
われわれは他人が表現した記号表現を見て、記号内容と結びつけて、相手の伝えたかったことを理解します。たとえば、相手がチョキのジェスチャーをしていれば、じゃんけんのチョキを出しているんだなと理解します。
しかし、機械が物理的な刺激を記号に結びつけるにはどうしたらいいのでしょうか?
これをシンボルグラウンディング問題と言います。人工知能の難題の一つです。
記号の日ではここまで話をしました。今回は、シンボルグラウンディング問題を2段階に分け、その解決の糸口について説明します。無数にある記号表現を特定する技術、パターン認識と、認識された記号表現を記号内容に結びつけ、他の記号内容と関連づける技術についていくつか紹介しましょう。
今回は人間のメカニズムと機械のアルゴリズムを対比させながら、説明します。
物理的刺激を記号表現に結びつける技術、パターン認識
かの有名なアインシュタインはこれまでの物理学の世界観、
静止している三次元空間とそれが連続している時間とで分離して考える世界観を、
時間と空間は一体である時空間という世界観に塗り替えました。
ここから、物理的刺激は空間だけに存在するわけではなく、時間方向にも存在していることがわかります。
たとえば、第x日目の心理物理実験を思い出していただけるとわかりますが、
画面の中央に写真で表現された**「有村架純」という記号が突然**現れるという現象が世の中には起きるわけです。
したがって、物理的刺激を記号表現に結びつけるには、どこに、なにが、いつという3つの情報を抽出する必要があります。視覚的刺激を人間が受けた場合、これらは、大脳皮質の背側経路、腹側経路、そしてそれらの認知の処理過程として認知されます(ただし、人間が時間を感じる理由は諸説あるため、あくまで一説だと思ってください。)。
一方、機械が物理的刺激を記号的表現に結びつけるときは、どこに、なにが、いつという3つの情報を抽出することをそれぞれ独立して抽出するアプローチをとったり、同時に抽出するアプローチがあります。前者をアプローチを取る場合、それぞれの情報を抽出する問題を(空間的)検出問題、認識問題、(時間的)検出問題としてそれぞれ別々に解かれています。例えば、先程あげた有村架純の顔認識の場合、(空間的)検出問題はAdaBoostとmeanshiftという手法で解かれ、認識問題は固有空間法など、(時間的)検出問題は(空間的)検出問題を最初と最後に解いた時間、あるいは解いてからparticle filterという手法で追跡した時間として解かれます。一方、後者のアプローチでは、主にニューラルネットワークを用いて同時に解くことが多いです。例えば、物体の種類を当てる問題の場合、YOLO v2などがあります。余談ですが、視覚的な認識問題には3段階あります。まず、物体の種類を当てる一般物体認識があります。次に、その物体の種類、たとえばアリの中でさらにどんなアリなのか、たとえばヒアリなのかを調べる詳細画像識別[1]があります。最後に顔認識のような、具体的にどんな個体なのかを調べる特定物体認識があります。
パターン認識を実装するアプローチ
パターン認識には主に2つのアプローチがあります。1つ目はルールベース、もう1つは非ルールベースです。
ルールベースとは既存の知識や法則から主にif-thenルールを導き出して問題を解く方法です。
例えば、顔を検出する際には、肌色の領域の中に肌色でない3つの領域(左目、右目、口)がある場所を顔の場所とする方法があります。ちなみに、この法則は人間が3つの点を見ると顔と錯覚する現象(シミュラクラ現象)を応用しています。
一方で、非ルールベースとは、既存のデータからコンピュータに複雑な法則を導き出させて問題を解く方法です。例えば、顔を検出する際には、顔の写真と顔でない写真を数万枚用意して、学習器というアルゴリズムに顔検出の法則を導き出させます。ちなみに、先程紹介したAdaboostとは学習器のうちの1つです。もちろんYOLO v2などのディープラーニングもこの学習器の1つになります。
現在ではパターン認識を実装するアプローチとして、非ルールベースが主流になっています。人間が世の中の法則を細々と導き出すのは時間的限界があったり、そもそも人間が世の中を客観的に見ることができなかったりするからです(c.f. 錯覚、認知バイアス)。ただし、データが十分に集まらないときや集められないときはルールベースで問題を解くことも1つの有効な作戦ではあるでしょう。データ収集の重要性を経営者がよくわかっていればわざわざルールベースなんて時代遅れな手法を使わなくてもいいのにね、ほんと
