GANの実装方法は多岐にわたる
先日kaggleの犬コンペに参加した時に、GANの実装方法が犬の数だけあって驚いたので、その中で個人的に気になった部分だけ比較して検証してみようと思います。
※ここではGANの説明はしません。詳しい記事は他の方がわかりやすく書いてくださっているので、御覧ください。
GANについて概念から実装まで ~DCGANによるキルミーベイベー生成~
今さら聞けないGAN(1) 基本構造の理解
初めに
GANの学習はとても難しいと言われていて、実際に私もコンペに出て実感しました。
最終的な精度云々ではなく、学習途中でlossが発散するなどしてしまい、それ以降はepochを重ねてもそこから向上しません。
GANの品質や多様性の改善と同じく効率的な学習方法についての論文も多く出てます。
下記の記事にてもっと役に立つ手法がいっぱいあります。
GAN(Generative Adversarial Networks)を学習させる際の14のテクニック
GANで学習がうまくいかないときに見るべき資料
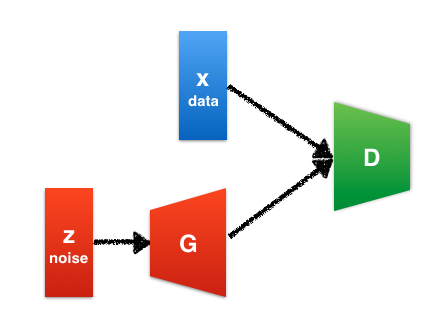
GANの仕組み
GANではgeneratorとdiscriminatorという2つのネットワークが登場します。Generatorは訓練データと同じようなデータを生成しようとします。一方、discriminatorはデータが訓練データから来たものか、それとも生成モデルから来たものかを識別します。
この関係は紙幣の偽造者と警察の関係によく例えられます。偽造者は本物の紙幣とできるだけ似ている偽造紙幣を造ります。警察は本物の紙幣と偽造紙幣を見分けようとします。
次第に警察の能力が上がり、本物の紙幣と偽造紙幣をうまく見分けられるようになったとします。すると偽造者は偽造紙幣を使えなくなってしまうため、更に本物に近い偽造紙幣を造るようになります。警察は本物と偽造紙幣を見分けられるようにさらに改善し…という風に繰り返していくと、最終的には偽造者は本物と区別が付かない偽造紙幣を製造できるようになるでしょう。
GANではこれと同じ仕組みで、generatorとdiscriminatorの学習が進んでいきます。最終的には、generatorは訓練データと同じようなデータを生成できるようになることが期待されます。このような状態では、訓練データと生成データを見分けることができなくなるため、discriminatorの正答率は50%になります。
上記の説明にもある通りG(generator)とD(discriminator)の2つのネットワークがそれぞれ敵対的(協力的?)に学習を進めていくところが「Generative Adversarial Networks」(GAN)と呼ばれる所以です。
この学習の進め方がほんとに色々あるのですが、その中でも気になった部分があります。
lossを流すタイミング

多くのGANの学習ステップとして多いのは
1. 本物画像(real_image)をDに識別させてlossを計算する。
2. 潜在変数zを乱数から作成し、Gにて(fake_image)を生成する。
3. Dにて(fake_image)を識別させてlossを計算する。
4. Dにreal,fakeのlossを同時に流す。
5. 1と同様にfake_imageを再度作成する。
6. Dに(fake_image)だけ判別をさせて、そのlossをGに流す。
このステップがおそらくGANの原文にもある通り、基本ステップだと思います。
これをパターンAとします。
基本的にはGANはmodelを通すタイミングがG,D合わせて5回あります。
[Dの学習時] G_pred, D_fake, D_real
[Gの学習時] G_pred, D_fake
