
聴覚によるコミュニケーション
われわれは音声によるコミュニケーションをしばしば行なっています。
道端で雑談したり、オフィスで会議したり、LINEで無料電話したり、固定電話で有料電話してくださる奇特な方もいます。
さて、音声で会話することは言語コミュニケーションなのでしょうか?非言語コミュニケーションなのでしょうか?
答えはどっちの要素も含まれているコミュニケーションです。
なぜなら音声には言語、感情などの記号が含まれているからです。
例えば、部下の失態を上司が叱る際には
「いい加減にしろ!」
と大きな音量で強い怒りの感情を込めて話しますよね。
他にも、風邪をひいている時に上司と電話するときには
「本日休みをいただいてもよろしいでしょうか?」
と、謝罪する気持ちと鼻声でゆっくり喋るでしょう。
そこで今回は感情を込めて喋ると、機械が感情を含んだ声で返答してくれるシステムを作りましょう。
また、それだけではなく、テンションが低いと反応が単調になり、テンションが上がると、反応が豊かになる
そんな人間っぽい機械を作ってみましょう。
では、恒例の聴覚メカニズムを説明します。
聴覚のメカニズム
音声から記号に変換するメカニズム
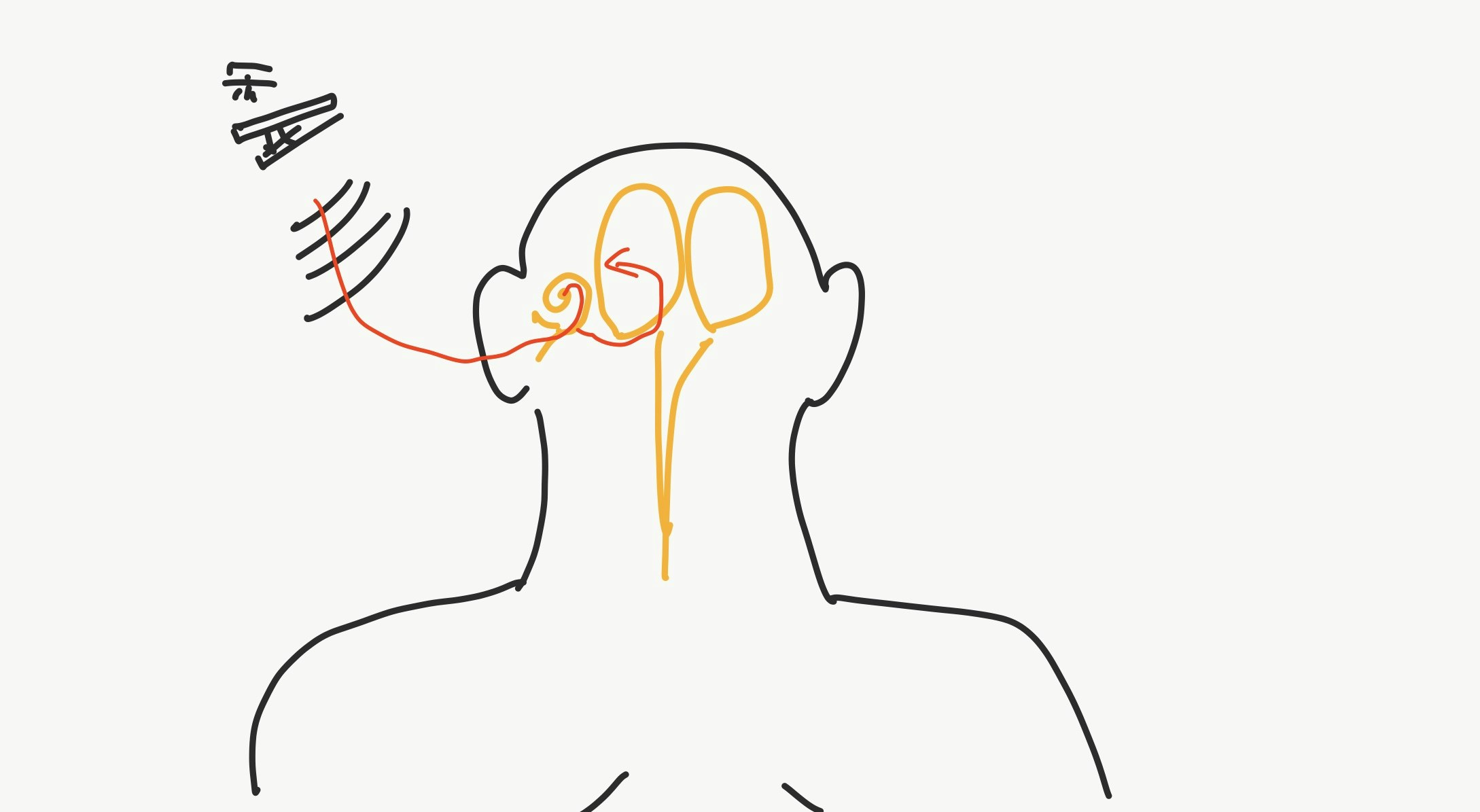
まず、音が発生するところから始めましょう。
物と物が衝突すると物体が高速で振動します。ハイスピードカメラで見ると、物体の衝突ってわりとブルブルしてることがわかります。おもしろいです。
で、グニャっとすると空気が押されて圧縮されます。その後、反対側にグニャとすると空気が引き延ばされます。
この密度の差、つまり振動が空間中に球状に広がり、耳介にぶつかり反射して、やがて人の耳に入ります。耳に入ると鼓膜があり、空気の振動に合わせて震えます。鼓膜が震えると鼓膜にひっついてる耳小骨を介して内耳の蝸牛に振動が伝わります。蝸牛の中には有毛細胞があり、その有毛細胞が振動することで蝸牛神経に刺激を与えることができる。一口に有毛細胞と言っても、振動する周波数やエネルギーは有毛細胞ごとに異なっています。これにより音の高さや大きさを感じ取ることができます。他にも自分の声や骨から振動を受け取って聞こえたり、鼓動やらの振動も感じ取れます。
その後、蝸牛神経が受け取った刺激は外側毛帯、中脳の下丘を通り、内側膝状体、一次聴覚野へと順に伝えられます。ここまでくると、やっと音を知覚することができます。
一次聴覚野では、周波数への反応有毛細胞と同じように特定の周波数に特定の神経細胞が反応します。一次聴覚野で処理された情報は高次聴覚野に伝わり、視覚野と同じように、どこに、なにの音波があるのか認識します。
また、この過程で扁桃体を通るため、情動の判定をしていると思われます。
このように音声は言語情報だけではなく、情動を扁桃体で、一次聴覚野でイントネーションなどの韻律などを感じ取っているため、非言語情報も同時に含まれています。言語が伴う非言語情報をパラ言語(Paralanguage)、または周辺言語と言います。研究者によっては非言語と周辺言語は別と言う人もいますが、僕はめんどくさいので非言語の中にひっくるめて説明します。(雑)
記号から音声に変換するメカニズム
ここのあたりは時間の都合上運動の項目に回します。
聴覚の特性
- 人間が得る情報のうち11%が聴覚によるもの[4]と言われています。
- 聴覚は指向性を持つものの、基本的にあらゆる方向から刺激を受けることができます。また、その方向を特定することができます。また、視覚を司る目と違い、耳自身は刺激を遮断することができません。刺激を遮断するには指で塞ぐなどの工夫が必要となります。
- 音声の中には言語情報だけではなく、周辺言語情報も多分に含まれます。例えば、イントネーション、語調などの韻律や情動、間をつなぐためのフィラー「えーっと」、たんが絡んだときの咳などがあります。
- 人間が聞こえる周波数は約22kHzまでと言われます。ただ、年をとると高い音が聞こえなくなったり、そもそも個人差があったりして、ばらついています。
- 人間が聴覚で聞こえるのは22kHzまでですが、その他の要因でもっと高周波が聞こえるのではないかとしている説(ハイパーソニック・エフェクト)とがあります。が、あやしいです。
聴覚に関わる非言語処理
ソフトウェア
機械に聴覚の能力を与える非言語処理は信号処理の中の音声処理の1つとして体系化されています。
聴覚に関わる信号処理は、フィルタリング、フーリエ変換、話者認識、音声認識、感情分析、音声合成、音源分離、音源定位、音声圧縮、立体音響などがあります。
視覚と同じく現在ディープラーニングにおかげで絶賛開拓中となっております。
