Summary
- OpenAI APIを使って論文を要約するプロンプトのversion 0.5を実装しました.
- ひとまずそれっぽい要約ができている
- 出力フォーマットはJSONになるようにコントロールした
| crate | GitHub |
|---|---|
| rsrpp | rsrpp |
| rsrpp-cli | rsrpp |
| arxiv-tools | rs-arxiv-tools |
| ss-tools | rs-ss-tools |
| keyword-tools | keywords |
| openai-tools | rs-openai-tools |
前回までのあらすじ
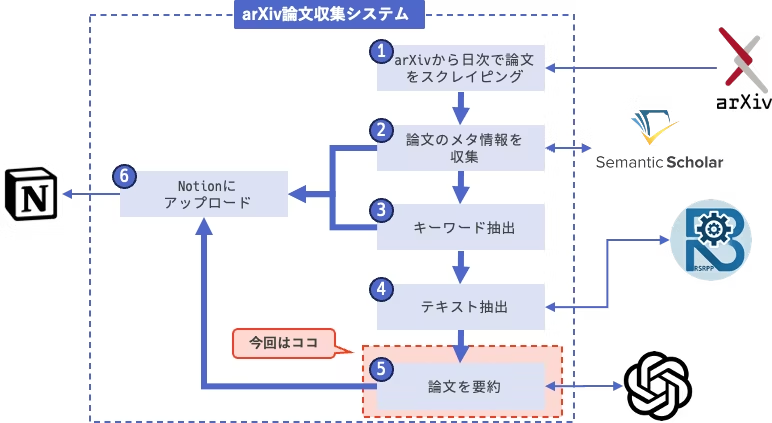
OpenAIのAPIのラッパーを実装しました.今回は論文を要約して欲しい情報を抽出するためのプロンプトチューニングを実施します.
とりあえず要約してみる
お馴染みの Attention Is All You Need を使って,まずはとりあえず「要約して」とやってみます.
let mut openai = OpenAI::new();
let paper_text = std::fs::read_to_string("src/output.txt").unwrap();
let messages = vec![Message::new(
"user".to_string(),
format!(
r#"次の論文を要約してください.
[論文]
{}"#,
paper_text
)
.to_string(),
)];
openai
.model_id("gpt-4o-mini")
.messages(messages)
.temperature(1.0);
let response = openai.chat().unwrap();
println!("{}", response.choices[0].message.content);
この論文では、従来の再帰的ニューラルネットワーク(RNN)や畳み込みニューラルネットワーク(CNN)をぜんぶ取り除き、注意機構のみに基づいた新しいネットワークアーキテクチャ「Transformer」を提案しています。Transformerは、シーケンストランスダクションモデルにおいて、長距離依存関係を効率的に学習する能力を持ち、トレーニング時間が大幅に短縮されます。
具体的には、WMT 2014の英語からドイツ語およびフランス語への翻訳タスクで新しい最先端のBLEUスコアを達成しました。英語からドイツ語への翻訳では28.4 BLEU、英語からフランス語への翻訳では41.0 BLEUを記録し、従来の後続モデルやアンサンブルよりも大幅に改善された結果です。
Transformerモデルは、エンコーダとデコーダの構造を持ち、エンコーダは入力シーケンスを連続的な表現にマッピングし、デコーダはその表現に基づいて出力を生成します。自己注意機構によりシーケンス内の任意の位置からの情報を抽出できるため、並列処理が可能であり、長い並列処理を実現しています。
また、モデルのトレーニングにはAdamオプティマイザーを使用し、各サブレイヤーへのドロップアウトやラベルスムージングによってオーバーフィッティングを防ぐ手法を取っています。
結論として、Transformerは注意機構に完全に基づいた最初のシーケンストランスダクションモデルであり、従来のRNNやCNNよりも早いトレーニングで高い翻訳品質を実現し、他のタスクにも一般化可能であることが示されています。このアプローチは今後のテキスト以外の入力や出力形式への応用が期待されています。
要約としては割と十分な内容です.
