概要
AWS Batchを用いて、AWS S3のファイル処理を行う方法を試行錯誤したので、自分の備忘録を兼ねて紹介する。
課題
AWS S3のバケットにある動画ファイルを、他のシステムからの指示により別のバケットにコピーしたい。
前提
- 転送元と転送先のバケットは固定である。
- 動画ファイルは、小さいもので数百 MBytes、大きいものでは1つあたり100 GBytes 以上も含む。
- このシステムは24h365dayの稼働を期待されているが、運用チームにシステムエンジニアは一人しかいない(つまり自分だ)。24時間張り付きは嫌だから、極力、システム運用が発生しない方法を選択しないといけない
- 自分は通常Windows PCで仕事をしているので、以下はWindowsの手順である。Macの人は適宜、読み替えてほしい。
方針
- ファイルの転送は5分以上かかる可能性があるので、Lambda は使えない。またS3バケットに過剰な転送負荷をかけるべきでないので、同時処理数を制御を行うには Batch が良さそうである。
- S3で大きな大きなファイル転送の場合、通常multi part転送を使う。がっつりとプログラムを組む方法もあるが、AWS CLIでもmulti partをサポートしていて、メンテナンスもAWSがやってくれるので、手間が省ける。CLIを利用する。
参考: AWS SDK for .NET マルチパートアップロード API を使用した Amazon S3 オブジェクトのコピー
構築手順
AWS環境構築
- AWS CLIをインストールして、接続設定を行う。Windows PowerShell を起動し(コマンドプロンプトでもよい。以下シェルと略す)
> aws configure
Docker環境構築
-
Docker HUBでアカウントを作成し、ログインして docker
最新版ダウンロード1し、インストールする。(再起動を求められる)
再起動時、PCのBIOSで仮想対応をONにして Docker Desctop サービスを開始する。
Dockerコンテナ作成
- PCのローカルに空のフォルダを作成し、以下を作成する。テキストエディタでUTF-8で保存するとBOMを解釈できず動きが怪しいので、日本語を使わないほうが無難だ。
run.sh
# !/bin/bash
BUCKET_SRC=(転送元のバケットを指定)
BUCKET_DST=(転送先のバケットを指定)
if [ $# -ne 2 ]; then
echo "usage $0 source_path/filename destination_path/filename" 1>&2
exit 1
fi
echo aws s3 cp s3://$BUCKET_SRC/$1 s3://$BUCKET_DST/$2
aws s3 cp s3://$BUCKET_SRC/$1 s3://$BUCKET_DST/$2
Dockerfile
FROM amazonlinux:latest
RUN curl -kl https://bootstrap.pypa.io/get-pip.py | python
RUN pip install awscli
RUN aws configure set default.s3.max_concurrent_requests 20
RUN aws configure set default.s3.multipart_threshold 64MB
RUN aws configure set default.s3.multipart_chunksize 16MB
ADD run.sh /usr/local/
- シェルを起動し、先ほどのフォルダにcdしてから、コンテナ"aws-s3-objectcopy"を作成する。"SECURITY WARNING: You are building a Docker image from Windows against a non-Windows Docker host..."のようなワーニングが出るが、今回は対処しない2。
> docker build -t aws-s3-objectcopy .
(中略)
Successfully built xxxxxxxxxxx