このうち、コミュニケーションで役立ちそうなのは、音声認識、感情分析、音声合成、音源定位ぐらいでしょう。
音声認識とは音声から言語を抽出する技術です。有名なアプリケーションは、「OK, Google」ってやつですね。
要素技術としてパターン認識、機械学習があります。
有名な開発ライブラリはTensorflow, chainerなどがあります。
また有名なWeb APIには、GoogleのGoogle Cloud Speech API, NTTの音声認識APIがあります。
音声合成とは言語や周辺言語から音声に変換する技術です。有名なアプリケーションは、「目的地まであと10分です」ってやつですね。
要素技術として機械学習(WaveNet)があります。
有名な開発ライブラリはTensorflow, chainerなどがあります。
また有名なWeb APIには、MSのBing Speech API, NTTの音声合成APIがあります。
感情分析とは音声の中に含まれる周辺言語情報を解析して、話者の感情を分析する技術です。
有名なアプリケーションは、「感性制御技術ST」があります[5]。
音源定位とは音源の位置を推定する技術です。
有名なアプリケーションは、Kinectがあります。
Kinectはただのモーションキャプチャーと思われがちですが、
音声認識機能や音源定位機能も備わっています。
ハードウェア
聴覚に関わるハードウェアには、人間の鼓膜に相当するマイクがあります。
マイクの中にも、音源定位や音源分離するためにマイクを複数台並べたマイクアレイ、人間の聞こえ方と同じようにマイクを配置したバイノーラルマイクなどがあります。
また、マイクから受けた電流をデジタル化するためにA/D変換器の性能が重要になってきます。
逆に人の声などに相当するスピーカーも重要です。スピーカーの中にも、人が知覚しにくい低音域を大きく再生するサブウーファーや人間の音源定位を有効にするサラウンドスピーカーなどがあります。
また、デジタル音源を電流に戻すためのD/A変換器、電流を増幅して音量を上げるためのアンプがあります。
音声認識や音声合成のための半導体GPGPUや分散処理基盤、通信の分野が関わってきます。
実装: 音声による感情コミュニケーション
今回、音声入力の感情認識はWebEmpath社の技術WebEmpath Web API[2]を使います。
また、感情を込めた音声合成はHOYA社のVoiceText[3]を用います。
そうやって他社の技術を使って実装するつもりでした。
が、世の中甘くないようです。
法人アカウントがないと試用できないようです。
やんぬるかな
そう思った矢先に音声認識の研究をしている同期から
HEARTalkを紹介してもらいました。
HEARTalkとは人間が話した言葉の韻律を解析してくれるボードで、
ちょうどいい感じの韻律で返答してくれます。
HEARTalkと感情モデルを使った会話をしましょう。
具体的にはテンションが低いと返答が単調になる一方ですが、
テンションが高くなると返答が豊かになる感じの会話になります。
材料
開発用PC(Mac) 1
韻律解析装置HEARTalk UU-002 1
シリアル通信用マイコンArduino Uno 1
ブレッドボード用USB端子 1
mini-BのUSBケーブル 1
ブレッドボード 1
ジャンパワイヤ多数
ピンヘッダメス多数
回路
今回はHEARTalkが主役になります。
ただ、HEARTalkとMacは直接繋げられません。
そこで、Arduinoを間に挟んで、HEARTalkの解析結果を
Macに伝える回路を作ります。
回路図は以下のとおりです。

この回路を作るためには、HEARTalkの開いている穴の一部に
ピンヘッダ(メス)を差し込む必要があります。
今回関係してくるピンは
- マイク設定用ピン: B7,B4
- 音グループピン: A2,A1,A0
- 音程ピン: A7,A6,A5,A4
なお、場所は基板の表面に書かれています。

当然、ハンダづけする必要があるため、
結構根気のいる作業になります。
がんばりましょう。
ぼくはがんばりました。
完成した写真が以下のとおりです。

ArduinoとHEARTalkを使って、韻律解析マイクを作っているみたいな感じでいいかと思います。
ソースコード
ソースコードは以下のとおりです。
//HEARTalkとPCをシリアル通信でつなげるためのコード
char pinA2=2;
char pinA1=3;
char pinA0=4;
char pinB7=6;
char pinB4=7;
char pinA7=8;
char pinA6=9;
char pinA5=10;