lossを流すタイミングは3回です。
[Dの学習時] D_fake, D_real
[Gの学習時] D_fake
lossを流した後に、modelを通したり、modelを全て通し終わった後にlossを流したり等いくつかパターンがありましたので、その違いを比較していきます。
細かい説明になってきますが、重要なのはlossを流すタイミングとmodelを通すタイミングです。
パターンB
1. 潜在変数zを乱数から作成し、Gによって(fake_image)を生成する。
2. Dにて(fake_image)のみ判別させて、**G**にlossを流す。
3. 1と同様にfake_imageを再度作成する。
4. Dによって(fake_image)と実際のデータ(real_image)を判別する。
5. それぞれlossを計算して、そのlossをDに同時に流す。
Dの学習→Gの学習の流れが逆転してGの学習→Dの学習になったパターンです。
どっちも変わらない気がしますが、先に学習するモデルの方が若干有利になりそうです。
この場合、Gにlossが流れて賢くなった後に再度fake_imageを作成してDを騙すので、
Dは精度が少し下がりそうな気がします。
最終的な精度にどれだけ影響するかは不明ですが。
パターンC
1. 潜在変数zを乱数から作成し、Gによって(fake_image)を生成する。
2. Dによって(real_image)のみ判別してDに(real_image)のlossを流す
3. Dによって(fake_image)のみ判別してDに(fake_image)のlossを流す
4. 1と同様にfake_imageを再度作成する。
5. Dに(fake_image)だけ判別をさせて、そのlossをGに流す。
※2,3は逆転するパターンもあります。
Aと比較するとD_lossを流す際にfake,realを**「同時に流すか、片方ずつ流すか」という違いがあります。
この場合は2でrealのみのlossを先に流しているので、賢くなった後で3のfake_imageの判別を行っています。
2で適切なlossが流れているとしたら、fake_imageの判別はAと比較してより正しい判断になります。
正しい判断になるということはDにlossが流れづらい**ということになります。
パターンD
1. 潜在変数zを乱数から作成し、Gにて(fake_image)を生成する。
2. Dにて(fake_image)と実際のデータ(real_image)を判別する。
3. それぞれlossを計算しておくが、まだ流さない。
4. 1と同様にfake_imageを再度作成する。
5. Dに(fake_image)だけ判別をさせて、そのlossをGに流す。
6. 3のlossをDにも流す。
このパターンはあまり見なかったのですが、個人的にはこれが一番フェアな気がします。
imageの作成やlossの計算はD,G共に全て終わらせてから、D,G同時に勾配を流すパターンです。
これならfake_image作成する際も、Dがreal,fakeの判別する際にもまだ勾配が流れていない状態なので、フェアです。
D,G同時に正解を知らされる感じです。
なんでこのパターンがあまり無いのか不明ですが、実装は簡単なので比較してみます。
何度も言いますが重要なポイントはlossを流すタイミングです。
lossを流してからpredictをするのか、predictを全て終わらせてからlossを流すのかという所の比較です。
また、上記のパターン意外にも色々あります。
DやGに複数回lossを流してみたりとか、条件付けをしてlossの数値が一定の値を超えた場合はlossを流すとか工夫がされてます。
