ちょっと気になった記事だったのでさわってみた。
- http://www.nttdata.com/jp/ja/insights/trend_keyword/2016042101.html (Apache Sparkより100倍速い??)
- 印象としてはHDFSをそのままインメモリにした感じ?
- HDFSもRAID0にしてソフト上で冗長担保するみたいなイメージなので、インメモリでデータとんでも大丈夫ってことかな?
- 最近メモリも安いしほんとに100倍早いなら実用的かも
※ amazon 計算で32GBが ¥16,500 = 1TBで ¥515,625 くらい
※ドキュメントとか読まない派でQuickStartしか読んでないので勘違いは許してくださいmm
alluxio SetUp
ローカルにSparkがいてsampleにSparkがあったのでSparkとつなげてみる
http://www.alluxio.org/docs/1.3/en/Running-Spark-on-Alluxio.html
alluxio起動まで
$ wget http://alluxio.org/downloads/files/1.3.0/alluxio-1.3.0-bin.tar.gz
$ tar xfvz alluxio-1.3.0-bin.tar.gz
$ ln -s alluxio-1.3.0 alluxio
$ cd alluxio
$ mvn clean package -Pspark -DskipTests
$ ./bin/alluxio-start.sh local
http://IP:19999/ でそれっぽい画面がでることを確認
サンプルデータ
- 500万行の1Gくらいのアクセスログっぽいデータ
$ wc -l /var/tmp/work/*
1695360 log1.txt
1692365 log2.txt
1705114 log3.txt
5092839 total
$ ll -h /var/tmp/work/*
-rw-r--r-- 1 root root 303M Oct 25 22:17 /var/tmp/work/log1.txt
-rw-r--r-- 1 root root 303M Oct 25 22:17 /var/tmp/work/log2.txt
-rw-r--r-- 1 root root 305M Oct 25 22:17 /var/tmp/work/log3.txt
データを入れてみる
$ ./bin/alluxio fs copyFromLocal /var/tmp/work /work
Copied /var/tmp/work to /work
$
http://IP:19999/ をみてみる
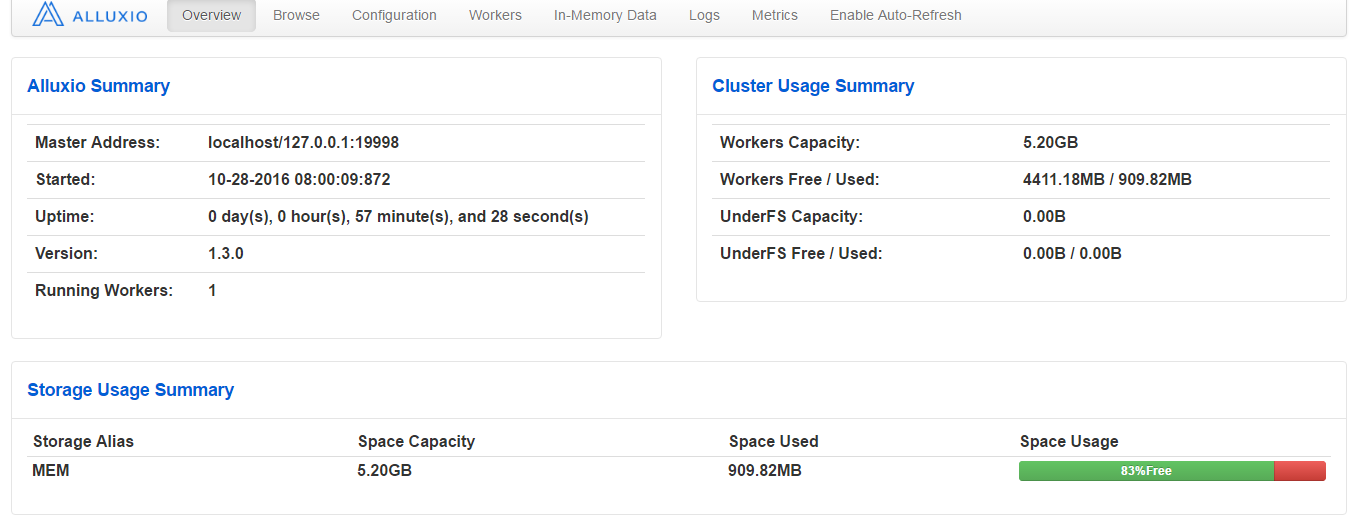
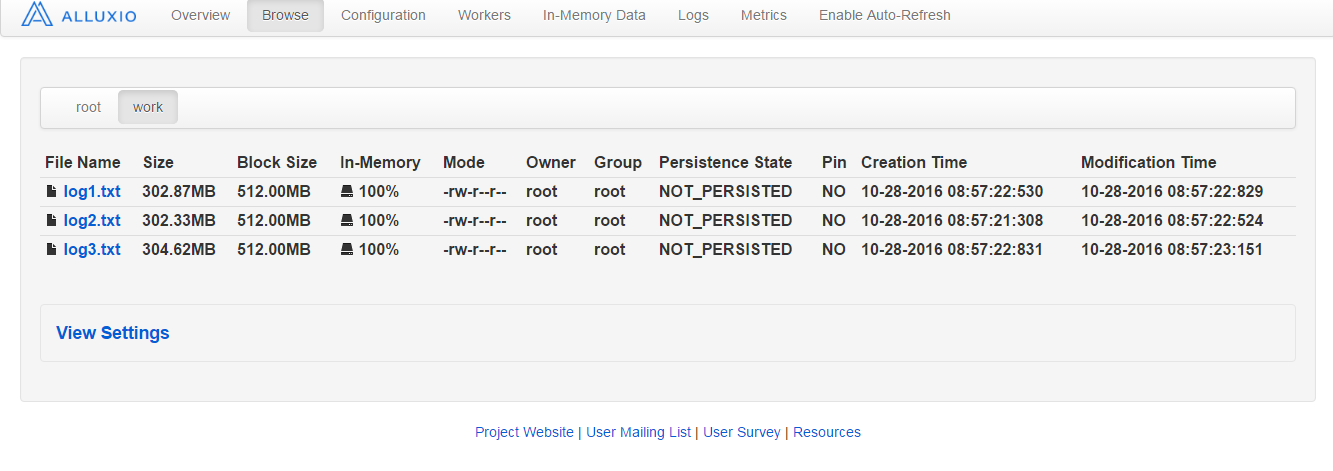
入ったっぽい
ちなみにHDFSっぽくlsとかrmとかcatとかもつかえる
$ ./bin/alluxio fs cat /work/* |wc -l
5092839
$
Sparkからアクセスしてみる
Spark SetUp
$ wget http://apache.mirrors.pair.com/spark/spark-2.0.1/spark-2.0.0.tgz
$ tar xfvz spark-2.0.0.tgz
$ ln -s spark-2.0.0.tgz spark
$ cd spark
