はじめに
溜め込んだAppleWatchのデータをColab上でpandasとmatplotlibでいい感じに可視化したい
パパこんなにガンバッたんだよって、、娘に褒められたいんです。。
娘に尊敬されたい一心で、ガンバッてみました。
先に結論です。
作業自体は難しくないけど、データがとにかく重い。。
1年間コツコツ記録したおかげで、データ容量(xml)が643MB!
それと、
一部のデータがiphone・AppleWatchと値がなぜだか合わないです。
私のある1日の活動代謝は8972kcalでした。
あれっ?この日は、椅子に座ってコーディングだけだったのですが、、
ちなみに、ガチのトライアスロンと同じぐらいの消費カロリーだそうです。
(スイム:3.8km +バイク:180km +ラン:42.195km)
出力ミスなのか、それともPandasの操作ミスなのか、謎が深まります。。
それ以外は、おおむね使えそうなデータでしたので、歩数データを取り出して色々とゴニョってみることにしました。
Applewatchデータのエキスポート
兎にも角にも、まずはデータのエキスポートしないと始まらないです。
AppleWatchのデータは同期しているiphoneに貯められています。
AppleWatchに限らずに「ヘルスケア」アプリに紐付けられたデバイス、サードパーティアプリのログも1つのデータに統合されます。
それでは、iphoneの「ヘルスケア」アプリからエキスポートします。
今の所は、このアプリからのエキスポート以外の方法は無さそうです。
「ヘルスケア」アプリから書き出す
- iphoneの「ヘルスケア」を起動
- 右上の自分のアイコンを選択
- 「ヘルスケアデータを書き出す」を選択
- 案内に沿って、出力方法を選択し書き出す。
iphoneでの書き出しに10分程かかりました。
ファイルはzip圧縮されて、出力先はiCloud、メールなど選べます。
私の場合は、結構大きなファイルだったため、AirDropで直接macbookに転送しました。
zipを解凍すると、export.xmlを取り出せます。これがAppleWatchのログデータとなります。
xmlだとデータの取り回しが悪いので、csvに変換していきます。
データをCSVに変換
GitHubGistにステキな変換プログラムが公開されているのでそちらをダウンロード
ConvertAppleHealthXMLtoCSV.py
https://gist.github.com/xiantail/12784626d1c82411e0b986f71d1171ee#file-convertapplehealthxmltocsv-py
いくつか修正
# 以下:33行ー39行目をコメントアウト
# valueをkeyとする値が無くそのままではエラーになってしまったので
try:
float(att_values['value'])
except ValueError:
#att_values['value_c'] = att_values['value']
#att_values['value'] = 0
continue
# 以下:56行目
# 自分の環境に合わせて任意にpathを変更
if __name__ == '__main__':
convert_xml_to_csv('export.xml')
日付付きファイル名のcsvが生成されます。
export20191021214259.csv
(以降、面倒なのでexport.csvとします)
GoogleColab
正式名は、「Google Colaboratory」です。
Googleが提供するサービスで、一言でいうと「jupyter notebook」のクラウド版です。
こちらにデータを持ち込んでゴニョゴニョやっていきます。
Colabへのデータ取り込みにはいくつか方法があるようですが、私が行ったのは以下の方法です。
- export.csvをGoogleDriveにアップ
- GoogleColabからGoogleDriveのファイルを読み込む
GoogleDriveにアップは割愛させていただきます。