とりあえずは上記パターンの違いが、どんな変化を生むかを検証してみます。
予想
大雑把にパターンの違いによる変化の予想をしてみます。
Aをベースラインとしてどうなるかという予想です。
| 予想 | Dの精度 | loss |
|---|---|---|
| B | 下がる | D↑G↓ |
| C | 上がる | D↓G↑ |
| D | 下がる | D↑G↓ |
上記の説明をおさらいすると
- BはG_lossを先に流すのでGが有利→Dの精度が下がる
- CはD_lossをfake,real別々に流すのでDが有利→Dの精度が上がる
- DはAではD_lossを先に流してたものを、D_loss,G_lossと同時にしたのでDが不利→Dの精度が下がる
という様な推測です。
前半の推移は上記の予想に近い気はしますが、中盤以降の動きは全くどうなるかわかりません。
ましてや、最終的なスコアにどういった影響を与えるのかと言うのは更に予想がつきません。
実験
環境
- kaggleの犬ganコンペのコードを基本的には利用
- PyTorchを使用
- 比較数値としてD,Gのloss,Dの出力,FID(50epochごと),Inception_score(50epochごと)の推移を比較
- optimizerとしてRAdamを使用
- kaggleのカーネルを使用して8.5時間回す
- inception_scoreはこちらのコードを使用
- FIDはkaggleから公式に配布されたコードを使用。
新しい物好きな性格と、スケジューラーの設定がめんどくさいということもあったので、
何故かRAdamを使用してます。
適切かどうかはわかりません笑
そして、基本的なパターンAのコードはこんな感じです。
for itr, data in tqdm(enumerate(dataloader), total = len(dataloader)):
#-------- Update Discriminator ---------
netD.zero_grad() # Dの勾配を初期化
output = netD(real_image) # 本物画像をDに識別させる(1)
errD_real = criterion(output, real_target) # BCEloss 本物画像との誤差を計算(1)
noise = torch.randn(sample_size, nz, 1, 1, device=device) # 偽物画像の元(ノイズ)を作成(2)
fake_image = netG(noise) # 偽物画像を作成(2)
output = netD(fake_image.detach()) # 偽物画像をDに識別させる(3)
errD_fake = criterion(output, fake_target) # 偽物画像の誤差を計算(3)
errD = errD_real + errD_fake # 2つの誤差を足し合わせる(4)
errD.backward() # Dに勾配を流す。(4)
#--------- Update Generator ----------
netG.zero_grad() # Gの勾配を初期化
noise = torch.randn(sample_size, nz, 1, 1, device=device) # 再度偽物画像の元(ノイズ)を作成(5)
fake_image = netG(noise) # 偽物画像を作成(5)
output = netD(fake_image) # 偽物画像をDに識別させる(6)
errG = criterion(output, real_target) # 偽物画像との誤差を計算(6)
errG.backward() # Gに勾配を流す。(6)
