Summary
- サーベイ論文を参考にプロンプトチューニングの主要な手法を試す
- 参考文献情報を外部知識として与えて論文の要約をブラッシュアップ
| crate | GitHub |
|---|---|
| rsrpp | rsrpp |
| rsrpp-cli | rsrpp |
| arxiv-tools | rs-arxiv-tools |
| ss-tools | rs-ss-tools |
| keyword-tools | keywords |
| openai-tools | rs-openai-tools |
前回までのあらすじ
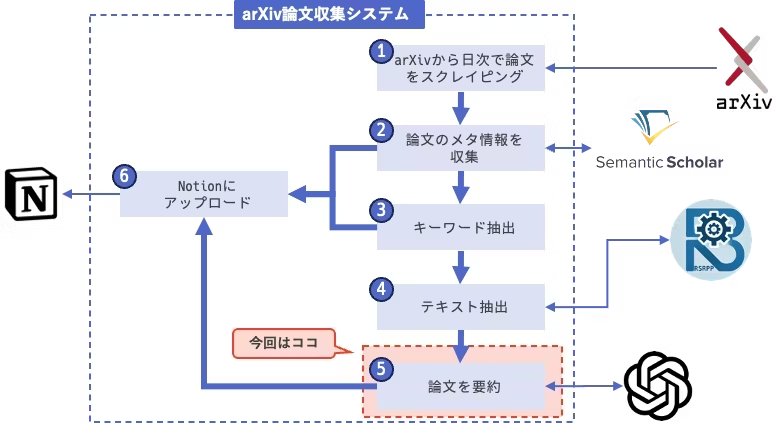
前回までで,基本的なプロンプトと出力フォーマットの調整が終わりました.
今回は,プロンプトの技術を軽くレビューし,今回のシステムに取り込めそうなものを組み合わせてプロンプトversion 1.0を実装します.
プロンプトチューニングの現在地
LLMにおいてパラメータを更新することなくプロンプトのみでモデルの出力をコントロールできるということが発見されてから,多数のプロンプトチューニング技術が発表されています.
最近のサーベイ論文1に主要なプロンプトチューニング手法が体系的に整理されています.
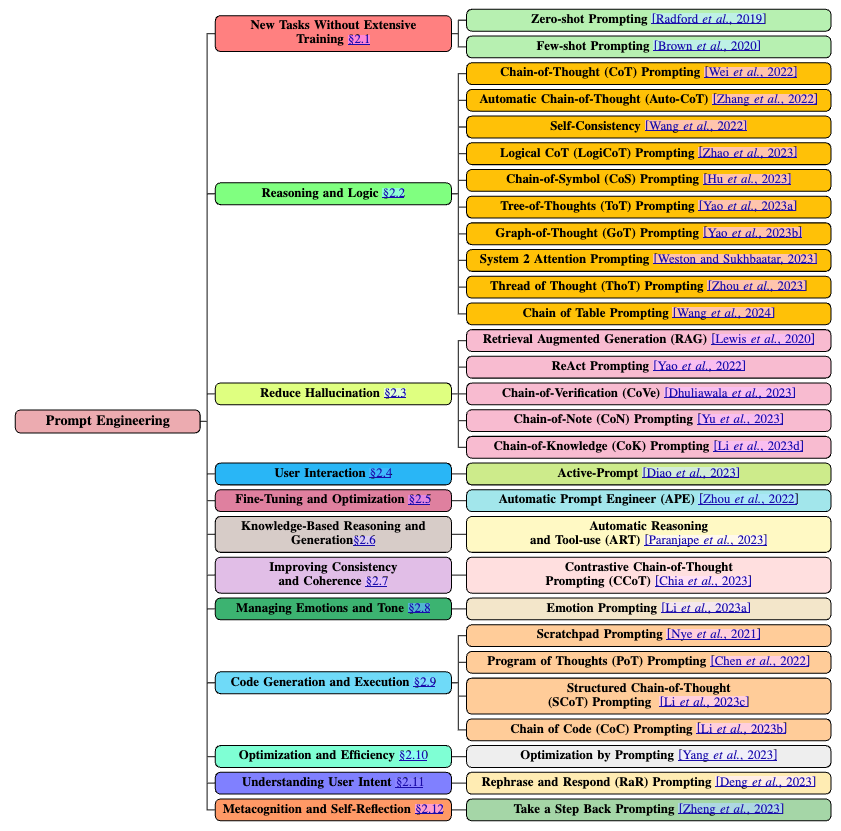
今回のシステムで利用したいのは,Reduce HallucinationおよびUnderstanding User Intentあたりの手法でしょうか.
