Shell Script Advent Calendar 2015 15日目 です。穴が空いていたので入っちゃいました。
★14日目は @laqiiz さんの "Googleの肩に乗ってShellコーディングしちゃおう" でした! コーディング規約…み…耳が痛いです
★16日目は @sosuke さんの "fish shell で補完の実装 - complete" です! fish では補完関数による候補生成ができないのですかね…??
概要
POSIX sh 縛りだとバイナリをシェルの組み込み機能だけで正しく扱うのは困難な様ですが、Bash/Zsh ならシェルの組み込み機能だけでバイナリファイルを扱えます! 外部コマンドは不要です! (ただし遅いけど)
言及
記事タイトルは @richmikan@github さんの POSIX 原理主義な記事 "シェルスクリプトはバイナリを扱えない。さてどうしよう……" を勝手に真似ました。あとこの記事は、@fumiyas さんのピュアシェルな記事 "バイナリーデータの扱い方 - 拡張 POSIX シェルスクリプト Advent Calendar 2013 - ダメ出し Blog" がきっかけで書きました。
1 みんなシェルでバイナリを処理したいに違いない!
検索するとたくさん出てきます。
POSIX sh および Bourne sh
- シェルスクリプトはバイナリを扱えない。さてどうしよう…… - Qiita
- Bシェルで、1文字づつ読み込む方法を教えてください。(バイナリ) - その他(プログラミング) | 教えて!goo
- text processing - Shell: How to read the bytes of a binary file and print as hexadecimal? - Unix & Linux Stack Exchange
POSIX sh じゃない (bash, zsh, ksh, etc. の機能を使用)
- JPEG の EXIF 除去の話題 (2年前)
ImageMagick による標準的な方法から、シェル芸、シェルスクリプトへと進化していく過程が面白いです!
- ImageMagick による普通の方法: 「奥さん、その写真、どこで撮ったかバレてますよ」的な問題に対するシェル芸的な対策 – 上田ブログ
-
cat/od/sed/tr/awk/gawkによるシェル芸: バイナリをテキストに直してまたバイナリに戻すワンライナー | 上田ブログ -
odを用いた bash/zsh/ksh スクリプト: バイナリーデータの扱い方 - 拡張 POSIX シェルスクリプト Advent Calendar 2013 - ダメ出し Blog -
ddを用いたスクリプト: Mitzyuki's Blog :: Exif 情報から GPS の緯度/経度情報を削除する
- shell でバイナリを扱う。進数変換する。osx
- shell script - Fetching individual bytes from a binary file into a variable with bash - Unix & Linux Stack Exchange
- Reading raw data using a shell script?
これは…バイナリをシェルで取り扱おうとみんな思っている…に違いありません! きっとそうです! 需要があるに違いありません!
しかし一方で、眺めてみるとどうも皆シェルだけでバイナリは扱えないと思っている様で、外部コマンド od (など) に頼る記事しか見付かりません。bash や zsh を前提としている記事でも何故か最後には外部コマンドに流れていくみたいです。
なので、ここでは! シェルによるバイナリの取り扱いについて書きます!
2 基本アイディア
一番非自明な部分はバイナリデータを読み出すところです。数々の先人が言及しているように bash では、素直なやり方では NUL 文字 (ASCII) を変数に格納できません。
引用:
シェルスクリプトによるバッチ処理は便利ですね! テキスト処理も、ちょっと勉強して頑張れば、sed や awk なしでも大抵のことはできます… そう、拡張 POSIX シェルである bash, ksh, zsh ならね。 しかし、シェルにとってバイナリーデータは苦手、というかそのままでは無理。 NULL とか、NULL とか、NULL とか…。
by fumiyas さん, 2013/12/02つまり、AWKもシェルも、変数にnull(0x00)を格納できないということだ。ただし、ここまでも何回か記しているようにGNU版AWKとzshはできるのだが……。
by richmikan@github さん, 2015/02/05
今回は、各バイトを整数に変換して読み取る方針で NUL 問題を回避します! 基本は以下の1行で尽きています:
# bash の場合
IFS= read -r -d '' -n 1 byte && printf %d "'$byte"
# zsh の場合
IFS= read -r -d '' -k 1 -u 0 byte && printf %d "'$byte"
1文字ずつ読み取ってそれを整数に変換するのです。bash では NUL が来ると $byte が空文字列になってしまいますが、その後 printf でめでたく (期せずして) 正しい値 0 になります。zsh の場合はどうも NUL をちゃんと "\0" という文字列として扱ってくれる様なので特別な処置は不要(?)のようですが、bash と zsh で実装を切り替えるのも面倒なので同様に処理します。
3 読み書きする関数を実装する
実際には複数のバイトを処理しなければならないし、ロケールもあるし、効率の問題にも注意しなければならないし、シェル毎・バージョン毎の work around とかもあるし、…なので、毎回変換コードを書くのは面倒です。関数にまとめてしまいましょう!