分かりやすくする為に色々端折ってますが、基本的にはこんな感じです。
文末の数字は上記で参照したパターンAのステップ数を表しています。
これらをそれぞれ4パターン回してみました。
パターンBの考察
450エポック前後まで学習していましたが、D_outとlossの後半の推移はほとんど変わらなかったので150エポック位までで比較してます。
D_out(左A,右B)
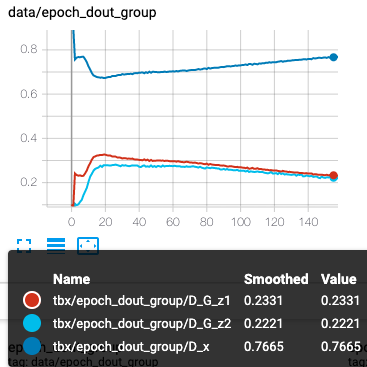
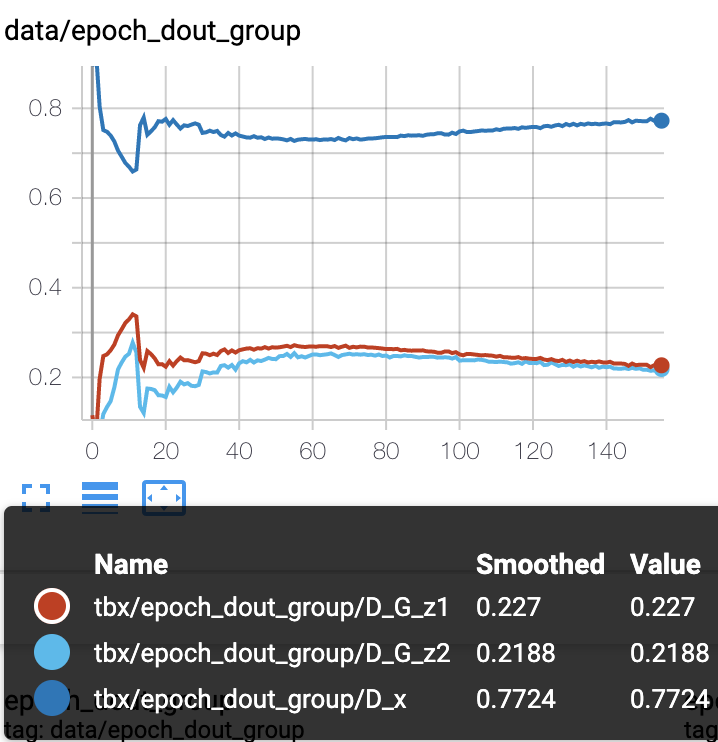
- 青がD_real
- オレンジはD学習時のD_fake
- 水色がG学習時のD_fake
※Dにはsigmoidが入っているので、1に近ければrealだと判断、0に近ければfakeだと判断したとなります。
realとfakeの差が広ければ広いほどDの精度は良くて相対的にGの精度は悪いとなります。
逆も然り
loss(左A,右B)
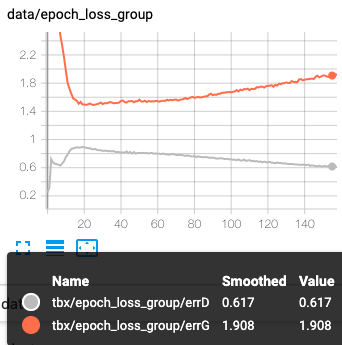
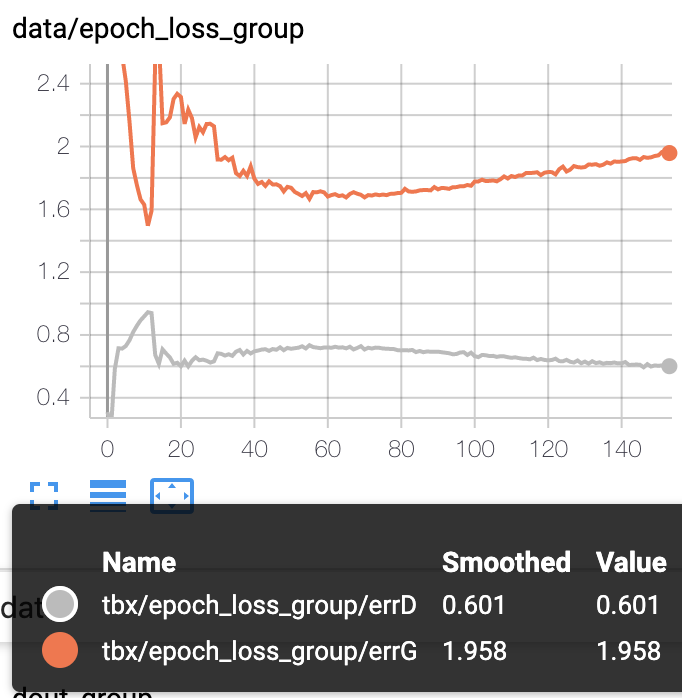
- オレンジはG_loss
- グレーはD_loss
<考察>
Gが有利になり、Dの精度が下がると予想しましたが、反対の結果となりました。
最初の10エポック辺りでDに多めのlossが流れたことで、逆にDが賢くなったのかもしれません。
10エポック辺りでD_outのreal,fakeの差が急激に広がってます。
それによってG_lossも上昇して、D_lossは下がってます。
このG_lossの上昇がスコアにいい影響を与えてくれると良いんですが、どうなるでしょうか。
inception_score(左A,右B)
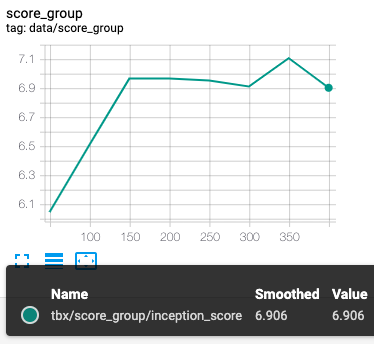
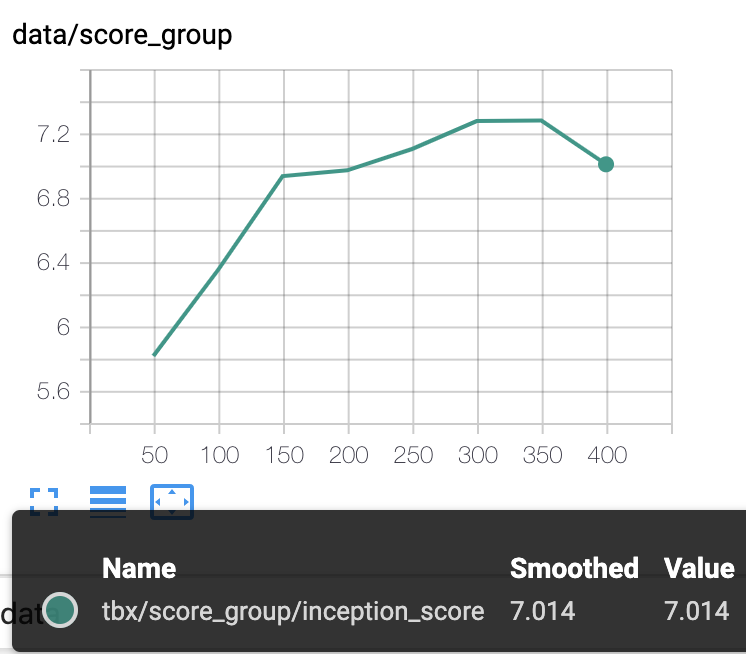
inceptionは高いほうがいい数字
FID(左A,右B)
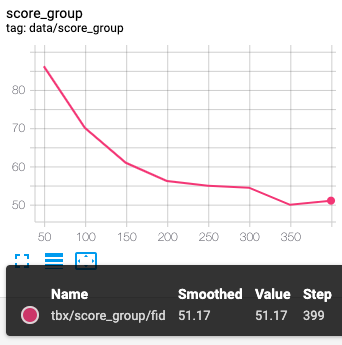
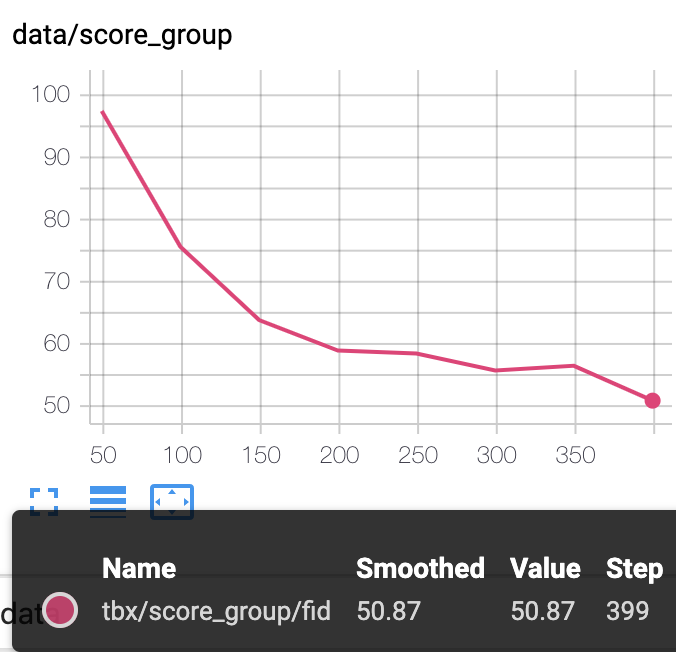
FIDは低い方がいい数字です。
<考察>
lossやdoutは前半に少しの差異が見られただけで、後半はほぼ変わらなかったのですが、スコアは違いが見られます。
まず、inception_scoreに関してはBの方が若干良いです。
そしてFIDはBのほうが悪い。
FIDは実画像の分布との差を図っていて、inceptionは画像自体の質と多様性を評価してるとのことです。
つまり今回は画像自体の評価はパターンBの方が良いが、実画像により近いのはパターンAということだと思われます。
前半にG_lossが大きかったので良い画像を生成しているかと思いきや、そこまででもありませんでした。
FIDはギリギリ最後に追いついた感じはありますが、遅れています。
もう少し長めにやっていれば、更に変化が見られたかもしれません。
G_lossが多い分inception_scoreを上げることは出来たけど、Dの精度が低いのでFIDの改善は出来なかったのかもしれません。
パターンCの考察
同様にAとの比較を行っていきます。
D_out(左A,右C)
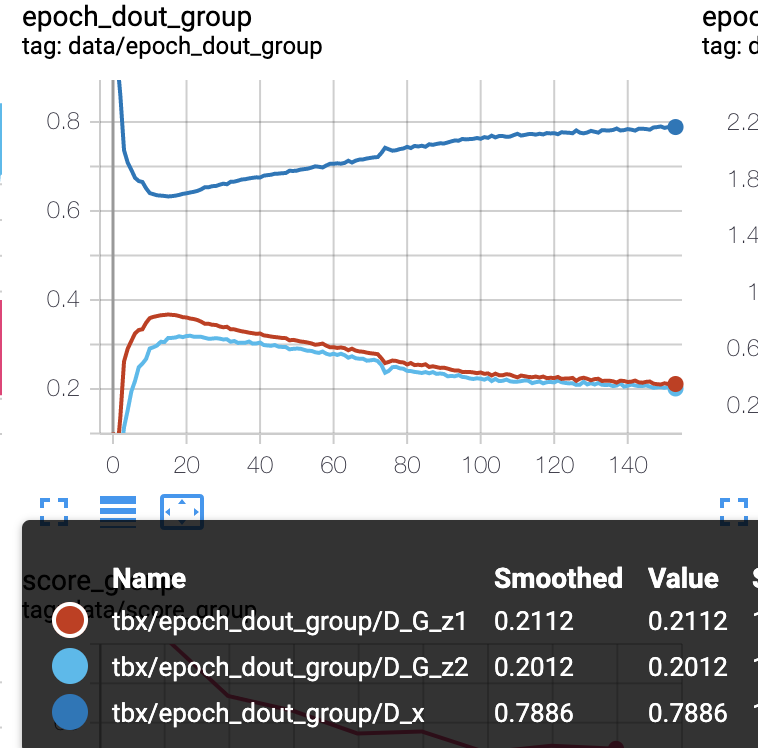
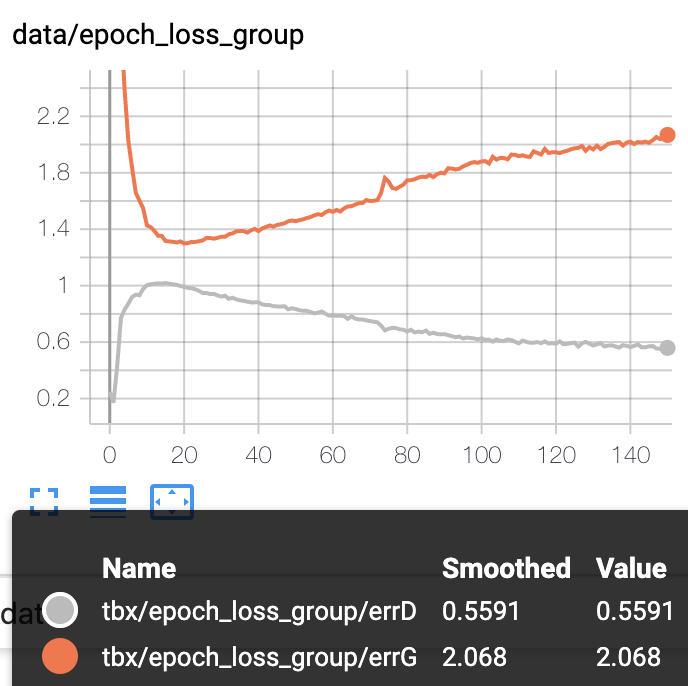
loss(左A,右C)
<考察>
こちらも予想が外れました。
Aと比較してDの精度が悪いです。
ただ、その後の精度の改善スピードは早く、後半はDが正しい判断が出来ています。
前半はDの精度が悪い為に、lossもDが高く、Gが低めです。