プロンプトチューニングでは,Reasonoingに関する手法が多数提案されていますが,論文の要約にあたっては今の所そこまで複雑な論理的推論は必要ありません.
ということで,下表が今回対象になりそうな手法の一覧です.
| Category | Method |
|---|---|
| Reduce Hallucination | Retrieval Augmented Generation (RAG) |
| Reduce Hallucination | ReAct Prompting |
| Reduce Hallucination | Chain-of-Verification (CoVe) Prompting |
| Reduce Hallucination | Chain-of-Note (CoN) Prompting |
| Reduce Hallucination | Chain-of-Knowledge (CoK) Prompting |
| Understanding User Intent | Active Prompting |
RAGやReActはかなり大規模なシステムの設計変更が必要なので,この中で応用できそうなのはCoNやCoKの発想でしょうか.
Chain-of-Noteはノイズや未知の質問が多いケースに対応するために,質問に関する外部情報 (Note) を作成してそれを参照する形で事実誤認を防ぐ手法です.
Chain-of-Knowledgeも似た発想ですが,こちらは質問に対する予備的な推論を段階的に実施して最終的に適切に修正された推論をもとにして回答を生成します.
今回は大量の論文を裁くことになるので,1本の論文に対してあまり多段階の推論を行うことは現実的ではありませんが,外部知識を利用するという発想は活かせそうです.
version 0.8
そこで,まずは論文に関する外部知識として,参考文献のリストを明示的に与えてみようと思います.
テキスト抽出した結果をそのまま使っているので,参考文献でない情報 (ノイズ) も混ざっていますがそのまま与えてみます.
###### 指示 ######
次の論文について,この論文の参考文献のリストを参考にしながら,以下の観点で要約を作成してください.
1. この論文はサーベイ論文ですか? [is_survey]
2.この論文のリサーチクエスチョンは何ですか? この論文がどんな既存研究を背景にしているかという点も合わせて記述してください. [research_question]
3. この論文のコントリビューションは何ですか? [contributions]
4. この論文で使用されているデータセットは何ですか? [dataset]
4. この論文で提案されている手法やアプローチはどのようなものですか? [proposed_method]
5. この論文実験結果はどのようなものですか? [experiment_results]
6. この論文の関連研究との比較はどのようなものですか? できる限り既存研究を参照しながら説明してください. [comparison_with_related_works]
7. この論文で解決されていない問題は何ですか? [future_works]
###### 参考文献リスト #######
[1] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
[2] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. CoRR, abs/1409.0473, 2014.
[3] Denny Britz, Anna Goldie, Minh-Thang Luong, and Quoc V. Le. Massive exploration of neural machine translation architectures. CoRR, abs/1703.03906, 2017.
[4] Jianpeng Cheng, Li Dong, and Mirella Lapata. Long short-term memory-networks for machine reading. arXiv preprint arXiv:1601.06733, 2016.
[5] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. CoRR, abs/1406.1078, 2014.
[6] Francois Chollet. Xception: Deep learning with depthwise separable convolutions. arXiv preprint arXiv:1610.02357, 2016.
[7] Junyoung Chung, Çaglar Gülçehre, Kyunghyun Cho, and Yoshua Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling. CoRR, abs/1412.3555, 2014.
[8] Chris Dyer, Adhiguna Kuncoro, Miguel Ballesteros, and Noah A. Smith. Recurrent neural network grammars. In Proc. of NAACL, 2016.
[9] Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin. Convolu tional sequence to sequence learning. arXiv preprint arXiv:1705.03122v2, 2017.
[10] Alex Graves. Generating sequences with recurrent neural networks. arXiv:1308.0850, 2013.
[11] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for im age recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016.