GoogleDriveからファイルを読み込む
Clob上から、GoogleDriveにアップしたデータを読み込みます。
from google.colab import drive
drive.mount('/content/drive')
実行すると、リンク先の表示とauthorization codeの入力を求められます。
リンクを辿って、自分のGoogleアカウントの権限コードをコピーして入力すると、
サイドバー > ドライブ にgoogleDriveのファイルが表示されます。
余談ですがGoogleColabは英語ではありますが、痒い所に手が届く親切サービスです。
何か分からない、きっとそんな機能がありそうだなーと感じたら、
コードスニペットから検索することができます。
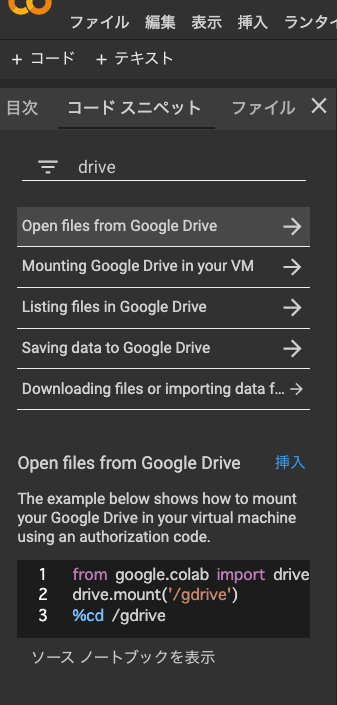
driveって打つだけでGoogleDriveの接続方法を教えてくれます。
さらに、「挿入」ボタンクリックするだけでコードをペーストしてくれます、便利ですね。
前処理
まずはお決まりのモジュールの読み込み。
import pandas as pd
import matplotlib.pyplot as plt
続いて、export.csvを読み込みます。
読み込みPathは、先程取り込んだサイドバー >ドライバーで該当のファイルを右クリックすると
パスをコピーが出てくるのでそちらを使ってコピペが便利です。
ファイルが大きすぎて読み込みに何度か失敗する場合は、low_memory=Falseのオプションを使ってみてください。
取り込み
df = pd.read_csv('/content/drive/My Drive/ColabNotebooks/export20191021214259.csv', low_memory=False)
df.head(3)

AppleHealthCareデータのフォーマットは以下となります。
- type: AppleHealthCare内でのデータ区分
- sourceName: データの取得元(この場合、「わたしの水」という連動アプリから取得されたデータ)
- sourceVersion: データ取得元のバージョンナンバー
- unit: 単位
- creationDate: データ作成日時
- startDate: データの取得の開始日時
- endDate: データの取得の終了日時
- value: 値 ほしいのはコレ
- device: 取得デバイス(センサー機器)
データ整理
データも重いし、見ずらいのでDataframeを少し整理します。
# デバイスはNaNか、appleWatchしか無いので削除、versionも特に必要無いので削除
df_apple = df.drop(["sourceVersion","device"], axis=1)
df_apple = df_apple.loc[:,['type','sourceName','value','unit', 'creationDate', 'startDate', 'endDate']]
# 作成日をIndexに設定、日付はただの文字列なのでdatetimeに型変換
df_apple = df_apple.set_index('creationDate')
df_apple.index = pd.to_datetime(df_apple.index, utc=True).tz_convert('Asia/Tokyo')
# 値を整える。NaNのデータを削除、数値では無いものも削除、浮動小数点に型変換
df_apple = df_apple.dropna(subset=['value'])
df_apple.drop(df_apple.index[df_apple['value'].str.match('[^0-9]')], inplace=True)
df_apple['value'] = df_apple['value'].astype(float)
# タイプが長ったらしいので、共通の余分な箇所を削除
df_apple['type'] = df_apple['type'].str.replace('HKQuantityTypeIdentifier','')