が,一目見て確認するにはもう少し観点を整理して情報を構造化したいです.
チューニングのゴール設定
さて,ここからプロンプトをチューニングしてarXiv論文収集システムに最適な形で情報抽出したいのですが,その前に「最適な形」について解像度を上げておきます.
今回のarXiv論文収集システムは,毎日100本以上の論文がデータベースに上がってくる仕組みになる想定で,それらをできるだけ短時間で確認したいです.
理想的には論文1本あたり数秒程度で確認を済ませたい.
何を確認するか.
その場で論文の内容を読み込めればベストなのですが,流石にそこまでは難しいので,最低限「読むべき論文か,今のところは無視してよい論文か」をチェックしてラベリングできるようにしたいと思います.
読むべき論文かどうかを判断するには,論文に関するどんな情報があれば良いでしょうか.
学術論文にはいくつか決まりごとがあり,その中の一つとして,論文のリサーチクエスチョンとコントリビューションを明示する必要がある,というものがあります.
全ての論文には,「その論文が何を目的に書かれたのか」という問いが設定してあり,また「この論文がコミュニティに
どのような貢献を果たしたのか」が記載されているということです.
ある論文が自分にとって興味の対象かどうかは,このリサーチクエスチョンとコントリビューションを確認するのが手っ取り早いと思っています.
そこで,論文の中からリサーチクエスチョンとコントリビューションを抽出し,短い文章でまとめるようにプロンプトを工夫してみます.
Version 0.1 - RQ/Contribの抽出
次の論文のリサーチクエスチョンとコントリビューションをそれぞれ説明してください.
[出力フォーマット]
- Research Question: [リサーチクエスチョン]
- Contribution: [コントリビューション]
[論文]
...
- Research Question:
伝達タスクにおける新しいモデルアーキテクチャ(Transformer)が、従来の再帰的または畳み込みニューラルネットワークに基づくモデルと比較して、翻訳品質、トレーニング時間、および計算効率においてどのように優れているか?
- Contribution:
Transformerは、再帰層や畳み込み層を使用せず、完全に注意機構に依存した初のシーケンス伝達モデルを提案する。新たなアーキテクチャによって、トレーニング時間が大幅に短縮され、WMT 2014の英語からドイツ語および英語からフランス語への翻訳タスクで新たな最先端のBLEUスコアを達成しました。この研究は、注意ベースのモデルの可能性を示し、他のタスクへの応用や効率的な入力と出力の処理のためのさらなる研究の道を開いた。
この論文のタスクは translation (翻訳)であって transmission (伝達)ではないのですが...
と思って論文を見てみたら,sequence transduction tasksという表現が出てきてますね.
こういうところはChatGPTさんもまだまだです.
ですが,ひとまず欲しい情報を出してくれているようです.
Research Questionに関しては,どんな研究を背景にしているのか,既存研究に対してどんなところに課題を位置付けているのか,というあたりの補足が欲しいですね.
Contributionに関しては,この論文が成し遂げたことがまとまっているので,わかりやすくなりました.
上記の背景の記述と,ついでに他の情報も収集できるようにさらにプロンプトを改良します.
Version 0.2
次の論文について,以下の観点で要約を作成してください.
1.この論文のリサーチクエスチョンは何か? この論文がどんな既存研究を背景にしているかという点も合わせて記述してください.
2. この論文のコントリビューションは何か?
3. この論文で提案されている手法やアプローチはどのようなものか?
4. この論文実験結果はどのようなものか?
5. この論文の関連研究との比較はどのようなものか?
6. この論文で解決されていない問題は何か?
[出力フォーマット]
- Research Question: [リサーチクエスチョン]
- Contribution: [コントリビューション]
- Proposed Method: [提案手法]
- Experiment Results: [実験結果]
- Comparison with Related Work: [関連研究との比較]
- Future Work: [解決されていない問題]
[論文]
...