以下は bash 用:
#!/bin/bash
## @fn readbinary < stdin
## バイナリデータを標準入力から読み出して配列 data に格納します。
## @var[out] data 読み取ったバイナリデータを格納します。
## @fn writebinary > stdout
## バイナリデータを配列 data から読み取って標準出力に書き出します。
## @var[in] data 出力するバイナリデータを格納します。
function readbinary {
data=()
local LC_ALL=C byte i=0
while IFS= read -r -d '' -n 1 byte; do
if [[ $byte == $'\x7F' ]]; then
data[i++]=127 # bash-3.0 対策: DEL が 0 になる
else
data[i++]="'$byte"
fi
done
data=($(printf '%d ' "${data[@]}"))
while ((--i>=0)); do
((data[i]&=0xFF)) # bash-4.0 未満対策: \x80-\xFF が負になる?
done
}
function writebinary {
LC_ALL=C printf "$(printf '\\x%x' "${data[@]}")" > "$1"
}
printf '%d ' "${data[@]}" の辺りで引数の個数の制限に引っかかるかもと思ったのですけれど、Bash 組込コマンドの場合には引数のサイズに制限はないのですかね…。1MiB ぐらいのファイルなら普通に読み込めたので余り気にしない事にしましょう。
さて、どうせなら速い方が嬉しいので、更に bash の version 毎に最善(?)と思われる方法で実装しちゃいましょう! (効率的に bash-4.0 以降が推奨)。序でに zsh にも対応:
#!/usr/bin/env bash
## @fn readbinary < stdin
## バイナリデータを標準入力から読み出して配列 data に格納します。
## @var[out] data 読み取ったバイナリデータを格納します。
##
## @fn writebinary > stdout
## バイナリデータを配列 data から読み取って標準出力に書き出します。
## @var[in] data 出力するバイナリデータを格納します。
_ble_bash=0
if [[ ${BASH_VERSINFO-} ]]; then
_ble_bash=$((BASH_VERSINFO[0] * 10000 + BASH_VERSINFO[1] * 100 + BASH_VERSINFO[2]))
fi
if [[ ${ZSH_VERSION-} ]]; then
# zsh
function readbinary {
data=()
local LC_ALL=C byte i=0 IFS=
[[ -o KSH_ARRAYS ]] || ((++i)) # zsh 配列の添字は 1 から
while read -r -d '' -k 1 -u 0 byte; do
data[i++]="'$byte"
done
IFS=' '
data=($(printf '%d ' "${data[@]}"))
}
function writebinary {
LC_ALL=C printf "$(printf '\\x%x' "${data[@]}")"
}
elif ((_ble_bash >= 40000)); then
# bash-4.0, 4.1, 4.2, 4.3
function readbinary {
data=()
local LC_ALL=C byte i=0 buff IFS=
while read -r -d '' -n 1 byte; do
data[i++]="'$byte"
done
printf -v buff '%d ' "${data[@]}"
IFS=' '
data=($buff)
}
function writebinary {
local buff
printf -v buff '\\x%x' "${data[@]}"
LC_ALL=C printf "$buff"
}
elif ((_ble_bash >= 30100)); then
# bash-3.1, 3.2
function readbinary {
data=()
local LC_ALL=C byte i=0 buff IFS=
while read -r -d '' -n 1 byte; do
data[i++]="'$byte"
done
printf -v buff '%d ' "${data[@]}"
IFS=' '
data=($buff)
while ((--i >= 0)); do ((data[i] &= 0xFF, 1)); done
}
function writebinary {
local buff
printf -v buff '\\x%x' "${data[@]}"
LC_ALL=C printf "$buff"
}
else
# bash-3.0
function readbinary {
data=()
local LC_ALL=C byte i=0 IFS=
while read -r -d '' -n 1 byte; do
if [[ $byte == $'\x7F' ]]; then
data[i++]=127 # bash-3.0 対策
else
data[i++]="'$byte"
fi
done
IFS=' '
data=($(printf '%d ' "${data[@]}"))
while ((--i >= 0)); do ((data[i] &= 0xFF, 1)); done
}
function writebinary {
LC_ALL=C printf "$(printf '\\x%x' "${data[@]}")"
}
fi
4 実例: 何をつくろうか…… base64?