記号表現を記号内容に結びつける技術
記号表現を記号内容に結びつける技術は実は体系化されていません。まだ、工学的にはほとんどどわかっていないと言ってもいいでしょう。そこで関係してそうな技術をいくつか上げてみます。
1つはセマンティックネットワークです。これは記号表現を幾つかの概念と手動で結びつけたグラフ構造のことを言います。例えば、「猫」といえば、「4足歩行」、「哺乳類」という記号と関連付けらますが、これをエッジという矢印とその意味をセットで表現します。ただ、あまりに人工的すぎるのでこれを機械が獲得するのはWebページを収集しないと難しそうです(c.f. セマンティック・ウェブ)。
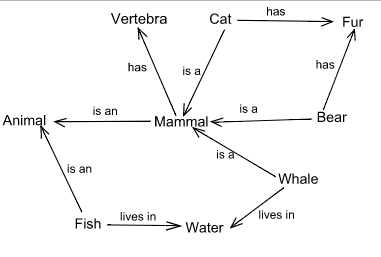
図 セマンティックネットワークの例
1つはWord2Vecです。これはニューラルネットワークを使って、入力されたたくさんの文章を基に単語の集合を低次元のベクトルで表現する技術です。Word2Vecを使うと、単語の足し算と引き算ができるようになります。たとえば、「パリ」-「フランス」+「日本」=「東京」などがあります。こうやってみると、記号内容の1つである意味を理解して演算しているのではないかと思われます。これがうまくいく理由として、Word2Vecにたくさんの文章が入力されるときに、文章に出てくる単語の前後関係を使って低次元のベクトルに表現しているかららしいです。これが、分布仮説という人間の意味を獲得するメカニズムに似ているということから、意味を獲得しているようにみえるのではないかとしています。詳しくは統計的意味論について調べてください。
記号表現を記号内容に結びつける技術は工学的には全くわからない一方で、人間の仕組みは徐々にわかってきています。そのきっかけとなったのは、おばあちゃん細胞仮説です。おばあちゃん細胞仮説とは、おばあちゃんという言葉やおばあちゃんの写真、おばあちゃんのイラストなどの記号表現に対し、1つの細胞が1つの概念といった記号内容を管理しているという仮説です。実際、ハル・ベリーという有名人に対して、選択的に反応する神経細胞が見つかったとする研究[3]もあります。ただ、反論もあったりはするので、確実にそうだとは言えないところもあります。
ただ、記号表現と記号内容をそもそもどうやって獲得するのか話に関しては、よくわかっていません。この過程は哲学の世界ではわりと解決されており、プラグマティズムの格率という言葉で説明されています。プラグマティズムの格律を噛み砕いて説明すると、
概念とは対象を操作して得られた結果のすべてである。
となります。意味がわからなすぎて、これを最初に言った人は相当あれな薬を決めていたのではないかと疑われます。 たとえば、鉛筆という概念を獲得するとき、我々はどうするでしょうか。赤ちゃんを見てるとわかると思いますが、たぶんまず、口に突っ込むと思うんですよね。そうすると苦くて食べられないという概念を獲得できます。次に紙にこすりつけてみると、何か黒い線がついてきます。すると、鉛筆とは食べるものではなくて、線を書くものだという概念を獲得できます。プラグマティズムの格率とはこういった経験論を一般化して説明したものになります。
以上から対象を操作する体がないと概念などの記号内容を機械が獲得できないのではないかという疑問が浮き出てきます。これを身体性の問題といいます。一方でWord2Vecのように自然言語処理をするだけで意味っぽいものがわかりそうだぞとなることがあります。身体性とは何だったんでしょうか。ますますわけがわからなくなったという次第です。
実装
今日は実装はありませんが、
代わりに実装する具体的な手法とアプローチを紹介したので許して下さい。
本当は前処理についての議論も入れようとしました。
まとめ
機械が物理的な刺激を記号に結びつけるにはどうしたらいいのか、紹介しました。
今回はこの問題の解決策を物理的な刺激を記号表現に、記号表現を記号内容に結びつけるという2段階で説明しました。
なお、これを直接解く方法として、記号創発ロボティクス[2]という方法も提案されています。
未だに解決されていない問題ではありますが、着実に解決されつつある問題となります。
参考文献
[1] http://www.nlab.ci.i.u-tokyo.ac.jp/pdf/ssii2014fgvc.pdf
[2] http://sercrest.com/
[3] http://www.natureasia.com/ja-jp/nature/highlights/4380