# 後で、月ごとや曜日ごとなどでソートしたり分析したいので、Indexに年、月、日、時間、曜日を追加
df_apple = df_apple.set_index([df_apple.index.year, df_apple.index.month, df_apple.index.day, df_apple.index.hour, df_apple.index.weekday, df_apple.index])
df_apple.index.names = ['year', 'month', 'day', 'hour', 'weekday', 'date']
df_apple.head()

だいぶスッキリしました。
df_apple.info()
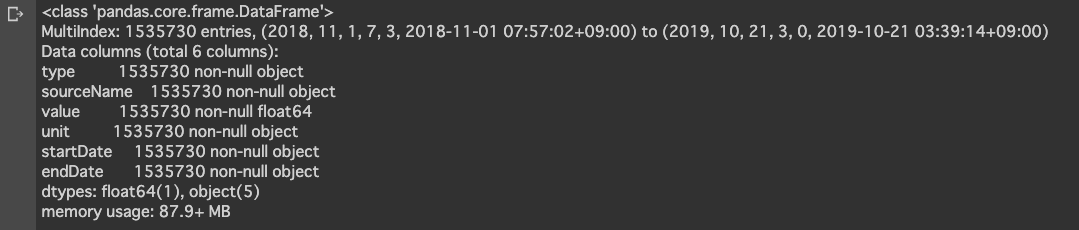
NaNなど掃除しましたが、データ数は153万以上ありますね。
日付はIndexに変換、valueがfloat型にしてあります。
xmlから変換して、データ整理してもまだ87MB以上ありますね。。重いです。
区分を見てみる
データの内訳はどうなってるか見てみます。
print(df_apple['type'].drop_duplicates().to_string(index=False, header=False))
print(df_apple['sourceName'].drop_duplicates().to_string(index=False, header=False))


- type
データの取得元なので、アプリ名だったりデバイス名が入ります(akinkoは私のニックネーム) - sourceName
データの項目名だったり、種類が入っています。例えば体重とか、歩行距離とかです(余分な接頭辞は消去済みです)
基本的にはsourceNameでデータを絞り込んでいきます。
複数のアプリや端末で、ひとつのsourceNameを共用している場合もあり、個別で調べたい場合はtypeを利用してデータを絞り込むと良いでしょう。
(例:appleWatchとiphone両方でstepcount(歩数)を取っているけど、applewatchで計測したデータだけを利用したい場合など)
分析
ここまでで、データの整頓と、ザックリと内容の確認ができました。
実際にデータの中身を見ていきます。
歩数
まずは、歩数データだけを絞り込んだDataFrameを作成
# 歩数:StepCount
# アプリで2重に取得している箇所があったため一方を削除
df_step = df_apple[(df_apple['type'] == 'StepCount') & ~(df_apple['sourceName'] == 'ヘルスケア')]
# 理由は不明だが、2018年が誤差が多く、2019年のみに絞る
df_step = df_step.query("year == '2019'")
1日の歩数ランキングTOP10
# 日毎の歩数合計
daily_step = df_step.sum(level=['year', 'month', 'day']).sort_values('value', ascending=False)
print('1日の歩数')
daily_step.head(10)
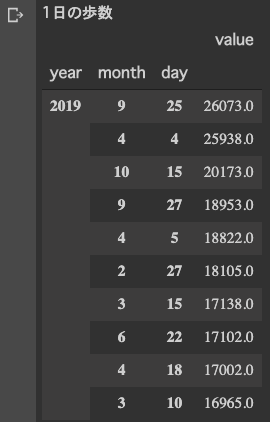
すごい歩いてますね、1位の9/25。
iphoneのデータとも整合取れているので、エラーではなさそうです。
調べてみると、有給休暇使ってお台場のチームラボ展に行って歩き回った日でした、なるほど♪
曜日ごと
何曜日が1番歩いているのか調べてみました。
# 曜日毎の歩数合計
# 0月曜ー6日曜
weekly_step = df_step.sum(level=['weekday']).sort_values('weekday')
weekly_step
plt.figure(figsize=(10,6))
plt.style.use('ggplot')