Successfully tagged aws-s3-objectcopy:latest
念のため、意図したものができているか確認する3。
> docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
aws-s3-objectcopy latest dcdcc19a1ebf 2 hours ago 231MB
> docker run -it aws-s3-objectcopy /bin/bash
bash-4.2## ls -l /usr/local/run.sh
-rwxr-xr-x 1 root root 226 Jan 2 06:06 /usr/local/run.sh
bash-4.2# exit
exit
ECRにレポジトリを登録する
- ブラウザでマネジメントコンソールより、ECR(Amazon Elastic Container Registry)を開く。
新規にレポジトリを作成する。ここではレポジトリ名は"aws-s3-objectcopy"とした。
シェルを起動し、ECRログイン文字列を取得し、レポジトリに登録する。
// ログイン文字列を取得
> aws ecr get-login --no-include-email --region ap-northeast-1
docker login -u AWS -p (長い文字が出力される)
> docker login -u AWS -p .....(上記表示をコピー)
Login Succeeded
// タグを指定
docker tag aws-s3-objectcopy:latest xxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/aws-s3-objectcopy:latest
//リポジトリにpush
docker push xxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/aws-s3-objectcopy:latest
AWS Batch起動用のネットワーク設定
- あとでセキュリティをカスタマイズするかもしれないので、専用のVPC/サブネットを作成して、セキュリティグループを作成する。(解説は省略)
- Batchコンテナを起動したサブネットからS3にアクセスするため、NAT Gateway経由でアクセスできるようにNATおよびルートテーブルを構築する。
AWS Batchの設定を行う(コンピューティング環境とジョブキューの作成)
- マネジメントコンソールでAWS Natchを開く。初回、初期ウィザードが起動したら「ジョブをどのように実行しますか?」で「ジョブの送信なし」を指定して「次へ」
- コンピューティング環境とジョブキューの設定

コンピューティング環境の名前=batch-s3-objectcopy(任意)
サービスロール=新しいロールの作成
EC2 インスタンスロール=新しいロールの作成
プロビジョニングモデル=オンデマンド
最小 vCPU=0
必要な vCPU=0
最大 vCPU=2
ジョブキュー名=jq-batch-s3-objectcopy
ロールはあとで調整する。vCPUは間違ってコストを浪費しないように、最初は最小設定で。
ネットワーキングの設定は先ほど作成したVPC/サブネット/セキュリティグループを指定
ジョブ実行ロールの設定を行う
- Batchの初期ウィザードにより、AWSBatchServiceRole と ecsInstanceRole が作成される。
マネジメントコンソールでIAMの画面より、ロールの画面を開き、該当のロールを確認する。 - ecsInstanceRole にS3の該当バケットにアクセスするためのカスタムポリシーを作成して割り当てる。
policy
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::(転送元バケット)/*"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:PutObjectAcl"
],