D_lossが多く流れたことから、結局Dがすぐに賢くなってGのlossがどんどん上がっていきます。
Dは学習が早いので、少しでも多めのlossを流すことでGが有利だったとしてもすぐに逆転されてしまう様な気がします。
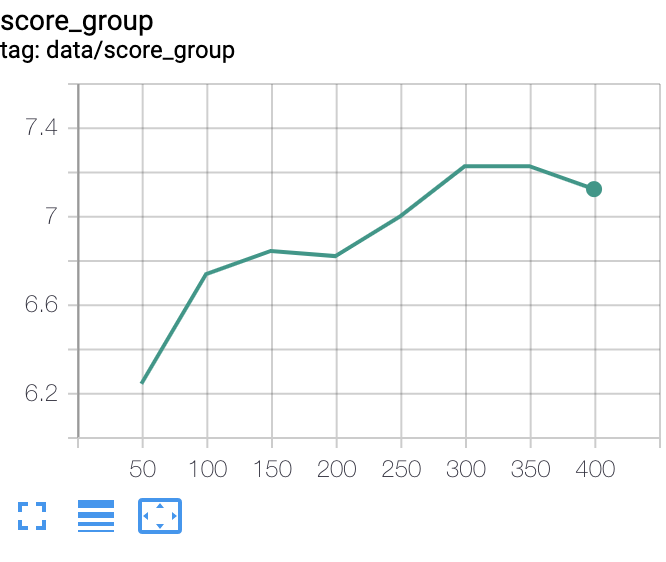
inception_score(左A,右C)
FID(左A,右C)
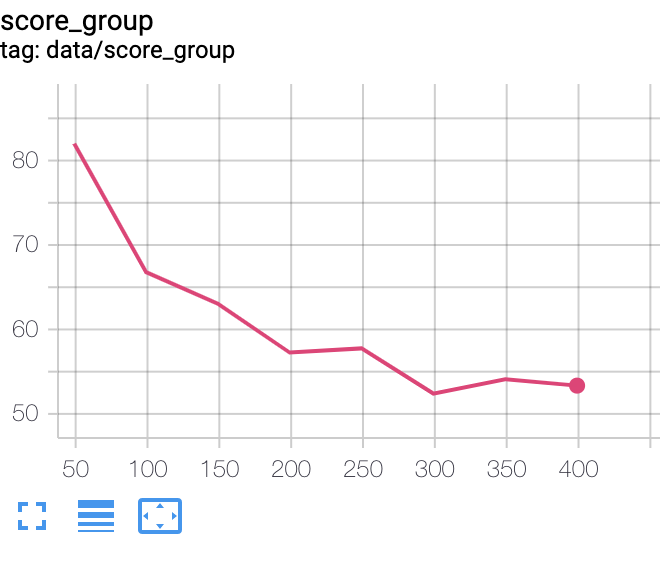
<考察>
inceptionに関しては初めの出だしは良かったもののその後の伸びが微妙です。
200エポック以降から更に一伸びあって、逆転しています。
150エポック以降にはG_lossが多く流れていき、inception_scoreを押し上げたかもしれません。
FIDはAほど下がりきりませんでした。
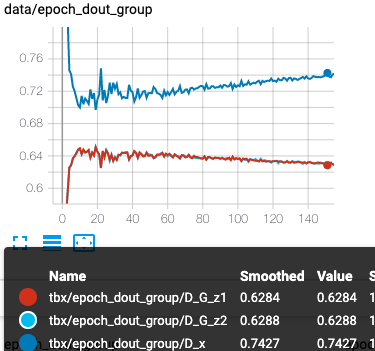
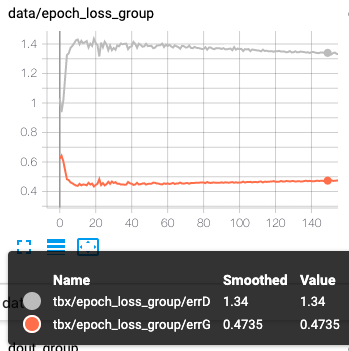
パターンDの考察
ちょっと疲れたのと、よくわからない感じになったのでまとめて載せます。
左dout,右loss
左inception,右fid
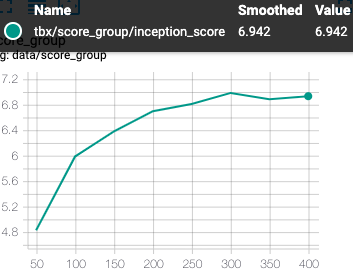
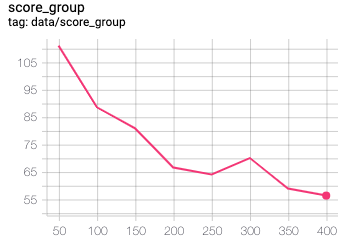
<考察>
こちらはDの精度が悪くなる予想でしたが、その通りとなりました。
ただ、想像以上に精度は悪くて、lossに関してはG,Dが逆転してます。
コードに何かしら不備があるかもしれません。
ただ、スコアだけを見るとそこまで大きな変化はありません。
スコアは改善に向かっていっているので、正常な気がします。
学習のバランスが崩れてしまっただけかもしれません。
総括
感想としては、予想以上に大きな変化が出たなという感覚です。
学習の順番等のタイミングを変えているだけで、lossの大きさ自体は操作していないのですが、それだけでここまで変化がありました。
意図した通りの変化を与えることは難しくて、ささいな変化が全体的なバランスを大きく変えてしまいます。
ここら辺がやっぱりGANが難しいと言われる所以でしょう。
感覚的にDは学習スピードが早いので、少しでも多くlossが流れるとGはすぐに逆転されてしまいます。
ただDの精度が上がらないと、Gに適切なlossが流れないということもあると思います。
結局どんな形のlossの推移がベストなのかは分からずじまいでしたが、学習が難しいということだけはわかりました。
あと、トータルで流れたlossの量も記録しておいたら良かった気がします。
lossの量によって、どんな影響を与えるのかというのも興味があります。
ちなみに素人の考察なので、間違っている部分は多くあるとおもいます。
もし、気づいたことなどあればコメントを頂けると勉強になって嬉しいです。
また、今回のパターンによる差異はどこまで有意かどうかはわかりません。
特にinceptionやFIDは50エポックに一回しか図っていないので、偶然差が出ただけかもしれません。
そこら辺はご理解くださいませ。
学習部分のコード
fid_each_epoch = 50
rap_time_list = []
for epoch in range(n_epoch):
epoch_start_time = time.time()
if pattern == 'B' or 'D':
for itr, data in tqdm(enumerate(dataloader), total = len(dataloader)):
#--------- ラベル作成 ----------
