はじめに
RAG(Retrieval-Augmented Generation)の検索部分をベクトル検索だけに頼ると、エラーコードのような exact match に弱いケースがあります。本記事では、Vector Search と BM25 を Reciprocal Rank Fusion (RRF) で統合したハイブリッド検索を備えた RAG チャットボットの実装を紹介します。
なお、検索対象として投入しているのは架空のスマートサーモスタット「AeroEco Smart Thermostat Pro」の取扱説明書です。実在の製品とは関係ありません。
構成はシンプルで、Python + FastAPI のバックエンドと、SSE でストリーミング表示するフロントエンドの1ファイル構成です。
技術スタック
| 役割 | 技術 |
|---|---|
| LLM エージェント | AWS Strands Agents SDK + Claude (Bedrock) |
| ベクトル DB | Chroma DB |
| Embedding | Amazon Titan Embed Text v1 |
| キーワード検索 | rank-bm25 (BM25Okapi) |
| API サーバー | FastAPI + SSE ストリーミング |
| フロントエンド | Vanilla JS(グラスモーフィズム UI) |
画面イメージ
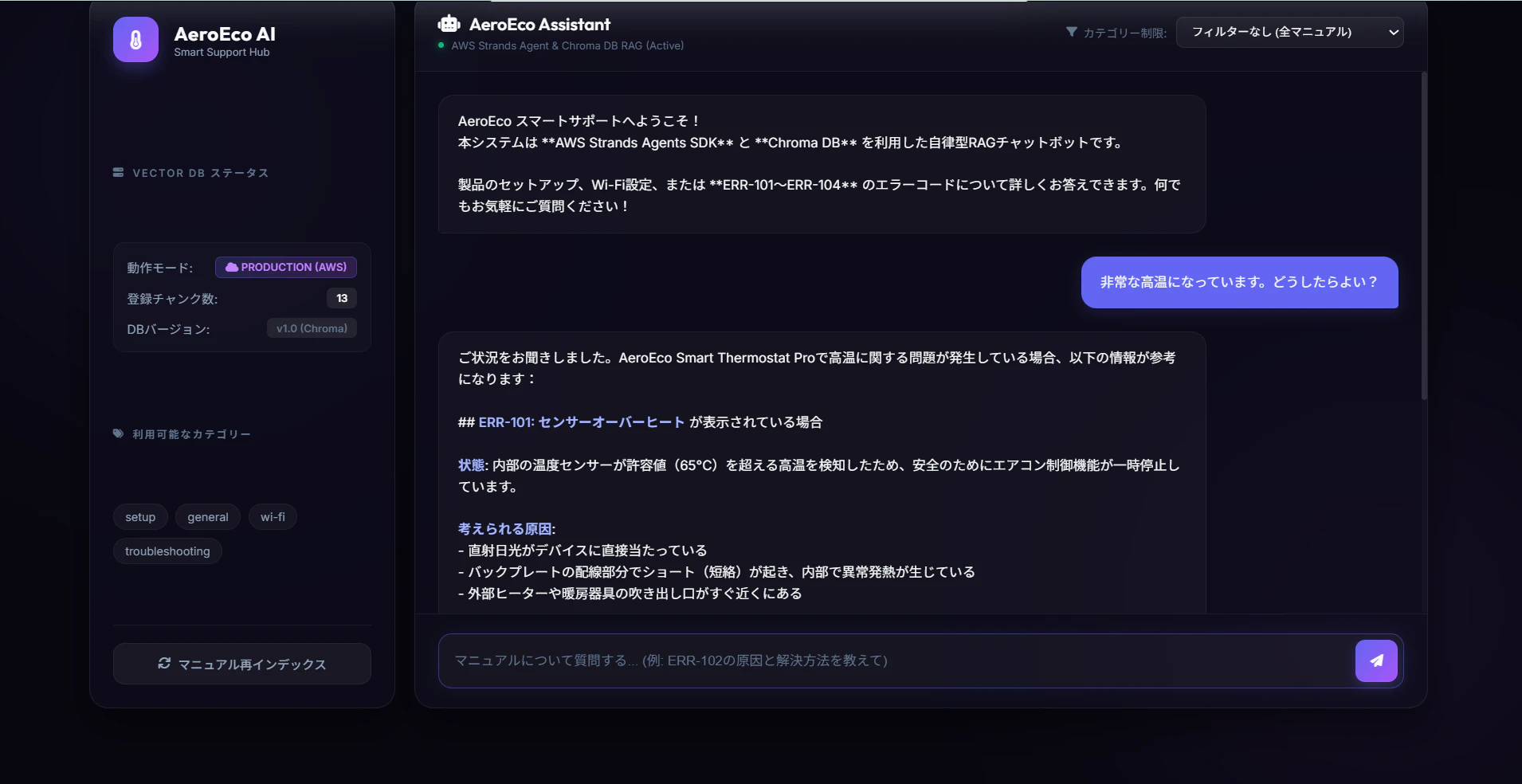
左サイドバーに DB ステータスとカテゴリー一覧、メインエリアにチャットが表示されます。
なぜハイブリッド検索か
ベクトル検索だけだと困るケースがあります。
ユーザー: 「ERR-107の対処方法は?」
Titan Embedding は「ERR-107」という短いコード文字列を意味空間で正確に捉えるのが苦手です。一方 BM25 なら、文書中に "ERR-107" が含まれるチャンクを確実にスコアリングできます。
逆に「温度が異常に高い」のような自然言語クエリでは、ベクトル検索が「センサーオーバーヒート」チャンクを意味的に拾えますが、BM25 は「オーバーヒート」という単語が query に含まれないため不利です。
両者を組み合わせれば、どちらのパターンにも対応できます。
実装のポイント
1. チャンカーで要約チャンクを自動生成
マニュアルを見出し単位で分割する際、親セクション(H2)配下の子セクション(H3)一覧をまとめた要約チャンクを自動生成しています。
# chunker.py(抜粋)
summary_chunk = {
"title": f"[要約] {parent['title']}",
"content": f"このセクションには以下の {len(children)} 件のサブセクションが含まれます:\n..."
f"エラーコードは合計 {len(error_codes)} 種類: {', '.join(error_codes)}",
"category": parent["category"],
}
これにより「エラーコードは何種類?」のような集約的な質問でも、top-k=3 で正確に回答できるようになります。
2. RRF によるランキング統合
def _reciprocal_rank_fusion(self, vector_results, bm25_ranked, n_results, k=60):
rrf_scores = {}