バイナリでファイルを読み書きできるとなると何か作ってみたくなるのが人情です。ここでは @richmikan@github さんの "シェルスクリプトはバイナリを扱えない。さてどうしよう……" に倣って base64 でも作ってみましょうか。
真面目に実装しようかとも思いましたが、実証用なのでシンプルにエンコードだけ。
#!/bin/bash
[[ $ZSH_VERSION ]] && setopt KSH_ARRAYS
source readbinary.sh # 上記関数を読込
base64encode_table=($(printf '%d ' \'{{A..Z},{a..z},{0..9},+,/,=}))
function uparr { eval "unset $1 && $1=(\"\${@:2}\")"; }
## @fn base64encode dst src
## @param[out] dst 変換後のデータを格納する配列名を指定します。
## @param[in] src 変換元のデータの入っている配列名を指定します。
function base64encode {
[[ ${2:-src} == src ]] || eval "local -a src=(\"\${$2[@]}\")"
[[ ${1:-dst} == dst ]] || local -a dst
local slen=${#src[@]} si di ax
for ((si=0,di=0;si<slen;si+=3,di+=4)); do
((ax=src[si]<<16|src[si+1]<<8|src[si+2]))
dst[di]=${base64encode_table[ax>>18&0x3F]}
dst[di+1]=${base64encode_table[ax>>12&0x3F]}
dst[di+2]=${base64encode_table[si+1<slen? ax>> 6&0x3F: 64]}
dst[di+3]=${base64encode_table[si+2<slen? ax &0x3F: 64]}
done
[[ ${1:-dst} == dst ]] || { local "$1" && uparr "$1" "${dst[@]}"; }
}
function _base64 {
local -a data
if [[ $1 ]]; then
readbinary < "$1"
else
readbinary
fi
base64encode data data
writebinary
}
巨大 Bash 配列のランダムアクセスは O(N) っぽい → 遅いので再実装
上記コードを用いて、bash で試しに 100 KB ぐらいの ELF binary を流し込んでみたら 11 秒1ぐらいだったので、調子に乗って 1 MB のやつを流し込んだら 7 分1ぐらいかかりました。何か変なことが起こっていますね…。色々と動かしてみると**bash のループの中で2本以上の巨大配列の真ん中を触ると実行時間が $O(N^2)$ でスケール**する(N はデータサイズ)様子です (まさか bash は配列を双方向 sorted リストか何かで実装しているんだろうか…B木とかハッシュテーブルとかで実装し直して欲しい)。仕方がないので巨大配列の真ん中を触らないように function base64encode を書き直し:
# 速度改善版
function base64encode {
[[ ${2:-src} == src ]] || eval "local -a src; src=(\"\${$2[@]}\")"
[[ ${1:-dst} == dst ]] || local -a dst
local ax=0 dx di=0 cx=0
dst=()
for dx in "${src[@]}"; do
((ax=ax<<8|dx,++cx==3)) &&
((dst[di++]=base64encode_table[ax>>18 ],
dst[di++]=base64encode_table[ax>>12&63],
dst[di++]=base64encode_table[ax>> 6&63],
dst[di++]=base64encode_table[ax &63],
ax=cx=0))
done
((cx==1?(ax<<=16,
dst[di++]=base64encode_table[ax>>18 ],
dst[di++]=base64encode_table[ax>>12&63],
