感覚ごとの非言語処理
我々人間がはっきりと感じることができて、
区別できる物事すべては記号として取り扱えるのです。
と、ババーンみたいな感じで前回言いました。
我々が感じるということは一体どういうことなんでしょうか。
みなさまもよく聞くかと思いますが、
人間には五感が備わっていると言います。
視覚、聴覚、触覚、味覚、嗅覚の5つです。
実はこれ以外にもいっぱい感覚はあります。
これらから受け取る感覚は記号にでき、
非言語情報として処理できます。
本アドベントカレンダーでは
このうち、視覚、聴覚、触覚によるコミュニケーションと
それらの非言語処理について取り扱います。
その後、生体信号や脳活動など感じることのできない
非言語情報についても取り扱っていきます。
視覚によるコミュニケーション
みなさんはLINEやってますか?
われわれは文字によるコミュニケーションを活発に行なっています。
LINEでメッセージを交換したり、声が出せないときは筆談したりします。
これらははっきりとした言語コミュニケーションですね。
一方で、手話は言語コミュニケーションですが、
ジェスチャーは非言語コミュニケーションに属します。
とはいっても、ジェスチャーの一部が新しい手話の単語になる例もあるんですけどね。
ちなみに限りなく言語と非言語の境界なのは絵文字とスタンプです。
時代を遡ると象形文字もそうでしょうね。
さて、視覚による純粋な非言語コミュニケーションの代表例といえば、
絵やイラストによるコミュニケーションでしょう。
古くは文字ができる前からあった原始的手法です。
そこで今回はその原始的手法であるイラストによるコミュニケーションを
機械とできるようなシステムを作って見ましょう。
プログラマには余談になるかもしれませんが、
まず、視覚ってなんぞやってところからスタートしましょう。
もし途中で飽きた場合、右側のリストから実装の章をクリックして飛ばしてください。
視覚のメカニズム
この章では我々がコミュニケーションする際にどのように脳を使っているのかという
仕組みを神経科学を元に説明していきます。
ただし、ここに書かれていることが正しいかどうか保証いたしかねます。
実は、神経科学の研究自体が条件をかなり絞って実験するため、
総合的な脳の活動がはっきりしているものが少ないのです。
このため、この章では各研究を継ぎ接ぎして、仮説を立てつつ説明しています。
今後の神経科学の発展によっては間違っていることが多くあると思いますが、
ご容赦くださいますようよろしくお願いします。
物理的刺激から記号が認識するまでのメカニズム
視覚といえば、目ですよね。目。
目もそうですが、目から先はどうなっているのでしょうか。
あえて光がでてくるところからスタートしましょう。
メカニズムの概略図は図1の通りになります。
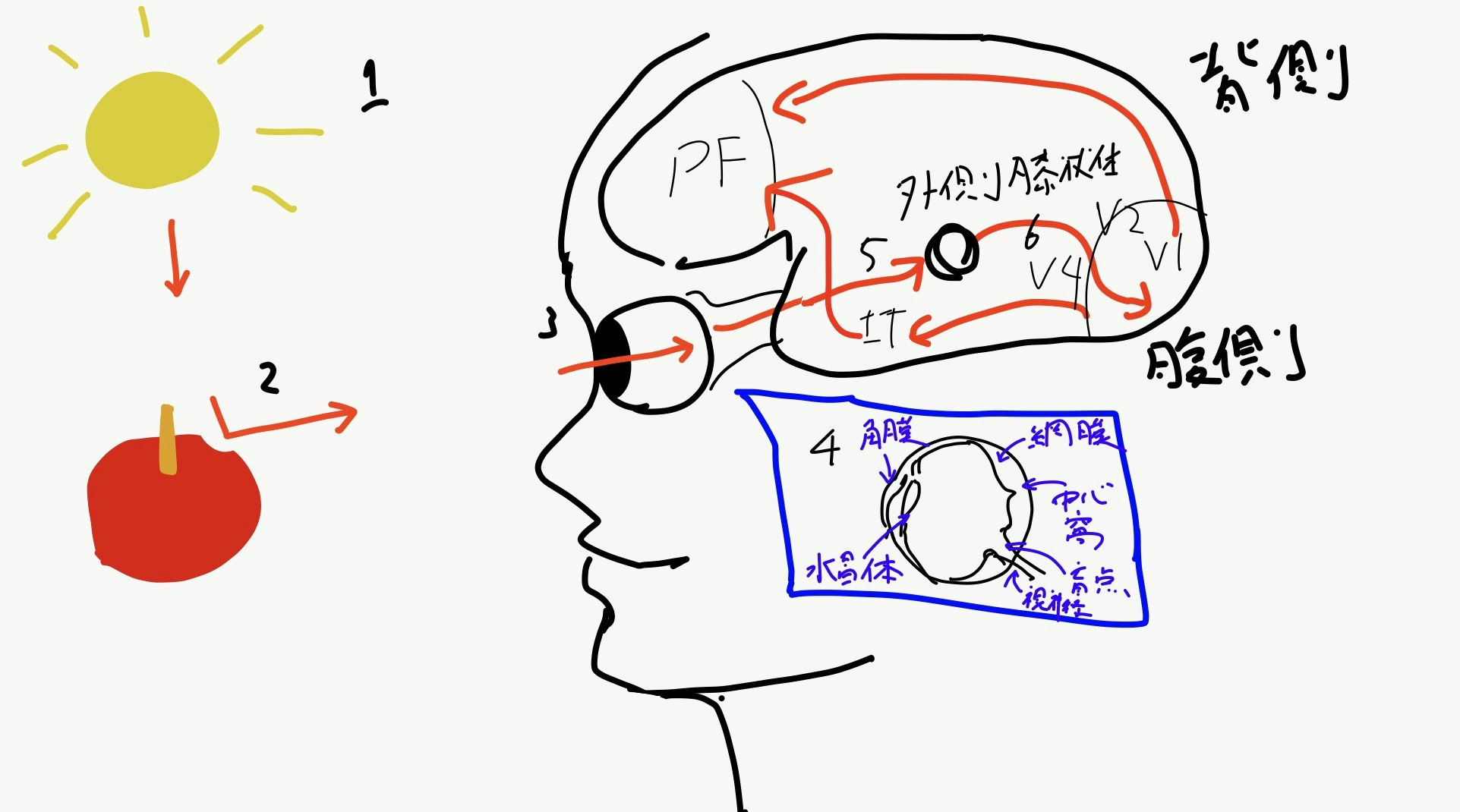