plt.title("weekly steps")
label = ["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"]
# plt.xlabel("week")
# plt.ylabel("steps")
# plt.ylim(450000, 600000)
plt.bar(weekly_step.index, weekly_step.value, tick_label=label, label="steps", align="center")
plt.show()
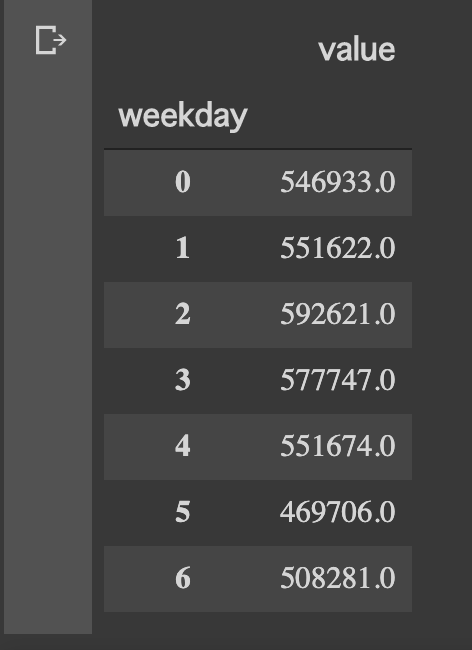
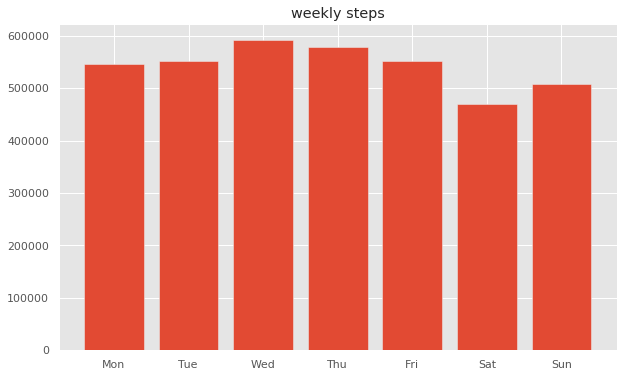
ふむふむ、
出勤が無いので土日が少なめだが、比較的に日曜は家族で出かけることが多い。
水曜は会社帰りにジムでランニングマシーンで少し走るから1番多いのか。
土曜ももう少し体を動かすことにします。
月ごと
月ごとの歩数量も見てみます。
# 月ごとの歩数合計
monthly_step = df_step.sum(level=['month']).sort_values('month')
monthly_step
plt.figure(figsize=(15,6))
plt.style.use('ggplot')
plt.title("monthly steps")
label = list(range(1, 11))
# plt.xlabel("month")
# plt.ylabel("steps")
plt.bar(monthly_step.index, monthly_step.value, tick_label=label, label="steps", align="center")
plt.show()
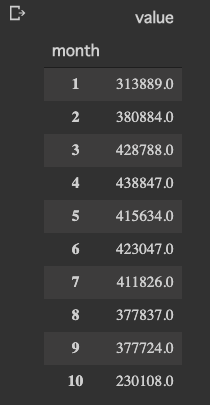
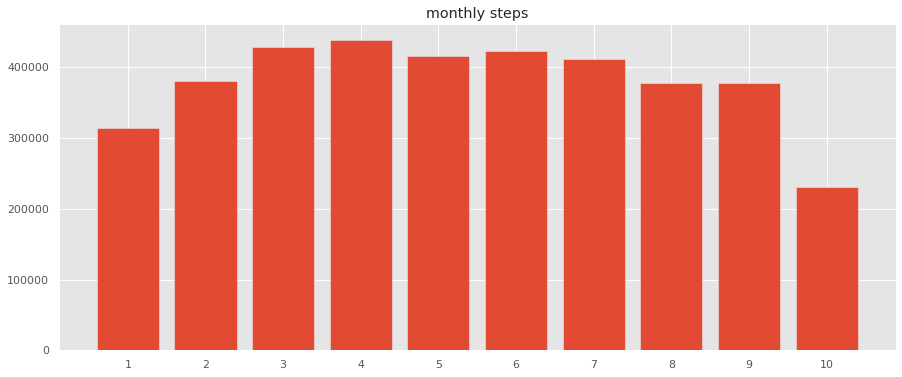
10月の途中でデータエクスポートしたので、10月は少ないです。
1月はインフルエンザと、寝正月で運動してないですね、、
今年の8月、9月は暑かったのであまり外に出なかった。
来年はインドアでも運動できるように工夫しよう。
週の歩数と合わせると
けっこう自分の行動パターンがわかって面白いです。
消費カロリー
最後に、消費カロリーについて触れておきます。
- 基礎代謝:basalEnergyBurned
何もしていなくても、生命維持のため消費されるカロリー - 活動代謝:activeEnergyBurned
運動により、消費されるカロリー
冒頭でも触れたとおり、とんでもない値が出てしまっています。
そのためか、iphone,applewatchとの合計値が整合取れてないです。
xmlからcsvへの変換でミスをしているのか、
それともログ計測1年間の間でAppleHealthCareで仕様が変更されたのかもしれません。
いちおう、活動代謝を計算して1日の消費TOP10を出してみました。
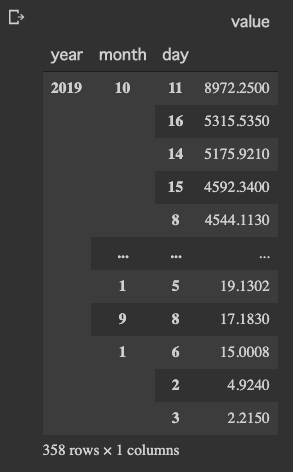
明らかにおかしい・・w
椅子に座ってコーディングしてただけなのに、8972kcal!!(トライアスロンのアイアンマン)
米国の特殊部隊でもこんなにカロリー消費しないのでは(´゚д゚`)
この記事を書き終わる直前ですが、連動させている体重計やサードパーティアプリの値も被って入っている可能性に気づきました。
機会があれば検証してみたいと思います。Appleさん、csv変換プログラムさん疑ってすいませんでした
おわりに
後々、気付いてしまったのですが、
11月のiOSアップデートで「ヘルスケア」アプリが結構優秀になっていました。
アプリ内だけでも、分かりやすく表示してくれるようになりました。
AppleWatchの活動データだけでなく、体重計や、睡眠時間、筋トレログなどと連動して分析してみるのも面白そうですね。
ここまでお読み頂きありがとうございました、皆様のヘルシープログラマーライフをお祈りしております。