# Vector 検索の順位からスコア付与
for rank, doc_id in enumerate(vector_results['ids'][0]):
rrf_scores[doc_id] = {"score": 1.0 / (k + rank + 1), ...}
# BM25 検索の順位からスコア加算
for rank, (doc_id, doc, meta, _) in enumerate(bm25_ranked):
rrf_score = 1.0 / (k + rank + 1)
if doc_id in rrf_scores:
rrf_scores[doc_id]["score"] += rrf_score # 両方に出現 → スコア加算
else:
rrf_scores[doc_id] = {"score": rrf_score, ...}
# スコア降順で top-k を返す
return sorted(rrf_scores.items(), key=lambda x: x[1]["score"], reverse=True)[:n_results]
k=60 は Cormack et al. (2009) の推奨値です。両方のランキングで上位に来るドキュメントほどスコアが高くなります。
3. SSE ストリーミング
FastAPI の StreamingResponse で回答をワード単位で逐次送信しています。
@app.post("/api/chat/stream")
def chat_stream_endpoint(request: ChatRequest):
def generate():
# ... エージェント実行 ...
words = answer_text.split(" ")
for word in words:
yield f"data: {json.dumps({'type': 'chunk', 'content': word})}\n\n"
time.sleep(0.03)
yield f"data: {json.dumps({'type': 'done'})}\n\n"
return StreamingResponse(generate(), media_type="text/event-stream",
headers={"Cache-Control": "no-cache", "X-Accel-Buffering": "no"})
フロントエンド側は response.body.getReader() で ReadableStream を消費し、チャンク到着ごとに DOM を更新します。
4. AWS 未接続時の自動フォールバック
起動時に Bedrock への接続テストを行い、失敗すればローカルデモモードへ自動切替します。デモモードではキーワードマッチ + テンプレート回答で動作するため、AWS 環境がなくても動作確認が可能です。
動かし方
git clone <repo>
cd easy-rag
./run.sh start
# → http://localhost:8000
AWS 認証情報がなければデモモードで起動します。
まとめ
- ベクトル検索だけの RAG には、exact match に弱い弱点がある
- BM25 を併用し RRF で統合すれば、少ない実装コスト(30行程度)でカバーできる
- 要約チャンクの自動生成で、集約クエリへの回答精度も改善できる
- SSE ストリーミングで UX を向上させつつ、フォールバック設計で環境依存を減らせる