図1 人間が光を受容して認識するまでのプロセス概要
一番身近な光といえば、太陽光でしょう。
太陽からふりそそぐ光は、かなりまっすぐ進みます。
この時、光はいろいろな色成分が重なり合って進んでいます(1)。
その光が物体、たとえば赤いりんごに当たると、
赤色以外の成分が吸収され、赤色だけが反射されます(2)。
その反射した光が目の瞳孔に入ると、水晶体によって
収縮し網膜の1点にはっきりとした像を結びます(3)。
網膜には視細胞がありまして、
さらにその中の視物質が
光を吸収するとそれぞれが化学反応を起こします[2]。
化学反応を起こすと、みごとにめきょっと構造が曲がります(4)
(シス型からトランス型へ光異性化をおこすようすを視覚的にいってます)。
ちなみに視細胞には以下の通りの種類と役割を持ちます。
- 杆体: 光の明るさそのもの
- L錐体: 赤色の光
- M錐体: 緑色の光
- S錐体: 青色の光
めっきょっすると、神経節細胞が刺激され、連鎖的に視神経を刺激します。
視神経はこの後脳に刺激を伝達しますが、
ここからややこしい接続方式で繋がっています
まず、視神経は脳に入ると視索と呼ばれる神経に入り、
間脳の外側膝状体や中脳に接続されます。ちなみに視索のうち鼻側の網膜と繋がっているものは左右の脳を交差して入力されます。俯瞰図にすると、図2のようになります。
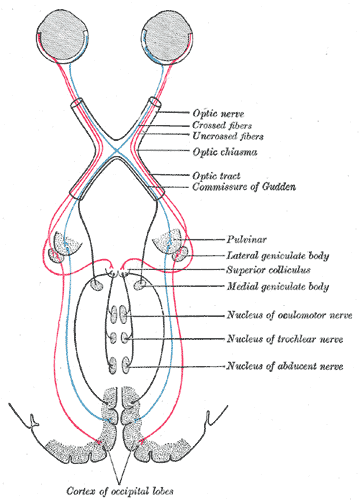
図2 視交叉と外側膝状体、一次視覚野の神経接続(グレイ解剖学より引用)
で、外側膝状体に入った刺激はM,P,K細胞によって信号処理されます[5]。
- M細胞は杆体とつながっており、動きや距離、光の微妙な明るさの違いを計算します。
- P細胞は錐体とつながっており、赤から緑ぐらいまでの色を処理します。
- K細胞は錐体とつながっており、青色を処理してくれます。
この外側膝状体の処理が行われることで光をやっと知覚することができます。ただし、それは無意識的なものみたいですね。
このあと、一次視覚野V1に到達します(6)。V1では斜めの線や点を認識します。またその認識結果を統合する働きを持っています。M細胞も距離を知覚しますが、奥行きを知覚する領域は左右の目から入った情報を統合するV1とV2になります。いわゆる両眼視差を使って計測するようです。このあと、V2にいたり、物体表面に関する性質を知覚します。
このあと、信号は腹側経路と背側経路に伝達され、物体が「何」であるかと物体が「どこ」にあるかを認識します。
ここでは物体認識に注目し、腹側経路を説明します。
腹側経路にはV4、腹側運動前皮質、下側頭皮質(IT)があります。
下側頭皮質は特に物体認識には重要な役割を果たします。
たとえば、顔を認識し、記号化するとされる顔選択性細胞がこの部分に存在します。
また、この下側頭皮質は情動を司る扁桃体と接続されているため、
