解くための無限に近い時間を必要とします。
そこで私は自分の中で特に理解したかった「心の理論」を中心に実装していこうと考えました。
これが社会人3年目頃の話です。
現在、社会人4年目ですが、
まもなく私の研究者としての人生は幕を終えると思われます。
このアドベントカレンダーは、そんな私が理解した非言語情報に対する人間のメカニズムと、メカニズムの実現方法について、半ば遺言としてまとめたかったところであります。
別に死ぬわけではありません。
今後はおそらく開発者、あるいは管理職としてのキャリアを歩むのだと思われます。
不本意ではあります。
しかし、日本のありとあらゆる会社に、組織に転職活動を行った結論として
日本という社会がそれを望んでいるのなら、日本に住む私は従わざるをえないのだと思われます。
ただ、最後にこのような形で残して、誰かの役に立てられるのであれば、すこしでもこの思いは成仏されるのかと思い、
筆を置かせていただきます。