"Resource": "arn:aws:s3:::(転送先バケット)/*"
}
]
}
AWS Batchの設定を行う(ジョブ定義の作成)
- ジョブ定義を新規作成する
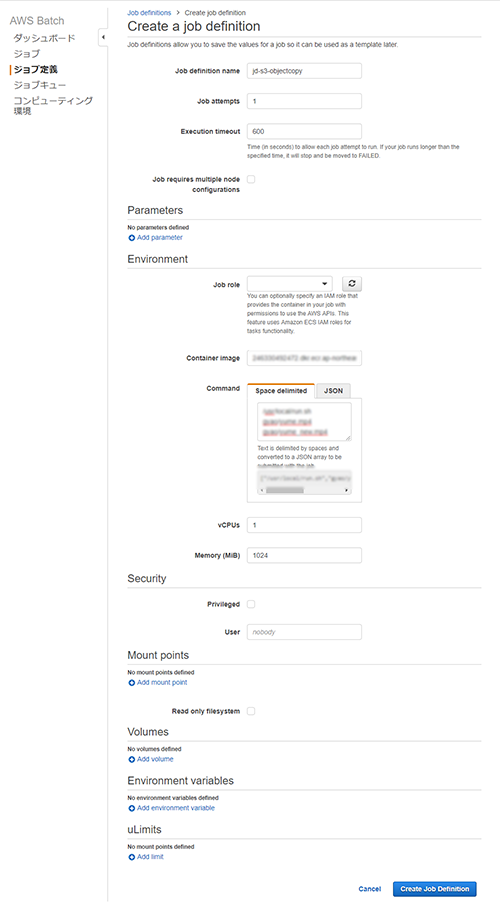
Job definition name=jd-s3-objectcopy(任意)
Job attempts(ジョブ試行)=1
Execution timeout(実行のタイムアウト)=600
Container image=(先ほど作成したコンテナ)
Command="/usr/local/run.sh 転送元パス/ファイル名 転送先パス/ファイル名"
vCPU=1
メモリ=1024(適当な値で、後で調節)
AWS Batchの設定を行う(ジョブ定義の作成)
- いよいよジョブを登録する。
マネジメントコンソールでジョブの画面を開き、「ジョブの送信」 - Submit an AWS Batch Job

Job name=適当に
Job definition=上記で作成したものを指定
Job queue=上記で作成したものを指定
Commandでジョブ定義で指定したものがデフォルトで設定されているので、必要あれば変更する。
「submit job」を実行。 - ジョブが正常に作成されたらダッシュボードを開く
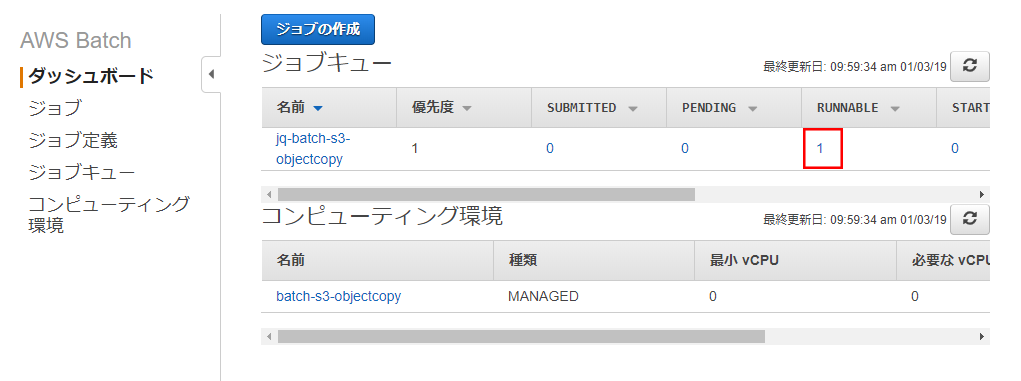
RUNNABLEに登録したジョブが表示され、しばらく1~2分くらい待つとSTARTになり、正常に完了するとSUCCEEDEDになる。
マネジメントコンソールのS3から、転送先のバケットを見るとファイルが作成されていれば成功。 - CloudWatch で実行したログを確認する。
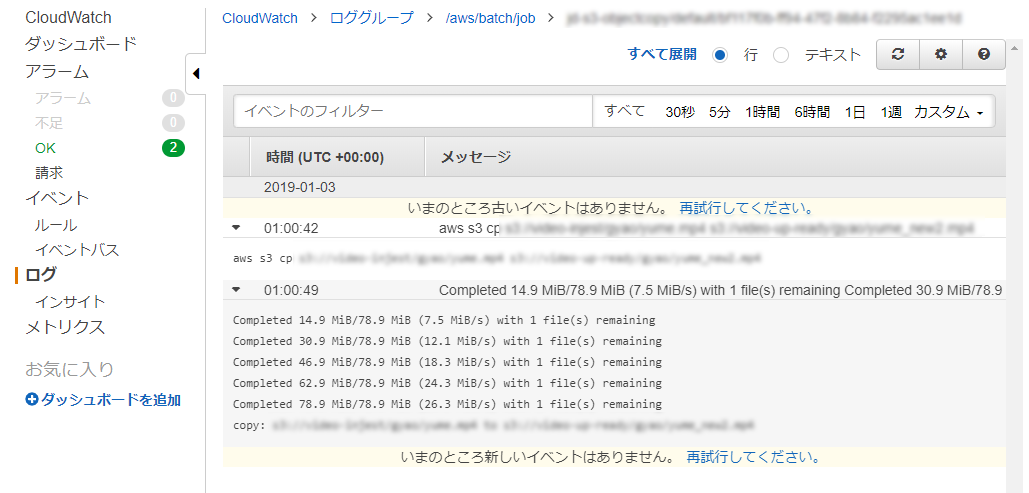
起動した実行ファイルの出力がそのままCloudWatchに出力されるらしい。
トラブルシュート
- ジョブがRUNNABLEのまま開始しない
サブネットから外部への通信ができない場合、NATやルートテーブルの設定不具合の可能性がある。デバッグにはサブネットでec2インスタンスを起動して通信を確認するのが手っ取り早い。4
参考 : AWS Batch のトラブルシューティング→ RUNNABLE 状態でジョブが止まる
まとめ
- AWS Batch でバケット間ファイルコピーができた。
- この方法で600MBの動画ファイルをオレゴンリージョンのS3バケットから同一リージョンの別のバケットに転送してみたが、バッチの実行時間は8秒であった。こんなに短いとBatchでつくる必要があるか、というのは悩ましいが、AWSのドキュメントではs3のgetObject/putObjectの速度を保証していないので、深く考えないことにしよう5。
今後の課題
- バッチジョブを起動する仕組みの構築を行う
- ファイル転送の失敗、ジョブがタイムアウトした場合の検知とエラー処理
参考文献
- AWS Batchを使って5分以上かかる処理を実行してみる
https://dev.classmethod.jp/cloud/aws-batch-5min-over/
-
今回用いたDockerバージョンは 18.09.0である ↩
-
開発段階では動作上支障がないのでエラーは無視する。Windows特有の現象なのか? 実際使うときになったらMacかLinux上でビルドしよう。 ↩
-
作成したコンテナは"docker ps -a -n=5" で確認。"docker rm (コンテナID)"で不要コンテナを整理。不要になったイメージは docker rmiで削除する。 ↩
-
自分でハマったときは、ルートテーブルのデフォルトゲートウェイのCIDRネットマスク部分を間違えて "0.0.0.0/24" と指定していた。正しくは "0.0.0.0/0"。サブネットにVPCを起動してパブリックサブネットのVPCを経由してログインできるのに、外部ネットワークにリーチャブルでなく、routeを確認して気づいた。 ↩
-
もしやりたい処理が数秒で完了することが保証されるなら、わざわざBatchにしなくても、呼び出し側のプログラムで実装したほうが簡単であるし、コストが小さい。 ↩