表情の認識にも関わってきます。
その後、下側頭皮質をとおり、意識を司る前頭前野に情報が入ります。
こうしてりんごという記号、特に記号表現を映像として認識できるわけです。
記号が発生してから記号表現を描くメカニズム
ここのあたりは時間の都合上運動の項目に回します。
視覚の特性
我々は意識に上ってくる視覚的イメージをあまり意識して感じ取ったことがありません。しかし、意識に上ってくる視覚から得られたイメージは脳による処理を受けまくった、いわば創作に近いデータです。ここでは、そんな視覚の特製を大雑把に解説していきます。
- 五感による知覚の割合は五感の中で80%を占める[7]と言われている(が、怪しい)。
- 化学変化を起こした視物質にもとに戻すために、視物質へ同じ光エネルギーを与えないように絶えず目は細かく動いている。この現象をマイクロサッケードと呼ぶ[1]。我々は普段安定して静止したイメージを感じ取ることができるのは脳が手ぶれ補正のような処理を視覚野で行っているためである。
- 目は対象物が水晶体の中心と網膜の中心窩と呼ぶところが直線的になるように目の周りの筋肉を使い追従する。中心窩には、目の網膜には錯体細胞と桿体細胞の存在に偏りが生じている。中心窩には錐体細胞とが集中しており、色を感じ取ることに特化している中心視野と言われている。その周りの色が感じ取りにくい領域を周辺視野と言われている。
- 網膜には視神経を脳内に送り出すために視細胞がない場所があり、これを盲点と呼んでいる。盲点は魚類から人類が進化したときの名残だと言われている。
- 他の五感と比べ、指向性を持つ。両眼でおおよそ180度である。
- 目を瞑ることで知覚を遮断できる。意識的にも無意識的にも遮断できる。
- 時間分解能は約60Hzとされている。 (この周波数を超えて、LEDなどを光らせると、網膜内の視物質が受けた光エネルギーが積算されて、ずっと光っているようにみえる。これを応用した工学的手法がダイナミック点灯である。)
- 知覚できる電磁波、つまり可視光は約360nmから約830nmの波長の範囲[8]に収まる。この範囲外の電磁波は網膜を通過したり、目の表面である角膜に吸収されたりする。
- 色彩の分解能は個人差が大きい。これは魚類から人間に進化する進化の過程で網膜の錐体細胞の種類が減ったり増えたりしたためである。特に男性には錯体が2種類しかない場合があり、この障がいを色盲と呼ぶ。逆に女性は4種類持つ人もおり、分解能が高い人もいる。
- 奥行きなどの距離を知覚できる。視差だけではなく、様々な要因によって決められる。
視覚に関わる非言語処理
実は、機械に視覚の能力を与える非言語処理はコンピュータビジョンCV、マシンビジョン、ロボットビジョンとしてすでに体系化されています。視覚に関わる非言語処理は体系化されていますが、現在ディープラーニングにおかげで絶賛開拓中となっております。