[12] Sepp Hochreiter, Yoshua Bengio, Paolo Frasconi, and Jürgen Schmidhuber. Gradient flow in recurrent nets: the difficulty of learning long-term dependencies, 2001.
[13] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
[14] Zhongqiang Huang and Mary Harper. Self-training PCFG grammars with latent annotations across languages. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, pages 832–841. ACL, August 2009.
[15] Rafal Jozefowicz, Oriol Vinyals, Mike Schuster, Noam Shazeer, and Yonghui Wu. Exploring the limits of language modeling. arXiv preprint arXiv:1602.02410, 2016.
[16] Łukasz Kaiser and Samy Bengio. Can active memory replace attention? In Advances in Neural Information Processing Systems, (NIPS), 2016.
[17] Łukasz Kaiser and Ilya Sutskever. Neural GPUs learn algorithms. In International Conference on Learning Representations (ICLR), 2016.
[18] Nal Kalchbrenner, Lasse Espeholt, Karen Simonyan, Aaron van den Oord, Alex Graves, and Ko ray Kavukcuoglu. Neural machine translation in linear time. arXiv preprint arXiv:1610.10099v2, 2017.
[19] Yoon Kim, Carl Denton, Luong Hoang, and Alexander M. Rush. Structured attention networks. In International Conference on Learning Representations, 2017.
[20] Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR, 2015.
[21] Oleksii Kuchaiev and Boris Ginsburg. Factorization tricks for LSTM networks. arXiv preprint arXiv:1703.10722, 2017.
[22] Zhouhan Lin, Minwei Feng, Cicero Nogueira dos Santos, Mo Yu, Bing Xiang, Bowen Zhou, and Yoshua Bengio. A structured self-attentive sentence embedding. arXiv preprint arXiv:1703.03130, 2017.
[23] Minh-Thang Luong, Quoc V. Le, Ilya Sutskever, Oriol Vinyals, and Lukasz Kaiser. Multi-task sequence to sequence learning. arXiv preprint arXiv:1511.06114, 2015.
[24] Minh-Thang Luong, Hieu Pham, and Christopher D Manning. Effective approaches to attention based neural machine translation. arXiv preprint arXiv:1508.04025, 2015.
[25] Mitchell P Marcus, Mary Ann Marcinkiewicz, and Beatrice Santorini. Building a large annotated corpus of english: The penn treebank. Computational linguistics, 19(2):313–330, 1993.
[26] David McClosky, Eugene Charniak, and Mark Johnson. Effective self-training for parsing. In Proceedings of the Human Language Technology Conference of the NAACL, Main Conference, pages 152–159. ACL, June 2006.
[27] Ankur Parikh, Oscar Täckström, Dipanjan Das, and Jakob Uszkoreit. A decomposable attention model. In Empirical Methods in Natural Language Processing, 2016.
[28] Romain Paulus, Caiming Xiong, and Richard Socher. A deep reinforced model for abstractive summarization. arXiv preprint arXiv:1705.04304, 2017.
[29] Slav Petrov, Leon Barrett, Romain Thibaux, and Dan Klein. Learning accurate, compact, and interpretable tree annotation. In Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the ACL, pages 433–440. ACL, July 2006.
[30] Ofir Press and Lior Wolf. Using the output embedding to improve language models. arXiv preprint arXiv:1608.05859, 2016.
[31] Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units. arXiv preprint arXiv:1508.07909, 2015.
[32] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017.
[33] Nitish Srivastava, Geoffrey E Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdi nov. Dropout: a simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 15(1):1929–1958, 2014.
[34] Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, and Rob Fergus. End-to-end memory networks. In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett, editors, Advances in Neural Information Processing Systems 28, pages 2440–2448. Curran Associates, Inc. , 2015.
[35] Ilya Sutskever, Oriol Vinyals, and Quoc VV Le. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems, pages 3104–3112, 2014.
[36] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. CoRR, abs/1512.00567, 2015.
[37] Vinyals & Kaiser, Koo, Petrov, Sutskever, and Hinton. Grammar as a foreign language. In Advances in Neural Information Processing Systems, 2015.
[38] Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144, 2016.
[39] Jie Zhou, Ying Cao, Xuguang Wang, Peng Li, and Wei Xu. Deep recurrent models with fast-forward connections for neural machine translation. CoRR, abs/1606.04199, 2016.