dst[di++]=base64encode_table[64],
dst[di++]=base64encode_table[64]):
(cx==2&&(ax<<=8,
dst[di++]=base64encode_table[ax>>18 ],
dst[di++]=base64encode_table[ax>>12&63],
dst[di++]=base64encode_table[ax>> 6&63],
dst[di++]=base64encode_table[64]))))
[[ ${1:-dst} == dst ]] || { local "$1" && uparr "$1" "${dst[@]}"; }
}
気を取り直して再度時間を計ると bash で、100KB 3.5秒、1MB 34.9秒になりました1。一方で zsh は巨大配列の要素書き換えが根本から苦手なようで時間が掛かりそうだったので計測を断念しました (簡単な見積もりによると 100KB 12分、1MB 20時間かかりそう)。
短いデータで勝負: base64.sh vs command base64
外部コマンド base64 (GNU coreutils) で試してみると 100KB 1.05ms, 1MB 2.58ms でした1。上記シェル関数 _base64 の計測結果と桁が違いますね…。大きなデータに対しては、全然勝ち目がありません。
そんな中、シェル関数が外部コマンドに勝てるかもしれない唯一の状況が短いデータの変換です。外部コマンドのプロセスを起動する為には時間が掛かります (fork/exec のコスト)。外部コマンドはハンデがあるのです。従って、短いデータで勝負すれば、シェル関数はハンデを覆される前にゴールできるという算段です。
そこで自分のへぼへぼシステム達に出てきてもらって計測しました。
計測環境:
| 略称 | $MACHTYPE |
/proc/cpuinfo model name |
|---|---|---|
| GNU/Linux 3.4GHz | x86_64-redhat-linux-gnu | Intel(R) Core(TM) i7-2600 CPU @ 3.40GHz |
| GNU/Linux 1.66GHz | i686-redhat-linux-gnu | Intel(R) Core(TM) Duo CPU T2300 @ 1.66GHz |
| Cygwin 1.86GHz | i686-pc-cygwin | Intel(R) Core(TM)2 CPU 6300 @ 1.86GHz |
bash を使います。上の3つとも、全部 bash-4.3.42 です。
計測方法: 適当にループさせて time で時間を計測しループ数で割ります。各データ点について 10 回程度ずつ計測を行い、その中で最小の物を採用します。データはヒアストリングで流し込みました。
_base64 <<< "データ"
base64 <<< "データ"
結果:
グラフから。横軸がデータ長 (単位はバイト) で、縦軸が処理時間です。青線が外部コマンド base64 で、赤線が上記シェル関数 _base64 です。処理時間は、青線の左端 (0バイト base64)が 1 になる様に規格化しています。
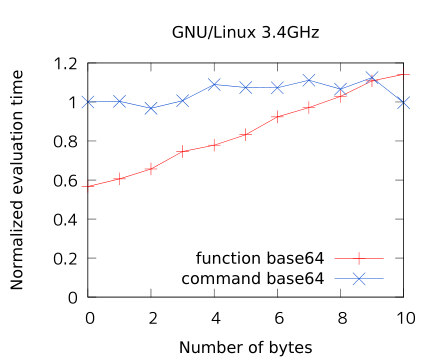
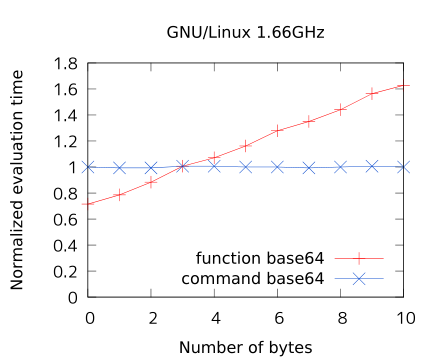
青線が横ばいなのは base64 の処理時間の殆ど全てが起動時間で、データ処理本体は見えないぐらい短時間で済んでいるということを意味します。一方で赤線を見ると、シェル関数はデータの処理に線形に時間が掛かるという事が分かります。
Linux だと数文字変換する内に外部コマンドに起動されてしまいます。システムにも依存する様ですが、余りシェル関数にする速度的なメリットはなさそうですね。
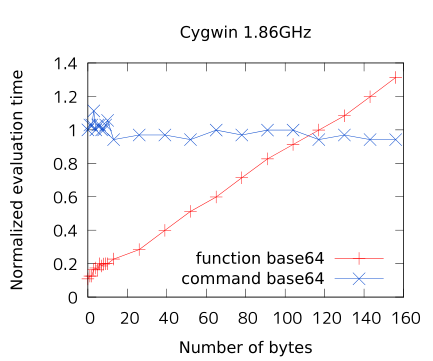
一方で Cygwin 環境では fork/exec に信じられないほど時間が掛かるので、この環境では 100バイト以下ならばシェル関数 _base64 の方が高速になっています。
5 最後に
結局シェルで全部処理しようとしても遅い! という結論になってしまいましたが、まあ、初めから予想できたことですね。じゃあ、シェルでバイナリを処理して何の意味があるのかというと、ただ単に楽しい! ということだけです(すみません…)。