コンピュータビジョンの他にも
人間の水晶体に相当する光学系の分野や
網膜に相当する半導体、受光素子の分野、
莫大な情報量を処理するための半導体GPGPUや分散処理基盤、通信の分野が関わってきます。
また、網膜からK細胞の処理まで一気にすっ飛ばしてくれるデプスセンサや測距センサ、LIDARといった距離を直接測定する装置もあります。
コンピュータビジョンには大きく、画像認識、画像生成、AR、三次元復元、幾何変換、フィルタリング(ノイズ除去などディープラーニングには大切な概念)、フォトメトリ(反射光などの性質をしらべたりする)などの分野に分けられます。
このうち、コミュニケーションに使えそうなのは、画像認識と画像生成、ARの3つになります。
画像認識は、与えられた画像がなんの記号なのかを認識する技術です。画像認識を使った有名なアプリケーションとしては自動運転車です。歩行者や標識、多様な道路状況を読み取るためにつかわれます。要素技術としてパターン認識、機械学習があります。
有名な開発ライブラリはOpenCV, PCL, Tensorflow, chainerなどがあります。
また有名なWeb APIには、GoogleのCloud Vision API, MSのComputer Vision API, Face APIがあります。
画像生成は、与えられた記号列から画像を生成する技術です。画像生成を使った有名なアプリケーションはMakeGirlsMoeあたりだと思います。また、イラスト自動着色PaintsChainerもその一部には入ると思います。
要素技術としてはGAN(生成型敵対的ネットワーク)があります。
有名な開発フレームワークは画像認識と同じくOpenCV, Tensorflow やchainer があります。
AR(拡張現実、Augmented Reality)は、現実の風景になんらかの情報を追加して提示する技術になります。ARを題材とした有名なSF作品は電脳メガネがあります。
ARを使った有名なアプリケーションはポケモンGOです。
要素技術としてSLAM(自己位置推定と環境地図作成)があります。
有名な開発ライブラリはARToolkit, AppleのARkitがあります。
表示するデバイスはHololensが有名でしょう。他にもスマートフォンやヘッドマウンドディスプレイが使われます。
実装:イラストによるコミュニケーション
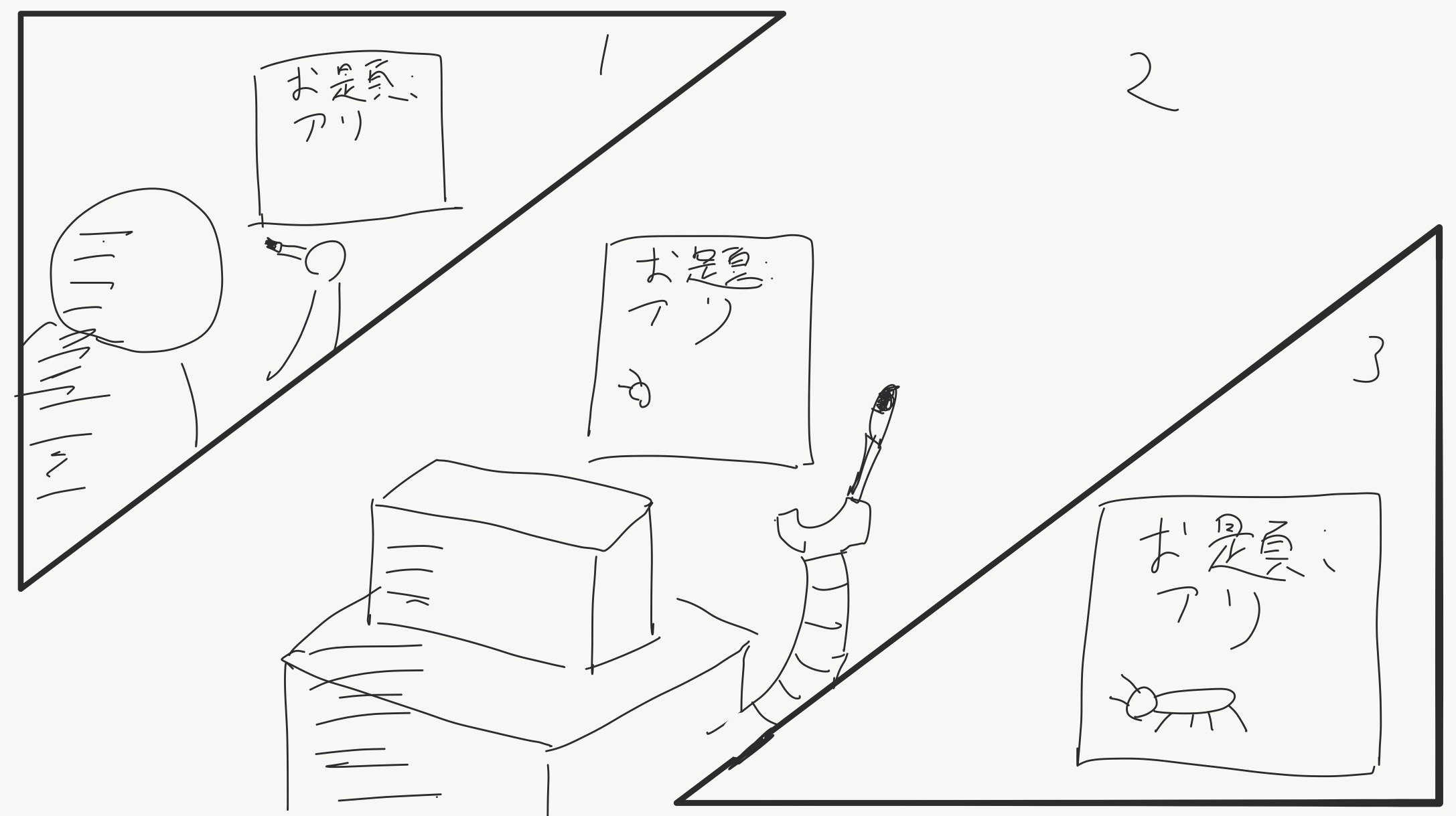
さて、イラストでコミュニケーションしましょう。
今回は、お題が与えられている状態で人が途中まで書いたイラストを
途中から人工知能が描いてくれるプログラムになります。
こちらがデモのリンクです。
http://alfredplpl.softether.net/sketch/
(著者のページです。)
めんどくさい方は以下の動画を眺めてください。