real_image = data.to(device) # Real Images
sample_size = real_image.size(0) # The number of images
real_target = torch.full((sample_size,), 1., device=device) # real target
fake_target = torch.full((sample_size,), 0., device=device) # fake target
#--------- Update Generator ----------
netG.zero_grad() # initialize gradient
noise = torch.randn(sample_size, nz, 1, 1, device=device) # generate input noise
fake_image = netG(noise) # fake images
output = netD(fake_image) # Discriminator output for fake image
errG = criterion(output, real_target) # MSELoss
D_G_z2 = output.mean().item() # for logging
if pattern != 'D':
errG.backward() # backward
optimizerG.step() # Updata Generator params
#-------- Update Discriminator ---------
netD.zero_grad() # initialize gradient
output = netD(real_image) # Discriminator output for real image
errD_real = criterion(output, real_target) # MSELoss
D_x = output.mean().item() # for logging
noise2 = torch.randn(sample_size, nz, 1, 1, device=device) # generate input noise
fake_image2 = netG(noise2) # fake images
output2 = netD(fake_image2.detach()) # Discriminator output for fake image
errD_fake = criterion(output2, fake_target) # MSELoss
D_G_z1 = output2.mean().item() # for logging
if pattern == 'D':
errG.backward() # backward
optimizerG.step() # Updata Generator params
errD = errD_real + errD_fake # Discriminator Loss
errD.backward() # backward
optimizerD.step() # Updata Discriminator params
errg_list.append(errG.item())
errd_list.append(errD.item())
dout_real.append(D_x)
dout_fake1.append(D_G_z1)
dout_fake2.append(D_G_z2)
writer.add_scalars("data/loss_group", {'errD': errD.item(),