- Research Question:
この論文は「自己注意メカニズムのみを使用して文を処理するシーケンス変換モデルを提案し、従来の再帰ニューラルネットワーク(RNN)や畳み込みニューラルネットワーク(CNN)を完全に排除できるか?」というリサーチクエスチョンを持っている。従来の研究では、再帰や畳み込みとともに注意メカニズムを取り入れたモデルが広く用いられていたが、シーケンス処理には限界があった。
- Contribution:
本論文の主なコントリビューションは、Transformerと呼ばれる新しいアーキテクチャを提案し、シーケンス変換タスクにおいて、従来の先進的なモデルよりも短時間で高いパフォーマンスを達成できることを示した点である。特に、翻訳タスクにおいてこれまでの最高のBLEUスコアを更新した。
- Proposed Method:
提案手法は「Transformer」アーキテクチャであり、自己注意メカニズムのみを用いたエンコーダー-デコーダー構造から成る。エンコーダーは、多層の自己注意とフィードフォワードネットワークから構成され、情報の長距離依存関係を扱うことができる。
- Experiment Results:
実験結果では、WMT 2014の英独翻訳タスクで、Transformerは28.4のBLEUスコアを達成し、従来のモデルよりも2以上のBLEU点を上回った。また、英仏翻訳タスクでも41.0のBLEUスコアをマークし、従来の単一モデルを大幅に上回る成果を挙げた。
- Comparison with Related Work:
関連研究と比較すると、従来のシーケンスモデルは再帰構造に依存しており、長いシーケンスを処理する際に計算の並列化が難しいが、Transformerは完全に自己注意メカニズムを使用することでこの制限を克服し、計算効率とモデル性能をともに向上させることに成功している。
- Future Work:
論文では、Transformerモデルが解決できていない問題として、順次生成を減少させる方法や、テキスト以外の入力および出力モダリティに拡張することを挙げている。将来的には、映像や音声などの大規模データを効率的に扱える局所的な注意メカニズムを探索することも目指している。
だいぶ良い感じになってきました.
ただ,出力フォーマットがこのままでは,後続の処理で受け取りにくいので,JSON形式で出力するようにプロンプトを修正します.
version 0.5
前回少し触れましたが,OpenAIのAPIには出力フォーマットを指定できる機能があり,出力をJSONにしたい場合にはJSONのスキーマを指定することで出力をコントロールできます.
openai-toolsには,JSONスキーマを指定する機能も実装しているので,それを使って出力フォーマットを指定します.
ついでに,Survey論文の場合は要約の観点が異なるので,論文がサーベイかどうかについてのフラグも追加しておきます.
let mut openai = OpenAI::new();
let paper_text = std::fs::read_to_string("src/output.txt").unwrap();
let messages = vec![Message::new(
"user".to_string(),
format!(
r#"###### 指示 ######
次の論文について,以下の観点で要約を作成してください.