char pinA4=11;
int micConfig;
int micPreviousConfig;
int soundGroup;
int interval;
void setup() {
// put your setup code here, to run once:
Serial.begin(115200);
//マイク設定用ピン
pinMode(pinB7, INPUT);
pinMode(pinB4, INPUT);
//音グループピン
pinMode(pinA2, INPUT);
pinMode(pinA1, INPUT);
pinMode(pinA0, INPUT);
//音程ピン
pinMode(pinA7, INPUT);
pinMode(pinA6, INPUT);
pinMode(pinA5, INPUT);
pinMode(pinA4, INPUT);
}
void loop() {
// put your main code here, to run repeatedly:
micConfig=digitalRead(pinB7)<<1;
micConfig+=digitalRead(pinB4);
//ネガティブエッジ駆動
if(micPreviousConfig>0 && micConfig==0){
soundGroup=digitalRead(pinA2)<<1;
soundGroup=(soundGroup+digitalRead(pinA1))<<1;
soundGroup+=digitalRead(pinA0);
interval=digitalRead(pinA7)<<1;
interval=(interval+digitalRead(pinA6))<<1;
interval=(interval+digitalRead(pinA5))<<1;
interval+=digitalRead(pinA4);
//なんとなくJSON形式でPCに吐き出す
Serial.print("{\"soundGroup\":\"");
Serial.write('a'+soundGroup);
Serial.print("\",\"interval\":");
Serial.print(interval);
Serial.println("}");
delay(1000);
}
micPreviousConfig=micConfig;
}
こちらがPC側のコードになります。
HEARTalkの結果をArduino経由で受け、
PCで人間っぽいものの感情を変動させながら返答する音声ファイルを再生している感じです。
# !/usr/bin/python
# -*- Coding: utf-8 -*-
"""
機械(バーチャルエージェント)と人がパラ言語でコミュニケーションするためのプログラム
"""
__author__="alfredplpl"
import cv2,serial,json
import subprocess
import os
import numpy as np
## 定数群
WAIT_TIME=100#[ms]
# 人間っぽいものクラス
class Agent():
def saturate_cast(self,x):
return max(-1.0,min(1.0,x))
def __init__(self):
self.emotion={}
self.emotion["valence"]=0.0
self.emotion["arousal"]=0.0
self.arduino = serial.Serial('/dev/cu.usbmodem14641', 115200,timeout=0.032)
def __del__(self):
#お片付け
cv2.destroyAllWindows()
self.arduino.close()
def isStimulatedViaAudioChannel(self):
#ArduinoからHEARTalkの解析結果を受け取る
jsonString=self.arduino.readline()
#音声がなかった場合
if(len(jsonString)==0):
# ほっとくと眠くなるし、ネガティブにもなる
self.emotion["arousal"]=self.saturate_cast(self.emotion["arousal"]-0.003)
self.emotion["valence"]=self.saturate_cast(self.emotion["valence"]-0.003)
return
#音声があった場合