'errG': errG.item()}, epoch*len(dataloader)+itr)
writer.add_scalars("data/dout_group", {'D_x': D_x,
'D_G_z1':D_G_z1,
'D_G_z2':D_G_z2}, epoch*len(dataloader)+itr)
else:
for itr, data in tqdm(enumerate(dataloader), total = len(dataloader)):
real_image = data.to(device) # Real Images
sample_size = real_image.size(0) # The number of images
real_target = torch.full((sample_size,), 1., device=device) # real target
fake_target = torch.full((sample_size,), 0., device=device) # fake target
#-------- Update Discriminator ---------
netD.zero_grad() # initialize gradient
output = netD(real_image) # Discriminator output for real image
errD_real = criterion(output, real_target) # MSELoss
if pattern == 'C':
errD_real.backward()
D_x = output.mean().item() # for logging
noise = torch.randn(sample_size, nz, 1, 1, device=device) # generate input noise
fake_image = netG(noise) # fake images
output = netD(fake_image.detach()) # Discriminator output for fake image
errD_fake = criterion(output, fake_target) # MSELoss
if pattern == 'C':
errD_fake.backward()
D_G_z1 = output.mean().item() # for logging
errD = errD_real + errD_fake # Discriminator Loss
if pattern == 'A':
errD.backward() # backward
optimizerD.step() # Updata Discriminator params
#--------- Update Generator ----------
netG.zero_grad() # initialize gradient
noise = torch.randn(sample_size, nz, 1, 1, device=device) # generate input noise
fake_image = netG(noise) # fake images
output = netD(fake_image) # Discriminator output for fake image
errG = criterion(output, real_target) # MSELoss
D_G_z = output.mean().item() # for logging