デモ用動画 pic.twitter.com/lEj2fYaNHs
— あるふ (@alfredplpl) 2017年12月3日
今回コードを書くことがほぼなかった
ざっくりとした実装解説
こちらはわたしが作ったものではなく、Googleのプロジェクト、Magenta[6]で作られたSketch RNNという技術のデモになります。一応、デモだけだとわかりにくかったので、いろいろ日本語化しました。
Sketch RNNについてざっくり説明すると、マウスで描いた線の軌跡を時間ごとに並べ、それをRNNというディープラーニングの一種で学びます。たとえば、アリの例では、アリの描き方をいろんな人が描いたアリからとことん学習させる感じですね。そうすると、途中かけの入力からアリを完成させる出力を吐き出すようにすることができます。
詳しくは原著論文をお読みください。
まとめ
今回は、非言語の記号の具体例として、視覚によるコミュニケーション、そのメカニズムと非言語処理について取り扱いました。
人間が物理的な刺激から記号を意識するまでには複雑なメカニズムが働いていることがわかりますし、
それらがまだ現代科学でもちぐはぐになっており、体系化されていないことがわかっていただけたと思います。
そのような中でも様々なソフトウェアやハードウェアが視覚に対しては整っています。
視覚による非言語コミュニケーションはまだまだ発展途上ではありますが、
個人的に最も期待したい分野だと思っています。
次回は触覚によるコミュニケーション、そのメカニズムと非言語処理について説明します。
参考文献
[1] 金澤一郎, 宮下保司, Eric R. Kandel, James H. Schwartz, Steven A. Siegelbaum, Thomas M.Jessell, A. J. Hudspeth、カンデル神経科学、2014
[2] 松山 オジョス 武、七田 芳則、”ロドプシン、” 脳科学辞典、http://bsd.neuroinf.jp/wiki/%E3%83%AD%E3%83%89%E3%83%97%E3%82%B7%E3%83%B3
[3] 端川 勉、”脳神経、” 脳科学辞典、http://bsd.neuroinf.jp/wiki/%E8%A6%96%E7%A5%9E%E7%B5%8C#.E7.AC.ACII.E8.84.B3.E7.A5.9E.E7.B5.8C
[5] Lateral_geniculate_nucleus、https://en.m.wikipedia.org/wiki/Lateral_geniculate_nucleus
[6] https://magenta.tensorflow.org/
[7] http://crd.ndl.go.jp/reference/detail?page=ref_view&id=1000181979
[8] JIS Z8120