[40] Muhua Zhu, Yue Zhang, Wenliang Chen, Min Zhang, and Jingbo Zhu. Fast and accurate shift-reduce constituent parsing. In Proceedings of the 51st Annual Meeting of the ACL (Volume 1: Long Papers), pages 434–443. ACL, August 2013.
Figure 3: An example of the attention mechanism following long-distance dependencies in the encoder self-attention in layer 5 of 6. Many of the attention heads attend to a distant dependency of the verb ‘making’, completing the phrase ‘making. ..more difficult’. Attentions here shown only for the word ‘making’. Different colors represent different heads. Best viewed in color.
Input-Input Layer5
Input-Input Layer5
Figure 4: Two attention heads, also in layer 5 of 6, apparently involved in anaphora resolution. Top: Full attentions for head 5. Bottom: Isolated attentions from just the word ‘its’ for attention heads 5 and 6. Note that the attentions are very sharp for this word.
Input-Input Layer5
Input-Input Layer5
Figure 5: Many of the attention heads exhibit behaviour that seems related to the structure of the sentence. We give two such examples above, from two different heads from the encoder self-attention at layer 5 of 6. The heads clearly learned to perform different tasks
###### 論文 ######
{
"is_survey":false,
"research_question":"この論文のリサーチクエスチョンは、「従来の再帰型ニューラルネットワーク(RNN)や畳み込みネットワークを使用せず、注意メカニズムだけに基づく新しいアーキテクチャであるTransformerが、シーケンス変換タスクでどの程度の性能を発揮できるか」である。この研究は、特に言語モデリングや機械翻訳における既存のRNNや注意メカニズムの利用に基づいている。",
"contributions":"この論文のコントリビューションは、完全に自己注意に基づく新しいシーケンス変換モデルであるTransformerの提案であり、これにより従来のRNNや畳み込みネットワークに依存せずにシーケンス間の依存関係をモデル化できる点である。また、Transformerは高速で効率的なトレーニングを可能にし、言語翻訳タスクにおいて新たな最先端の結果を達成した。",
"dataset":"この論文で使用されたデータセットは、WMT 2014 English-GermanおよびEnglish-French翻訳タスクにおける約450万の文ペアと3600万の文で構成されている。",
"proposed_method":"本研究で提案された手法は、Transformerアーキテクチャであり、これは再帰的または畳み込み的な構造を排除し、自己注意メカニズムに完全に依存する。このアプローチにより、全ての入力と出力のポジション間でのグローバルな依存関係を捉えることが可能である。",
"experiment_results":"実験結果として、TransformerはWMT 2014 English-German翻訳タスクで28.4 BLEUを達成し、WMT 2014 English-Frenchタスクで41.0 BLEUという新たな単一モデルの最先端スコアを樹立した。これらのモデルは、従来の最良モデルに比べてトレーニングコストが大幅に低く、数日間でトレーニングされた。",
"comparison_with_related_works":"従来のアプローチと比較して、Transformerは従来のRNNやコンボリューションモデルよりも高い性能を示しており、自己注意メカニズムが長距離依存性を学習するのに役立つことが示された。特に、従来のモデルが依存関係を学習するうえで直面する課題が、Transformerによって大幅に緩和された。",
"future_works":"今後の研究では、Transformerモデルをテキスト以外の入力および出力モダリティに拡張すること、ならびに視覚や音声、ビデオなどの大規模入力や出力を効率的に処理するための局所的な制限付き注意メカニズムを探求することを計画している。また、生成処理をより非直線的にすることも今後の研究目標としている。"
}
要約の大枠は変わっていませんが (変わっていたら困る!),データセットや参考研究への言及がより詳細になりました.
方向性は合っていそうです.
version 1.0
では最後に,関連研究をより適切な形で与えるために,事前に関連研究のリストを構造化して与えてみます.
rsrppでは,セクションごとにテキストを抽出することができるので,Referenceセクションの内容を事前にOpenAI APIに与えて,参考文献リストとして構造化しておきます.
###### 指示 ######
次の論文について,この論文の参考文献のリストを参考にしながら,以下の観点で要約を作成してください.