errG.backward() # backward
optimizerG.step() # Updata Generator params
errg_list.append(errG.item())
errd_list.append(errD.item())
dout_real.append(D_x)
dout_fake1.append(D_G_z1)
dout_fake2.append(D_G_z2)
writer.add_scalars("data/loss_group", {'errD': errD.item(),
'errG': errG.item()}, epoch*len(dataloader)+itr)
writer.add_scalars("data/dout_group", {'D_x': D_x,
'D_G_z1':D_G_z1,
'D_G_z2':D_G_z2}, epoch*len(dataloader)+itr)
writer.add_scalars("data/epoch_loss_group", {'errD': np.mean(errd_list[epoch*len(dataloader):]),
"errG": np.mean(errg_list[epoch*len(dataloader):])}, epoch)
writer.add_scalars("data/epoch_dout_group", {'D_x': np.mean(dout_real[epoch*len(dataloader):]),
"D_G_z1": np.mean(dout_fake1[epoch*len(dataloader):]),
"D_G_z2": np.mean(dout_fake2[epoch*len(dataloader):]),}, epoch)
writer2.add_images('fake_images', fake_image[:10] * 0.5 + 0.5, global_step=epoch, walltime=None, dataformats='NCHW')
rap_time = time.time() - epoch_start_time
rap_time_list.append(rap_time)
if epoch % fid_each_epoch == fid_each_epoch-1: # fid_each_epoch回数分、画像出力、loss、d_outプロット、画像を10000枚作成、FID計算まで行う。
show_generated_img()
outimg_path = '../output_images'+str(epoch)
create_image(netG,nz=nz,threshold=1,fold_name=outimg_path,n_images=10000, im_batch_size=100)
fid = fid_calc(outimg_path)
inception_data = Inception_data(outimg_path+'/*')
inc_mean, inc_std = inception_score(inception_data, cuda=True, batch_size=8, resize=True, splits=5)
print('inception_score=',inc_mean)
writer.add_scalars("data/score_group", {'fid': fid,
"inception_score": inc_mean}, global_step=epoch)
if time.time() - start_time > 60*60*8.5:
break