paraLangData=json.loads(jsonString)
print(paraLangData)
soundGroup=paraLangData["soundGroup"]
interval=paraLangData["interval"]
# 音程が高いほど、テンションが上がる
self.emotion["valence"]=self.saturate_cast(self.emotion["valence"]+0.1*interval)
# 話しかけられると目が覚める
self.emotion["arousal"]=self.saturate_cast(self.emotion["arousal"]+0.2)
#眠くなると反応が単調になる
if(self.emotion["arousal"]<0.0):
soundGroup="b"
interval=0
soundFile="%s%02d.wav"%(soundGroup,interval)
print(self.emotion)
print(soundFile)
#音楽再生用ソフトをコール。macのみ。
subprocess.call(["afplay", os.path.join("kohaku_yurisan_c",soundFile)])
def getEmotions(self):
return self.emotion
############
# ここからメイン関数に相当する場所
if __name__ == "__main__":
#人間っぽいもの生成
agent=Agent()
graphImg=np.ones([500,500])*255
while (True):
#人間っぽいものに音声刺激を与える
agent.isStimulatedViaAudioChannel()
#感情を可視化する部分
emotion=agent.getEmotions()
cv2.putText(graphImg,"Arousal",(250,50),cv2.FONT_HERSHEY_PLAIN,1.5,[0])
cv2.putText(graphImg,"Valence",(300,250),cv2.FONT_HERSHEY_PLAIN,1.5,[0])
cv2.line(graphImg,(250,0),(250,500),[0])
cv2.line(graphImg,(0,250),(500,250),[0])
cv2.circle(graphImg,(int(emotion["valence"]*250+250),500-int(emotion["arousal"]*250+250)),6,color=[128],thickness=-1)
cv2.imshow("Emotion", graphImg)
cv2.waitKey(WAIT_TIME)
cv2.circle(graphImg,(int(emotion["valence"]*250+250),500-int(emotion["arousal"]*250+250)),6,color=[255],thickness=-1)
実験結果
とりあえず、人間っぽいものと会話で遊んで見ることにしました。
感情マップと合わせてその様子を以下の通り動画にしました。
韻律解析装置HEARTalkと情動の円環モデルを使って、テンションが上がり下がりの激しい対話システムを作ってみました。今日のアドベントカレンダーのでも動画になります。 pic.twitter.com/MOkejsGxoh
— あるふ (@alfredplpl) 2017年12月10日
感想
HEARTalk、意外と楽しいです。
相槌をそれっぽく言うだけで、
こんなに楽しくなるとは思いませんでした。
ぜひいま会社で開発しているシステムに突っ込んでみたいとか言っても
上司にボツされるんだろうな。
まとめ
今回は非言語処理の中でも2番目に大きな要素を占める聴覚について取り扱いました。この視覚と聴覚ですが、あまりにも重要なため研究者がひしめいているジャンルでもあります。研究者になりたい方は特に気をつけてください。
参考文献
[0] カンデル神経科学
[1] http://bsd.neuroinf.jp/wiki/%E8%81%B4%E8%A6%9A%E9%87%8E
[2] https://webempath.net/lp-jpn/
[3] http://voicetext.jp/
[4] http://crd.ndl.go.jp/reference/detail?page=ref_view&id=1000181979
[5] http://www.agi-web.co.jp/