1. この論文はサーベイ論文ですか? [is_survey]
2.この論文のリサーチクエスチョンは何ですか? この論文がどんな既存研究を背景にしているかという点も合わせて記述してください. [research_question]
3. この論文のコントリビューションは何ですか? [contributions]
4. この論文で使用されているデータセットは何ですか? [dataset]
4. この論文で提案されている手法やアプローチはどのようなものですか? [proposed_method]
5. この論文実験結果はどのようなものですか? [experiment_results]
6. この論文の関連研究との比較はどのようなものですか? できる限り既存研究を参照しながら説明してください. [comparison_with_related_works]
7. この論文で解決されていない問題は何ですか? [future_works]
###### 参考文献リスト #######
<References>
<Reference>
<Title>Layer normalization</Title>
<Year>2016</Year>
<Authors>
<Name>Jimmy Lei Ba</Name>
<Name>Jamie Ryan Kiros</Name>
<Name>Geoffrey E Hinton</Name>
</Authors>
</Reference>
<Reference>
<Title>Neural machine translation by jointly learning to align and translate</Title>
<Year>2014</Year>
<Authors>
<Name>Dzmitry Bahdanau</Name>
<Name>Kyunghyun Cho</Name>
<Name>Yoshua Bengio</Name>
</Authors>
</Reference>
...
###### 論文 ######
{
"is_survey":false,
"research_question":"この論文は、複雑な再帰的または畳み込みニューラルネットワークに基づく従来のシーケンス変換モデルに代わり、単純なアーキテクチャのTransformerを提案することによって、特に機械翻訳の精度と計算効率を改善することを目的としている。この研究は、以前の注意メカニズムを用いた変換モデルやEncoder-Decoderアーキテクチャに関連する既存研究に基づいている。具体的には、Transformerモデルは自己注意メカニズムのみに依存することで、シーケンス間のグローバルな依存関係を捉えることができる。",
"contributions":"この研究の主要な貢献は、再帰や畳み込みなしで完全に注意メカニズムに基づく新しいトランスダクションモデルであるTransformerを導入し、機械翻訳タスクでの新しい最先端のBLEUスコアを達成することである。また、推論速度の向上とトレーニング時間の短縮を実現しており、計算配分を効率化している点も重要である。",
"dataset":"実験には、WMT 2014 English-Germanデータセット(約450万文ペア)およびWMT 2014 English-Frenchデータセット(約3600万文)を使用している。",
"proposed_method":"論文では、Transformerと呼ばれる新しいモデルアーキテクチャを提案しており、これは直接的に自己注意機構を利用し、各層がマルチヘッド自己注意とフィードフォワードネットワークから構成されている。Transformerは、再帰的アプローチに取って代わるシンプルかつ効率的な方法を提供する。",
"experiment_results":"Transformerの実験結果は、WMT 2014 English-German翻訳タスクで28.4 BLEU、WMT 2014 English-French翻訳タスクで41.0 BLEUという新しい状態の最先端スコアを達成しており、以前のモデルよりも計算コストが大幅に削減されている。",
"comparison_with_related_works":"本論文では、従来の再帰的および畳み込みベースのモデルと比較し、計算効率と精度の両面でTransformerが優れていることを示している。具体的には、自己注意機構を用いることで、長距離の依存関係を効果的に学習できることに言及している。",
"future_works":"今後の研究として、Transformerの拡張を試み、テキスト以外の入力・出力モダリティへの適用を探ることや、大規模な入力と出力の効率的処理を可能にするためのローカル限定注意メカニズムの調査が挙げられている。"
}
出力内容はversion 0.8とあまり変わりませんね...
まぁ,今回は元々の参考文献リストが綺麗な形だったので,あまり差が出ないのかもしれません.
参考文献リストを構造化しようとすると,OpenAIへのクエリ回数が増えるので,この辺りは費用対効果と相談ですね.
ともあれ,これでひとまず論文を要約する処理が形になりました.
次回
次回はシステムの最後のパーツであるNotionへのアップロードを実装していこうと思います.
-
Sahoo, Pranab, et al. "A systematic survey of prompt engineering in large language models: Techniques and applications." arXiv preprint arXiv:2402.07927 (2024). ↩