$ mvn clean package -Pspark -DskipTests
$ ./sbin/start-all.sh # ssh localhostできるようにしておく
$ vi conf/spark-defaults.conf # さっきalluxioをbuildしたclientのjarを指定する
spark.driver.extraClassPath /root/alluxio/core/client/target/alluxio-core-client-1.3.0-jar-with-dependencies.jar
spark.executor.extraClassPath /root/alluxio/core/client/target/alluxio-core-client-1.3.0-jar-with-dependencies.jar
countしてみる
$ ./bin/spark-shell
scala> val s = sc.textFile("alluxio://localhost:19998/work/*")
s: org.apache.spark.rdd.RDD[String] = alluxio://localhost:19998/work/* MapPartitionsRDD[1] at textFile at <console>:24
scala> s.count()
[Stage 2:=======================================> (2 + 1) / 3]
res0: Long = 5092839
scala>
ちゃんとうごいてるっぽい
ちなみに1Gのファイルをカウントしてみた時間
alluxio
scala> val start = System.currentTimeMillis(); val s = sc.textFile("alluxio://localhost:19998/work/*"); s.count(); val end = System.currentTimeMillis(); val interval = end - start;
start: Long = 1477907300034
s: org.apache.spark.rdd.RDD[String] = alluxio://localhost:19998/work/* MapPartitionsRDD[1] at textFile at <console>:30
end: Long = 1477907304488
interval: Long = 4454
scala>
local
scala> val start = System.currentTimeMillis(); val s = sc.textFile("/var/tmp/work/*"); s.count(); val end = System.currentTimeMillis(); val interval = end - start;
start: Long = 1477907405639
s: org.apache.spark.rdd.RDD[String] = /var/tmp/work/* MapPartitionsRDD[5] at textFile at <console>:32
end: Long = 1477907409010
interval: Long = 3371
scala>
まぁ1Gくらいだと対して変わらん?(1TBとかのメモリ用意できればちゃんと計測できるんだけどおかねない;;)