1. この論文はサーベイ論文ですか? [is_survey]
2.この論文のリサーチクエスチョンは何ですか? この論文がどんな既存研究を背景にしているかという点も合わせて記述してください. [research_question]
3. この論文のコントリビューションは何ですか? [contributions]
4. この論文で使用されているデータセットは何ですか? [dataset]
4. この論文で提案されている手法やアプローチはどのようなものですか? [proposed_method]
5. この論文実験結果はどのようなものですか? [experiment_results]
6. この論文の関連研究との比較はどのようなものですか? できる限り既存研究を参照しながら説明してください. [comparison_with_related_works]
7. この論文で解決されていない問題は何ですか? [future_works]
###### 論文 ######
{}"#,
paper_text
)
.to_string(),
)];
let mut json_schema = JsonSchema::new("summary".to_string());
json_schema.add_property(
"is_survey".to_string(),
"boolean".to_string(),
Option::from("この論文がサーベイ論文かどうかをtrue/falseで判定.".to_string()),
);
json_schema.add_property(
"research_question".to_string(),
"string".to_string(),
Option::from("この論文のリサーチクエスチョンの説明.この論文の背景や既存研究との関連も含めて記述する.".to_string()),
);
json_schema.add_property(
"contributions".to_string(),
"string".to_string(),
Option::from("この論文のコントリビューションをリスト形式で記述する.".to_string()),
);
json_schema.add_property(
"dataset".to_string(),
"string".to_string(),
Option::from("この論文で使用されているデータセットをリストアップする.".to_string()),
);
json_schema.add_property(
"proposed_method".to_string(),
"string".to_string(),
Option::from("提案手法の詳細な説明.".to_string()),
);
json_schema.add_property(
"experiment_results".to_string(),
"string".to_string(),
Option::from("実験の結果の詳細な説明.".to_string()),
);
json_schema.add_property(
"comparison_with_related_works".to_string(),
"string".to_string(),
Option::from("関連研究と比較した場合のこの論文の新規性についての説明.可能な限り既存研究を参照しながら記述すること.".to_string(),),
);
json_schema.add_property(
"future_works".to_string(),
"string".to_string(),
Option::from("未解決の課題および将来の研究の方向性について記述.".to_string()),
);
openai
.model_id("gpt-4o-mini")
.messages(messages)
.temperature(1.0)
.response_format(ResponseFormat::new("json_schema".to_string(), json_schema));
let response = openai.chat().unwrap();
println!("{}", response.choices[0].message.content);
{
"is_survey":false,
"research_question":"この論文は、再帰型ニューラルネットワークや畳み込みネットワークを排除し、自己注意メカニズムのみに依存したトランスフォーマーアーキテクチャを提案しています。既存の研究として、再帰型言語モデルやエンコーダ・デコーダアーキテクチャ(特にRNNを用いたもの)が挙げられ、これらのモデルが直面する計算効率の課題や長期依存性の学習の難しさに触れています。",
"contributions":"この研究の貢献は、自己注意に基づく新しいシーケンストランスダクションモデル「トランスフォーマー」を提案したことにあります。このモデルは再帰層や畳み込み層を使用せず、全ての依存関係をグローバルにモデル化することで、計算の並列化が可能であり、高い翻訳品質を達成します。",
"dataset":"本研究では、WMT 2014英独翻訳データセット(約450万文対)およびWMT 2014英仏翻訳データセット(約3600万文)を使用します。いずれも、バイトペアエンコーディングを用いて符号化され、トークン数はそれぞれ約37000および32000です。",
"proposed_method":"提案された手法は、トランスフォーマーアーキテクチャで、自己注意メカニズムを基盤とし、エンコーダとデコーダをそれぞれ6層の自己注意モジュールと全結合ネットワークで構成しています。マルチヘッド注意を用いて、異なる位置の情報に同時に注意を向けられるようにしています。",
"experiment_results":"実験の結果、WMT 2014英独翻訳タスクにおいて、ビッグトランスフォーマーモデルがBLEUスコア28.4を達成し、他の最先端モデルを2.0ポイント上回りました。同様に、WMT 2014英仏翻訳タスクでもBLEUスコア41.0を達成し、これまでのシングルモデルの最先端を上回っています。",
"comparison_with_related_works":"この論文は、従来のRNNやCNNに基づくシーケンスモデルと比較され、トランスフォーマーの自己注意メカニズムが、依存関係の学習や計算効率において大きな利点を持つことを示しています。特に、再帰的な計算の制約を回避し、長いシーケンスをより効率的に処理できる点が強調されています。",
"future_works":"将来的には、トランスフォーマーを入力・出力の他のモダリティ(画像、音声、動画など)にも適用することや、大規模入力や出力の効率的な処理のために、ローカルに制限された注意メカニズムを探究する計画があります。生成過程の効率化にも取り組む意向があります。"
}
ひとまず形になりました.
このままでも後続の処理に渡すことはできるのですが,ここでの要約の精度は今回のシステムによって非常に重要なので,さらにプロンプトをチューニングできないか先行研究を参照して検討してみます.
次回
プロンプトチューニングの既存の知見を整理して,version 1.0を目指します.